A2 VM の一般提供開始 - NVIDIA A100 GPU で最大級の GPU クラウド インスタンスを実現

Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
NVIDIA Ampere A100 Tensor Core GPU を基盤とした A2 VM が Compute Engine 向けに一般提供となりました。これにより、NVIDIA CUDA による機械学習(ML)およびハイ パフォーマンス コンピューティング(HPC)のスケールアウト / スケールアップ ワークロードを、より効率的にコストを抑えながら実行することが可能となります。
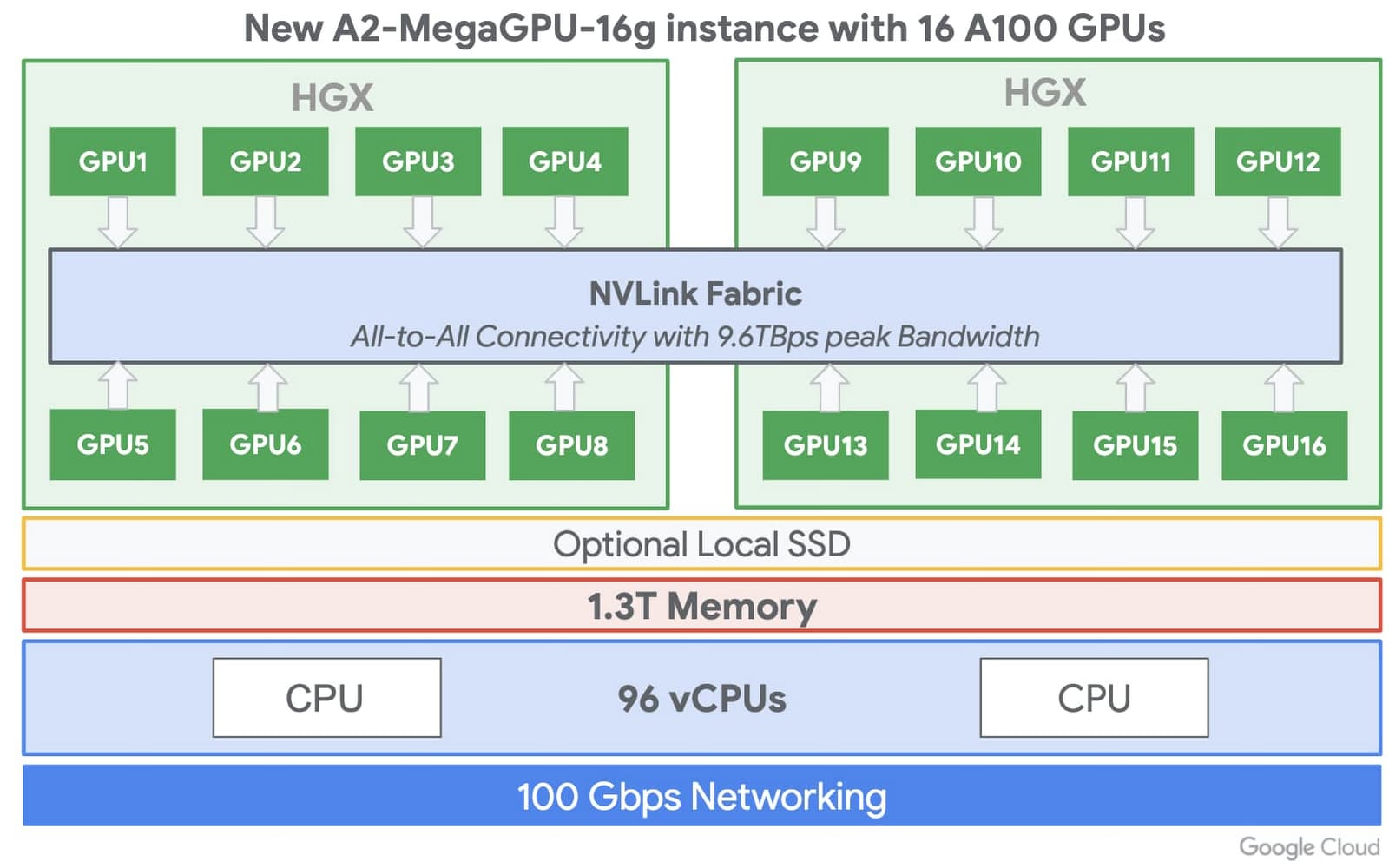
単一の VM で NVIDIA A100 GPU 16 個に対応する A2 VM は、主要なクラウド プロバイダから提供される単一ノードの GPU インスタンスとして最大規模を誇り、他社とは一線を画したパフォーマンスを実現します。さらに、A2 VM は小規模の GPU 構成(VM あたりの GPU 数が 1、2、4、8)でも提供されており、各自のワークロードのスケーリングに適したものを自由に選べるのが特長です。

