Google Kubernetes Engine でアプリをデバッグするツール
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: この記事は、Google Kubernetes Engine で実行されているコンテナ化されたアプリケーションで Cloud Logging を使用する方法に関する最近の投稿のフォローアップです。この投稿では、DevOps チームが Cloud Monitoring と Cloud Logging を使用して問題をすばやく見つける方法を中心に解説します。
Google Kubernetes Engine(GKE)でコンテナ化されたアプリを実行するのは、DevOps チームがアプリ開発に集中できるようにするためです。これにより、チームは安全でスケーラブルな高可用性 Kubernetes クラスタを実行するために必要な運用上の作業から解放されます。Cloud Logging と Cloud Monitoring は、GKE に統合されたサービスの一部で、アプリケーションとシステムに対する DevOps チームのオブザーバビリティを高め、問題発生時にトラブルシューティングしやすくするものです。
Cloud Logging を使用する
シンプルですが、ごく一般的なユースケースを見てみましょう。ご自身が、DevOps チームのメンバーだとします。本番環境の Kubernetes クラスタでアプリケーション エラーが発生したというアラートを Cloud Monitoring から受け取りました。このエラーを診断する必要があります。具体例を示すために、ここでは GKE クラスタにデプロイされているサンプルのマイクロサービス デモアプリに基づいたシナリオを使用します。このデモアプリには、さまざまなマイクロサービスと、その依存関係が含まれています。
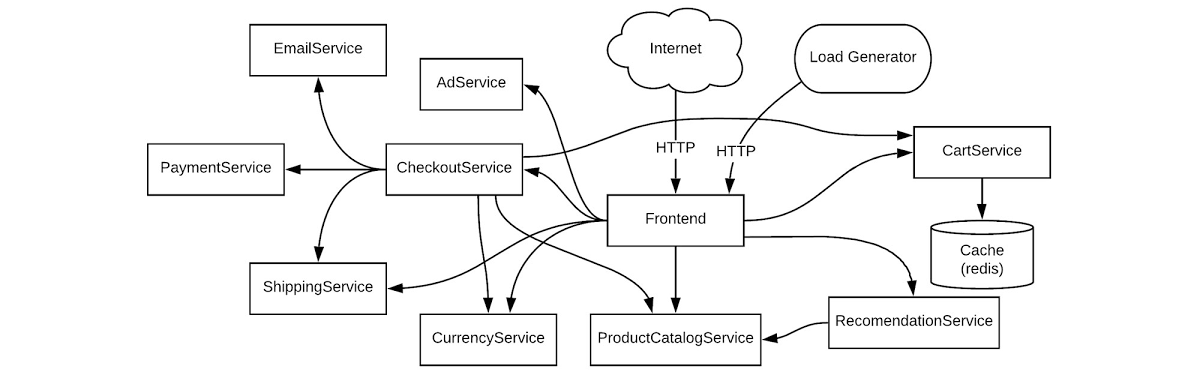
この例では、複数のチームで共有しているステージング環境、または複数のワークロードを実行している本番環境でデモアプリが実行されているとします。簡単なエラーシナリオをトラブルシューティングする方法を見てみましょう。
まず、多数の HTTP 500 エラーによってトリガーされたアラートを確認するところから始めましょう。ログイベントの数またはログエントリの内容に基づいてログベースの指標を作成できます。これはアラート目的にも活用できます。Cloud Monitoring は、メールや SMS の送信、サードパーティ アプリでの通知生成を設定できるアラート機能を提供しています。
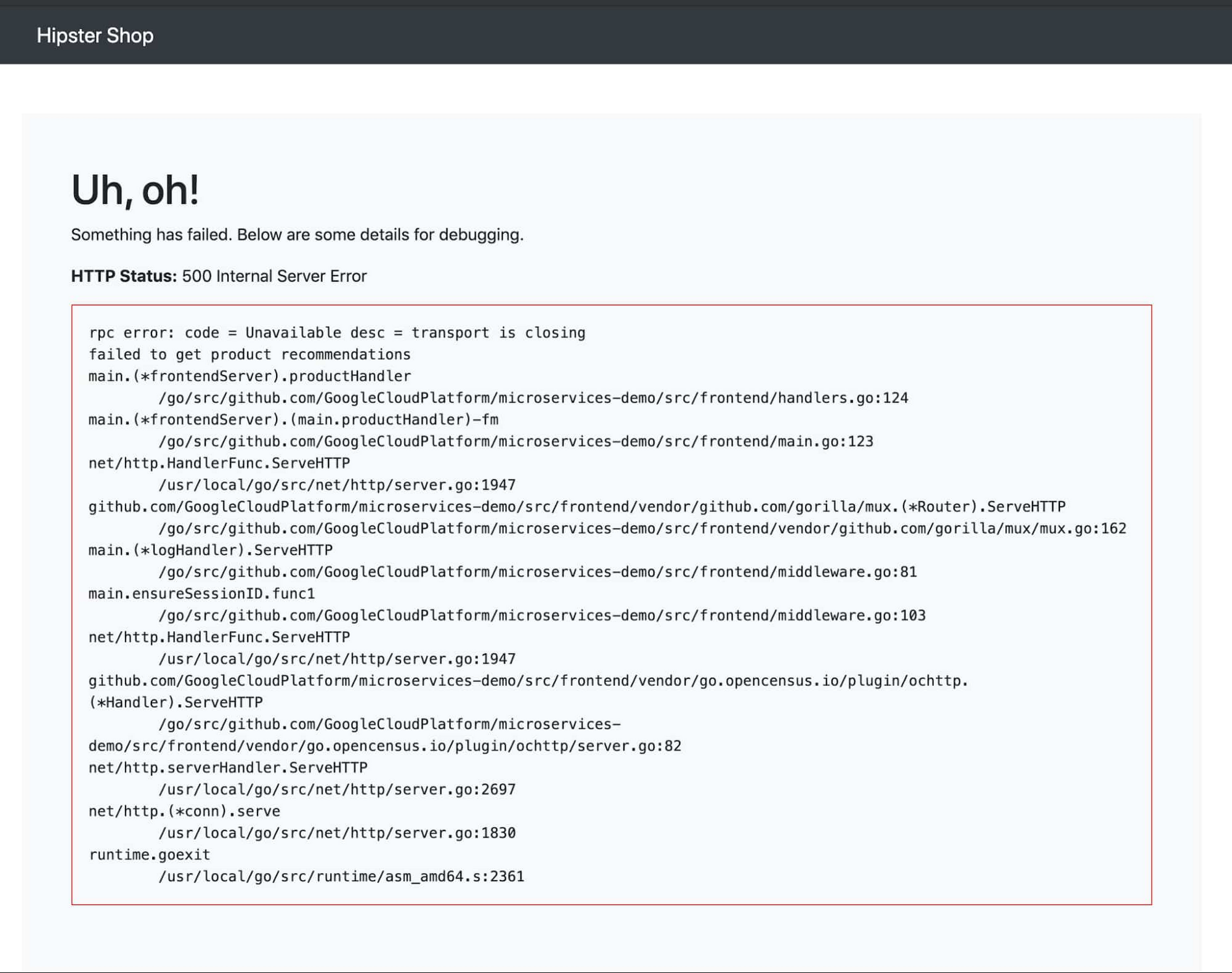
この例では、次のスタック トレースで HTTP 500 エラーが発生したとします。
すでに Cloud Monitoring でアラート ポリシーを作成している場合は、次のような通知を受け取ります。
