InstaDeep による、Cloud TPU でのスケーラブルな強化学習

Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
AI の長期的な目標は、現実の複雑な問題を解決することです。強化学習(RL)は、環境と対話することで報酬を最大化し、最適な意思決定を学習する ML アルゴリズムの一種であり、インテリジェンスへの道において大きな貢献をしてきました。
強化学習の最初の画期的な成果はビデオゲームの世界で生まれました。囲碁、StarCraft 2、Dota2 などのゲームの世界チャンピオンが RL ベースのシステムに敗北したことがその例です。最近では、強化学習により、成層圏気球の航行、核融合炉のトカマクプラズマの制御、さらには AlphaDev による新しいアルゴリズムの発見など、現実世界で目覚ましい偉業が成し遂げられています。
このような顕著な成功がありながら、RL は現実世界の用途にはまだ広く採用されていません。主な要因の一つはエンジニアリング上の課題です。高性能の RL モデルには、多くの場合、大規模なシミュレーションと意思決定プロセスのトレーニングが必要です。たとえば、OpenAI Five は、10 か月にわたって毎秒 100 万フレームの速度で数千の GPU を使用するという、前例のない規模でトレーニングされました[1]。これにより、最終的に Dota 2 での優れたパフォーマンスが実現しました。これらの結果は、PaLM 2 の成功の裏で、自然言語処理とコンピュータ ビジョンで最近発見されたスケーリングの法則を反映しています。実際、「スケール」は AI の分野で成功を収めるために不可欠な要素となっています。
この記事では、Cloud TPU のスケーリング機能と、研究と産業の両面における、強化学習のワークロードに対する Cloud TPU の変革的な影響について詳しく説明します。特に Cloud TPU は、InstaDeep の AI 駆動プリント基板(PCB)設計製品である DeepPCB の背後にいる AI エージェントの改善において極めて重要な役割を果たしました。TPU により、スループットが 235 倍向上し、トレーニング費用が 90% 近く削減されたのです。TPU はコスト効率が高いだけでなく、AI エージェントの長期的なパフォーマンスを向上させました。その結果、DeepPCB によって生成されるルーティングの品質が向上し、ユーザーの全体的なエクスペリエンスが向上しました。
強化学習をスケーリングする
