RAG 検索の最適化: テスト、チューニング、成功
Hugo Selbie
Staff Customer & Partner Solutions Engineer, Google
Tom Pakeman
Customer Partner & Solutions Engineer
※この投稿は米国時間 2024 年 12 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
検索拡張生成(RAG)は、大規模言語モデル(LLM)をリアルタイム データ、専有データ、特殊なデータに接続することで、LLM を強化します。これにより、LLM はより正確で関連性が高く、コンテキストを認識した回答を提供できるようになるため、ハルシネーションを最小限に抑え、AI アプリケーションへの信頼を構築できます。
しかし RAG は諸刃の剣です。コンセプトは、関連情報を見つけて LLM に入力するだけという単純なものですが、その実装を習得するのは困難です。適切に実装できないと、AI の信頼性に対するユーザーの信用に影響が及ぶ可能性があります。原因は多くの場合、徹底した評価を行っていないことです。徹底した評価を行っていない RAG システムは「サイレント障害」につながり、システム全体の信頼性を損なう可能性があります。
このブログ投稿では、RAG システム内の問題を特定し、透明性の高い自動評価フレームワークを使用して修正するための一連のベスト プラクティスを紹介します。
ステップ 1. テスト フレームワークを作成する
RAG システムのテストは、ツールに対して一連のクエリを実行することと、出力を評価することで構成されます。テストとイテレーションを迅速に行うための重要な前提条件は、成功の定義として一連の指標を決定し、それらを自動化された厳密かつ反復可能な方法で計算することです。以下にガイドラインをいくつかご紹介します。
-
質の高い質問でテスト データセットを組み立てる
-
テストセットが、基礎となるデータの広範なサブセットを網羅していて、実際のユースケースに一致する表現や質問の複雑さについてバリエーションを備えていることを確認します。
-
上級者向けのヒント: このデータセットの品質と関連性を確保するために、ここで関係者やエンドユーザーと相談することをおすすめします。
-
評価に使用する望ましい出力の「ゴールデン」参照データセットを組み立てる
-
一部の指標は参照データセットがなくても計算できますが、既知の良好な出力があると、より包括的で微妙な範囲の評価指標を作成できます。
-
テストの実行間では一度に 1 つの変数のみ変更する
-
RAG パイプラインには、違いを生み出す機能が多数あります。一度に 1 つずつ変更することで、評価スコアの変化が 1 つの機能のみに起因していることを確認できます。
-
同様に、テストの実行間で、使用している評価の質問、参照回答、またはシステム全体のパラメータと設定を変更しないようにする必要があります。
ここでの基本的なプロセスは、RAG システムの 1 つの側面を変更して一連のテストを実行し、機能を適応させてまったく同じ一連のテストを再度実行することで、テスト結果がどのように変化したかを確認することです。機能を改善できないと判断したら、設定を固定し、プロセスの別の部分のテストに進みます。
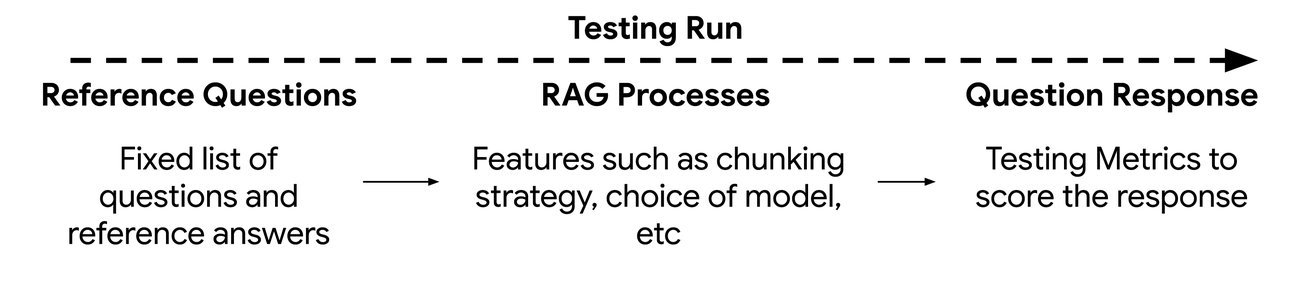
このテスト フレームワークは、次の 3 つのコンポーネントとして視覚化できます。
-
参照質問と参照回答:
-
評価する一連のクエリ。計算される指標に応じて、対応する参照回答が含まれる場合があります。
-
RAG プロセス
-
変更され評価されている検索および要約手法
-
質問の出力
-
テスト フレームワークによってスコア付けされた評価出力
適切な指標の選択
システムを評価するための最適な指標を設定するには、試行錯誤が必要です。事前定義されたテスト フレームワークは、特定のユースケースにも適応できる事前構築済みの指標を提供することで、プロセスを高速化するように設計されています。これにより、RAG システムの評価と改良のためのベースライン スコアをすばやく生成できます。このベースラインから、検索機能と生成機能を体系的に変更し、改善点を測定できます。
一般的な RAG 評価フレームワーク:
Ragas
Ragas は、RAG システムを評価するためのオープンソース ツールです。事実の精度、回答の関連性、取得したコンテンツが質問にどの程度適合しているかなど、重要な側面を測定します。Ragas はテストデータの生成にも役立ち、開発者は RAG システムの精度と有用性をより簡単に改善できるようになります。
