GKE の NVIDIA NeMo フレームワークで、生成 AI への取り組みを加速
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
背景
生成 AI が AI の分野で注目されるようになって以来、スタートアップ企業から大企業に至るまで、さまざまな組織が生成 AI の力を活用しようと動き出しており、アプリケーション、ソリューション、プラットフォームの欠かせない要素として生成 AI を取り入れています。生成 AI の真価は、学習に基づいて既存のコンテンツから新しいコンテンツを作成することにありますが、生成されるコンテンツが特定の分野やドメインにある程度特化しているということが重要になってきています。
このブログ投稿では、NVIDIA の高速コンピューティングと NVIDIA NeMo フレームワークを使用して、Google Kubernetes Engine(GKE)でモデルをトレーニングする方法を示し、生成 AI モデルをどのようにユースケースに適応できるかをご説明します。
生成 AI モデルの構築
生成 AI モデルの構築においては、高品質なデータ(「データセット」)が基盤要素となります。テキスト、コード、画像などさまざまな形式のデータは、モデルの出力への直接的な影響を最小限に抑えるために処理、拡張、分析されます。モデルのモダリティに基づき、このデータはモデル アーキテクチャにフィードされ、モデルのトレーニング プロセスを可能にします。Transformers の場合はテキスト、GAN(Generative Adversarial Networks)の場合は画像が使用される可能性があります。
トレーニングの過程で、モデルはその出力がデータのパターンや構造に一致するよう、内部パラメータを調整します。モデルが学習している間、トレーニング セットの損失が減少しているか、テストセットに対する予測が改善しているかなど、モデルのパフォーマンスが監視されます。パフォーマンスに改善が見られなくなったら、モデルは収束したとみなされます。その後、場合によっては、人間のフィードバックによる強化学習(RLHF)のような、さらなる改良が行われます。学習率やバッチサイズなどのハイパーパラメータを調整することで、モデルの学習の効率を高めることができます。必要な構造やツールを提供するフレームワークを利用することで、モデルの構築とカスタマイズのプロセスを迅速化し、導入を簡素化できます。
NVIDIA NeMo
NVIDIA NeMo は、カスタマイズされたエンタープライズ グレードの生成 AI モデルの構築に特化した、オープンソースのエンドツーエンド プラットフォームです。NeMo は、NVIDIA の最先端テクノロジーを活用し、自動化された分散データ処理から、カスタマイズされた大規模なモデルのトレーニング、そして Google Cloud のインフラストラクチャを利用したデプロイとサービングまで、ワークフロー全体を円滑化します。NeMo では、Google Cloud Marketplace で入手可能な NVIDIA AI Enterprise ソフトウェアと組み合わせることで、エンタープライズ グレードのデプロイも可能です。
