Google’s Cloud TPU v4 provides exaFLOPS-scale ML with industry-leading efficiency

Norm Jouppi
Google Fellow, Google
David Patterson
Google Distinguished Engineer, Google Research
Editor’s note: Today, two legendary Google engineers describe the “secret sauce” that has made TPU v4 a platform of choice for the world’s leading AI researchers and developers for training machine learning models at scale. Norm Jouppi is the chief architect for all Google’s TPUs, from TPU v1 to TPU v4. He is a Google Fellow and a member of the National Academy of Engineering (NAE). David Patterson, a Google Distinguished Engineer, shared the ACM A.M. Turing Award and the NAE Charles Draper Prize. David is one of the creators of RISC and RAID, and his recent research has been on the CO2e emissions from machine learning.
Scaling computing performance is foundational to advancing the state of the art in machine learning (ML). Thanks to key innovations in interconnect technologies and domain specific accelerators (DSA), the Google Cloud TPU v4 enabled:
a nearly 10x leap forward in scaling ML system performance over TPU v3
boosting energy efficiency ~2-3x compared to contemporary ML DSAs, and
reducing CO2e as much as ~20x over these DSAs in typical on-premise data centers1.
As such, the performance, scalability, efficiency, and availability of TPU v4 make it an ideal vehicle for large language models.
TPU v4 provides exascale ML performance, with 4096 chips interconnected by an internally-developed industry-leading optical circuit switch (OCS). You can see one eighth of a TPU v4 pod below. Google’s Cloud TPU v4 outperforms TPU v3 by 2.1x on average on a per-chip basis and improves performance/Watt by 2.7x. The mean TPU v4 chip power is typically only 200W.

located in Oklahoma, which runs on ~90% carbon-free energy.
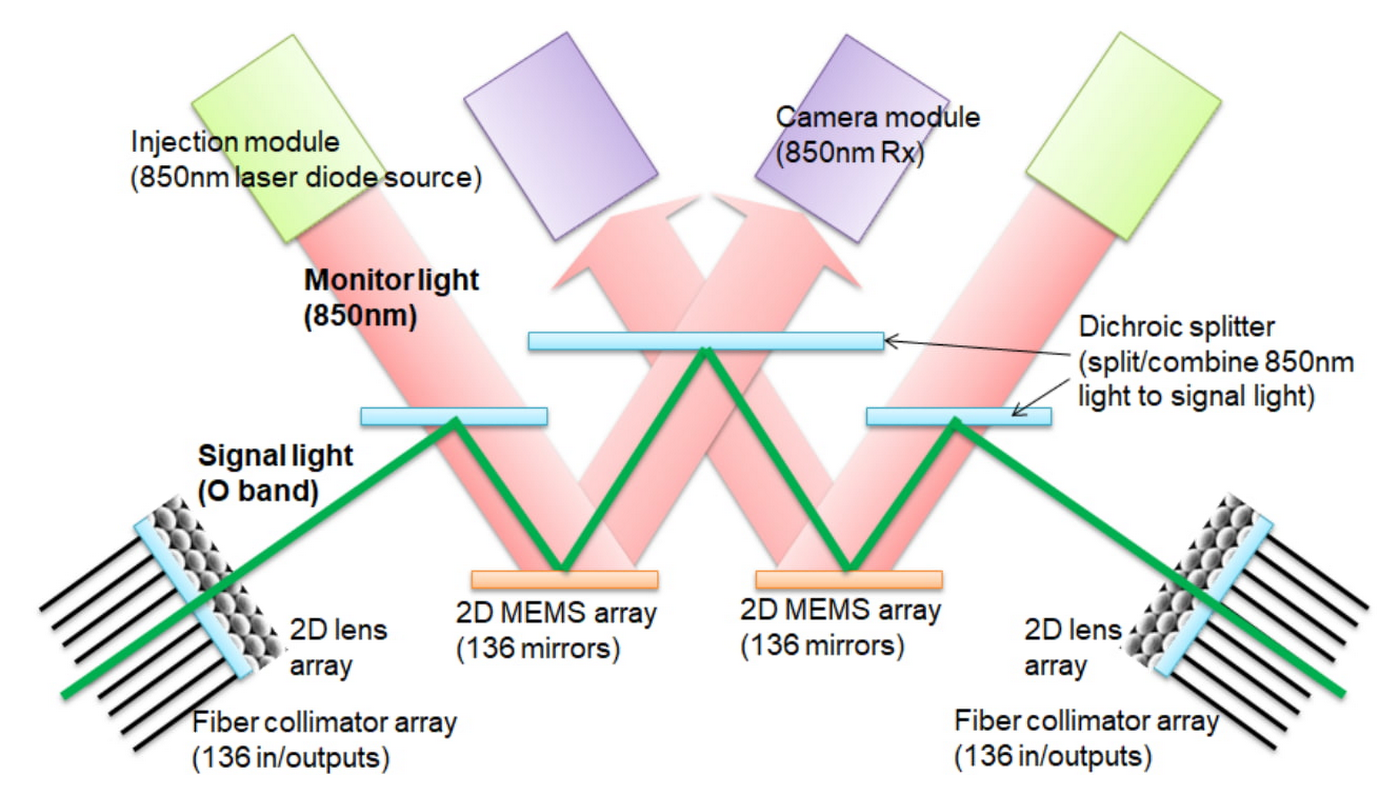
TPU v4 is the first supercomputer to deploy a reconfigurable OCS. OCSes dynamically reconfigure their interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are <5% of TPU v4’s system cost and <5% of system power. The figure below shows how an OCS works, using two MEMs arrays. No optical to electrical to optical conversion or power-hungry network packet switches are required, saving power.
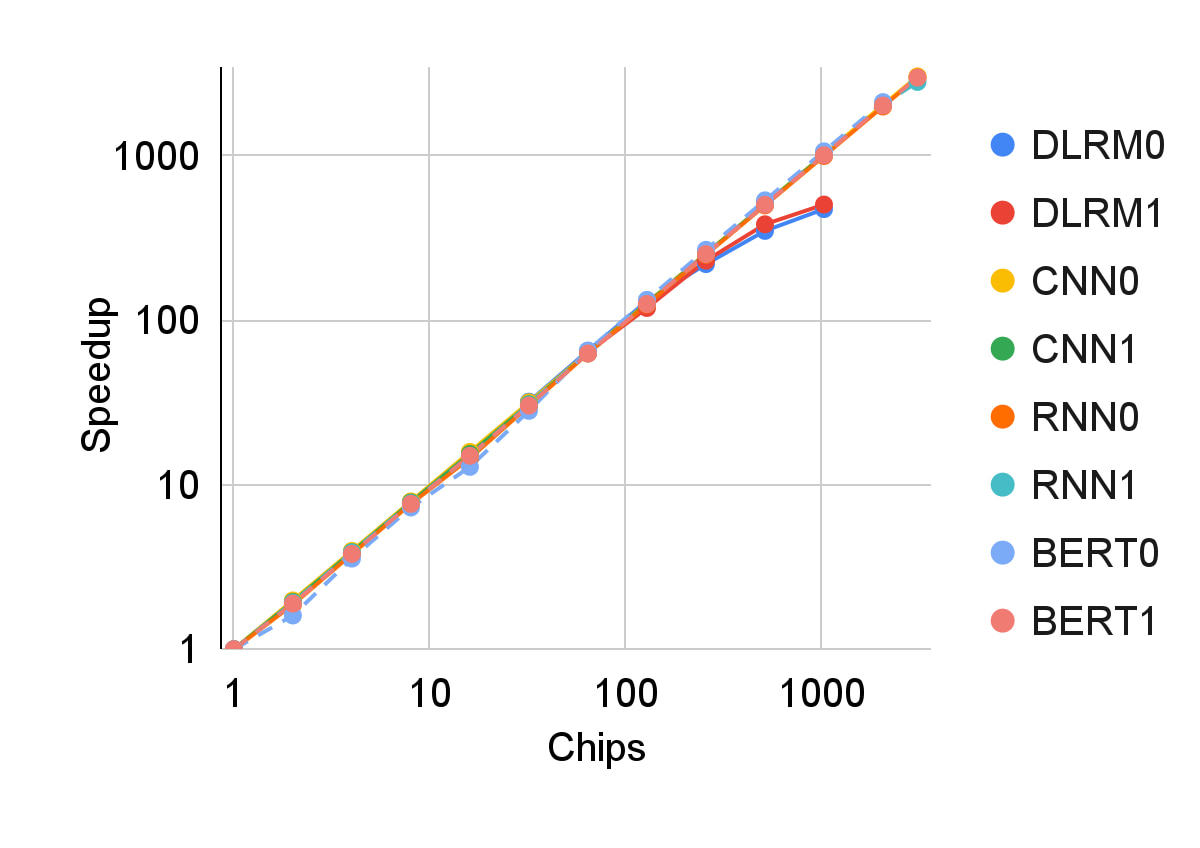
The combination of powerful yet efficient processors and a distributed shared memory system provides remarkable scalability for deep neural network models. The scalability of TPU v4 production workloads on a variety of model types is shown below on a log-log scale.
