Vertex AI Agent Engine Memory Bank のプレビュー版が一般提供開始
Kimberly Milam
Software Engineer, Vertex AI
George Lee
Product Manager, Cloud AI Research
※この投稿は米国時間 2025 年 7 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
デベロッパーはエージェントの製品化に向けてしのぎを削っていますが、記憶機能の欠如による制限にしばしば遭遇します。記憶機能がない場合、エージェントは個々のインタラクションを空白の状態から始めるため、同じ質問を繰り返したり、ユーザーの好みを思い出せなかったりします。コンテキストを認識できないため、エージェントはパーソナライズされた支援を提供することが難しく、デベロッパーは不満を抱えています。
記憶機能の問題を軽減する一般的な方法: これまでのところ、この問題に対する一般的なアプローチは、LLM のコンテキスト ウィンドウを活用することでした。しかし、セッションの対話をすべて LLM のコンテキスト ウィンドウに直接注入すると、費用がかさみ、計算効率も悪くなります。その結果、推論コストが増加し、応答時間が長くなります。また、LLM に入力される情報量が増加すると(特に関連性のない詳細や誤解を招く詳細が含まれている場合)モデル出力の品質が大幅に低下し、「lost in the middle」や「context rot」などの問題が発生します。
今回の解決策: このたび、Vertex AI Agent Engine の最新のマネージド サービスである Memory Bank の公開プレビュー版がリリースされました。これにより、高度にパーソナライズされた会話エージェントを構築し、より自然で、コンテキストに沿った、継続的なエンゲージメントが可能になります。Memory Bank は、4 つのアプローチで記憶機能にまつわる問題への対処を支援します。
-
やり取りをパーソナライズ: 一般的なスクリプトにとどまらず、ユーザーの好み、重要なイベント、過去の選択を記憶して、すべての回答をカスタマイズします。
-
継続性を維持: 数日または数週間経過しても、複数のセッションにわたって会話を中断したところからシームレスに再開できます。
-
より適切なコンテキストを提供: ユーザーに関する必要な背景情報をエージェントに提供することで、より関連性が高く、洞察に満ちた、役立つ回答が得られます。
-
ユーザー エクスペリエンスを向上: 同じ情報を繰り返すことによるストレスを解消し、より自然で効率的かつ魅力的な会話を実現します。
アクセス方法: Memory Bank は、Agent Development Kit(ADK)と Agent Engine Sessions と統合されています。ADK を使用してエージェントを定義し、Agent Engine Sessions を有効にすることで、会話履歴を個々のセッションで保存および管理できるようになります。そして今回ご紹介する Memory Bank を有効にすると、エージェントが関連情報を保存、取得、管理するための長期記憶を複数のセッションにわたって提供できます。また、Memory Bank を使用して、LangGraph や CrewAI などの他のエージェント フレームワークの記憶を管理することもできます。
Memory Bank の仕組み
-
インタラクションからの記憶を理解して抽出する: Memory Bank は Gemini モデルを使用して、ユーザーとエージェントの会話履歴(Agent Engine セッションに保存)を分析し、重要な事実、好み、コンテキストを抽出して新しい記憶を生成できます。これはバックグラウンドで非同期的に行われるため、複雑な抽出パイプラインを構築する必要はありません。
-
