強く求められるスピード: HPC ワークロードに C2 マシンを使用
Google Cloud Japan Team
※この投稿は米国時間 2020 年 11 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウドは、ハイ パフォーマンス コンピューティング(HPC)への新たな可能性の扉を数多く開いています。クラウドでは最新のテクノロジーとさまざまなマシンタイプ(VM)を利用できますが、すべての VM が HPC ワークロードの要求に適しているわけではありません。
そこで、Google Cloud のコンピューティング最適化(C2)マシンは、特にコンピューティング負荷の高いワークロードのニーズに応えるために設計されました。具体的には、科学技術計算、CAE(コンピュータ支援エンジニアリング)、生物科学、EDA(電子設計自動化)分野の HPC アプリケーションなどの分野に適しています。
C2 は、第 2 世代の Intel® Xeon® スケーラブル プロセッサを基盤にして、最大 60 個の仮想コア(vCPUs)と 240 GB のシステムメモリを搭載しています。3.8 GHz の持続的な周波数で動作する C2 は、一般的なアプリケーション向けだった前世代の VM と比べて、パフォーマンスが 40% 以上改善されています。前世代の各 VM との比較で、総メモリ帯域幅は 1.21 倍、vCPU ごとのメモリ帯域幅も 1.94 倍となりました。1ここでは、Google Cloud での HPC ワークロード向け C2 VM について詳しくご紹介します。
リソースの分離
密結合な HPC ワークロードは、リソースの分離に依存して予測可能なパフォーマンスを実現します。C2 は、共有された物理リソース(CPU キャッシュ、メモリ帯域幅など)の分離とマッピングの一貫性を実現するために構築されました。その結果、変動性が低下し、パフォーマンスの一貫性が改善されました。また、C2 では、比較的大きなサイズの VM の CPU パワーの状態を公開し、ユーザーが明示的に制御できるようにして(C ステート)、有効な周波数とパフォーマンスを高めています。
NUMA ノード
Google Cloud は、ハードウェアの改善に加え、C2 インスタンスでの HPC に特化した最適化を数多く可能にしました。多くの場合、密結合な HPC アプリケーションでは、プロセスが物理コアに最も近いメモリにアクセスするよう、プロセスやスレッドを物理コアに慎重にマッピングする必要があります。C2 は、ゲスト オペレーティング システム(OS)に NUMA ドメインの明示的な可視性と制御を提供して、パフォーマンスを最大化します。
AVX-512 をサポート
