新しい GKE 推論機能で費用とテール レイテンシを削減し、スループットを向上
Akshay Ram
Group Product Manager, GKE
Drew Bradstock
Sr. Director of Product Management, Google Kubernetes Engine
※この投稿は米国時間 2025 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
現在、生成 AI モデルによる現実世界のビジネス上の問題解決を可能にしているのは、推論です。Google Kubernetes Engine(GKE)では、生成 AI 推論の採用が進んでいます。たとえば、HubX は、画像ベースのモデルの推論を実行して、1 日あたり 25 万枚以上の画像を処理することで、生成 AI エクスペリエンスを強化しています。また、Snap は、広告ランキング システムのために GKE で AI 推論を実行しています。
しかし、生成 AI 推論の導入には課題も伴います。まず、このプロセスの評価フェーズでは、すべてのアクセラレータ オプションを評価し、各自のユースケースに適したものを選択する必要があります。Tensor Processing Units (TPU) への関心が高まるなか、多くのお客様は一般的なモデル サーバーとの互換性を求めています。本番環境への移行後は、トラフィックのロード バランシング、実際のトラフィックの規模に応じたコスト パフォーマンスの管理、パフォーマンスのモニタリング、発生した問題のデバッグを行う必要があります。
今週開催された Google Cloud Next では、この課題に対応するために、GKE 向けの新しい生成 AI 推論機能を発表しました。
-
GKE Inference Quickstart: ベスト プラクティスに従って推論環境をセットアップできます。
-