Compute Engine の A2 VM シェイプ
大規模なパフォーマンス
単一で最大 16 個の NVIDIA A100 GPU をサポートする A2 VM なら、機械学習(ML)のトレーニングや推論、HPC などのスケーラブルな CUDA コンピューティング ワークロードにおいてパフォーマンスを簡単かつ大幅に改善できるため、研究者や、データ サイエンティスト、デベロッパーの皆様に最適です。Google Cloud Platform の A2 VM ファミリーは、Altair ultraFluidX での CFD シミュレーションなど、HPC アプリケーションの中でも特に要求の厳しいアプリケーションにも対応できるように設計されています。
Google Cloud では、超大規模な GPU クラスタを必要とするお客様を想定し、数千個の GPU からなるクラスタもサポートされているため、ML の分散トレーニングや NCCL 最適化ライブラリにおいてパフォーマンスをスケールアウトすることが可能です。最大 16 個の A100 GPU をサポートする単一の VM シェイプと、NVIDIA の NVlink ファブリックという組み合わせは Google Cloud 独自のものであり、他のクラウド プロバイダからは提供されていません。大規模かつ要求の厳しいワークロードをスケールアップする必要が生じた場合は、まず A100 GPU 1 個から始めて 16 個まで徐々に増やすことで、複数の VM を構成することなく単一ノードで ML トレーニングを行うことが可能です。
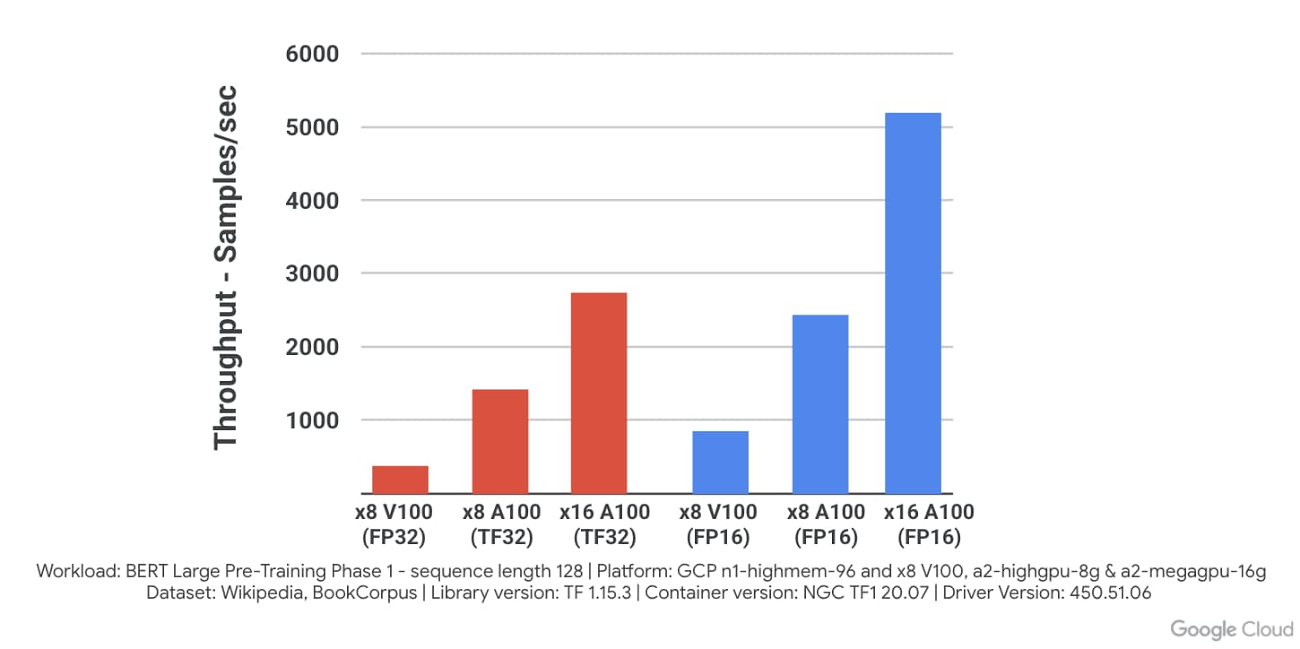
また、A2 VM は小規模の構成でも利用できるので、アプリケーションのニーズに応じて適したものを選べます。さらに、ローカル SSD を最大 3 TB まで使用して GPU へのデータフィードを高速化することも可能です。結果として、Google Cloud で A100 を実行する場合、VM シェイプの GPU が 8 から 16 へと増加するに従って線形スケーリングが達成され、前世代の NVIDIA V100 に比べ、BERT Large の事前トレーニング モデルにおいてパフォーマンスが 10 倍に向上します。さらに、NVIDIA の NGC リポジトリから、コンテナ化された事前構成済みのソフトウェアも利用できるので、Compute Engine A100 インスタンスを簡単に設定して使い始めることが可能です。
お客様の声
2020 年 7 月に A100 GPU を備えた A2 VM への早期アクセスを開始して以来、機械学習や、レンダリング、HPC の限界に挑む数々の企業に A2 VM をご利用いただいています。そうしたお客様からのコメントをいくつかご紹介します。

