ML 生産性グッドプットの概要: AI システムの効率性を測定する指標

Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
現在、コンピューティングは非常に面白い時代を迎えています。大規模生成モデルは、かつては調査研究のためのものでしたが、今では教育、創作、ソフトウェア設計などの分野における基本的なテクノロジーの活用方法と言えるまでに普及しました。利用可能なコンピューティング能力(一般的にモデルのトレーニングに必要な浮動小数点演算数で測られます)がこれまでになく高まるなか、これらの基盤モデルの性能や機能も向上し続けています。
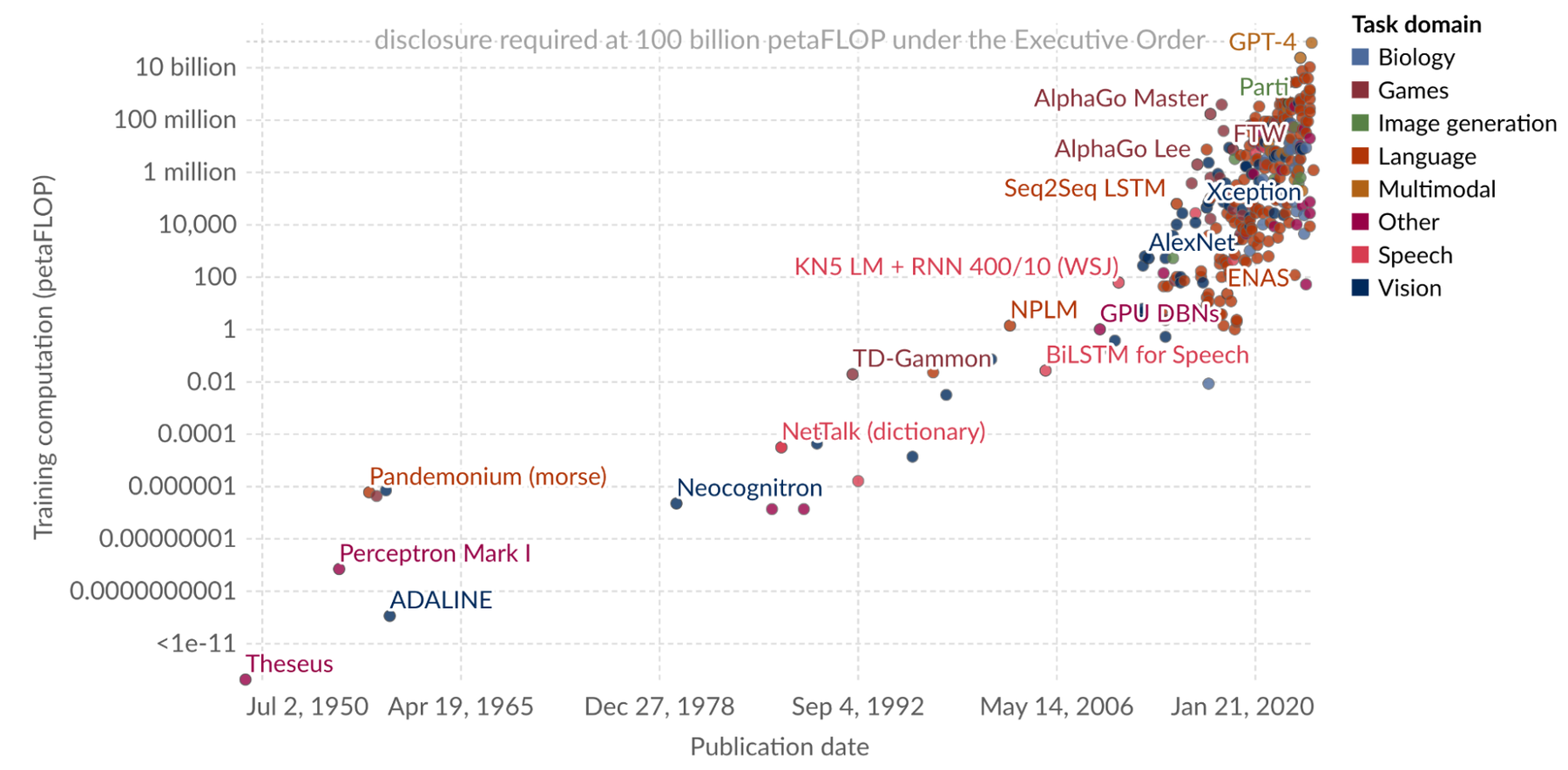
有名なモデルのコンピューティング規模の飛躍的な成長。出典: Our world in data
コンピューティングの規模の急拡大は、より大規模で効率性の高いコンピューティング クラスタによってもたらされています。しかし、(ノード数やアクセラレータ数で測られる)コンピューティング クラスタの規模が拡大するにつれ、システム全体としての平均故障間隔(MTBF)は線形的に短縮する一方、故障率は線形的に増加します。さらに、インフラストラクチャのコストも線形的に増加します。そのため、故障に伴う全体的な費用は、コンピューティング クラスタの規模に対して 2 乗のオーダーで増加します。