Vertex AI の Gen AI Evaluation Service
Vertex AI の Gen AI Evaluation Service を使用すると、カスタム指標に基づいて生成モデルやアプリケーションのテストや比較を行えます。モデルの選択、プロンプト エンジニアリング、ファインチューニングをサポートしており、ユーザーは指標の定義、データの準備、評価の実行、結果の確認を行えます。Gen AI Evaluation Service は、モデルベースと計算ベースの両方の評価方法を使用して、Google のモデル、サードパーティのモデル、さまざまな言語のオープンモデルで動作します。
指標の例
モデルベースの指標では、Google 所有のモデルを使用して、候補モデルの出力を評価します。このモデルはエバリュエータとして機能し、定義済みの基準に基づいて回答にスコアを付けます。
-
ポイントワイズの指標: 判定モデルが候補モデルの出力に数値スコア(0~5 のスケールなど)を割り当て、評価基準との整合性を示します。スコアが高いほど適合度が高くなります。
-
ペアワイズの指標: 判定モデルが 2 つのモデルの回答を比較し、優れているモデルを特定します。このアプローチは、候補モデルをベースライン モデルと比較するためによく使用されます。
コンピューティング ベースの指標: モデルの出力をグラウンド トゥルースまたは基準値と対比する数式を使用します。よく使用される例としては、ROUGE や BLEU があります。
独断的なタイガーチームのアクション
-
関係者と協力して、一連の「ゴールデン」な質問入力を作成します。これらの質問は、RAG システムが対処することを意図した主なユースケースを正確に反映する必要があります。包括的なテストを確実に行うには、単純なクエリ、複雑なクエリ、複数の部分から成るクエリ、スペルミスのあるクエリなど、さまざまなタイプのクエリを含めることが重要です。
-
Vertex AI の生成 AI 評価フレームワークを活用します。このフレームワークを使用すると、開発者は複数のテスト指標を迅速に実装し、最小限のセットアップでモデルのパフォーマンスに関する複数のテストを実行できます。フィードバック ループが高速になるため、迅速に改善を行えます。
-
RAG 検索システムのポイントワイズ評価を実施します。
-
次の基準に基づいてモデルスコアを生成します。
-
回答の根拠: 生成されたテキストが、ソース ドキュメントから取得された事実情報とどの程度一致しているか。
-
詳細度: 回答の長さと詳細さ。包括的な理解には有益ですが、詳細度が高すぎると、質問に簡潔かつ正確に答えることの難しさが示される場合があります。そのような場合は、ユースケースに基づいて、この指標をチューニングすることをおすすめします。
-
指示の実行: 与えられた指示に正確かつ包括的に従うテキストを生成するシステムの能力。これにより、出力がユーザーの意図に関連し、一致することが保証されます。
-
指示に関連する質問応答品質: ユーザーの質問に詳細かつ一貫性を持って正しく回答するテキストを生成する RAG システムの能力。
-
結果を Vertex AI Experiments などの共有の場所に保存すると、時間の経過に伴う簡単な比較が可能になります。
ステップ 2. 根本原因の分析と反復テスト
再現可能なテスト フレームワークを設定する目的は、問題の根本原因を理解することです。RAG は基本的に、(1)最近傍一致の検索精度と(2)回答を生成する LLM に提供するコンテキストという 2 つのコンポーネントに基づいています。
これらのコンポーネントを個別に識別して分離することで、問題の原因となっている可能性のある特定の領域を判断し、テスト可能な仮説を立て、生成 AI 評価フレームワークを使用して Vertex AI で実行できます。
通常、根本原因の分析演習を実行する場合、ベースラインとしてテスト実行を行い、RAG コンポーネントの 1 つの実装を変更して、テスト実行を再度行います。テスト指標の出力スコア間の差分は、変更した RAG コンポーネントによるものです。このフェーズの目標は、選択した各指標で最大スコアに最適化することを目指して、コンポーネントを慎重に変更して文書化することです。多くの場合、テスト実行の間に複数の変更を加えたくなりますが、これを行うと、特定のプロセスの影響や、RAG システムに測定可能な変更を作成することに成功したかどうかが見えなくなってしまう可能性があります。
実行する RAG テストの例
テストする RAG コンポーネントの例:
-
回答生成を改善するために LLM に渡すドキュメント チャンクの理想的な隣接数はどのくらいか?