GKE TPU サービング スタック: TPU のコスト パフォーマンスのメリットを簡単に活用できます。
-
GKE Inference Gateway: 生成 AI に対応するスケーリングとロード バランシングの手法を導入します。
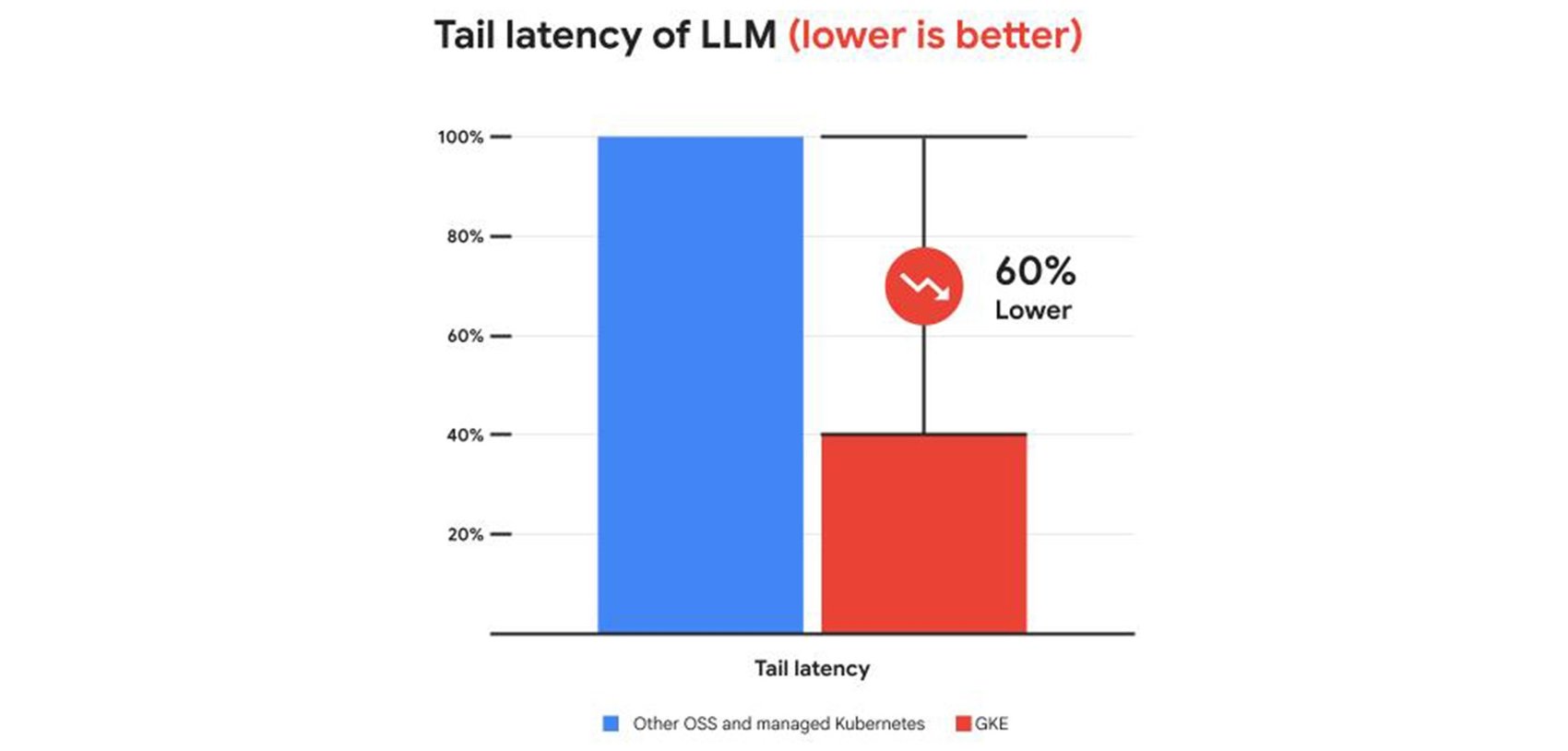
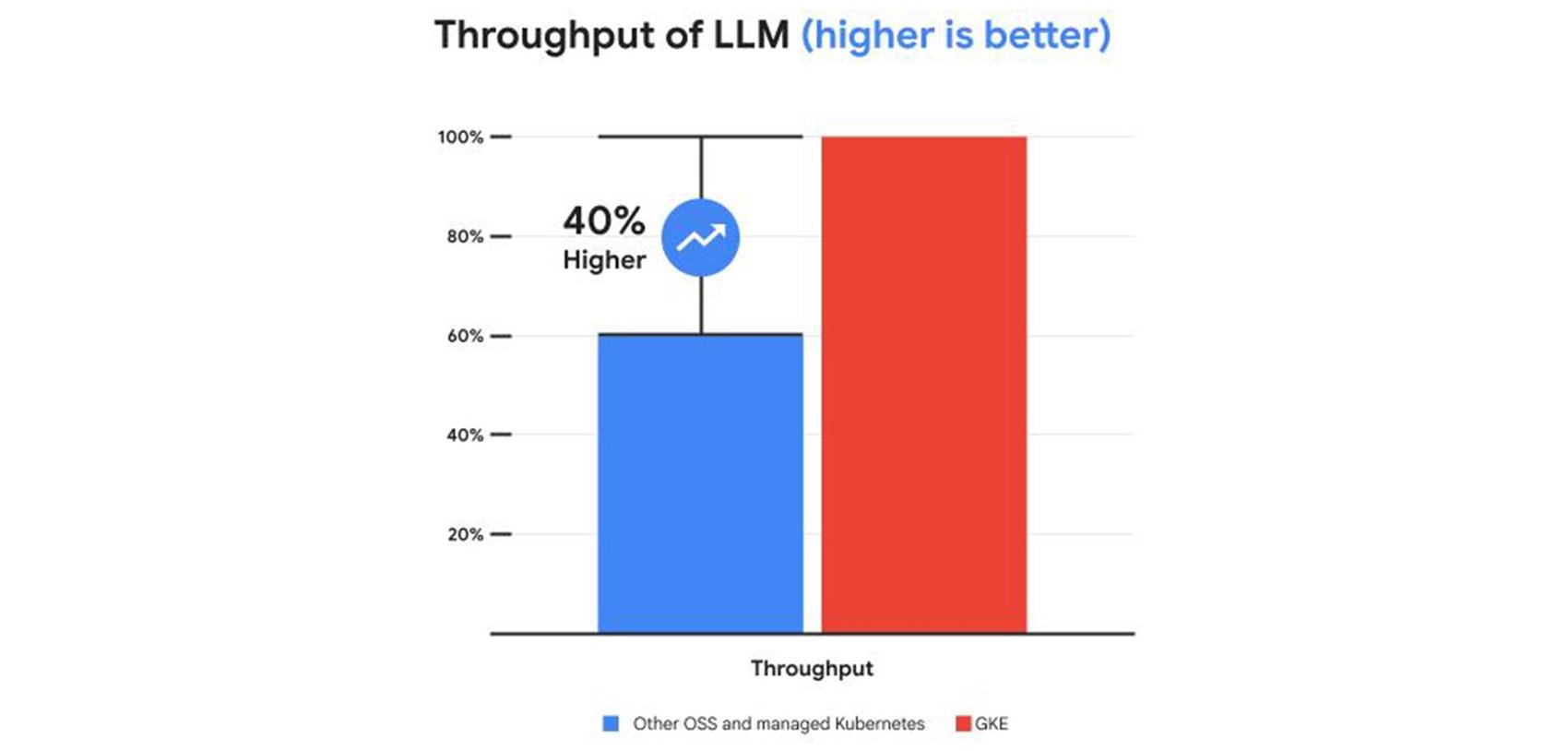
これらの機能により、他のマネージド サービスやオープンソースの Kubernetes サービスと比較して、サービング費用を 30% 以上、テール レイテンシを 60% 削減し、スループットを最大 40% 向上させることができます。

GKE Inference Quickstart
GKE Inference Quickstart は、AI / ML 推論アプリケーションに最適なアクセラレータ、モデルサーバー、スケーリング構成の選択と最適化を支援します。インスタンス タイプ、さまざまな GPU と TPU のモデルとインスタンスの互換性、特定のアクセラレータがパフォーマンス目標の達成にどのように役立つかを示すベンチマークに関する情報が含まれており、アクセラレータの構成後は、GKE Inference Quickstart を Kubernetes のスケーリングや、推論固有の新しい指標にも活用できます。今後のリリースでは、GKE Inference Quickstart が Gemini Cloud Assist エクスペリエンスとして利用可能になります。
GKE TPU サービング スタック
TPU と vLLM(主要なオープンソース モデルサーバーの一つ)をサポートすることで、GPU / TPU 間でのシームレスなポータビリティが実現します。これにより、任意のオープンモデルを使用し、vLLM:TPU コンテナ イメージを選択して、TPU 固有の変更を加えることなく簡単に GKE にデプロイできます。