RL エージェントは、シミュレートされた環境で行動し、外部の例やガイダンスなしで問題を解決する方法を発見することで学習します。この試行錯誤のプロセスは、RL トレーニング インフラストラクチャが、膨大な数のエージェントと環境の相互作用をシミュレートし、収集した経験に基づいてエージェント(多くの場合はニューラル ネットワーク)を更新する必要があることを意味します。
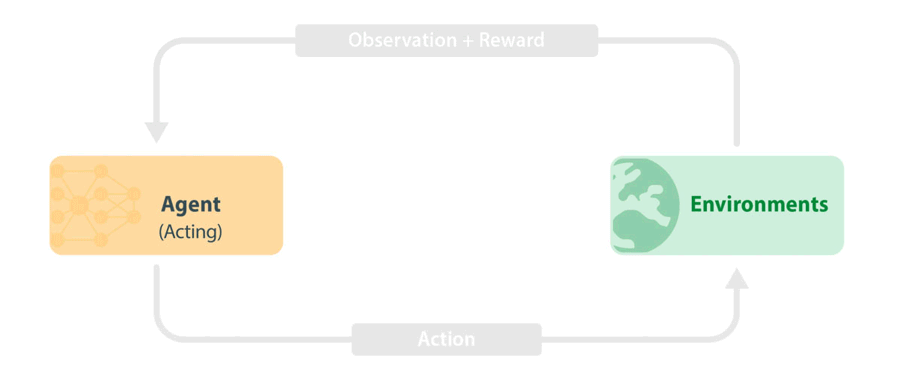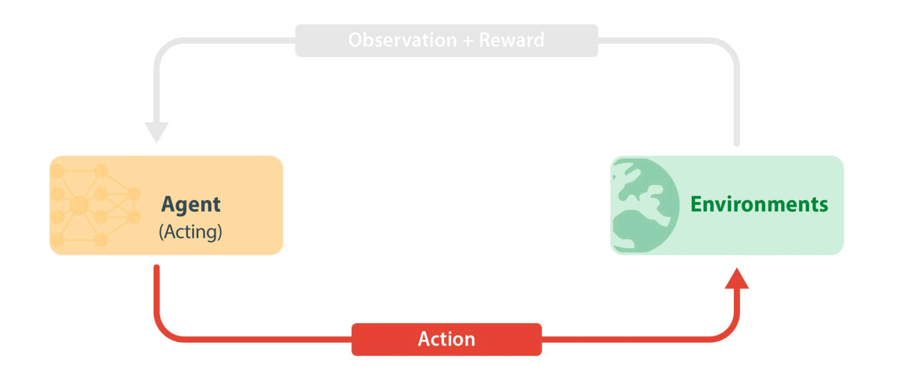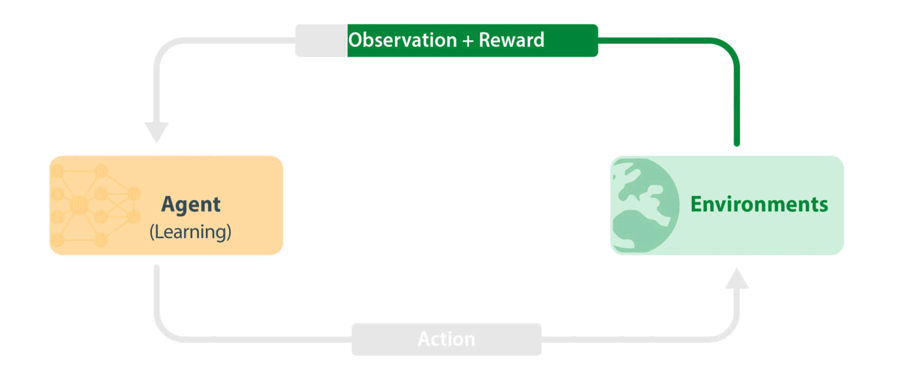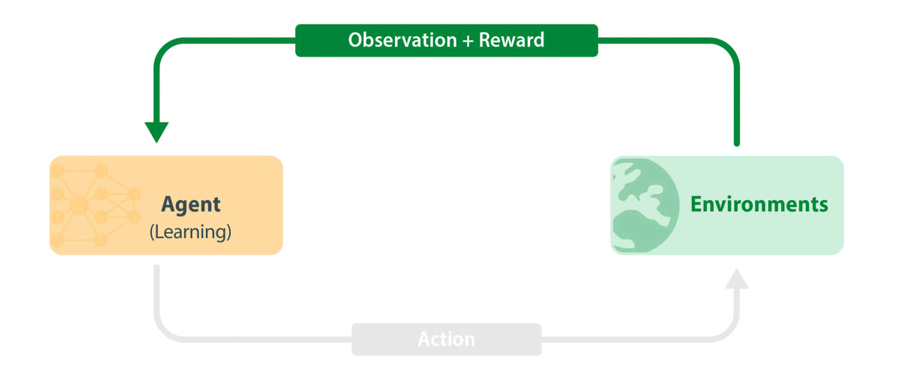
図 1: 標準的な RL トレーニング ループ。エージェントは環境から最新の情報(観察と報酬)を取得し、これを使用して次のアクションを選択します。アクションは環境に渡され、シミュレーションの次のステップが実行されます。新しい情報はエージェントに戻され、エージェントは観察と報酬から学習します。
データ収集のスループットを向上させるために、複数の手法が採用されています。よく利用されている手法では、エージェントを、環境を通じてデータの生成と収集を担当する「実行者」と、実行者のデータを使用してエージェントを更新する担当の「学習者」に分けます。このアーキテクチャにはさまざまなバリエーションがあり、それぞれに明確な長所と短所があります。たとえば、SEED-RL は集中型の推論設計に注力しており、バッチ推論と学習のためにハードウェア アクセラレータを共有します。これにより、SEED-RL はモデル取得の通信オーバーヘッドを削減でき、ハードウェア アクセラレータを利用して動作推論を高速化できます。もう一つのアーキテクチャである Menger は、局所的な推論に注力した別のアプローチを採用しています。データを生成するために、実行者は CPU のプール全体で複製され、そのデータがシャーディングされた再生バッファを通じて学習者に提供されます。これにより、観測の大規模なバッチを集中サーバーに送信するオーバーヘッドが除去されます。ただし、モデルの更新を CPU ベースの実行者に送信するという費用は発生します。