-
埋め込みモデルの選択は検索精度にどのように影響するか?
-
さまざまなチャンク戦略は品質にどのように影響するか?たとえば、チャンクサイズやオーバーラップなどの変数を調整したり、チャンクを前処理して言語モデルで要約または言い換えるなどの戦略を検討します。
-
生成に関しては、モデル A とモデル B やプロンプト A とプロンプト B を比較するだけで、プロンプト設計をファインチューニングしたりモデル構成を調整したりするのに特に役立ち、開発者が特定のユースケースに合わせてモデルとプロンプトを最適化できるようになります。
-
タイトル、作成者、タグなどのメタデータを使用してドキュメントを拡充し、検索シグナルを改善するとどうなるか?
独断的なタイガーチームのアクション
-
生成タスクのモデル A とモデル B をテストします(シンプルで、測定可能な結果を生成できます)。
-
単一の埋め込みモデル内で検索のためのチャンク戦略をテストします(400 文字、600 文字、1200 文字、完全なドキュメント テキスト)。
-
長いチャンクを前処理して、より小さなチャンクサイズにまとめることをテストします。
-
コンテキストとしてどのデータを LLM に渡すのかをテストします。たとえば、一致したチャンク自体を渡すのか、これをルックアップとして使用してソース ドキュメントを見つけ、長いコンテキスト ウィンドウを利用してドキュメント テキスト全体を LLM に渡すのかをテストします。
ステップ 3. 人間による評価
テスト フレームワークによって作成された定量的指標から得られるデータは貴重ですが、実際のユーザーによる定性的フィードバックも重要です。自動テストツールはスケーラビリティと迅速なイテレーションには効果的ですが、高品質の出力を保証するという点では、人間の判断を再現することはできません。人間のテスターは、回答のトーン、説明の明確さ、潜在的な曖昧さなどの微妙な側面を評価できます。定性的テストと定量的テストを組み合わせることで、RAG システムのパフォーマンスをより包括的に理解できます。
人間によるテストは通常、自動テスト フレームワークを通じて評価指標を最適化し、ベースラインの回答品質が安定したレベルに達した後に実行します。パフォーマンス、UX など、システム全体のより広範なユーザーテスト動作の一部として、人間による回答評価を含めることもできます。前述のテストと同様に、人間のテスターは構造化された手順に従って特定のシステム機能に焦点を当てることも、アプリケーション全体を評価して包括的な定性的フィードバックを提供することもできます。
人間によるテストは時間がかかり、繰り返し実施するため、積極的に関与し、意味のあるフィードバックを提供してくれるユーザーを特定することが不可欠です。
独断的なタイガーチームのアクション
-
RAG システムのターゲット ユーザーに基づいて主要なペルソナを特定します。
-
現実的なフィードバックを確実に得るために、これらのペルソナに一致する参加者の代表サンプルを募集します。
-
可能であれば、テストには技術系と非技術系の両方のユーザー グループを含めます。
-
ユーザーと同席して(可能であれば)、フォローアップの質問をして、回答の詳細を掘り下げます。
まとめ
独自の評価を開始するには、Google Cloud の Gen AI Evaluation Service を詳細に確認してください。ここでは、事前構築された評価方法とカスタム評価方法の両方を作成して、RAG システムを強化できます。