インテリジェントに記憶を保存、更新: 「好みの温度は 22 度」、「飛行機では通路側の席が好き」といった重要な情報は、ユーザー ID など、定義したスコープごとに永続的に保存され、整理されます。新しい情報が発生すると、Memory Bank は Gemini を使用してその情報を既存の記憶と統合し、矛盾を解消して記憶を最新の状態に保ちます。
-
関連情報を想起する: ユーザーが新しい会話(セッション)を開始すると、エージェントは保存された記憶を取得することができます。これは、すべての事実を単純に取得する場合もあれば、より高度な類似性検索(エンベディングを使用)で現在のトピックとの関連性が最も高い記憶を見つけ、エージェントに常に適切なコンテキストを提供する場合もあります。

AI エージェントが Agent Engine Sessions の会話履歴を使用して、Memory Bank からユーザーに関する永続的な記憶を生成および取得する方法を示した図。
このプロセス全体は、Google Research の斬新な研究手法(ACL 2025 にアクセプト)に基づいています。この手法は、エージェントが情報を学習および想起する方法に対するインテリジェントなトピックベースのアプローチを可能とし、エージェントの記憶パフォーマンスの新しい基準を確立するものです。
具体的な例で考えてみましょう。あなたは美容業界の小売業者であるとします。記憶機能を備えたパーソナル ビューティー コンパニオンが、商品やスキンケア ルーチンを提案します。
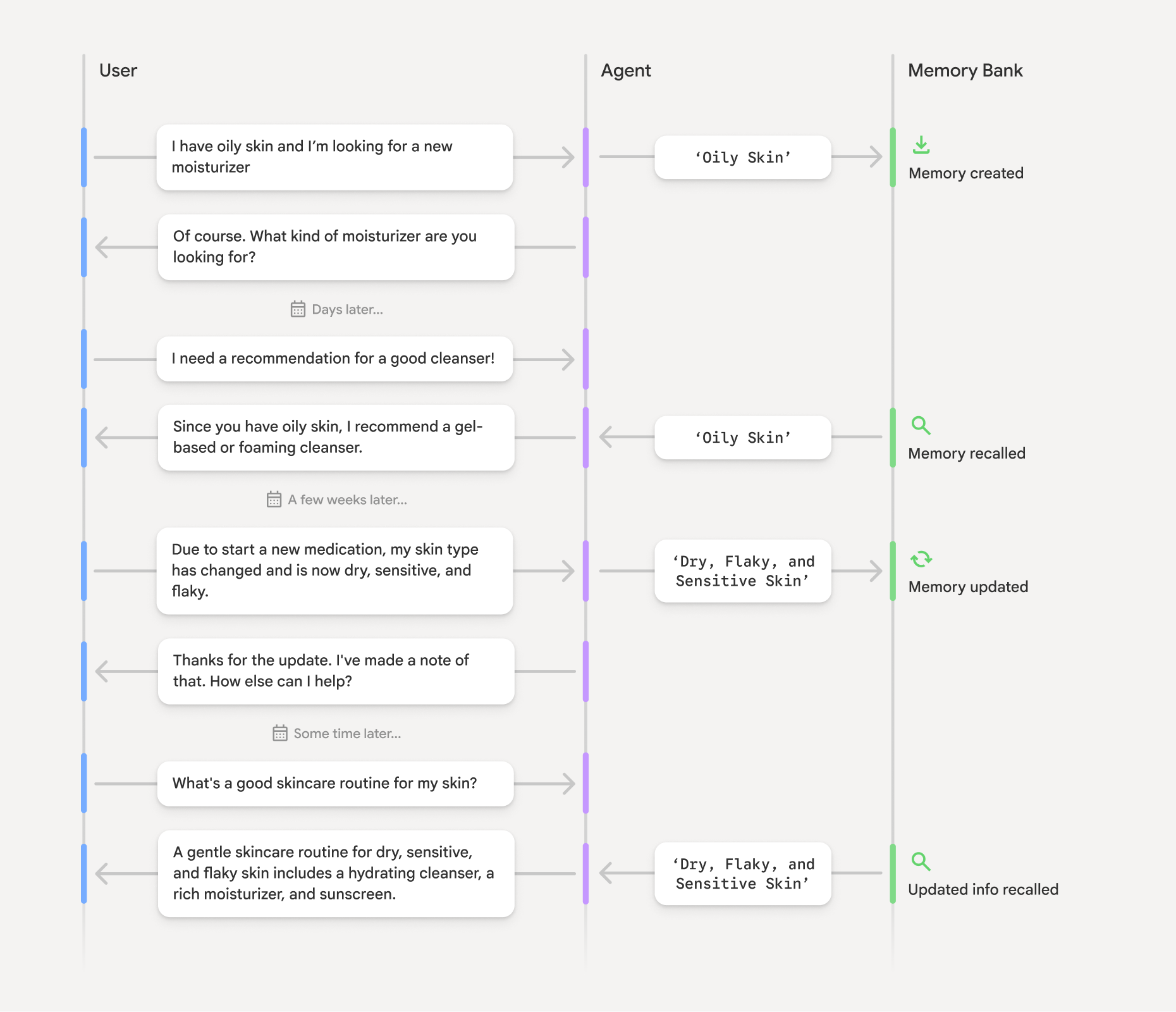
図に示すように、エージェントは、ユーザーの肌タイプが時間とともに変化しても(コンテキストを維持)、それを記憶して、パーソナライズされたおすすめを提示できます。これが長期記憶を備えたエージェントの力です。
今すぐ Memory Bank を使ってみましょう
Memory Bank をエージェントに統合する方法は主に 2 つあります。
-
Google エージェント開発キット(ADK)を使用してエージェントを開発し、すぐに使えるエクスペリエンスを実現する。
-
他のフレームワークでエージェントを構築する場合は、Memory Bank への API 呼び出しをオーケストレートするエージェントを開発する。
ご利用にあたっては、公式のユーザーガイドとデベロッパー ブログをご覧ください。実践的な例については、GitHub の Google Cloud 生成 AI リポジトリで、ADK との統合や Agent Engine ランタイムへのデプロイなど、さまざまなサンプル ノートブックが提供されています。サードパーティのフレームワークと Memory Bank の組み合わせを試したい方のために、LangGraph と CrewAI のノートブック サンプルも用意しています。
Agent Development Kit(ADK)を使用していて、Google Cloud を使用したことがない場合でも、Agent Engine Sessions と Memory Bank の新しいエクスプレス モード登録でご利用を開始することができます。手順は次のとおりです。
-
Gmail アカウントで登録して API キーを受け取る
-
キーを使用して Agent Engine Sessions と Memory Bankにアクセスする
-
無料枠の使用量割り当て内でエージェントを構築してテストする
-
本番環境へ移行する準備が整ったら、フルの Google Cloud プロジェクトへシームレスにアップグレード
Memory Bank の詳細についてご関心のある方は、Vertex AI Google Cloud コミュニティにご参加ください。経験の共有、質問、新しいプロジェクトでのコラボレーションをしていただけます。
-Vertex AI、ソフトウェア エンジニア、Kimberly Milam
-Cloud AI Research、プロダクト マネージャー、George Lee



