新しい非同期レプリケーションを活用した、障害からのデータ保護
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
今日のビジネス環境において最も重要なのは、データの可用性と完全性です。自然災害によるものか人災かを問わず、障害は業務を中断させ、重要な情報にとって大きなリスクとなります。
これに対処するため、Google はこのたび、Persistent Disk(PD)非同期レプリケーションを導入しました。Persistent Disk 非同期レプリケーションは、Google Cloud リージョン間でデータを複製することにより Compute Engine ワークロードの障害復旧を可能にし、1 分未満の目標復旧時点(RPO)と短い目標復旧時間(RTO)を実現します。
このソリューションの設計の核となっているのはシンプルさです。レプリケーションは数回の API 呼び出しで管理されます。必須の VM エージェント、専用のレプリケーション VM、サポート対象のゲスト オペレーティング システムの制約、ワークロードのパフォーマンス オーバーヘッドなどはありません。PD 非同期レプリケーションはブロック インフラストラクチャ レベルで機能し、障害からデータを保護する高速かつ共通のインフラストラクチャ基盤を提供します。また、簡単にオンボーディング、オペレーション、モニタリングができるよう設計されていて、ディスク クローン、リージョン ディスク(同期レプリケーション)、スナップショットなど、他のデータ保護形態と組み合わせて使用することも可能です。レプリケーションは、ワークロードを実行しているリージョンのプライマリ ディスクから、セカンダリ リージョンに作成したリカバリ ディスクに対して直接実行されます。
「Persistent Disk 非同期レプリケーションは、インフラストラクチャ ベースの障害復旧に欠かせない強固な基盤をもたらすだけでなく、低 RPO / RTO のデータ保護に対する規制要件を満たせるようサポートしてくれます。また、DR テスト、フェイルオーバー、フェイルバックというライフサイクル全体に対応しています。」 - Intesa Sanpaolo、Cloud Center of Excellence 責任者 Nicola Carotti 氏
レプリケーションの設定
既存の PD ディスクで PD 非同期レプリケーションを有効にするには、API、gcloud、または Google Cloud コンソールで 2 つの呼び出しを実行します。まず、保護するプライマリ ディスクを参照する空のディスクを、セカンダリ リージョンで新規作成します。次に、セカンダリ ディスクを参照するプライマリ ディスクから、レプリケーションを開始します。この時点から、データはディスク間で自動的に複製されます。ディスクの変化率にもよりますが、RPO は通常 1 分未満です。この設定ワークフローでは、両方のリージョンで明示的な操作が行われるまで、データは転送されません。また、PD 非同期レプリケーションを使用するためにネットワークを再構成する必要もありません。
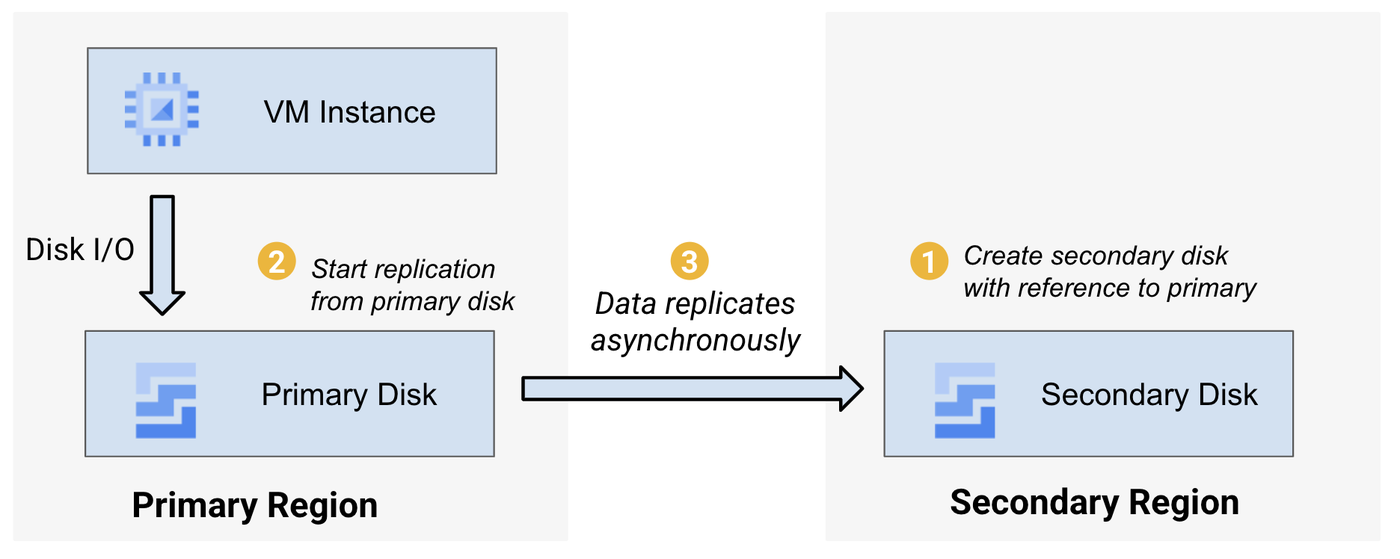
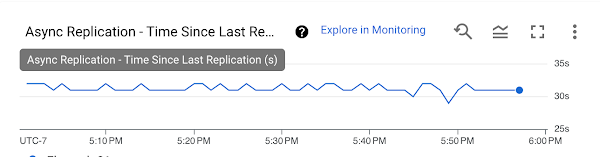