Dynamic OCS reconfigurability also helps with availability. Circuit switching makes it easy to route around failed components so that long-running tasks like ML training can utilize thousands of processors for weeks at a time. This flexibility even allows us to change the topology of the supercomputer interconnect to accelerate the performance of an ML model.
The performance, scalability, and availability make TPU supercomputers the workhorses of large language models like LaMDA, MUM, and PaLM. The 540B-parameter PaLM model sustained a remarkable 57.8% of the peak hardware floating point performance over 50 days while training on TPU v4 supercomputers. TPU v4’s scalable interconnect also unlocks multidimensional model-partitioning techniques that enable low-latency, high-throughput inference for these LMs.
TPU supercomputers are also the first with hardware support for embeddings, a key component of Deep Learning Recommendation Models (DLRMs) used in advertising, search ranking, YouTube, and Google Play. Each TPU v4 includes third-generation SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x–7x yet use only 5% of die area and power.
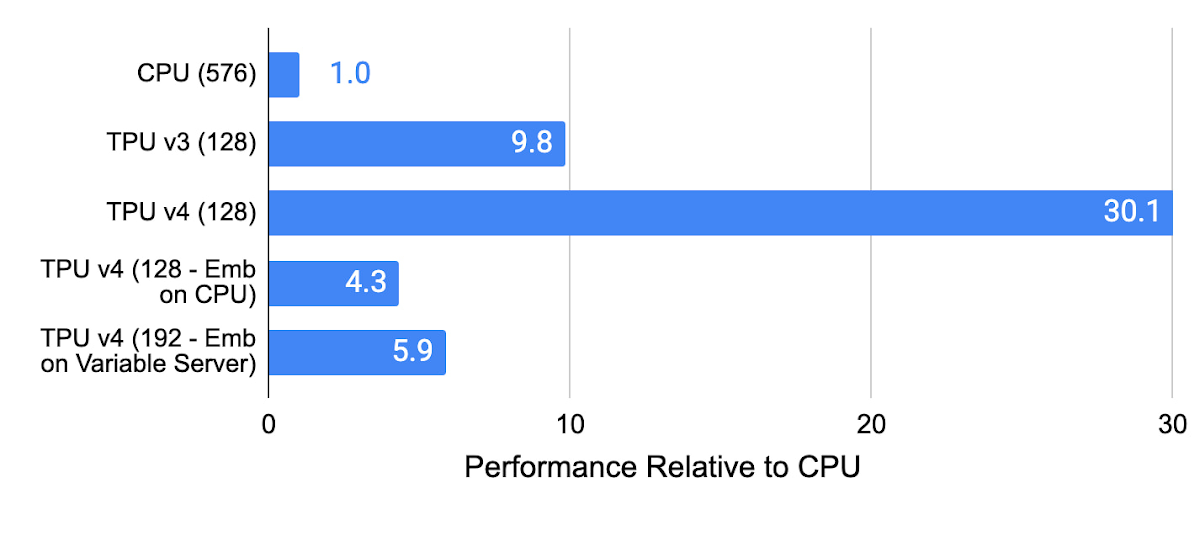
The performance of an internal recommendation model on CPUs, TPU v3, TPU v4, and TPU v4 with embeddings in CPU memory (not using SparseCore) is shown below. The TPU v4 SparseCore is 3X faster than TPU v3 on recommendation models, and 5–30X faster than systems using CPUs.