最近 Square によって買収された人工知能(AI)研究会社の Dessa は、A2 VM の初期ユーザーです。Dessa によるテストとイノベーションを通じて、Cash App と Square は一般のユーザーが AI を活用して金銭面でより適切な意思決定が行えるようにするため、パーソナライズされたサービスやスマートなツールを作成する取り組みをさらに進めています。
Dessa のシニア ソフトウェア エンジニアである Kyle De Freitas 氏は、次のように述べています。「Google Cloud は、当社のプロセスに不可欠な管理機能を提供してくれました。NVIDIA A100 Tensor Core GPU を搭載した Compute Engine A2 VM により、処理時間を劇的に短縮し、テストを大幅にスピードアップできる可能性があることがわかりました。Google Cloud の AI Platform で NVIDIA A100 GPU を実行することで、革新を継続し、アイデアを実現してお客様にとって効果の大きいサービスを提供するために必要な基盤を獲得できました。」

グローバルな動画テクノロジー企業である HyperConnect は、ビデオ通信(WebRTC)や AI を専門としています。同社は、世界中の人々を結び付けることによって社会的および文化的な価値を創出するというミッションのもと、動画および AI 関連の各種テクノロジーを基盤としたサービスを展開しています。
「Google Cloud で前世代の V100 GPU から A2 インスタンスの新しい NVIDIA A100 GPU へと簡単かつシームレスに移行したことで、ディープ ラーニング モデルのトレーニングがまったく新しいレベルへと引き上げられました。V100 に比べてトレーニング処理の計算速度が 2 倍以上になっただけでなく、Google Cloud 上の大規模なニューラル ネットワーク ワークロードを A2 megagpu VM シェイプによってシームレスにスケールアップすることもできました。こうした飛躍的進歩のおかげで、今後、Hyperconnect サービスのユーザー エクスペリエンス向上に役立つ優れたモデルを構築できるようになりました。」 - Hyperconnect ML 研究者、Beomsoo Kim 氏

科学者、エンジニア、機械学習専門家らで構成された DeepMind(Alphabet の子会社)では、チームが一丸となって AI の技術水準を高める取り組みを進めています。
「DeepMind では、『知性を解明すること』というミッションのもと、人工知能を進化させるためのさまざまな課題に取り組んでおり、それに伴う各種実験にハードウェア アクセラレータを活用しています。Google Cloud の協力を得て、最新世代の NVIDIA GPU と a2-megagpu-16g マシンタイプを使用したことで、GPU を用いた実験のトレーニングをこれまでより高速化することができました。引き続き Google Cloud と連携し、将来に向けた ML および AI 基盤の開発と構築に取り組んでいきたいと考えています。」 - DeepMind 研究部門バイス プレジデント、Koray Kavukcuoglu 氏