第 2 世代の Xeon プロセッサは、データの並列処理用として Intel Advanced Vector Extension 512(Intel AVX-512)をサポートしています。AVX-512 命令は、SIMD(シングル インストラクション マルチプル データ)命令であり、より広範なレジスタによって、1 つの命令に 64 個の単精度(または 32 個の倍精度)浮動小数点演算をまとめることができます。つまり、それぞれのクロック サイクルでより多くの処理を行えるため、全体的な実行時間が短縮されます。また、第 2 世代の Xeon プロセッサの最新世代 AVX-512 命令には、DL Boost 命令が含まれます。DL Boost 命令は 3 つの INT8 命令を 1 つに組み合わせて AI 推定のパフォーマンスを大幅に高めるため、コンピューティング リソースの使用率の最大化とキャッシュの利用率の向上を実現し、帯域幅のボトルネックを避けることができます。
低レイテンシ
HPC ワークロードは、多くの場合、完了するまでの時間を短縮するため複数のノードにスケールアウトします。Google Cloud の C2 では、「コンパクト プレースメント ポリシー」が有効になりました。これにより物理的に近い位置に設置された vCPU を最大 1,320 個まで割り振り、ノード間のレイテンシを最小限に抑えます。コンパクト プレースメントは、Intel MPI ライブラリとともに、HPC アプリケーションのマルチノード スケーラビリティを最適化します。マルチノード ワークロードでの低レイテンシを実現するためのベスト プラクティスについて詳しくは、こちらをご覧ください。
開発ツール
ハードウェアの最適化に加えて、Intel は包括的な開発ツールスイート(パフォーマンス ライブラリ、Intel コンパイラ、パフォーマンス モニタリング ツール、パフォーマンス チューニング ツールなど)を提供しています。これにより、最新のベクトル化、マルチスレッド処理、マルチノードの並列化、メモリ最適化の技術を活用して、コードの作成とモダナイゼーションを容易に行えます。Intel の Parallel Studio XE の詳細については、こちらをご覧ください。
まとめ
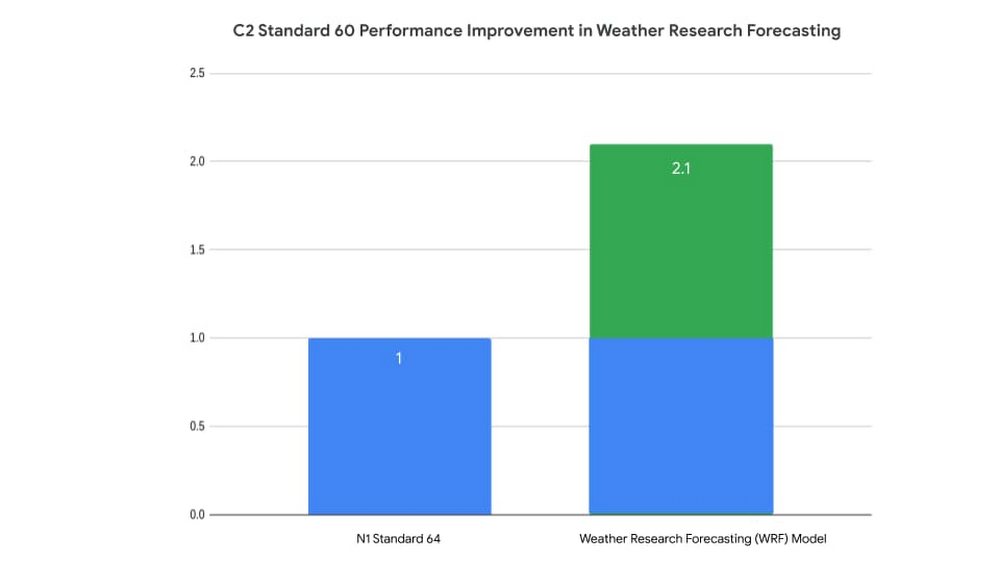
ハードウェアの改善と Google Cloud スタックで行われた最適化により、ほぼ同サイズの VM2 の HPC ワークロードに対する C2 VM のパフォーマンスは、前世代の N1 と比べて最大 2.1 倍改善されました。
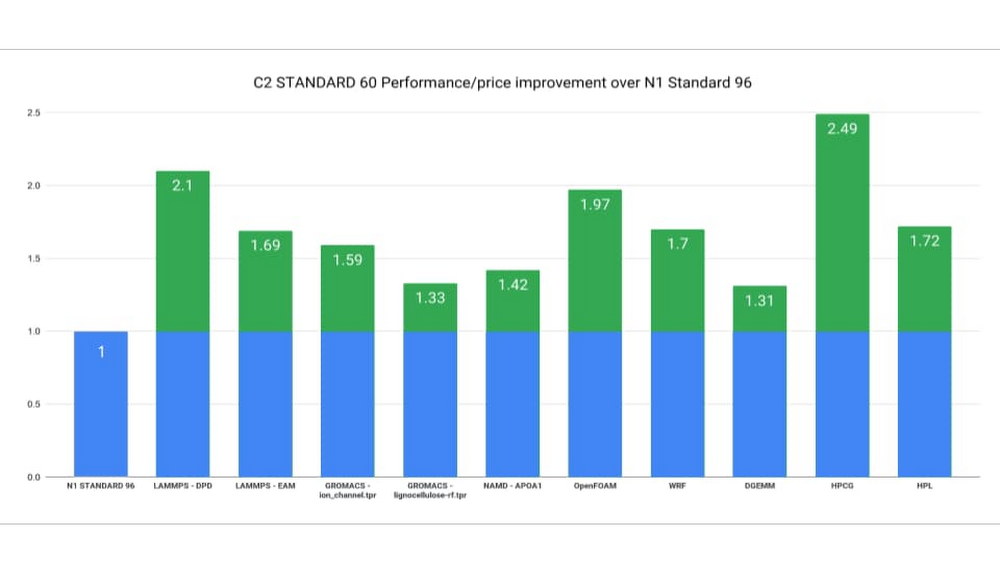
多くの場合、HPC アプリケーションは、フルノードまでスケールアップできます。単一の C2 ノード(60 vCPU および 240 GB)のパフォーマンスと料金は、単一の N1 ノード(96 vCPU および 360 GB)と比較して最大 2.49 倍優れています。3
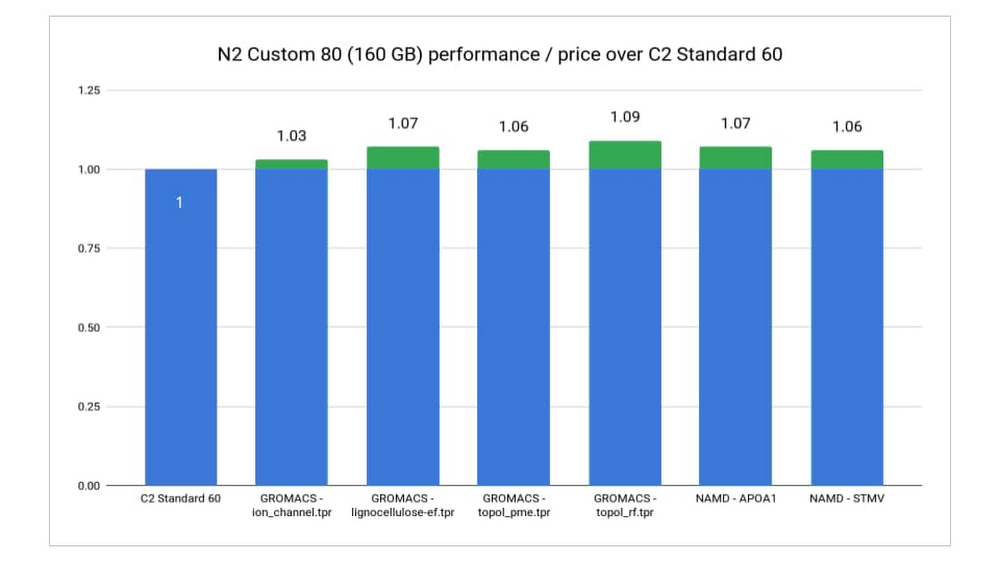
