Cloud Vision API によって画像を有効活用する方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 5 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
この投稿では、Vision API で画像から意味を抽出する画期的な方法をいくつかご紹介します。このまま読み進めていただくことも、Python、Node.js、Go または Java を使用したチュートリアルに直接移動することもできます。このチュートリアルは、Google Cloud の無料枠の範囲内で完了することができます。
「1 枚の写真は千の言葉に値する」という英語のことわざがありますが、その「言葉」を利用可能にして役立つようにするにはどうすればよいでしょうか?世界中で、かつてないほど多くの画像が生成されています。こうして増え続けるデータがもたらす計り知れない機会に対応するために、企業が画像認識テクノロジーに注目するのは当然とも言えます。
Cloud Vision API は、画像データに対してラベル検出、テキスト認識、オブジェクト トラッキングなどのさまざまなタスクを実行できる優れたツールです。小売店での商品の識別、ブランドへの言及に関するソーシャル メディア投稿の分析、特定のオブジェクトを見つけるための数百万の画像のスキャンなど、企業は Cloud Vision API を使用して画像分析ワークフローを自動化し、視覚データから有用な分析情報を得ることができます。また、この API は、プライバシーを保護し、責任を持って構築できるようにするために、人をぼかして識別可能な特徴を隠すなどの、個人の識別を制限する機能を提供します。
では、Cloud Vision API の主な機能をいくつか見ていきましょう。
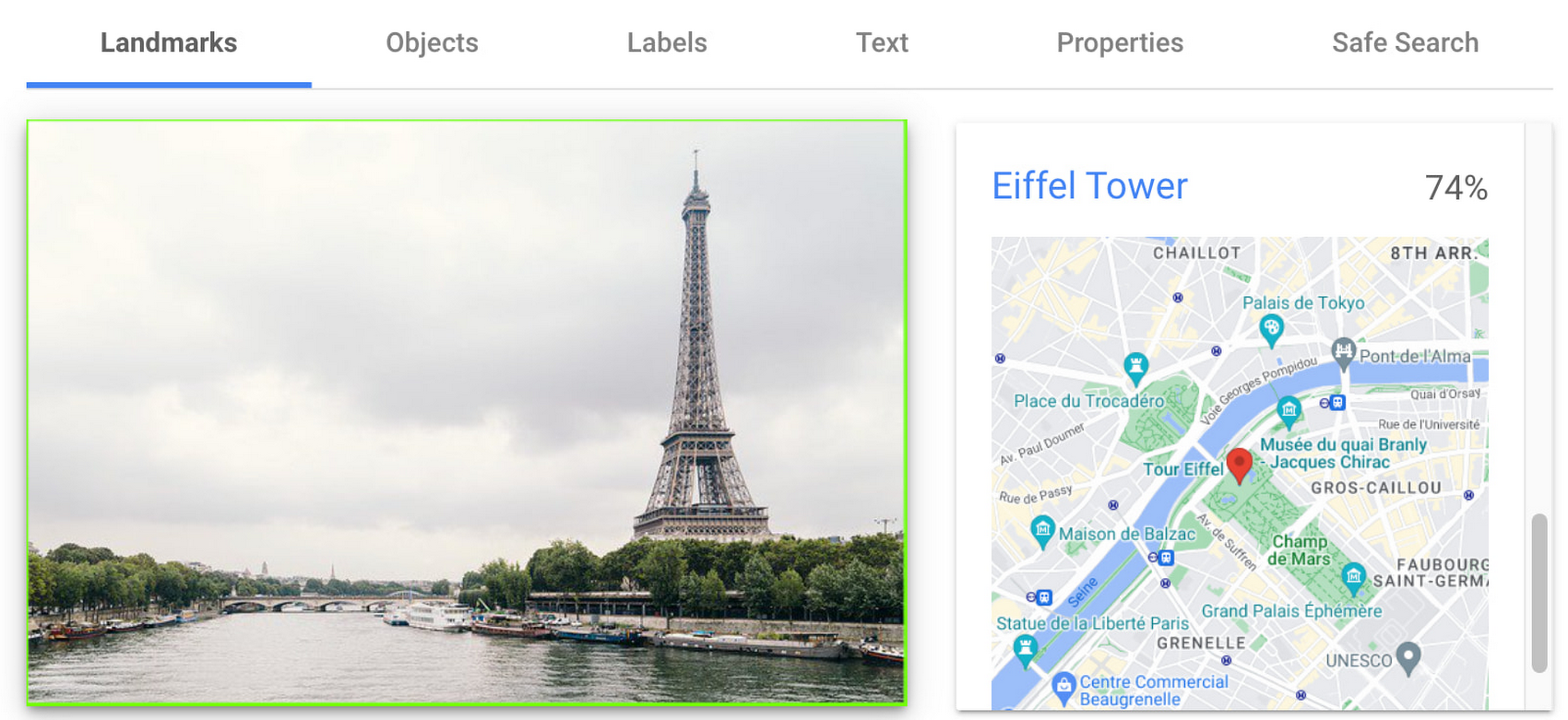
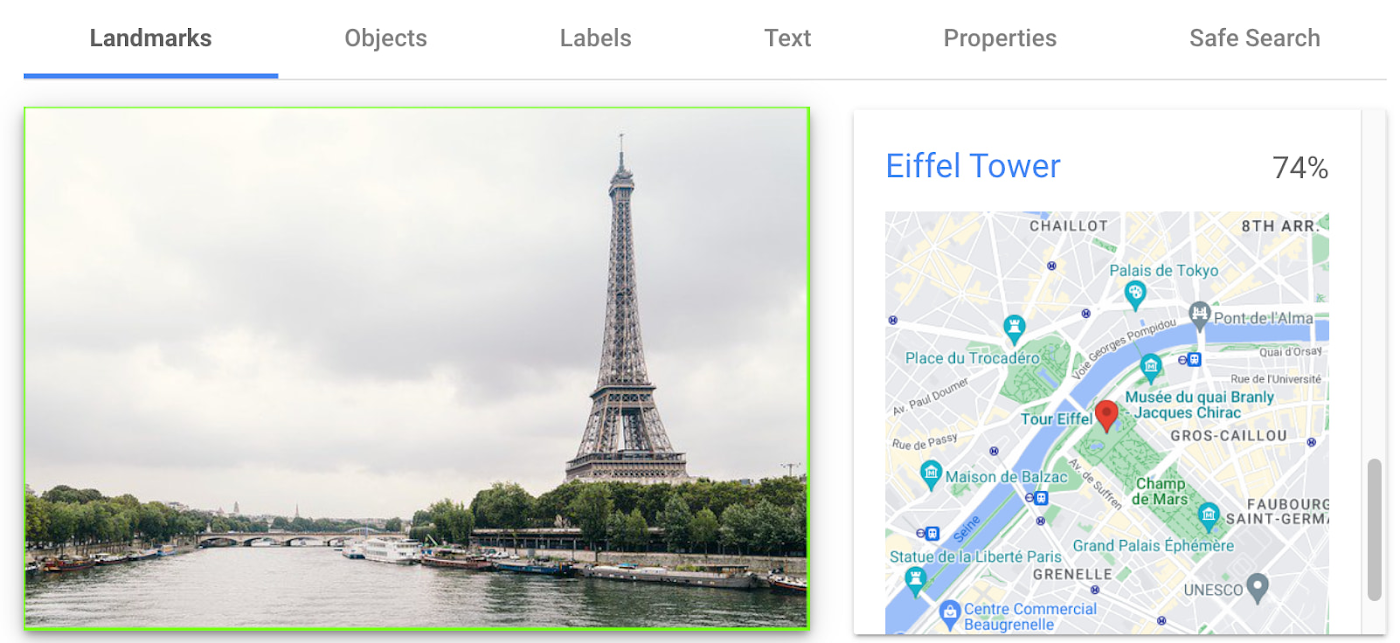
有名なランドマークの検出
ランドマーク検出を使用すると、画像を分析して、建物、自然特性、その他の認識可能な場所など、特定のランドマークを識別できます。Cloud Vision API はランドマークを認識し、その名前、場所、その他の関連する詳細情報を提供します。ソーシャル キャンペーンの一環として顧客が共有した画像内のランドマークを特定しようとしたり、有名なランドマークに関する情報を観光客に提供するモバイルアプリの構築を考えたりしたことはありませんか?