大規模なトレーニングにおいては、全体的な ML システムの真の効率性がトレーニング実施の肝となります。効率性を高める取り組みなしでは、一定以上の規模を実現できなくなる可能性があります。しかし適切に設計することができれば、より大きな規模で新たな可能性を切り開くことができます。このブログ投稿では、このような効率性を測定するための新たな指標である ML 生産性グッドプットについてご紹介します。また、プロジェクトに統合してグッドプットを測定およびモニタリングできる API、そして ML 生産性グッドプットを最大化するための方法について説明します。
ML 生産性グッドプットの概要
ML 生産性グッドプットは、スケジューリング グッドプット、ランタイム グッドプット、プログラム グッドプットの 3 つのグッドプット指標で構成されています。
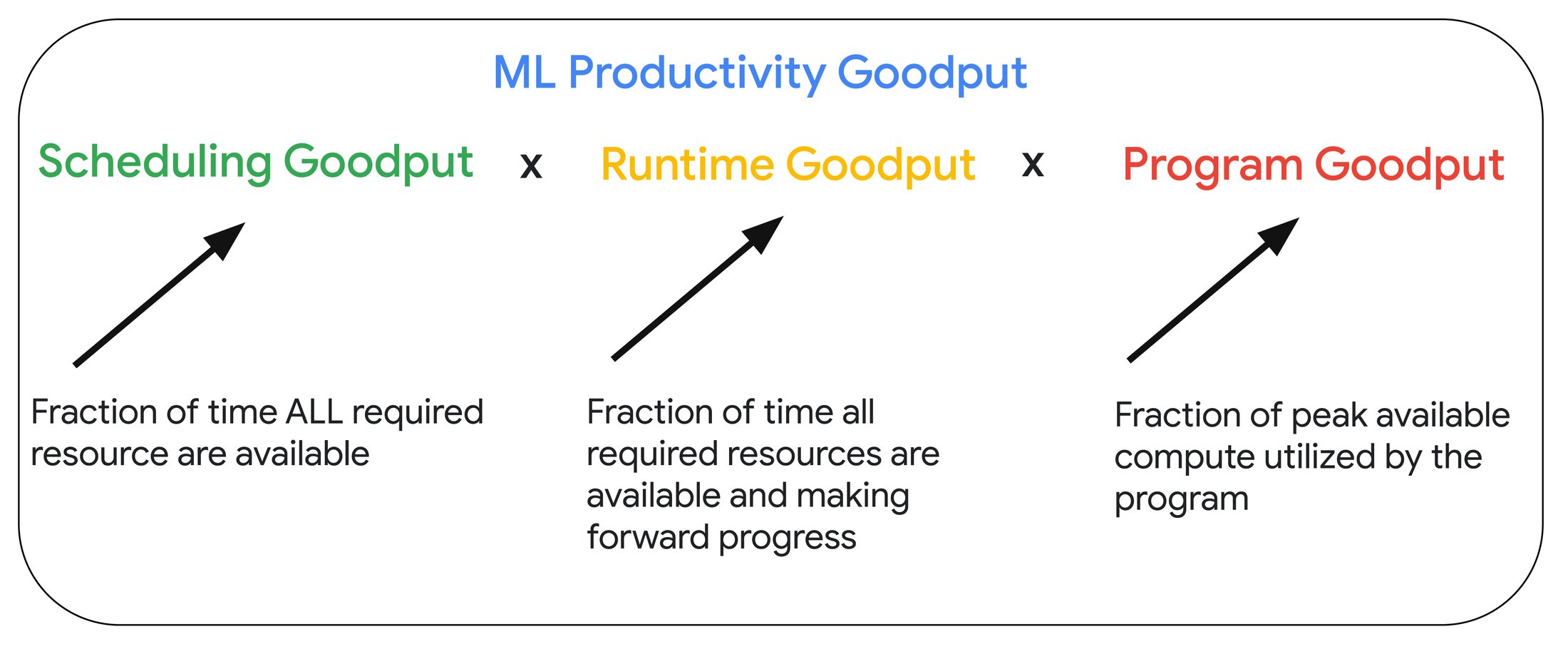
スケジューリング グッドプットは、トレーニング ジョブを実行するために必要なすべてのリソースが利用可能な時間の割合を測定したものです。オンデマンドまたはプリエンプティブルな利用モデルにおいては、リソース不足が発生する可能性があるためこの指標は 100% 未満となります。そのため、スケジューリング グッドプットのスコアを最適化できるようリソースを予約することをおすすめします。
ランタイム グッドプットは、すべてのトレーニング リソースが利用可能な場合に、トレーニングを進めることのできた時間の割合を測定したものです。ランタイム グッドプットを最大化するには、設計において入念な検討が必要となります。Google Cloud 上の大規模なトレーニング ジョブにおいて、ランタイム グッドプットをどのように測定して最大化することができるかについては次のセクションで説明します。