GKE Inference Quickstart では TPU のベストプラクティスも推奨しているため、TPU でスムーズに実行でき、切り替え費用も発生しません。最先端のモデルを実行したい場合は、Google 社内で Gemini などの大規模モデルに使用している Pathways を利用して、マルチホストや非集約型のサービングを実行できます。
GKE Inference Gateway
GKE Gateway は、ロードバランサを利用した抽象化であり、Kubernetes アプリケーションへの受信リクエストをルーティングするものです。従来は、ラウンドロビンなどのロード バランシング手法を使用して、リクエストのパターンが非常に予測しやすいウェブサービス アプリケーション向けにチューニングされていました。しかし、LLM のリクエスト パターンには大きなばらつきがあります。そのため、高いテール レイテンシや不均一なコンピューティング利用が発生し、エンドユーザー エクスペリエンスに悪影響を及ぼしたり、推論費用が無駄に増加したりする可能性があります。また、従来の Gateway は、推論時にモデルを再利用することで GPU の効率を高めることができる、Low-Rank Adaptation(LoRA)などの一般的なパラメータ エフィシエント ファインチューニング(PEFT)手法用のルーティング インフラストラクチャをサポートしていません。
スケールアウトのシナリオでは、新しい GKE Inference Gateway が生成 AI 対応のロード バランシングを提供し、最適なルーティングを実現します。また、GKE Inference Gateway を使用することで、安全なロールアウトのためのルーティング ルール、複数のリージョンにまたがる設定、優先度などのパフォーマンス目標を定義できます。さらに、GKE Inference Gateway は LoRA をサポートしているため、複数のモデルを同じ基盤サービスにマッピングして、効率を高めることができます。