全体としては、RL システムの効率は、ハードウェアの導入と切り離すことができないということです。効果的な分散アーキテクチャでは、利用可能なハードウェア(アクセラレータの種類、接続性、プロセッサのクロック速度、共有メモリアクセスなど)、環境の複雑さ(シミュレーション時間など)、アルゴリズム自体(オン / オフのポリシーなど)といった複数の要素を考慮する必要があります。コンピューティング効率を最大化するために、システムは、データ通信、リソース使用率、およびアルゴリズムの制約のバランスをとるという困難なタスクに対処する必要があります。
Google Cloud TPU とは
Tensor Processing Unit(TPU)とは、大規模な ML モデルのトレーニングなど、大規模な高性能コンピューティング アプリケーション向けに設計された、専用の AI アクセラレータです。最新のニューラル ネットワーク計算を支えるテンソル演算を高速化するように設計された、最適化されたドメイン固有のアーキテクチャが、TPU の特徴です。これには、高メモリ帯域幅、高密度線形代数用の専用行列処理ユニット(MXU)、およびスパースモデルを高速化するための特殊なコアが含まれます。
TPU Pod は、相互接続された TPU チップのクラスタです。これらは、チップ間のスムーズな通信とデータ共有を可能にする高速相互接続を活用し、膨大な並列処理と計算能力を提供するシステムを構築します。Google の TPUv4 Pod は、チップを最大 4,096 個組み合わせることができ、1.1 ExaFLOPS という驚異的なピーク パフォーマンスを実現します[2]。TPU v4 は、4,096 個のチップクラスタを動的に構成してより小さな TPU スライスを提供する、光回線スイッチ(OCS)も搭載しています。さらに、データセンター インフラストラクチャに対する Google の統合アプローチにより、TPU は従来の施設で実行される他のドメイン固有アーキテクチャ(DSA)よりも 2~6 倍エネルギー効率が高く、炭素排出量を最大 20 倍削減できます[2]。
Cloud TPU を使用して強化学習をスケールする
TPU Pod は、RL システムのスケーリングにおける特有の課題に対して、革新的なソリューションを提供します。高度に相互接続されたアーキテクチャと特殊なコアにより、従来の RL アーキテクチャのような追加のオーバーヘッドを発生させることなく、高速なデータ転送と並列処理が可能になります。そのようなアプローチの一つは、Podracer で導入された Sebulba アーキテクチャです。これは、実行者と学習者の分離を利用してエクスペリエンスを効率的に生成します。Sebulba アーキテクチャは、任意の環境をサポートし、単一の TPU マシン上の同じ場所で実行と学習を行い、TPU リソースの使用率を最大化するように設計されています。