C2 は、定義済みのシェイプで提供されます。これは一般的な HPC ワークロードに最適な vCPU とメモリ構成を提供するためです。また、カスタム VM シェイプにより、パフォーマンスまたはパフォーマンスと料金をさらに改善できる場合もあります。たとえば、ある特定のワークロードで、C2 の標準的な 60vCPU VM のデフォルトである 240 GB より少ないメモリが必要であることがわかっている場合は、少ないメモリによるカスタムの N2 マシンで、より低コストでほぼ同じパフォーマンスを実現できます。Google は、複数の一般的な HPC ワークロードのニーズに合わせて VM シェイプを調整することで、最大 1.09 倍優れたパフォーマンスと料金を実現しました。4
使ってみる
クラウドのアジリティと柔軟性のメリットを活用する HPC ワークロードが増加するなか、Google Cloud と Intel は、こうしたワークロード特有のニーズに最適化したソリューションを共同で開発しています。Intel の第 2 世代 Xeon プロセッサと Google Cloud での最新の最適化により、C2 VM は、Google Cloud で HPC アプリケーション実行するのに最適なソリューションを提供すると同時に、お客様固有のビジネスニーズに合わせて自由な構築と進化が可能です。このため、高パフォーマンスを必要とするお客様の多くは、予想どおり C2 VM にワークロードを移行されました。
C2 および第 2 世代の Intel Xeon スケーラブル プロセッサについて詳しくは、営業担当者にご相談いただくか、こちらから直接お問い合わせください。また、今週開催される SC20 にご参加の際は、ぜひ Google の仮想ブースにお越しください。セッションの視聴やリソースへのアクセスに加え、Google の HPC エキスパートとチャットでお話いただけます。
1. STREAM Triad Best Rate のベンチマークを使用した c2-standard-60 と n1-standard-96 マシンタイプの内部分析に基づく。
2. Weather Research Forecasting(WRF)のベンチマークを使用した c2-standard-60 と n1-standard-96 マシンタイプの内部分析に基づく。
3. High Performance Conjugate Gradients(HPCG)のベンチマークに基づき、C2-standard-60($3.1321/時)と N1-standard-96($4.559976)の Google Cloud VM インスタンス料金を分析(2020 年 10 月 15 日時点)。
4. GROMACS および NAMD のベンチマークに基づき、Google Cloud VM インスタンス料金を 160 GB のメモリを備えた N2-custom-80($3.36528)と C2-standard-60($3.1321/時)で分析(2020 年 10 月 15 日時点)。
-HPC チーフ テクノロジスト Bill Magro
-Intel クラウド テクノロジー担当 Shideh Shahidi