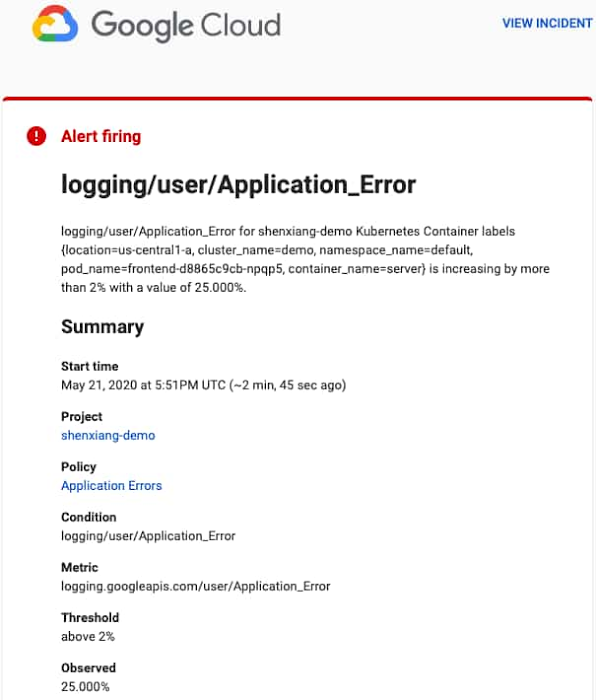
[インシデントを表示] をクリックすると、インシデントの詳細を表示できます。アラート通知にある [ポリシー] をクリックすると、Monitoring UI のアラート セクションが開きます。
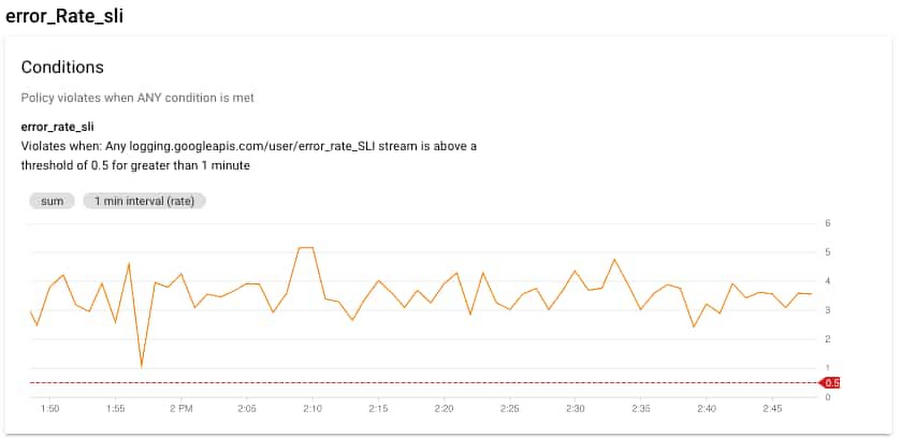
エラー情報の確認のために最初に見る場所の一つは、Monitoring コンソールの Kubernetes Engine セクションです。ワークロード ビューを使ってクラスタを選択すると、そのクラスタで実行されているポッドとコンテナの使用リソースを簡単に確認できます。この場合、recommendationservice のポッドとコンテナの CPU 使用率が非常に高いことがわかります。これは、recommendationservice が過負荷状態になっていて、フロントエンドからのリクエストに応答できないことを意味している可能性があります。コンテナの CPU とメモリの使用率についてもアラートが生成されるよう、アラートを設定しておくことが理想的です。
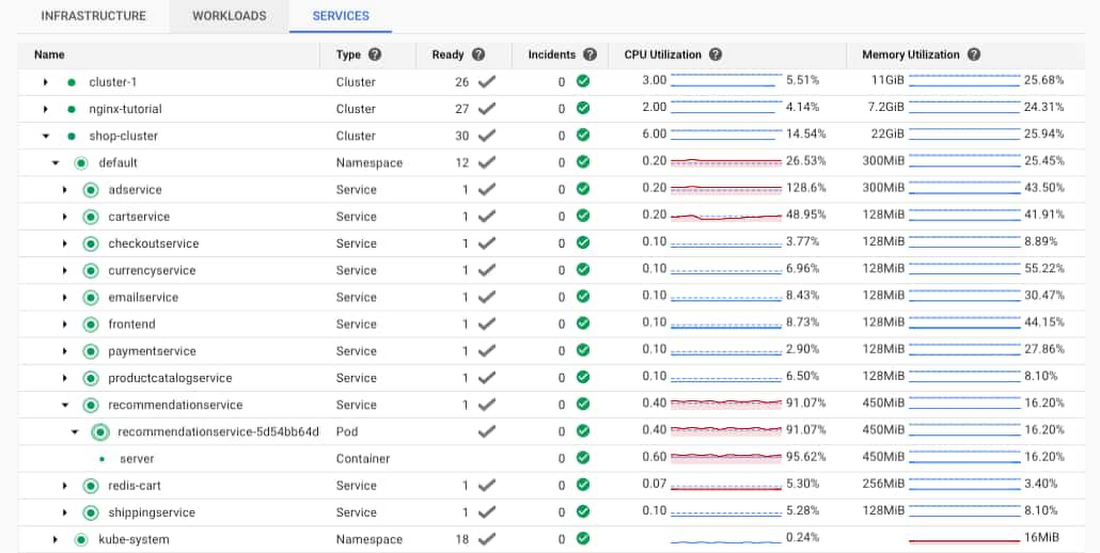
recommendationservice サービスまたはポッドの下の server コンテナへのリンクを開くとコンテナの詳細が表示されます。表示されるのは、メモリや CPU などの指標、ログ、コンテナに関する詳細などです。[管理] をクリックすると、GKE コンソールでポッドの詳細に直接移動することもできます。