NeMo フレームワークは、AI モデルの構築にモジュール式の設計を採用しており、データ サイエンティスト、ML エンジニア、開発者は、これらのコア要素を組み合わせて使用できます。
-
データ キュレーション: データセットからの情報を抽出、重複排除、フィルタして、高品質のトレーニング データを生成
-
分散トレーニング: NVIDIA 画像処理装置(GPU)により、ワークロードを何万ものコンピューティング ノードに分散させることで、トレーニング モデルの高度な並列処理を実現
-
モデルのカスタマイズ: P-tuning、SFT(教師ありファイン チューニング)、RLHF(人間からのフィードバックを用いた強化学習)などのテクニックを使用して、複数の基礎となる事前学習済みモデルを特定のドメインに適応させる
-
デプロイ: NVIDIA Triton Inference Server とのシームレスな統合により、高精度、低レイテンシ、高スループットの結果を実現。NeMo フレームワークは、安全性とセキュリティの要件を満たすためのガードレールを提供。
これにより組織は、イノベーションを促進して、運用効率を最適化し、ソフトウェア フレームワークへの簡単なアクセスを確立して、生成 AI への取り組みを開始できます。
Slurm Workload Manager のようなスケジューラを含む可能性のある HPC システムに NeMo をデプロイしたい場合は、Cloud HPC Toolkit で利用可能な ML ソリューションを使用することをおすすめします。
GKE を使用した大規模なトレーニング
モデルの構築とカスタマイズには、膨大なコンピューティング、メモリとストレージへの迅速なアクセス、迅速なネットワーキングが必要です。さらに、大規模なモデルのスケーリング、効率的なリソースの利用、より高速な反復処理のためのアジリティ、フォールト トレランス、分散ワークロードのオーケストレーションなど、インフラストラクチャ全体でさまざまなことが求められます。
GKE を利用することで、すべてのワークロードを単一のプラットフォームで管理でき、より一貫性のある堅牢な開発プロセスを実現できます。基盤プラットフォームとして GKE は、比類のない拡張性と、NVIDIA GPU を含む多様なハードウェア アクセラレータとの互換性を提供し、アクセラレータ オーケストレーションの長所を生かして、大幅なパフォーマンスの向上とコストの削減を支援します。
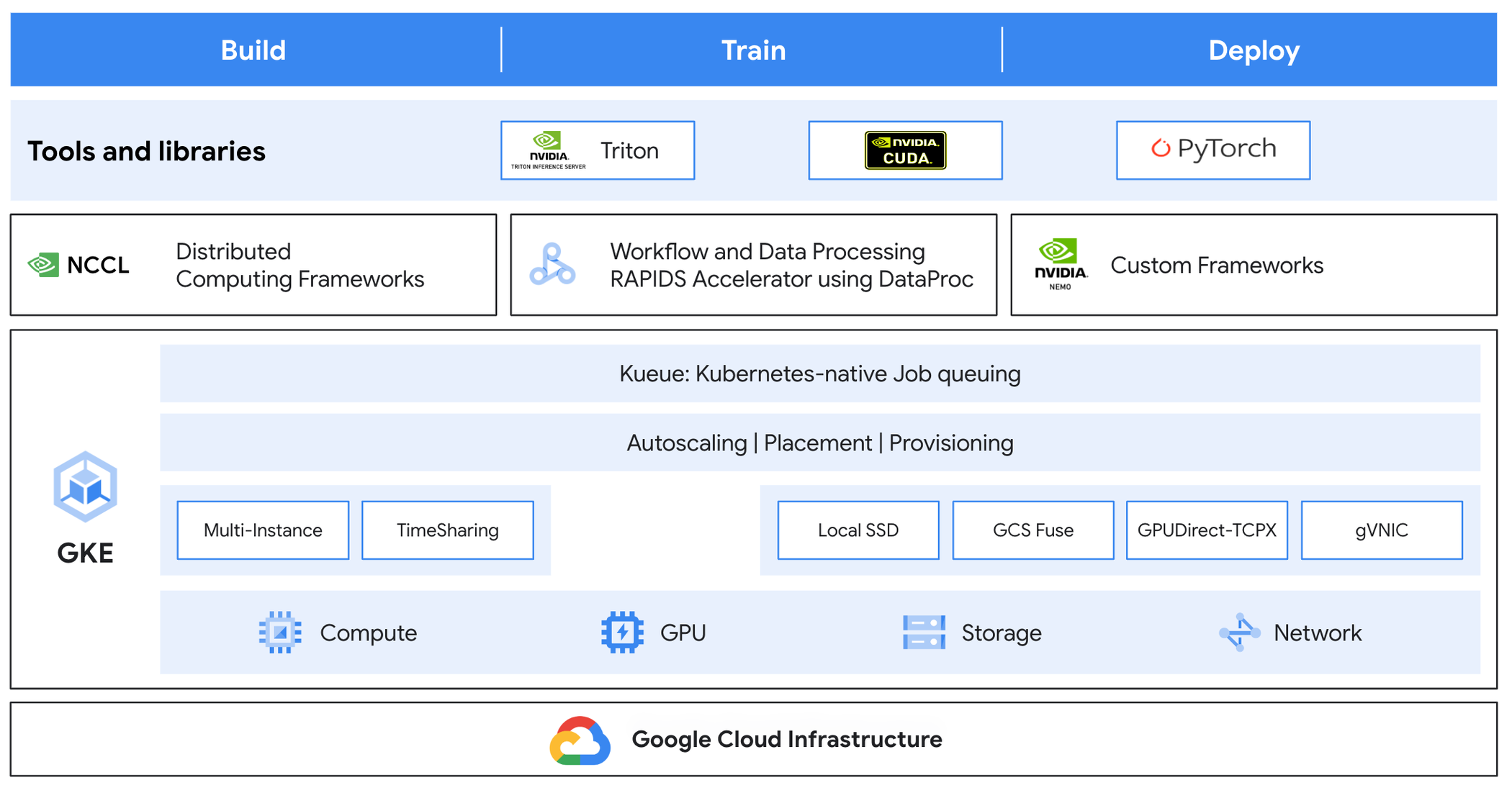