プログラム グッドプットは、ピーク ハードウェア パフォーマンスのうち、トレーニング ジョブが利用できる割合を測定したものです。プログラム グッドプットは「モデルの FLOP 使用率(モデルの実効 FLOP 使用率)」とも呼ばれます。つまり、システムのピーク スループットのうち、モデルのトレーニングのスループットが占める割合を示します。プログラム グッドプットは、効率的なコンピューティングと通信のオーバーラップや、必要なアクセラレータ数に効率的にスケールするための入念な分散戦略などの要素に左右されます。
Google の AI ハイパーコンピュータ
AI ハイパーコンピュータには、AI のトレーニング、チューニング、アプリケーションへのサービス提供といった領域にわたり ML の生産性を高めるためのシステムレベルでの共同設計により構築された、選び抜かれた機能のセットが組み込まれています。以下の図は、ML 生産性グッドプットの各要素が AI ハイパーコンピュータで具体化されている様子を示します。
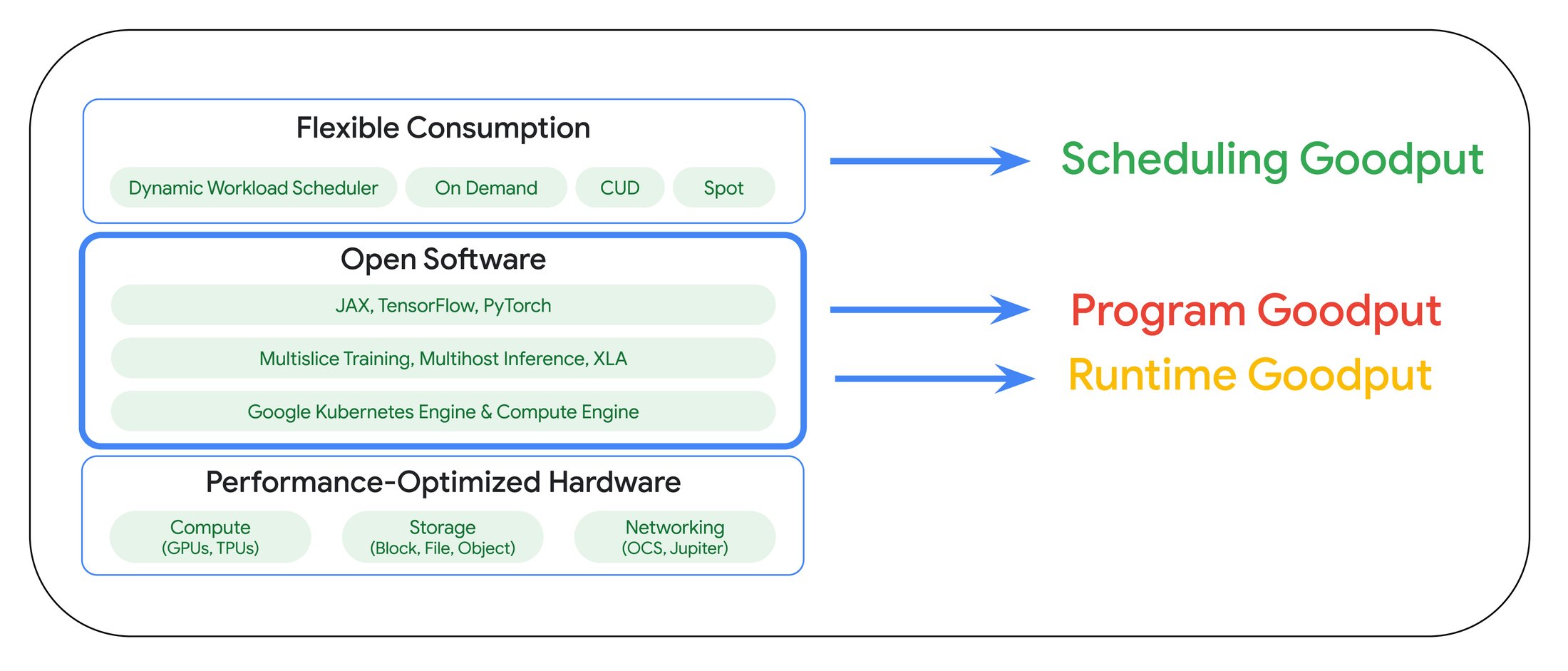
上図に示したように、AI ハイパーコンピュータではフレームワーク、ランタイム、オーケストレーションのレイヤにわたりプログラムおよびランタイム グッドプットを最適化できるよう、具体的な機能が盛り込まれています。本投稿の以降のセクションでは、AI ハイパーコンピュータにおいてグッドプットの最大化につながる要素に焦点を当てて説明します。