下の左側の画像では、Cloud Vision API がエッフェル塔を検出し、可視化されたレスポンスが表示されています。この画像には表示されていませんが、ビル アケム橋とシャン ド マルス公園(エッフェル塔前の公園)も検出されています。
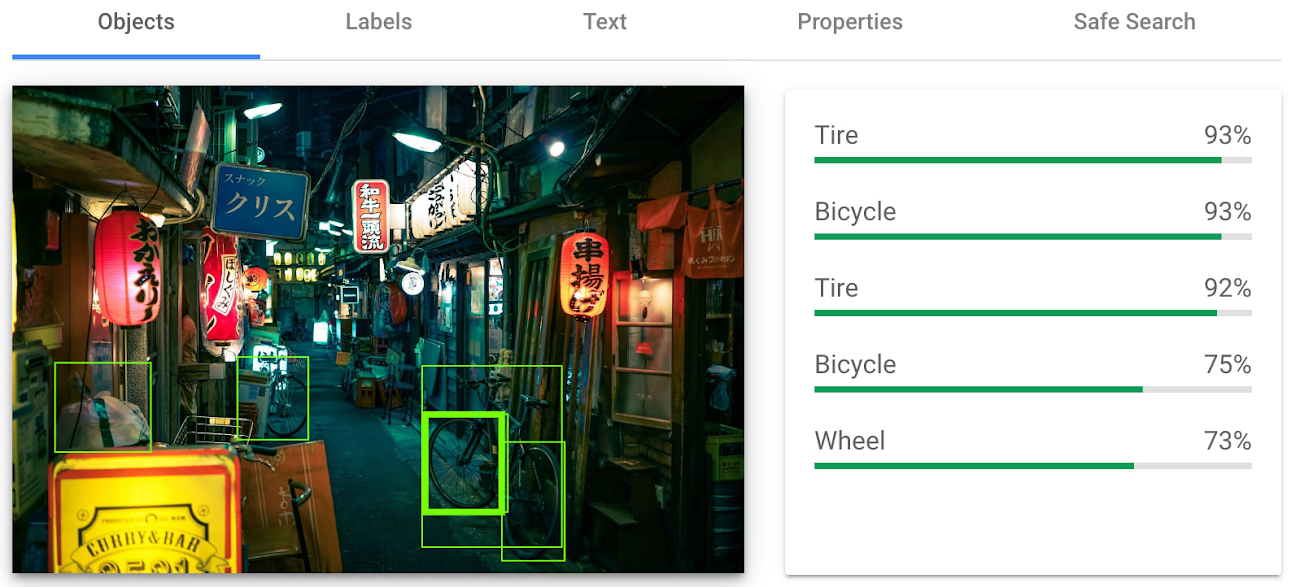
オブジェクトの検出と画像へのラベル付け
オブジェクト検出とラベルは、画像内のオブジェクトを識別して分類するための 2 つの関連した機能です。オブジェクト検出は、画像内のオブジェクトを検出して位置を特定し、各オブジェクトの位置、サイズ、向きなどの情報を提供します。一方、ラベルでは、画像内のコンテンツの一般的な分類が可能です。