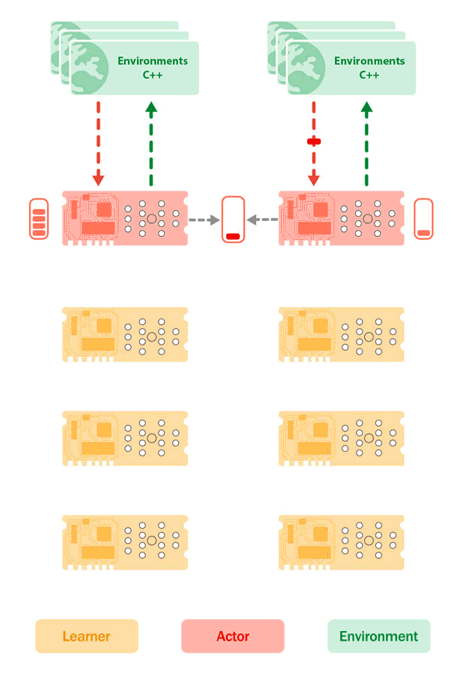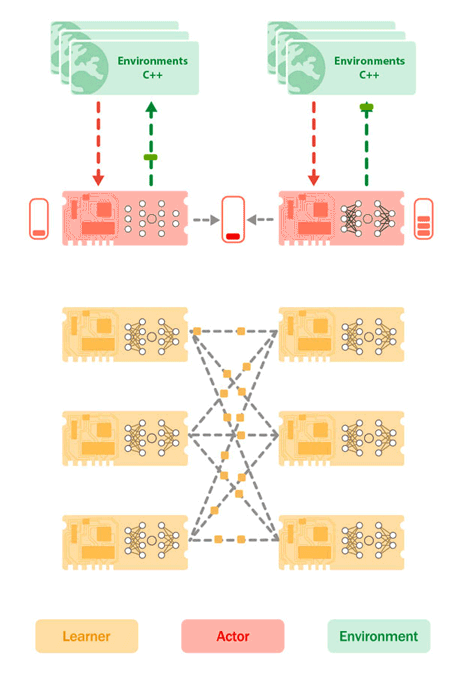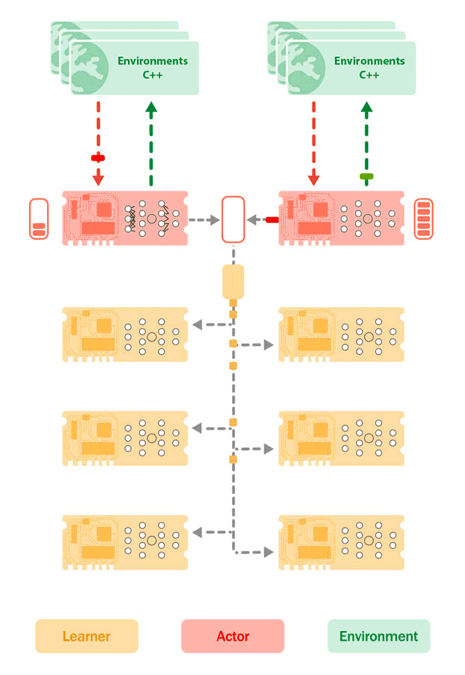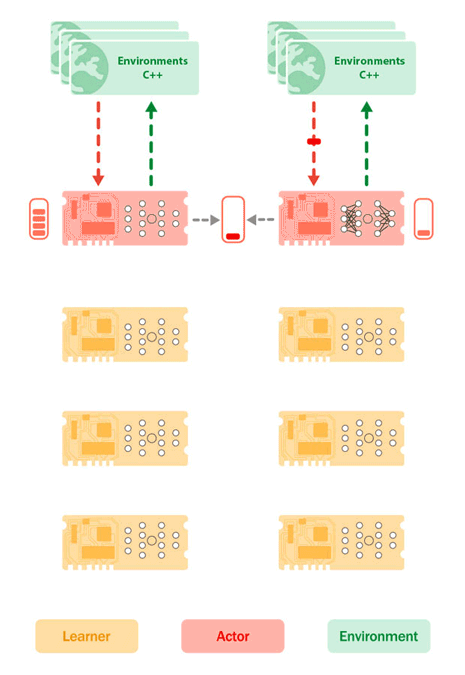
図 2: TPU 上の学習者コア(黄色)と実行者コア(赤色)の配置と、ホスト CPU 上の環境(緑色)を示す Sebulba アーキテクチャ。環境は、その観察と報酬を実行者コアに送信し、実行者コアは次に実行するアクションをレスポンスとして送信します。そうすることで、実行者は軌道のバッファを構築します。同時に、学習者は実行者のバッファから軌跡のバッチを pull し、学習の更新を実行して、新しいモデル パラメータを実行者デバイスに push します。
Sebulba は、1 台のマシンで利用可能な 8 つの TPU コアを実行者と学習者の 2 つのグループに分割します。実行には、学習プロセスの経験を生み出すために、環境のバッチとの対話を伴います。Sebulba はこの目的のために複数の Python スレッドを使用し、各スレッドが環境のバッチを担当します。これらのスレッドは並行して実行され、観察のバッチを TPU コアに送信し、TPU コアが次のアクションを選択します。環境は、Python の Global Interpreter Lock(GIL)の影響を最小限に抑えるために、C++ スレッドの共有プールを使用して段階的に実行されます。環境が段階的に実行されている間、TPU コアがアクティブであることを保証するために、各実行者コアに複数の Python スレッドが使用されます。
Sebulba の学習パートには、実行者によって生成された経験を処理して、エージェントの意思決定を改善することが含まれます。各実行者スレッドは、固定長の軌道のバッチを TPU コア上に蓄積し、それをより小さなシャードに分割し、高速なデバイス間通信チャネルを通じて学習者コアに送信します。続いて、ホスト上の単一の学習者スレッドが、すでに学習者コア全体に分散されているデータを処理します。JAX の「pmap」オペレーションを使用して、各学習者コアは経験のシャードに更新関数を適用します。パラメータ更新は、JAX の「pmean/psum」プリミティブを使用してすべての学習者コア間で平均化され、学習者コアの同期が維持されます。各更新の後、新しいパラメータが実行者コアに送信され、実行者スレッドが次の推論ステップで最新のパラメータを使用できるようになります。