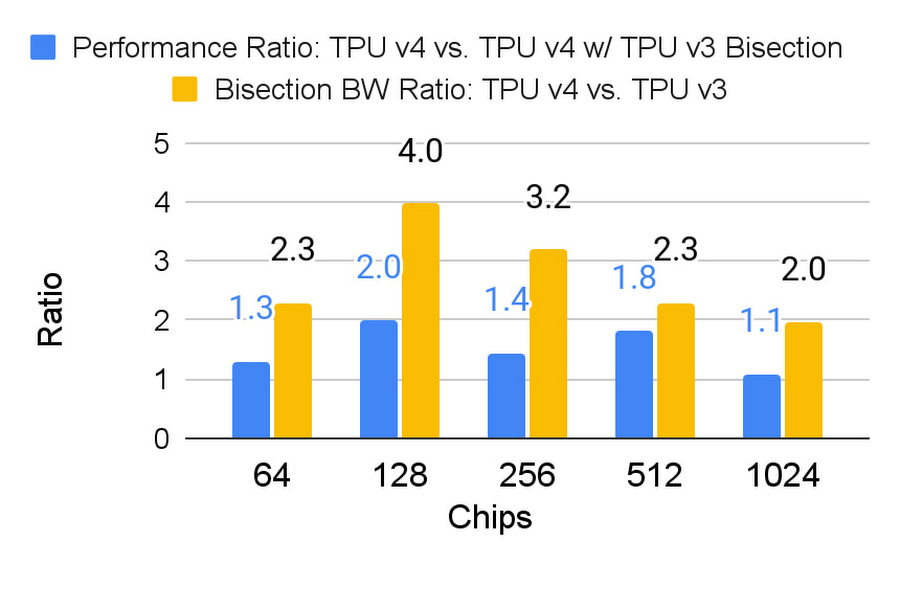
Embeddings processing requires significant all-to-all communication, since the embeddings are distributed around TPU chips working together on a model. This pattern stresses the bandwidth of the shared memory interconnect. That’s why TPU v4 uses a 3D torus interconnect (vs. TPU v2 and v3 which used a 2D torus). TPU v4’s 3D torus provides a higher bisection bandwidth — i.e., the bandwidth from one half of the chips to the other half across the middle of the interconnect — to help support the larger number of chips and the higher SparseCore v3 performance. The figure below shows the significant bandwidth and performance increase from the 3D torus.
TPU v4 has been operational at Google since 2020 and became available for customers on Google Cloud last year. Since its launch, TPU v4 supercomputers have been actively used by leading AI teams around the globe for cutting-edge ML research and production workloads across language models, recommender systems and generative AI. For example, the Allen Institute for AI, a non-profit institute founded by Paul Allen with the mission of conducting high-impact AI research for the common good, greatly benefitted from TPU v4 architecture and was able to unlock many of their large-scale, high-impact research initiatives.
“More recently, a number of researchers have turned to Cloud TPUs for their easy ability to distribute across many processing units. With GPUs, once you scale beyond a single machine you need to adjust your code for distribution and you might be disappointed by the connection speeds between your servers,” said Michael Schmitz, Senior Director of Engineering, Allen Institute for AI. “But with Cloud TPUs you can seamlessly scale individual workloads to thousands of chips, where all chips are directly connected to each other via a high-speed mesh network.”
Midjourney, one of the leading text-to-image AI startups, have been using Cloud TPU v4 to train their state-of-the-art model, coincidentally also called “version four”.
"We’re proud to work with Google Cloud to deliver a seamless experience for our creative community powered by Google’s globally scalable infrastructure,” said David Holz, founder and CEO of Midjourney. “From training the fourth version of our algorithm on the latest v4 TPUs with JAX, to running inference on GPUs, we have been impressed by the speed at which TPU v4 allows our users to bring their vibrant ideas to life.”
We are proud to share additional details of our TPU v4 research in a paper that will be presented at the International Symposium on Computer Architecture, and we look forward to discussing our findings with the community.
The authors thank many of Google's engineering and product teams for making TPU v4 a success story. We also want to thank Amin Vahdat, Mark Lohmeyer, Maud Texier, James Bradbury and Max Sapozhnikov for their contributions to this blog post.
1. This ~20x improvement comes from a combination of: ~2-3x more energy efficient TPUs, ~1.4x lower PUE of Google data centers relative to on-premise data centers, and ~6x for the cleaner energy in Oklahoma that houses all Cloud TPU v4 supercomputers versus the average energy cleanliness of the typical on-premise data center.