オブジェクト検出は、自動運転車、小売業、製造業など、多くの業界で実際に応用されており(自動車業界では特に重要)、ラベルは、大量の画像の分類や整理、またはコンテンツの分類やフィルタに使用できます。
世田谷で撮影されたこの画像では、オブジェクト検出機能とラベル付け機能が提供するレスポンスの類似点と相違点を確認できます。
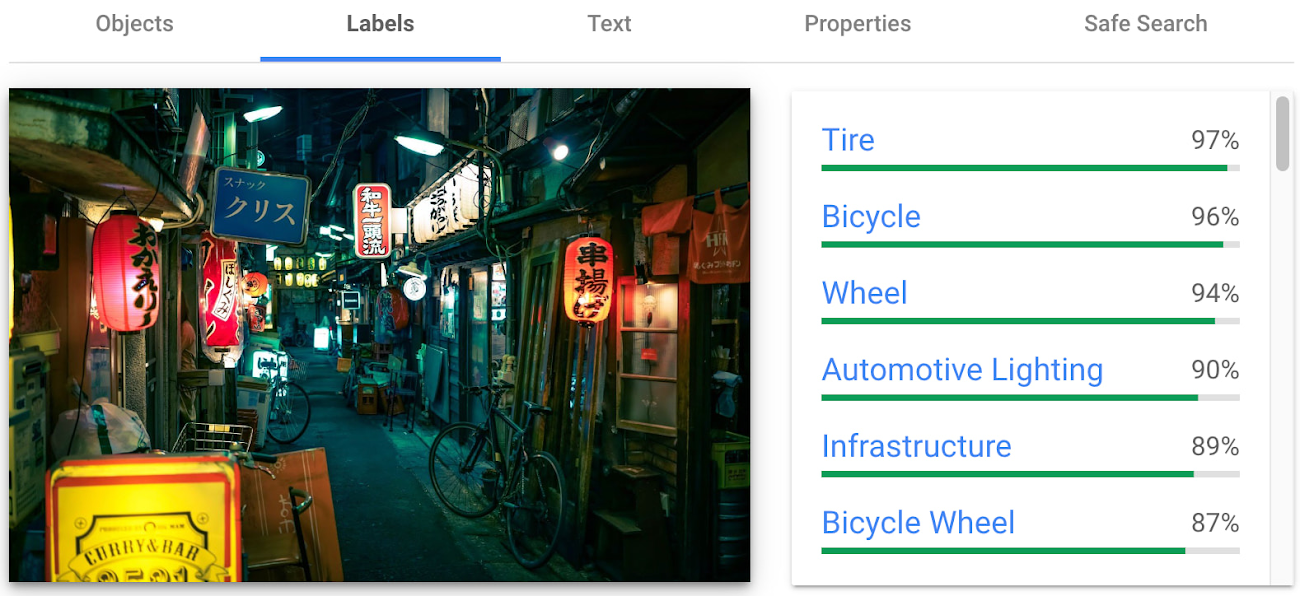
テキストの検出
Cloud Vision API は、手書き文字や異なる言語であっても、あらゆる画像からテキストを検出して抽出します。API は、テキストを検出すると、各テキスト要素の位置、向き、サイズに加え、個々の単語、その境界ボックスに関する情報を提供します。
この交通標識の画像では、Cloud Vision API がテキストを検出し、それをレスポンスで表示しています。
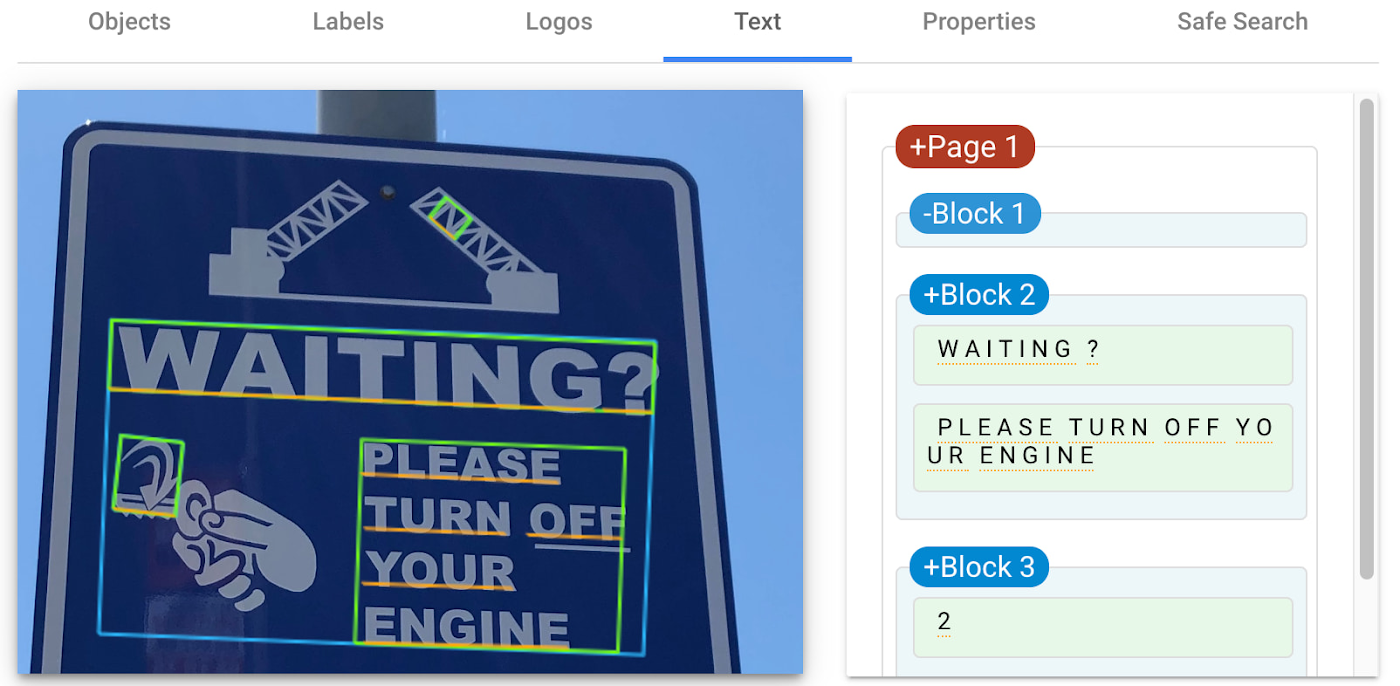
