Ray と Kueue を使用した AI / ML の高度なスケジューリング
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
Ray は、オープンソースの統合コンピューティング フレームワークです。AI / ML や Python アプリケーションを容易にスケーリングできることから、開発者の間で好評を博しています。KubeRay は Google Kubernetes Engine(GKE)内で Ray の機能を利用したソリューションを提供します。KubeRay は Ray クラスタのオーケストレーターとして機能し、コンピューティング、ネットワーキング、ストレージの基盤レイヤとして Kubernetes API を活用しています。また、KubeRay はクラウドネイティブの強力なキューイング システムである Kueue とも連携して、GKE 上で Ray アプリケーションの高度なスケジューリング機能を利用可能にしています。
このブログ投稿では、KubeRay と Kueue がどのように連携して Ray アプリケーションの高度なスケジューリングをオーケストレーションしているのかを掘り下げます。また、以下の手法をご紹介します。
- 優先スケジューリング: AI / ML タスクに優先順位を付け、本番環境の信頼性を確保し、費用対効果を高めます。
- ギャング スケジューリング: 蜜結合した AI / ML タスクの同時実行をオーケストレーションし、リソースの使用量を最大化してトレーニングを加速させます。
優先スケジューリング
シナリオ
ある会社が、継続的インテグレーション(CI)のテストや本番環境用の RayJob を使用したオフライン バッチ推論タスクなど、さまざまなバッチ ワークロードを GKE クラスタ上でホストしています。クラスタのリソースには限りがあり、これらのアプリケーション間で共有する必要があるため、この会社は本番環境ワークロードの迅速な実施を目指しています。その結果、優先スケジューリングが採用され、本番環境ワークロードでは CI テストなどの優先順位の低いタスクからリソースをプリエンプトできるようになりました。
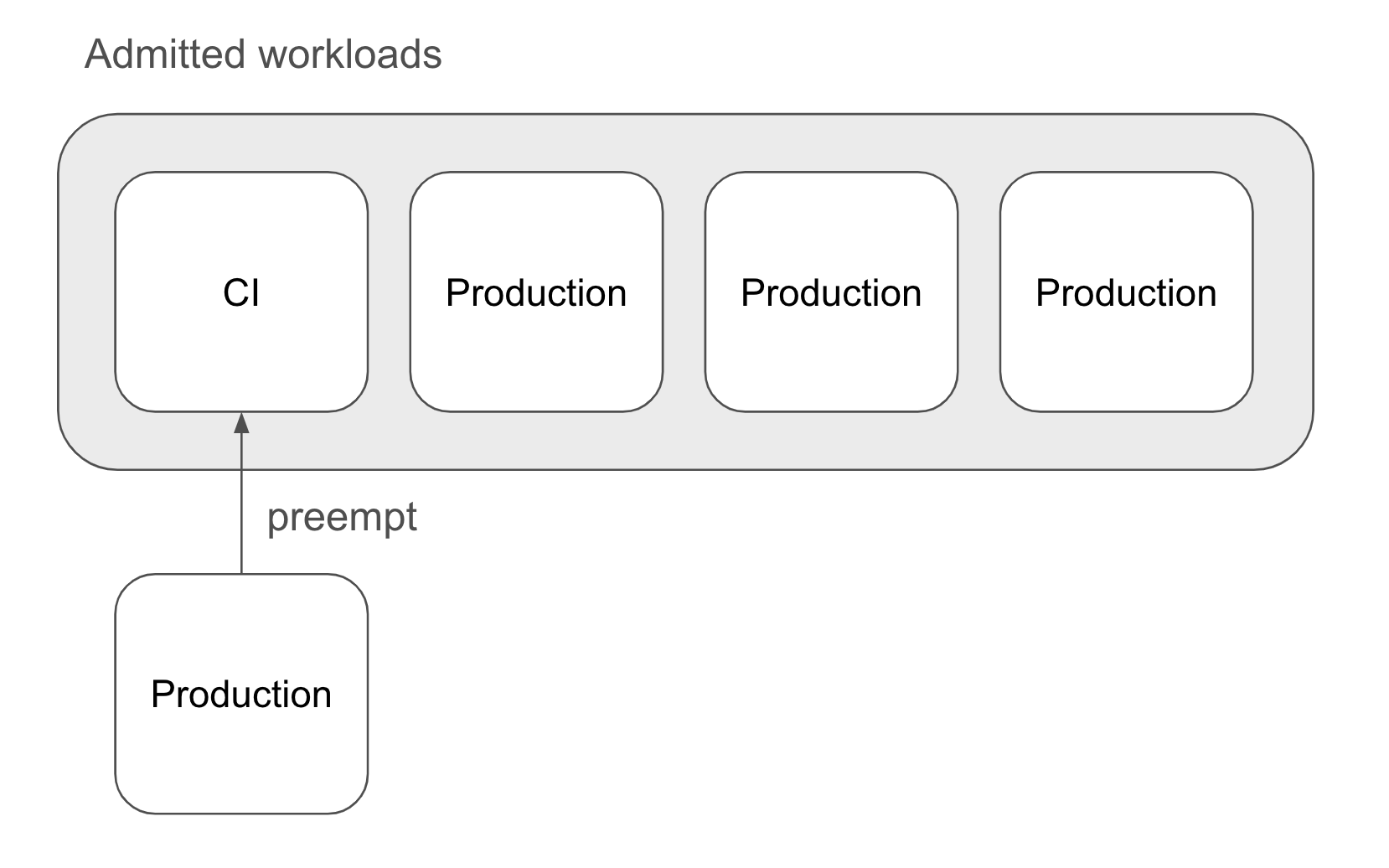
Kueue と KubeRay の優先スケジューリングの実装方法
Kueue の WorkloadPriorityClass API は、GKE 環境内で RayJob と RayCluster のリソースを優先するために必要な制御を可能にします。ワークロードの優先順位は 2 つの重要な側面に影響します。まず、ClusterQueue 内でワークロードの順序が決定され、優先順位の高いワークロードがより早く実行されます。次に、ClusterQueue またはそのコホートの割り当てが不足している場合、受信ワークロードは ClusterQueue のポリシーに基づき、すでに許可されているワークロードのプリエンプションをトリガーできます。プリエンプションは RayJob と RayCluster のためにすべての Ray Pod を削除し、カスタム リソースのステータスを「一時停止中」に遷移させます。その後、ClusterQueue のリソースが十分に確保されると、Kueue は中断されていたワークロードを再開します。
優先スケジューリングは、限られたリソースを本番環境ワークロードと開発ワークロードで奪い合うような場合には欠かせません。本番環境に関連するタスクに高い優先順位を割り当てることで、時間的制約の少ないジョブのプリエンプションが可能となり、適切なタイミングで本番環境モデルの更新やデプロイを行うことができます。
以下は、本番環境ワークロードと開発ワークロードを区別する 2 つの WorkloadPriorityClass リソースの例です。