Sebulba アーキテクチャは、スケーリング時に直面するエンジニアリングのボトルネックの多くに対処できるため、大規模な RL に最適です。
- 通信オーバーヘッドの削減: Sebulba は、同じ TPU 上の同じ場所に実行と学習を配置し、高速なデバイス間通信と組み合わせることで、パラメータの更新や収集したデータの学習者への送信などのデータ転送に関連する一般的なボトルネックを最小限に抑えます。
- 高度な並列化: Sebulba アーキテクチャは TPU の並列処理機能を活用しつつ、C++ 環境のプールによって補完されます。これにより、Sebulba は複数の環境を同時に効率的に処理できるようになります。環境からの軌跡データと学習ステップの両方を同時に処理することで、強化学習プロセス全体が大幅に高速化されます。
スケーラビリティ: Sebulba アーキテクチャは、スケールできるように設計されています。RL タスクの要求が厳しくなるなかで、Sebulba はより大規模な TPU 構成に簡単に適応し、現実世界のアプリケーションへの道を開きます。
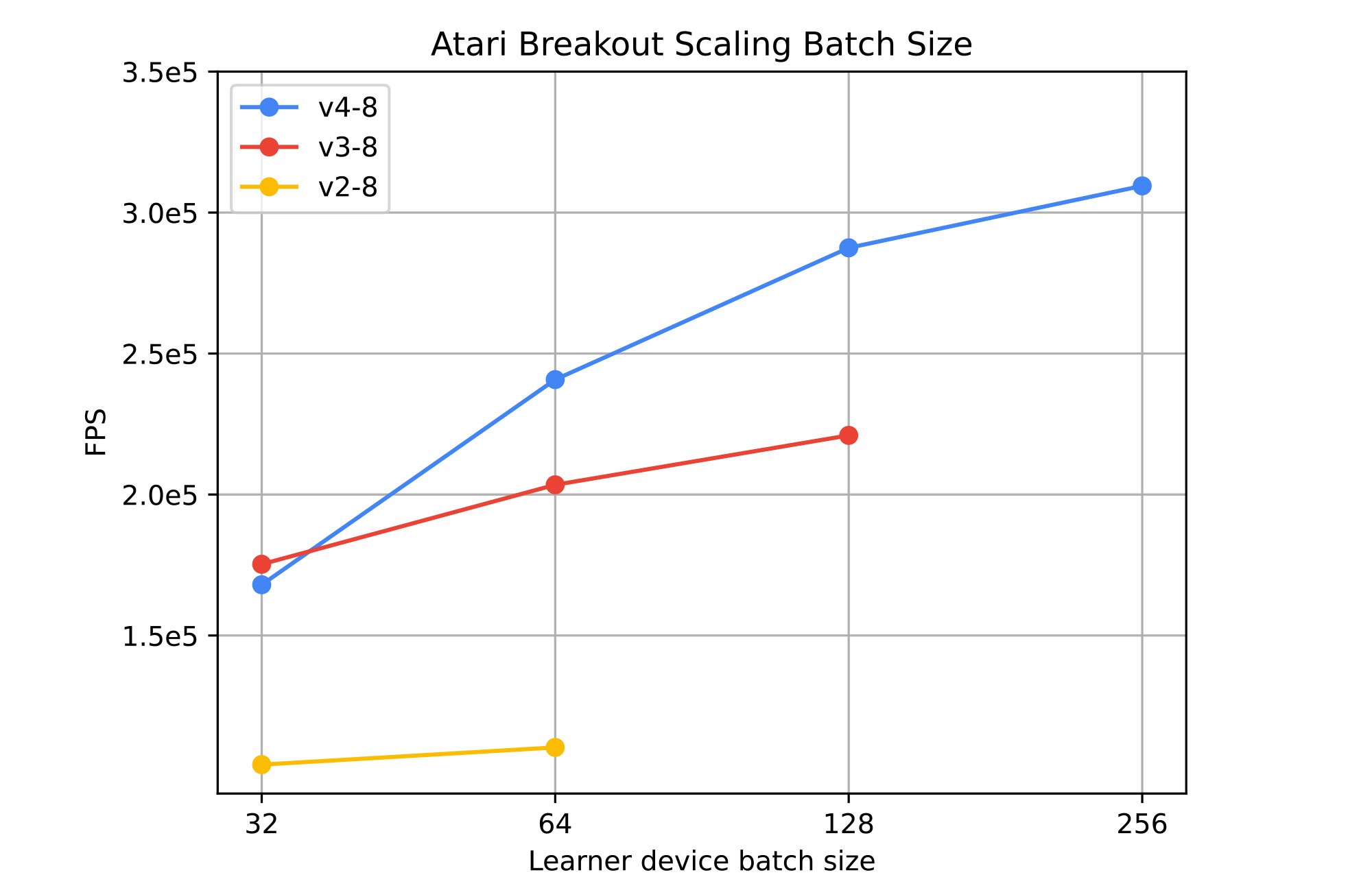
図 3: TPU v2(黄色)、v3(赤色)、および v4(青色)全体でバッチサイズを 32~256 の範囲にスケーリングした場合の影響。(出典: InstaDeep ベンチマーク: 2023 年 8 月 7 日)
業界でよく採用されている PPO アルゴリズムを使用して、古典的な Atari ベンチマークでアーキテクチャをテストしました。図 3 は、Sebulba がさまざまな Cloud TPU 世代にわたって到達する 1 秒あたりのフレーム数(FPS)を示しており、単一の TPUv4 で最大 300,000 FPS を超えます。バッチサイズを大きくすると、エージェントのスループットは一貫して向上しますが、スケールするにつれて収穫逓減が発生します。利用可能なオンチップ メモリが制限要因になる場合があります。以前の世代の TPU では、大きなバッチサイズ(たとえば TPU デバイスあたり 256)をサポートしていません。