図 1 を参考に、GKE により基盤となるインフラストラクチャの管理がどのように簡素化されるのかを見てみましょう。
-
コンピューティング
-
マルチインスタンス GPU(MIG): 単一の NVIDIA H100 または A100 Tensor Core GPU を複数のインスタンスに分割することで、各インスタンスに高帯域幅メモリ、キャッシュ、コンピューティング コアを持たせる
-
時間共有 GPU: 単一の物理 GPU ノードを複数のコンテナで共有することで、効率的な使用とランニング コストの削減を実現
-
ストレージ
-
ローカル SSD: 高スループットと I/O 要件
-
GCS Fuse: オブジェクトに対し、ファイル システムのような操作を可能にする
-
ネットワーキング:
-
GPUDirect-TCPX NCCL プラグイン: NCCL 通信時に GPU から NIC への直接転送を可能にするトランスポート層のプラグイン。ネットワーク パフォーマンスを向上させる。
-
Google 仮想ネットワーク インターフェース カード(gVNIC): GPU ノード間のネットワーク パフォーマンスを向上させる
-
キューイング: Kubernetes ネイティブのジョブ キューイング システムで、リソースが制限された環境でジョブの実行を完了までオーケストレート。
GKE は、他の ISV(独立系ソフトウェア ベンダー)を含む、さまざまなコミュニティによって広く受け入れられており、ツール、ライブラリ、フレームワークの導入に利用されています。GKE は、さまざまな規模のチームが AI モデルを構築、トレーニング、デプロイできるようにすることで、インフラストラクチャを誰もが利用できるようにします。
ソリューション アーキテクチャ
AI / ML 分野における現在の業界動向は、高い演算能力がモデルの性能向上に大きく寄与することを示しています。GKE を NVIDIA GPU と組み合わせて利用することで、Google Cloud のプロダクトとサービスが持つ高い演算能力を最大限に活用し、業界をリードするスケールでモデルをトレーニング、サービングすることが可能になります。
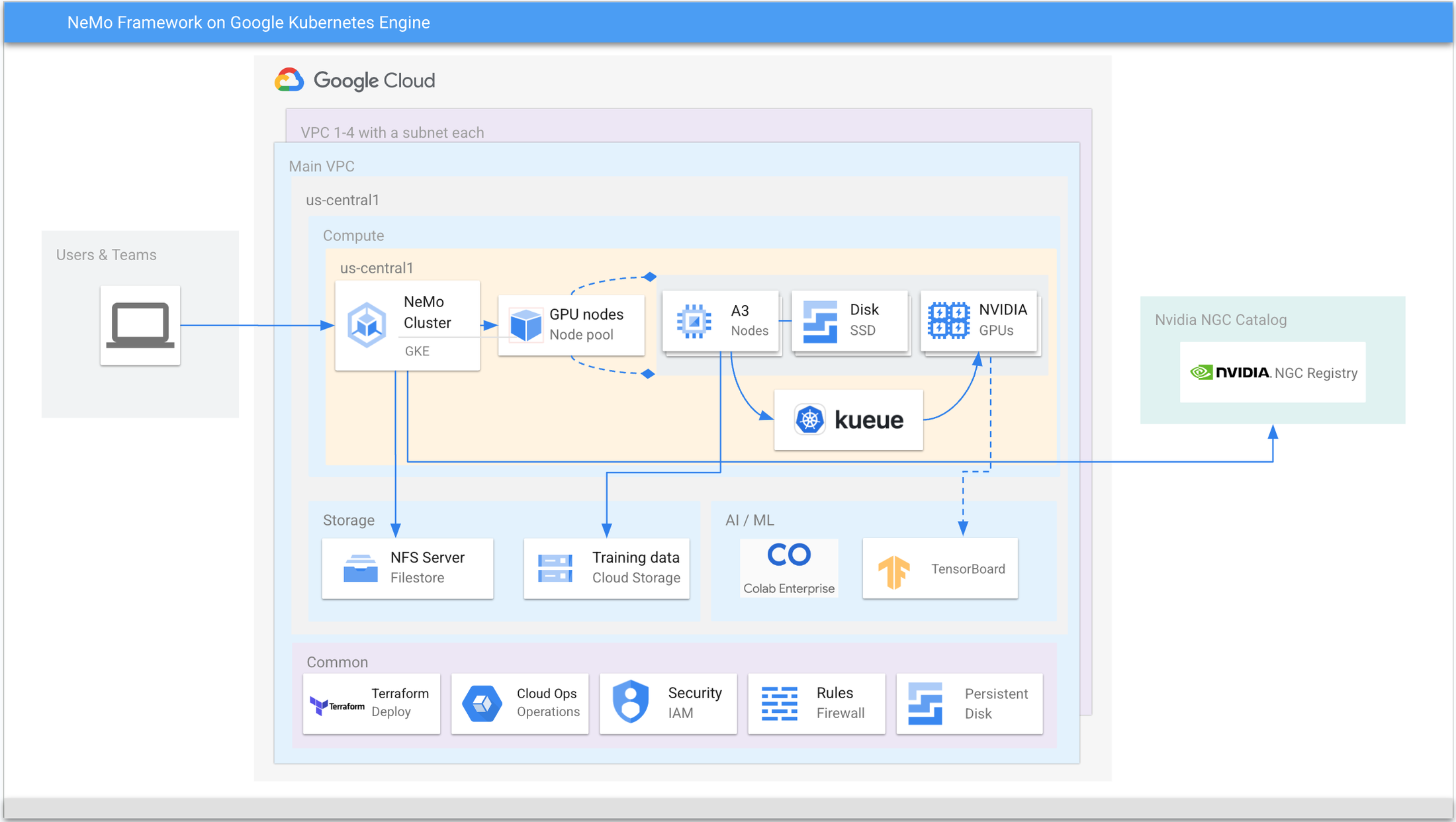
上記の図 2 のリファレンス アーキテクチャは、GKE を使用して NeMo 大規模言語モデルをトレーニングする際に使用される主な要素、ツール、一般的なサービスを示しています。
-
2 つのノードプールで構成されたリージョンまたはゾーンのロケーションとして設定された GKE クラスタ。DNS ポッド、カスタム コントローラなどの一般的なサービスを管理するデフォルトのノードプールと、ワークロードを実行する A3 ノードを含んだマネージド ノードプール。
-