その後、Kueue の優先度クラスのラベルを使用して、KubeRay リソースに優先度クラスを割り当てます。
詳しい手順については、RayJob と Kueue を使用した優先スケジューリングのガイドをご覧ください。
ギャング スケジューリング
シナリオ
ワークロードの承諾に対する Kueue のオールオアナッシング アプローチでは、必要なリソースがすべて利用可能な場合にのみ、RayJob と RayCluster がスケジュールされるようにします。これにより、タスクを実行できないクラスタが部分的にプロビジョニングされることを防ぎ、リソースの効率性を大幅に高めます。通常、「ギャング スケジューリング」と呼ばれるこの戦略は、大量のリソースを消費する AI / ML ワークロードにとって特に有用です。
ギャング スケジューリングは、分散型モデルのトレーニングでデータ並列処理を行うようなユースケースにおいて重要です。データ並列処理では、複数の Pod にデータをシャーディングして、それぞれで同じモデルを実行します。勾配はすべてパラメータ サーバーに送られ、パラメータ サーバーはハイパーパラメータを更新し、次の反復処理のためにすべての Pod に再配布します。RayJob または RayCluster が部分的にプロビジョニングされている場合、パラメータ サーバーはハイパーパラメータを更新できず、カスタム リソースが完全にプロビジョニングされるまで処理が停止するため、リソースの完全な無駄となります。ギャング スケジューリングでは、このような状況を効果的に回避できます。
Kueue と KubeRay のギャング スケジューリングの実装方法
Kueue の動的なリソース プロビジョニングとキューイングを利用して、KubeRay のギャング スケジューリングをオーケストレーションできます。これは、GPU や TPU のような制限のあるハードウェア アクセラレータを使用する場合に不可欠です。Kueue は、必要なリソースがすべて使用可能な場合にのみ Ray ワークロードが実行されるようにして GPU / TPU サイクルの無駄を防ぎ、使用量を最大化します。
Kueue は ProvisioningRequest API を使用して、GKE 上でこの効率的なギャング スケジューリングを実現します。この API は、必要なコンピューティング ノードを同時にプロビジョニングできるまで待機するよう、Ray ワークロードにシグナルを送ります。GKE のクラスタ オートスケーラーは ProvisioningRequest を受け入れ、必要なリソースがすべて使用可能な場合に限り、ノードをワンステップでスケールアップします。その後、新たにプロビジョニングされたノード上に、Ray クラスタ Pod がまとめてスケジューリングされます。詳しくは ProvisioningRequest の仕組みをご覧ください。
詳しい手順のデモンストレーションについては、RayJob と Kueue を使用したギャング スケジューリングのガイドをご覧ください。
まとめ
KubeRay と Kueue は、GKE 内で Ray アプリケーションを管理および最適化する強力なツールを提供します。優先スケジューリングは、最も重要な AI / ML タスクが必要なリソースを常に確保できるようにします。ギャング スケジューリングは、ハードウェア アクセラレータを最大限に活用して時間の無駄を防ぎ、効率を最大化するのに役立ちます。これらの手法を組み合わせることで、クラウド上の Ray アプリケーションのパフォーマンスと費用対効果が向上します。
-Google、ソフトウェア エンジニア Andrew Sy Kim
-Anyscale、ソフトウェア エンジニア Kai-Hsun Chen 氏