テキスト検出機能によるレスポンスの可視化。
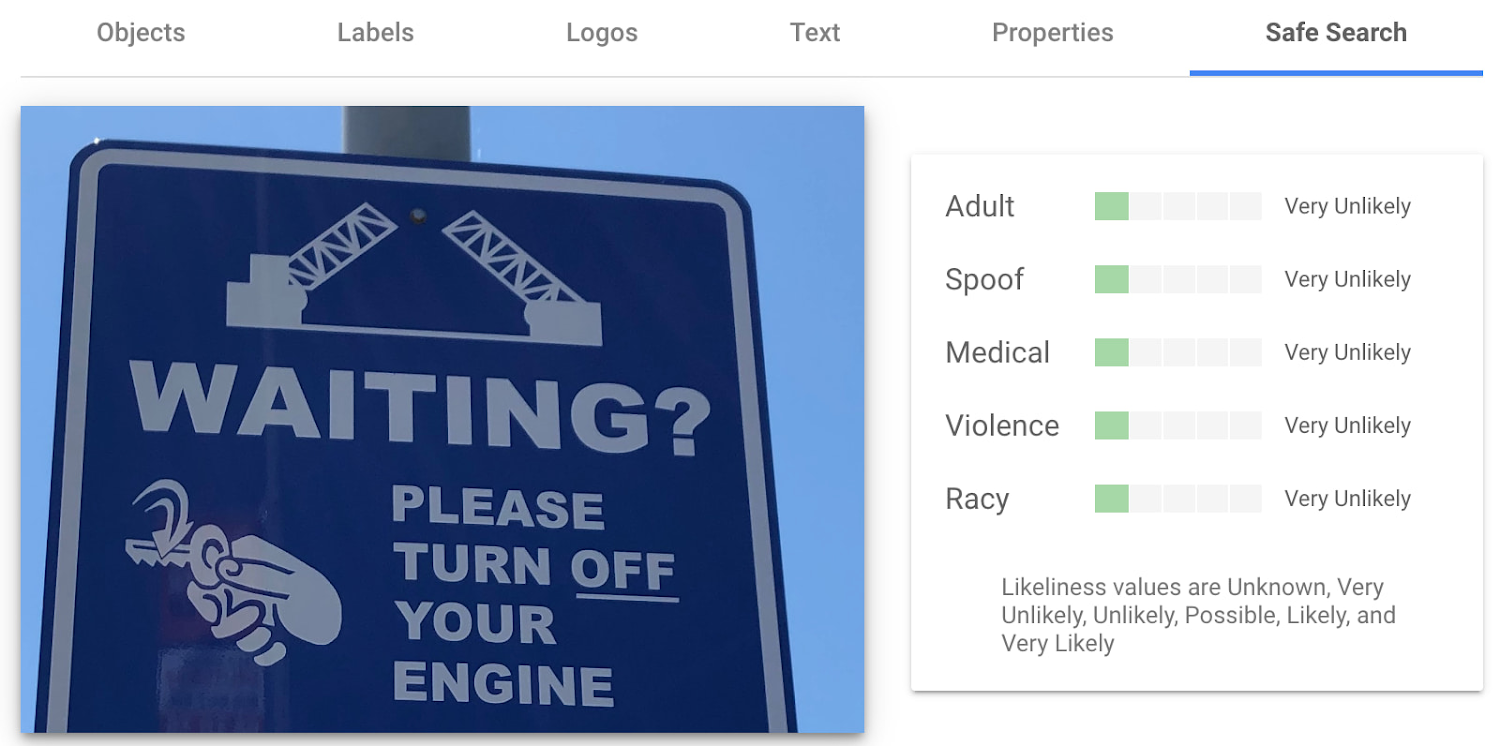
露骨な表現を含むコンテンツの検出
Cloud Vision API は、5 つのカテゴリ(アダルト、なりすまし、医療、暴力、露骨)を使用して、画像内の露骨なコンテンツや不適切なコンテンツを自動的に識別し、フラグを立てることができます。API が画像内における各カテゴリの可能性を示すスコアを提供するため、これを使用してアプリケーションのしきい値を設定し、しきい値を超えた場合の処理方法を決定できます。この機能は特に、ユーザー作成コンテンツのフィルタや管理に役立ちます。
幸いなことに、私がここで共有した画像については、各カテゴリが存在する可能性は「非常に低い」と見なされています。一安心です。