Monitoring は GKE コンソールに統合されているため、ポッドのモニタリング グラフを表示できます。CPU グラフを使用すると、CPU がリクエスト量をたびたび超えていることがわかります。左下のグラフで紫の線が青の実線と交差していることに注目してください。また、メモリとディスク容量の使用率がさほど高くないことも簡単にわかるため、考えられる問題から排除できます。このケースの問題は、CPU であると考えられます。
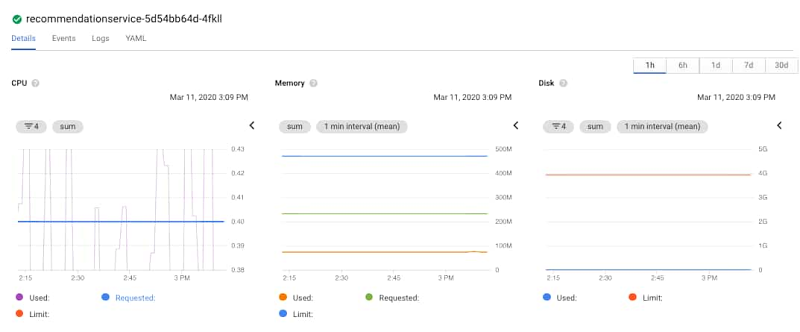
コンテナをクリックすると、リクエストされた CPU、メモリ、デプロイの詳細が表示されます。

また、[変更履歴] をクリックして、コンテナの履歴を確認することもできます。最近デプロイが行われたことがわかります。
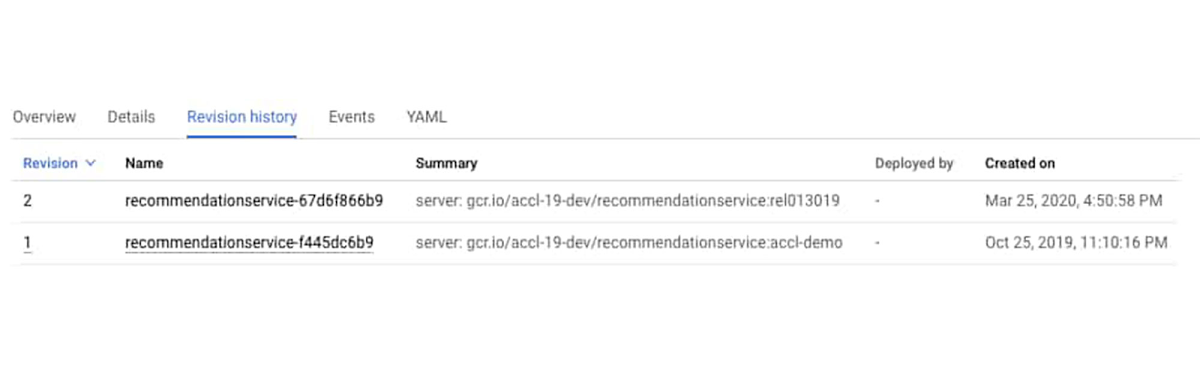
追加の CPU パワーが突然必要になる理由についての情報がないか、ログを確認する価値はあります。元のエラーがフロントエンドのポッドを介して提供された 500 エラーだったことから、[ワークロード] のフロントエンド エントリに移動します。フロントエンドのログを表示するには、[コンテナのログ] をクリックします。これにより Cloud Logging UI が開き、このコンテナのログ用にあらかじめ作成された特定のフィルタが表示されます。