A3 ノード。それぞれ 16 のローカル SSD、8 つの NVIDIA H100 Tensor Core GPU、関連ドライバを搭載。各ノードでは、Filestore CSI の CSI ドライバが有効になっており、フルマネージドの NFS ストレージと、ファイル システムである Google Cloud Storage にアクセスするための Cloud Storage FUSE にアクセスできるようになっている。
-
ワークロード管理のための Kueue のバッチ処理。複数のチームが使用する大規模な設定がある場合に推奨される。
-
トレーニングのパフォーマンスを確認するための出力、中間、最終ログを保存するため、各ノードにマウントされたファイルストア。
-
トレーニング データを格納する Cloud Storage バケット。
-
NVIDIA NGC が NeMo フレームワークのトレーニング イメージをホスト。
-
Filestore にマウントされたトレーニング ログで、TensorBoard を使用して表示し、トレーニングの損失とトレーニングのステップ時間を確認できる。
-
ログを表示するための Cloud Ops、セキュリティを管理するための IAM、設定全体をデプロイするための Terraform などの一般的なサービス。
エンドツーエンドのチュートリアルは、GitHub リポジトリの https://github.com/GoogleCloudPlatform/nvidia-nemo-on-gke で確認できます。このチュートリアルでは、Google Cloud プロジェクトで上記のソリューションを設定し、NeMo フレームワークを使用して NVIDIA の NeMo Megatron GPT を事前トレーニングする方法について、詳細な手順を紹介しています。
さらなる拡張
大量の構造化データが存在するシナリオでは、中心的なデータ ウェアハウジング プラットフォームとして BigQuery が企業で一般的に使用されています。また、モデルをトレーニングするために Cloud Storage にデータをエクスポートする手法があります。データが意図した形式で利用できない場合は、Dataflow を利用してデータを読み取り、変換し、BigQuery に戻すことができます。
まとめ
GKE を活用することで、企業は基盤となるインフラストラクチャの心配をすることなく、ビジネスを成長させるためのモデルの開発とデプロイに集中できます。NVIDIA NeMo は、カスタムの生成 AI モデルの構築に非常に適しています。これらを組み合わせることで、モデルのトレーニングやサービングのプロセスにおいて、拡張性、信頼性、使いやすさが実現されます。
GKE の詳細については、こちらをクリックしてください。また、NVIDIA NeMo の詳細については、こちらをクリックしてください。
今後開催される NVIDIA GTC にお越しの際は、ブース #808 の Google Cloud でぜひ実際にご覧ください。