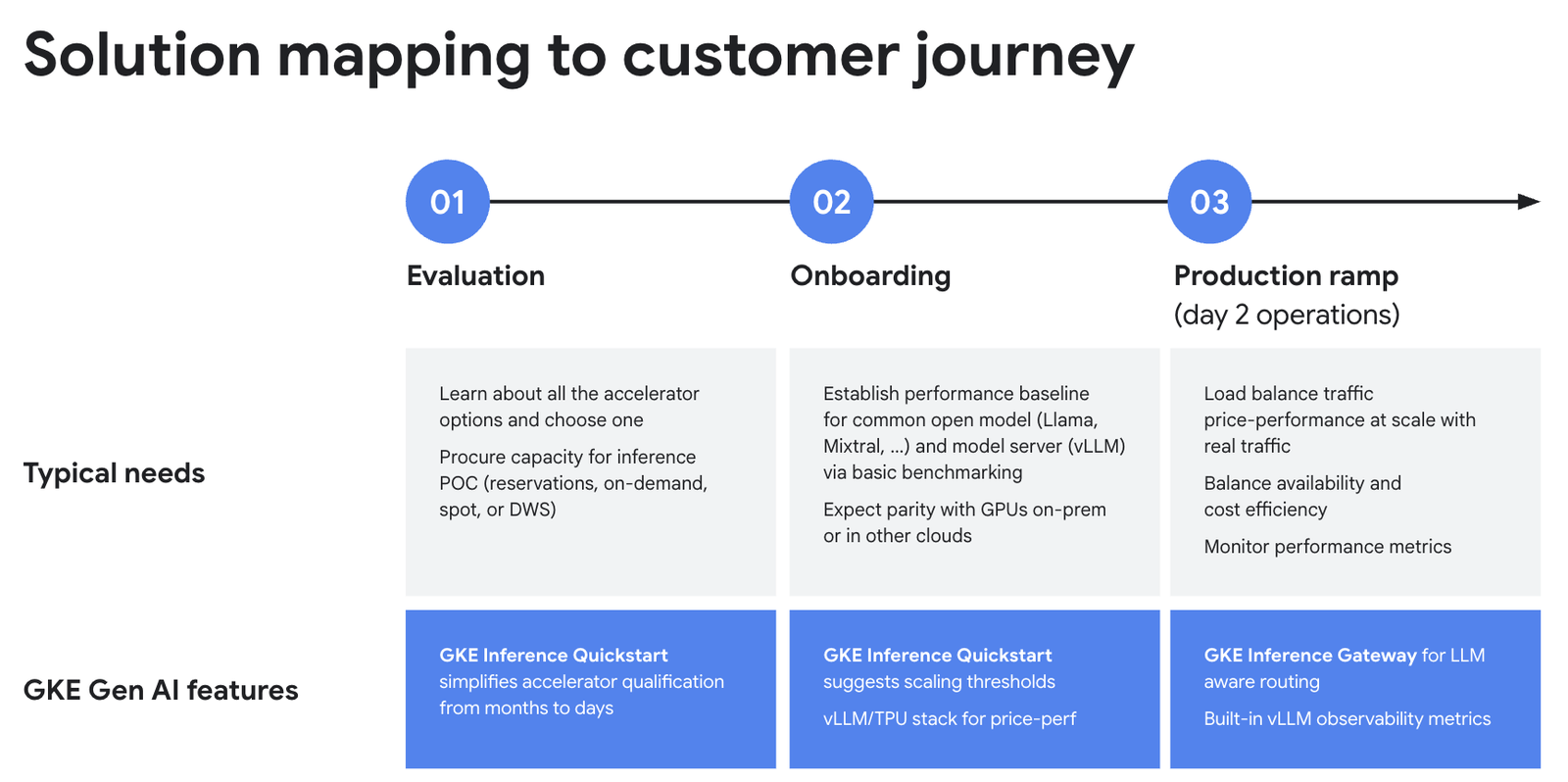
以下の図は、AI 推論のさまざまな段階におけるお客様のニーズをまとめたものです。GKE Inference Quickstart、GKE TPU サービング スタック、GKE Inference Gateway が、評価、オンボーディング、本番環境の各フェーズをどのように簡素化するかを示しています。
お客様の声
「GKE で TPU を使用することで(特に、推論用に新しい Trillium を使用して画像生成をした場合)、レイテンシが最大 66% も短縮され、ユーザーエクスペリエンスの向上とコンバージョン率の増加につながりました。レスポンスを 30 秒も待つようなことはなくなり、10 秒以内に受け取れるようになりました。これは、ユーザー エンゲージメントと定着率の向上に不可欠です」- HubX、共同創業者、Cem Ortabas 氏
「お客様は、生成 AI 推論のコスト パフォーマンスの最適化を重視しています。最適化されたロード バランシングと拡張性を備えた GKE Inference Gateway がオープンソースで提供されることを楽しみにしています。GKE Inference Gateway の新しい機能は、お客様の推論ワークロードのパフォーマンスをさらに向上させる可能性があります」- BentoML、CEO / 創業者、Chaoyu Yang 氏
GKE の新しい推論機能は、AI の次のステップに進むための強力な機能のセットです。詳しくは、Next 25 で開催された GKE 生成 AI 推論のブレイクアウト セッションをご覧になり、Snap がどのように推論プラットフォームを再構築したかをご確認ください。
-GKE、グループ プロダクト マネージャー、Akshay Ram
-Cloud Runtimes 担当シニア ディレクター、Drew Bradstock