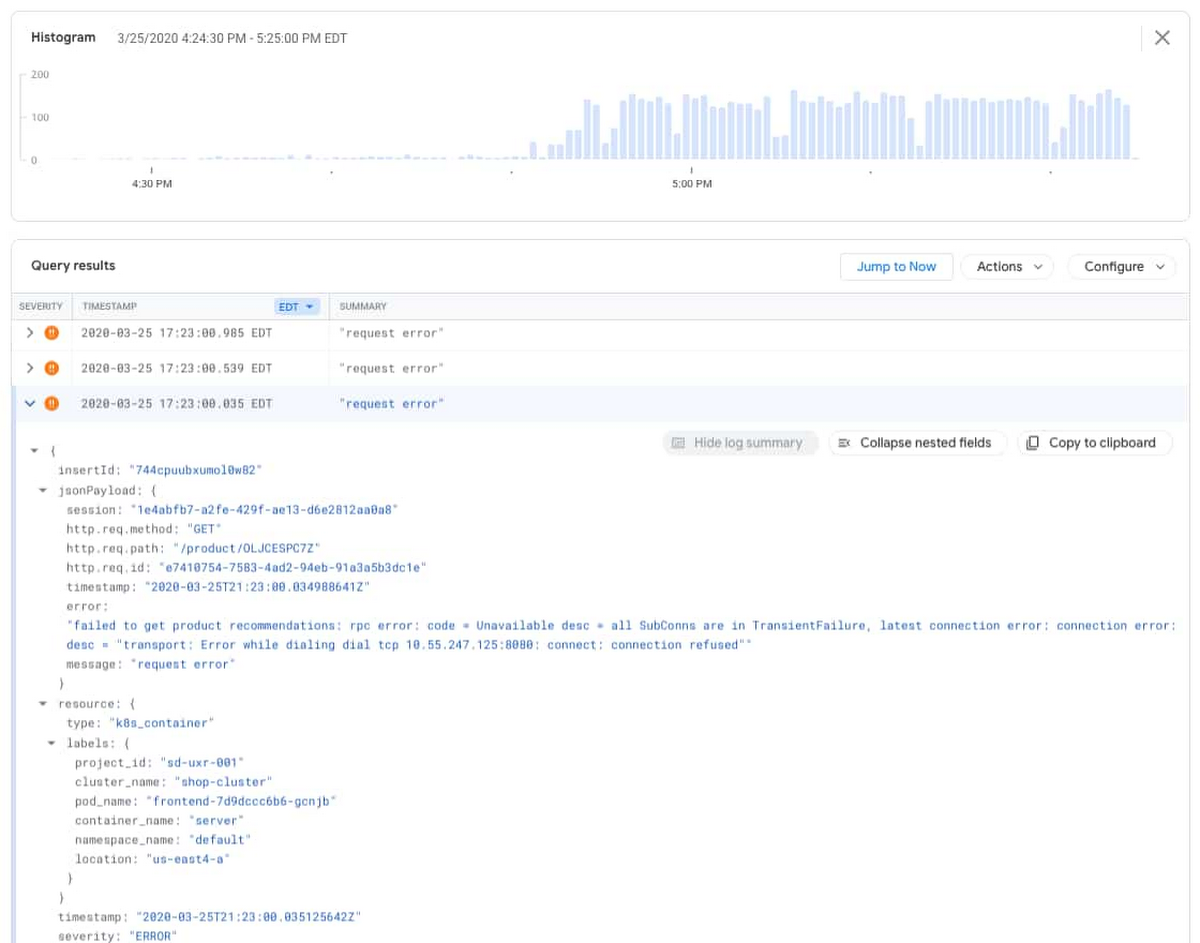
ログビューアでは、詳細なクエリ、ログのヒストグラム、個々のログエントリを確認できます。ヒストグラム機能は、特定の時間枠でログエントリがモニタリングされた頻度についてのコンテキストを提供します。この機能はアプリケーションの問題を特定する強力なツールとして活用できます。このケースでは、エラーエントリが午後 4 時 50 分頃に増加し始めたことがわかります。
エラーエントリを展開すると、以下のログ メッセージが表示されます。
これは、フロントエンド ポッドを介して提供された元の HTTP 500 エラーと一致します。次に、ログフィルタを調整して「recommendations」という名前のエラーエントリを表示して、recommendationservice ポッドログを確認します。以下のフィルタにより、「recommendations」という接頭詞を持つポッド内のコンテナで発生したエラーのみがエントリとして表示されます。
次に、フィルタを調整して、エラー以外のログエントリを確認します。
ログ ヒストグラムで、サービスから生成されたログエントリがあることがわかります。これは、サービスがまだいくつかのリクエストを受信して応答していることを意味します。
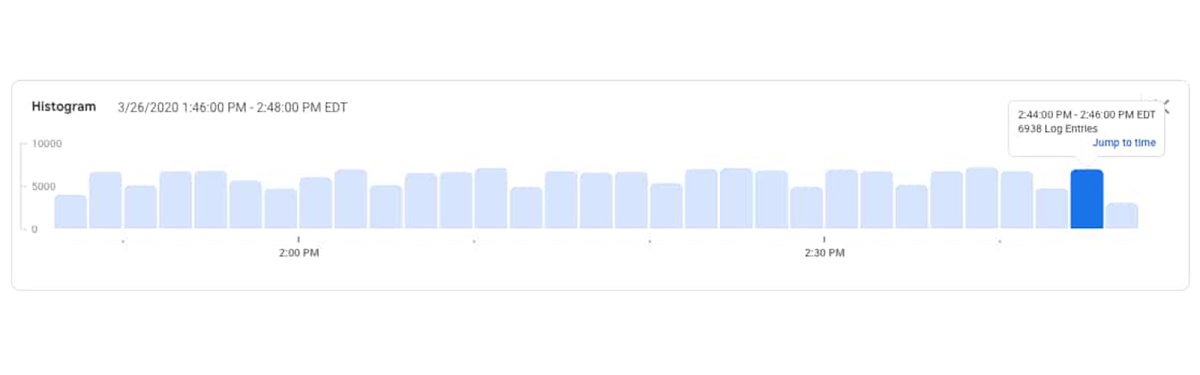
ログ内に recommendationservice によって生成されたエラーは見つかりませんでした。このことから、以前よりも多くの CPU が使用される原因となっているのは、直近のコードデプロイに問題があるからだという疑念を裏付けることができます。この情報を基に対応できます。コンテナ YAML で CPU リクエストを増やすか、recommendationservice の最新のアップデートをロールバックして、サービス担当の開発者に連絡し、CPU 使用率の増加を確認します。具体的な対応策は、当該のコードと直近のデプロイについてどれほど知っているか、組織とポリシーによって異なります。いずれにしても、Cloud Logging と Cloud Monitoring を使用して、有害なイベントがないか引き続きクラスタをモニタリングできます。
Cloud Logging、Monitoring、GKE について学ぶ
GKE のロギング機能とモニタリング機能を Cloud オペレーションに組み込んで、アプリのモニタリング、アラート送信、分析を簡単に行えるようにしました。まだご利用になっていない場合は、GKE で Cloud Logging の使用を開始して、Google のメーリング リストのディスカッションにぜひご参加ください。皆様からのフィードバックをお待ちしております。
- By プロダクト マネージャー Charles Baer、ソリューション アーキテクト Xiang Shen