ランタイム グッドプットについて
ランタイム グッドプットを突き詰めると、特定の時間枠において完了した、有効なトレーニング ステップの数ということになります。想定されるチェックポイントの間隔、スライスを再スケジュールするまでの時間、そしてトレーニングを再開するまでの時間に基づき、以下のようにランタイム グッドプットを推定できます
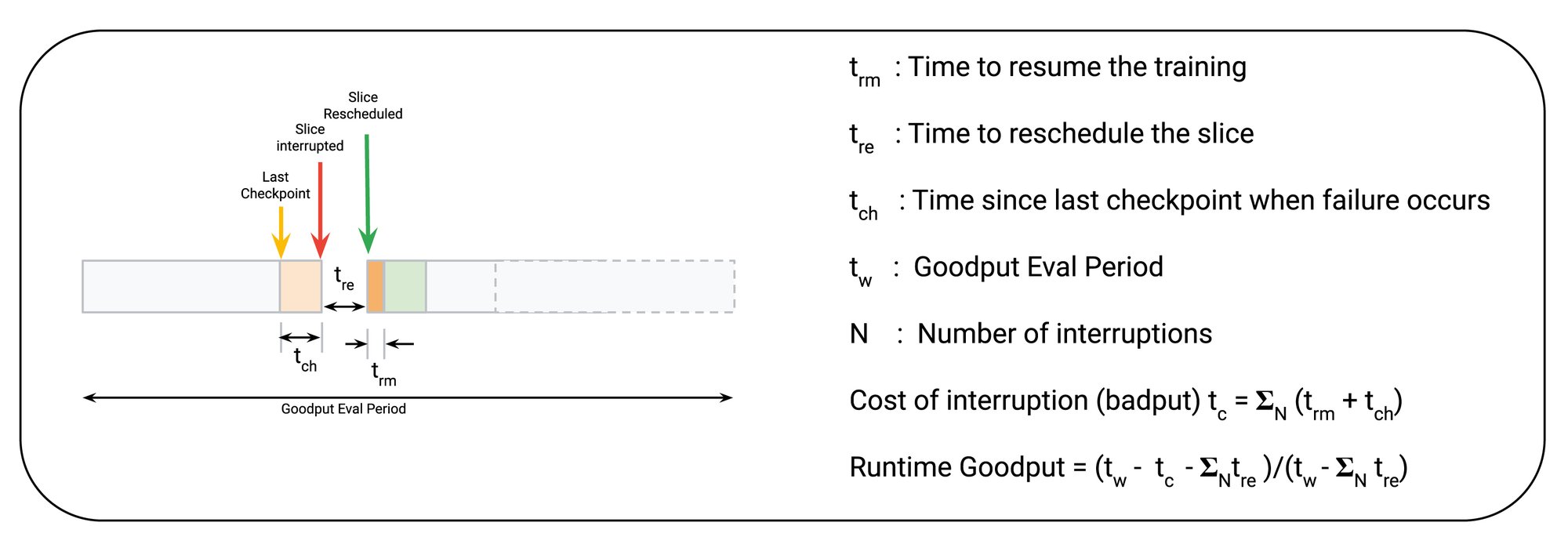
この分析モデルでは、1)障害が発生したときの最後のチェックポイントからの経過時間(tch)、2)トレーニング再開までの時間(trm)、3)スライスの再スケジュールまでの時間(tre。これも重要な要素ではありますが、スケジューリング グッドプットのセクションで説明します)の 3 つの具体的な要素を使用してスコアが計算されます。ランタイム グッドプットを最大化するためには、これらを最小化する必要があります。
Goodput Measurement API の概要
指標を改善するには、まず測定しなければなりません。Goodput Measurement API を使用すると、Python パッケージを使用して(スケジューリング グッドプット × ランタイム グッドプット)の測定をコードに実装できます。Goodput Measurement API では、Cloud Logging にトレーニング ステップの進行状況をレポートし、Cloud Logging からその進行状況を読み取ってランタイム グッドプットを測定し、モニタリングするためのメソッドが用意されています。