Sebulba アーキテクチャのシンプルさにより、TPU Pod 全体にわたって単一ノード構成を複数回複製することができ、スムーズなスケーリングが可能になります。以前と同様に、各レプリカは、推論には実行者コアを、Pod のスライスで生成された軌道を処理するためには学習者コアを使用して、独自の環境プールをステップ実行します。唯一の違いは、モデル パラメータを更新するために計算された勾配が、JAX の集合的な操作を使用して、個々の TPU 内だけでなく TPU Pod 全体のすべての学習者コア間で同期されることです。
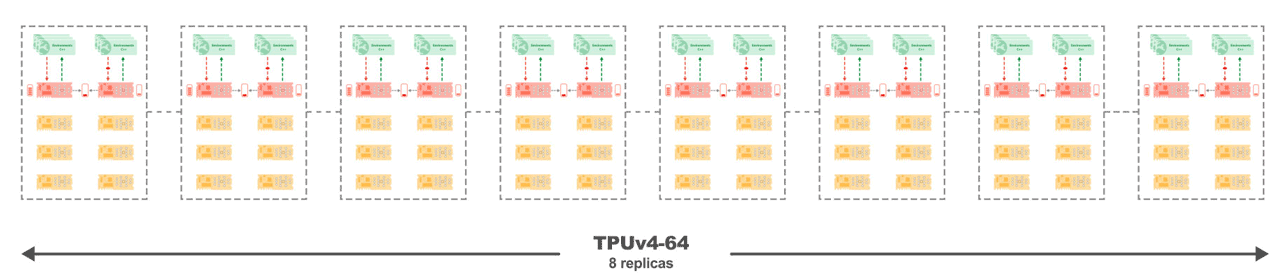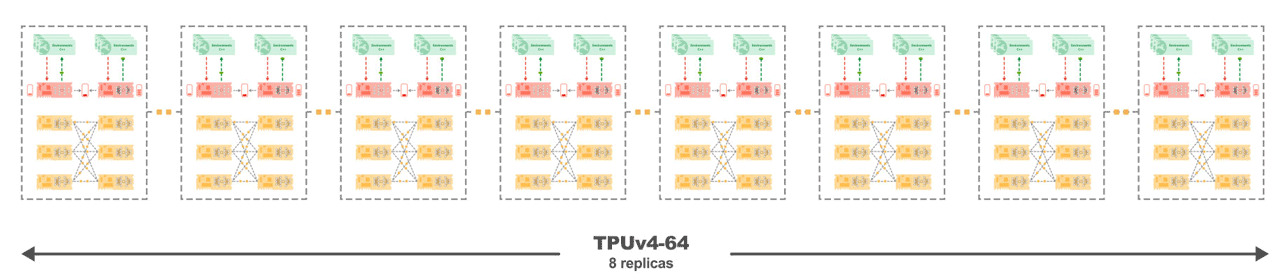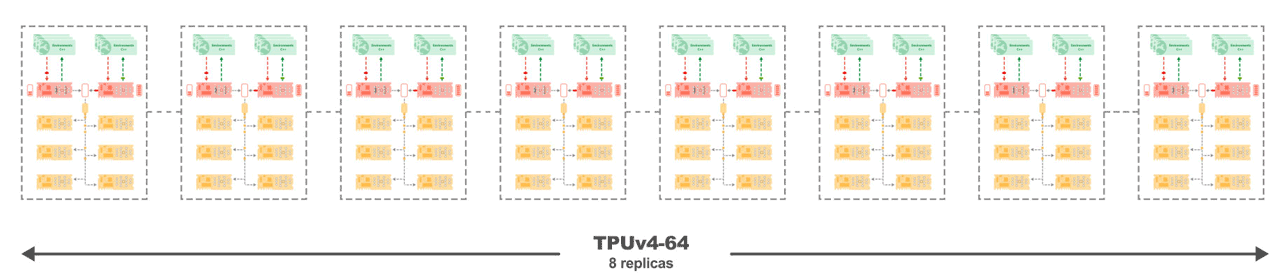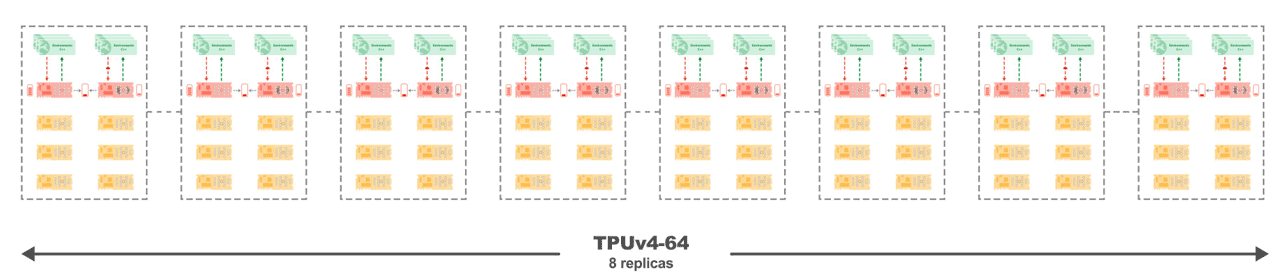
図 4: 8 つのレプリカのそれぞれのコアが高速インターコネクトで接続されており、線形スケーリングが可能な、TPUv4-68 上の Sebulba。
実験では、Sebulba アーキテクチャのスケーリング特性と TPU の通信効率が確認されており、ほぼ完璧なスケーリング係数 0.998 を達成しています。図 4 に示しているように、TPU コアの数を増やすと、TPUv4-128 を使用した場合、Atari ベンチマークで 343 万 FPS という驚異的な値に達します。
Sebulba の拡張機能により、収束が高速化するだけでなく、データの生成と処理の能力も向上し、システムの有効なバッチサイズを拡張できます。図 5 は、この利点による実際の効果を示しています。レプリカ数を増やすと、収束(Breakout のスコア 400 に到達)するまでの時間が数分に短縮され、最終的なトレーニング スコアが向上します。
これらの結果は、AlphaStar や OpenAI 5 などの主力の大規模 RL プロジェクトで観察されたスケーリングのレベルと一致します。人間レベルのパフォーマンスを超えるには、さらに大量のデータが必要になります。エージェントを拡張する能力を Sebulba が簡素化することで、実験時間を短縮し、全体的なパフォーマンスを向上させ、研究開発を加速できます。
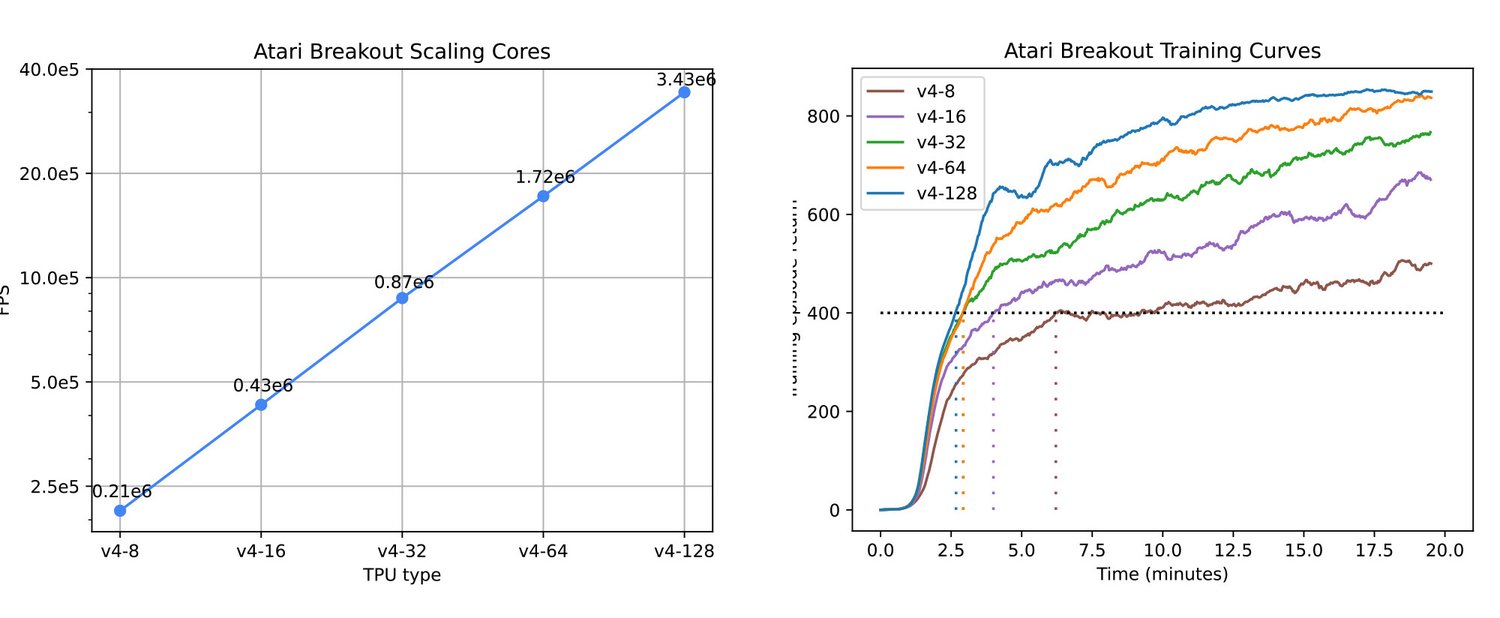
図 5(左): 複数の TPU ホスト上で Atari Breakout で PPO をトレーニングする場合の FPS の線形スケーリング(係数 0.995)。図 5(右): 複数の TPU ホスト上で複製された Atari Breakout での PPO の学習曲線と、収束時間への影響。(出典: InstaDeep ベンチマーク、2023 年 7 月 30 日)