PD 非同期レプリケーションが実行されると、前回レプリケーションが行われてからの時間と送信されたネットワーク データ量を Cloud Monitoring で確認できます。プライマリ リージョンで障害が発生したか、フェイルオーバーをいつ開始するかの判断は、ワークロードの責任を負う運用チームが行います。フェイルオーバーを開始するには、ディスク間のレプリケーションを停止し、セカンダリ ディスクをセカンダリ リージョンの VM にアタッチします。この作業は数分で完了できます。前回セカンダリ リージョンにフェイルオーバーしてからのワークロードをプライマリ リージョンに復元するには、プライマリ リージョンに新しいレプリケーション ペアを作成して、ワークロードをフェイルバックできるようにします。リージョンの異なるデータセンター間でデータを複製することにより、自然災害のような地域的な出来事によって生じる局地的な障害からデータを保護可能な、復元力のあるデータレプリカを作成できます。
複雑なステートフル ワークロードには整合性グループを使用
ワークロードの依存データが複数のディスクや VM インスタンスに分散している場合、整合性グループによって依存データを調整管理することができます。PD 非同期レプリケーションで整合性グループを使用すると、グループ内のすべてのディスク間でレプリケーション期間が自動的に同期され、アトミックなデータ レプリケーションの同時実行が可能になります。これにより、プライマリ ディスクとセカンダリ ディスクの間でデータの整合性が確保され、障害が発生してもワークロードを復元させることができるようになります。
障害復旧のテスト
実際に障害が発生したときに復旧手順が確実に機能するよう、セカンダリ リージョンで定期的にテストを行うことをおすすめします。PD 非同期レプリケーションを中断したり切断したりしなくても、整合性グループを適用したセカンダリ ディスクを一括クローニングすれば、新しいデータを受信しながらテストできます。
高可用性と障害復旧のためのデプロイ
リージョン Persistent Disk(リージョン PD)と PD 非同期レプリケーションは、高可用性(HA)と障害復旧の両方を必要とするワークロードに対し、組み合わせて使用するよう設計されています。リージョン PD をプライマリまたはセカンダリの非同期ディスクとして構成すると、プライマリまたはセカンダリ リージョンのゾーンディスクと組み合わせて動作させることができます。リージョン PD が構成に使われているプライマリ リージョンの 1 つのゾーンだけで障害が発生した場合、ディスクは残りの正常なゾーンからセカンダリ リージョンへのレプリケーションを継続します。PD 非同期レプリケーションは 2 つの異なるディスク間で設定されますが、個々のリージョン PD は 2 つのゾーンにデータを格納し、2 つのゾーンにアタッチできる単一のディスクであることにご注意ください。
HA および DR 対策の強化
PD 非同期レプリケーションと整合性グループを活用することで、企業は堅牢なデータ保護機能と復旧機能を手に入れることができます。このアプローチは、重要なデータを障害から守り、ダウンタイムを最小限に抑え、データの整合性を維持して、フォールト トレランスを強化するのに役立ちます。非同期レプリケーションと整合性グループを活用すれば、不測の障害に直面してもデータへの継続的なアクセスが可能な、復元力のあるプラットフォームを構築できます。
PD 非同期レプリケーションには、コンソール、Compute Engine API、gcloud ツール、Terraform、Cloud Monitoring からアクセスできます。詳しくは、一般公開ドキュメントをご確認ください。
- エンジニアリング マネージャー Dengkui Xi