スケジューリング グッドプットの最大化
スケジューリング グッドプットは、トレーニングの実行に必要なすべてのリソースの可用性に左右されます。短期的な使用におけるグッドプットを最大化できるよう、トレーニング ジョブのためにコンピューティング リソースを予約できる DWS カレンダー モードが導入されました。さらに、中断から再開する際のリソースのスケジュールにかかる時間 tre を最小化するために、「ホットスペア」の使用をおすすめします。リソースの予約とホットスペアにより、スケジューリング グッドプットを最大化できます。
ランタイム グッドプットの最大化
AI ハイパーコンピュータには、ランタイム グッドプットを最大化するための以下の方法が用意されています(これらを使用することをおすすめします)。
-
自動チェックポイントの有効化
-
コンテナのプリロードの使用(Google Kubernetes Engine で利用可能)
-
永続コンパイル キャッシュの使用
自動チェックポイント
自動チェックポイントを使用すると、トレーニング ジョブが中断されようとするときに発生する SIGTERM シグナルに基づきチェックポイント作成をトリガーできます。デフラグ関連のプリエンプションやメンテナンス イベントが発生すると、最後のチェックポイント以降に進行した処理が失われますが、自動チェックポイントにより、失われる処理を少なく抑えることができます。
自動チェックポイントの実装例として Orbax や MaxText があります。MaxText は、Google Cloud におけるモデルのトレーニングおよび推論のための高パフォーマンスなリファレンス実装です。