大規模な強化学習による PCB ルーティングの解決
Sebulba とそのスケーリング効率を Cloud TPU 上でさらに評価するため、プリント基板(PCB)の配置配線問題に適用しました。この問題は、製造基準を満たし、デザイン ルール チェック(DRC)に合格しながら、PCB コンポーネントを最適に配線することを目的とする、強化学習タスクとして捉えることができます。InstaDeep は、電気エンジニアが人間の介入なしに PCB を最適に配線できるようにする AI ベースのプロダクト、DeepPCB を開発しました。これを実現するために、同社のプロダクト チームは、強化学習エージェントを効率的にトレーニングする高速シミュレーション エンジンを開発しました。しかし、課題の複雑さと規模によって、一般的に使用される RL ライブラリではトレーニング スループットが不十分です。DeepPCB シミュレータを Sebulba に接続すると、以前の旧型の分散アーキテクチャで実行した場合と比較して、15 倍から 235 倍の加速が観察されました。
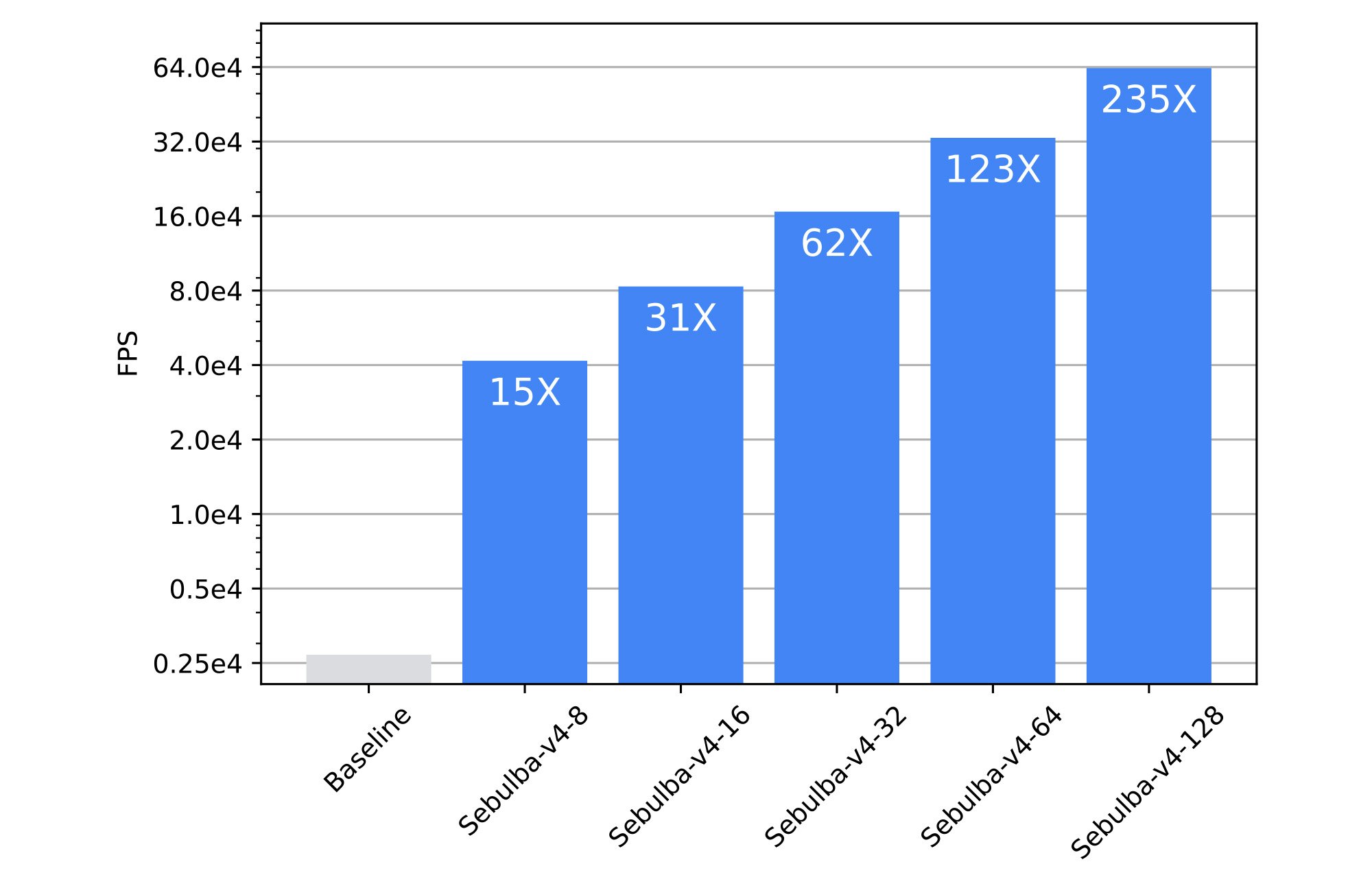
図 6: Sebulba アーキテクチャと以前 DeepPCB に使用されていた旧型システムとのベンチマーク比較。(出典: InstaDeep ベンチマーク、2023 年 8 月 1 日)
図 6 は、DeepPCB に使用されていた以前のベースライン システムと比較して、Sebulba が提供する劇的な高速化を強調しています。Google Cloud Platform でハイエンド GPU を使用する場合、ベースライン システムの完全なトレーニングには約 24 時間かかり、その費用は約 $260 です。Google Cloud TPU の Sebulba アーキテクチャに切り替えれば、費用と時間の両方が削減できます。最適な構成では、トレーニング時間はわずか 6 分に短縮され、費用はわずか $20、13 分の 1 に削減されます。
さらに、Cloud TPU での Sebulba の線形スケーリングとチップあたりの価格が固定されているため、より大きな TPU Pod にスケールアップした場合でもトレーニング費用を一定に保つと同時に、収束までの時間を大幅に短縮できます。実際には、システムサイズを 2 倍にすると時間あたりの料金も 2 倍になりますが、収束までの時間を半分に短縮することで相殺できます。