AI2 は、公共の利益となるような影響力の高い AI の研究開発を目的として設立された非営利研究機関です。
「私たちの主なミッションは、コンピュータでできることの限界を押し広げることですが、これを目指すうえで大きな障壁が 2 つあります。1 つは、最新の AI アルゴリズムには膨大な処理能力が必要であるということ。もう 1 つは、現場のハードウェアやソフトウェアは刻々と変化していくため、その変化に常に対応していかなければならないということです。A100 の GCP なら、既存のシステムに比べて処理速度が 4 倍に高まるうえ、コードの大規模な変更も不要です。ほとんどプラグ アンド プレイのような感覚です。最終的に、Google Cloud の A100 のおかげで 1 ドルあたりの処理能力が大幅に向上したため、実験を拡充したり、活用データを増やしたりすることが可能となっています。」 - Allen Institute for Artificial Intelligence シニア エンジニア、Dirk Groeneveld 氏

クラウドでのグラフィック処理を手がける企業、OTOY は、世界中のメディアおよびエンターテイメント企業を顧客に抱え、コンテンツの作成と配信の常識を塗り替えるような革新的技術を開発しています。
「当社では、これまで約 10 年にわたり、クリエイティブなアート制作作業への制約を取り払うべく、GPU を用いたレンダリングおよびクラウド コンピューティングの限界を押し広げてきました。大量の VRAM を搭載し、OctaneBench で過去最高の結果を記録した Google Cloud の NVIDIA A100 インスタンスにより、当社では GPU によるレンダリング処理において未踏の領域に到達し、アーティストがシーンの複雑さを気にすることなく独自のクリエイティブ ビジョンを表現できるようになりました。OctaneRender で GPU による高速レンダリングを実現することで、ハリウッドのスタジオに匹敵する最高級の視覚効果を誰でも NVIDIA GPU によって生み出すことができるようになっています。Google Cloud の NVIDIA A100 インスタンスのおかげで、これまではハリウッドの大規模なスタジオでしか利用できなかったような最先端の NVIDIA GPU を OctaneRender および RNDR ユーザーがオンデマンドで使用できるようになったことは、高度な視覚効果のさらなる民主化に向けた大きな一歩といえるでしょう。」 - OTOY 創業者兼 CEO、Jules Urbach 氏
GPU の料金、対象リージョン、提供形態
NVIDIA A100 GPU インスタンスは現在、us-central1、asia-southeast1、europe-west4 でご利用いただけるほか、2021 年中にその他のリージョンも対応する予定です。現在、A2 Compute Engine VM は、オンデマンド、プリエンプティブル、確約利用割引の形で提供されています。また、Google Kubernetes Engine(GKE)、Cloud AI Platform およびその他の Google Cloud サービスにおいて完全にサポートされています。A100 GPU の料金は、プリエンプティブルの A2 VM で GPU ごとに 1 時間あたりわずか $0.87 となっています。料金について詳しくは、こちらをご覧ください。
使ってみる
任意の対応リージョンで Deep Learning VM イメージ を使えば、簡単に A2 VM を設定して使用を開始し、NVIDIA A100 GPU で ML モデルのトレーニングを行ったり、推論ワークロードに活用したりできます。このイメージには、ドライバ、NVIDIA CUDA-X AI ライブラリのほか、TensorFlow や PyTorch のような一般的 AI フレームワークなど、必要なソフトウェアがすべて含まれています。最適化されたビルド済み VM イメージである TensorFlow Enterprise イメージでは、TensorFlow の現行バージョンおよび旧バージョン(1.15、2.1、2.3)の A100 向け最適化もサポートしています。ソフトウェアのアップデートや、互換性、パフォーマンスの最適化についてはすべて Google 側で処理されますので、ユーザーの皆様はこれらを気にする必要なしに使用を続けることができます。Google Cloud で提供している各種 GPU について詳しくは GPU ページをご覧ください。
-プロダクト マネージャー Bharath Parthasarathy
-Cloud GPU プロダクト マネージャー Chris Kleban