DeepPCB をケーススタディとして、Cloud TPU が現実世界の意思決定の問題に対して、費用対効果の高いソリューションをどのように提供できるかを見てきました。TPU の可能性を最大限に活用することで、チームの実験速度の高速化、システムのパフォーマンス向上を実現しています。これは研究チーム、エンジニアリング チームにとって非常に重要であり、これまで実現できなかった新しいプロダクト、サービス、研究成果を提供できるようになります。
この投稿と並行して、これらの結果を生み出すために使用されたコードベースをオープンソース化できることを嬉しく思います。これは、強化学習を実際のアプリケーションに統合したいと考えている研究者や業界関係者にとって、良い出発点となります。
参照
1.Christopher Berner、Greg Brockman、Brooke Chan、Vicki Cheung、Przemysław Dębiak、Christy Dennison、David Farhi、Quirin Fischer、Shariq Hashme、Chris Hesse、Rafal Józefowicz、Scott Gray、Catherine Olsson、Jakub Pachocki、Michael Petrov、Henrique P. d.O. Pinto、Jonathan Raiman、Tim Salimans、Jeremy Schlatter、Jonas Schneider、Szymon Sidor、Ilya Sutskever、Jie Tang、Filip Wolski、Susan Zhang(2019)。大規模な深層強化学習を備えた Dota 2。arXiv プレプリント arXiv:1912.06680。
2. Norman P. Jouppi、George Kurian、Sheng Li、Peter Ma、Rahul Nagarajan、Lifeng Nai、Nishant Patil、Suvinay Subramanian、Andy Swing、Brian Towles、Cliff Young、Xiang Zhou、Zongwei Zhou、David Patterson。(2023)。「TPU v4: 組み込み用のハードウェア サポートを備えた、光学的に再構成可能な ML 用スーパーコンピュータ」。arXiv プレプリント arXiv:2304.01433。
-InstaDeep、ソフトウェア エンジニア、Armand Picard 氏
-InstaDeep、シニア リサーチ エンジニア、Donal Byrne 氏