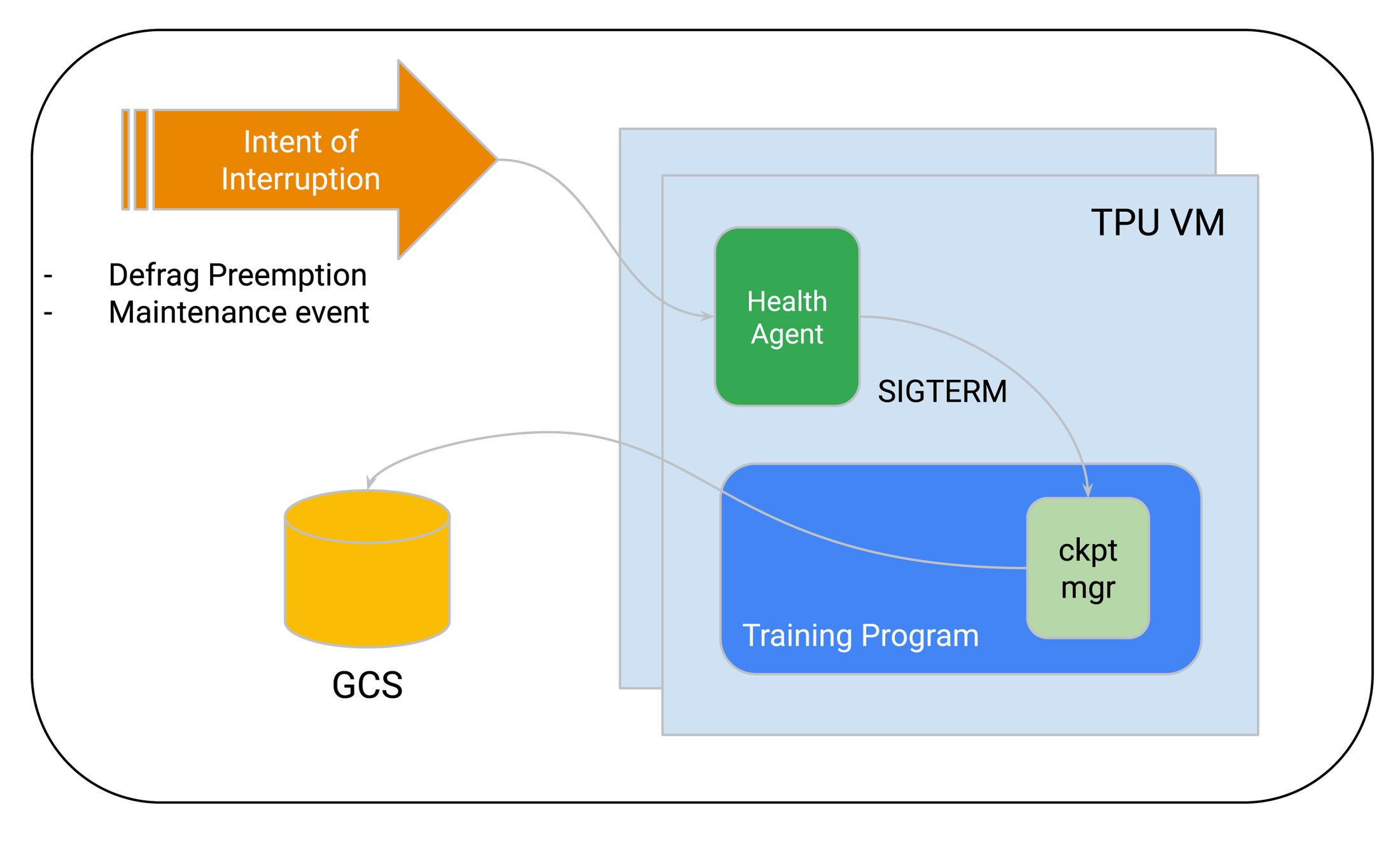
自動チェックポイントは、GKE ベースおよび非 GKE ベースの両方のトレーニング オーケストレータで利用でき、Cloud TPU および GPU のいずれにおけるトレーニングでも利用できます。
コンテナのプリロード
最大のグッドプット スコアを実現するためには、障害やその他の中断の発生後、迅速にトレーニングを再開できることが重要です。そのために、Google Kubernetes Engine(GKE)の使用をおすすめします。GKE は、セカンダリ ブートディスクからのコンテナとモデルのプリロードをサポートしています。現在プレビュー版として提供されている GKE のコンテナとモデルのプリロードを使用すると、ワークロード、特にサイズの大きいコンテナ イメージを非常に短時間で起動することができます。そのため、障害やその他の中断が発生しても、トレーニング復旧までの時間のロスを最小限に抑えることができます。ジョブの再開時に大きなコンテナ イメージをオブジェクト ストレージから pull するには長い時間がかかることがあります。そのため、この時間を短縮することが重要です。プリロードでは、ノードプール作成時や、自動プロビジョニング時に必要となるコンテナ イメージを格納したセカンダリ ブートディスクを指定できます。障害が発生したノードが GKE により起動されるとすぐに必要なコンテナ イメージを利用できるため、速やかにトレーニングを再開できます。
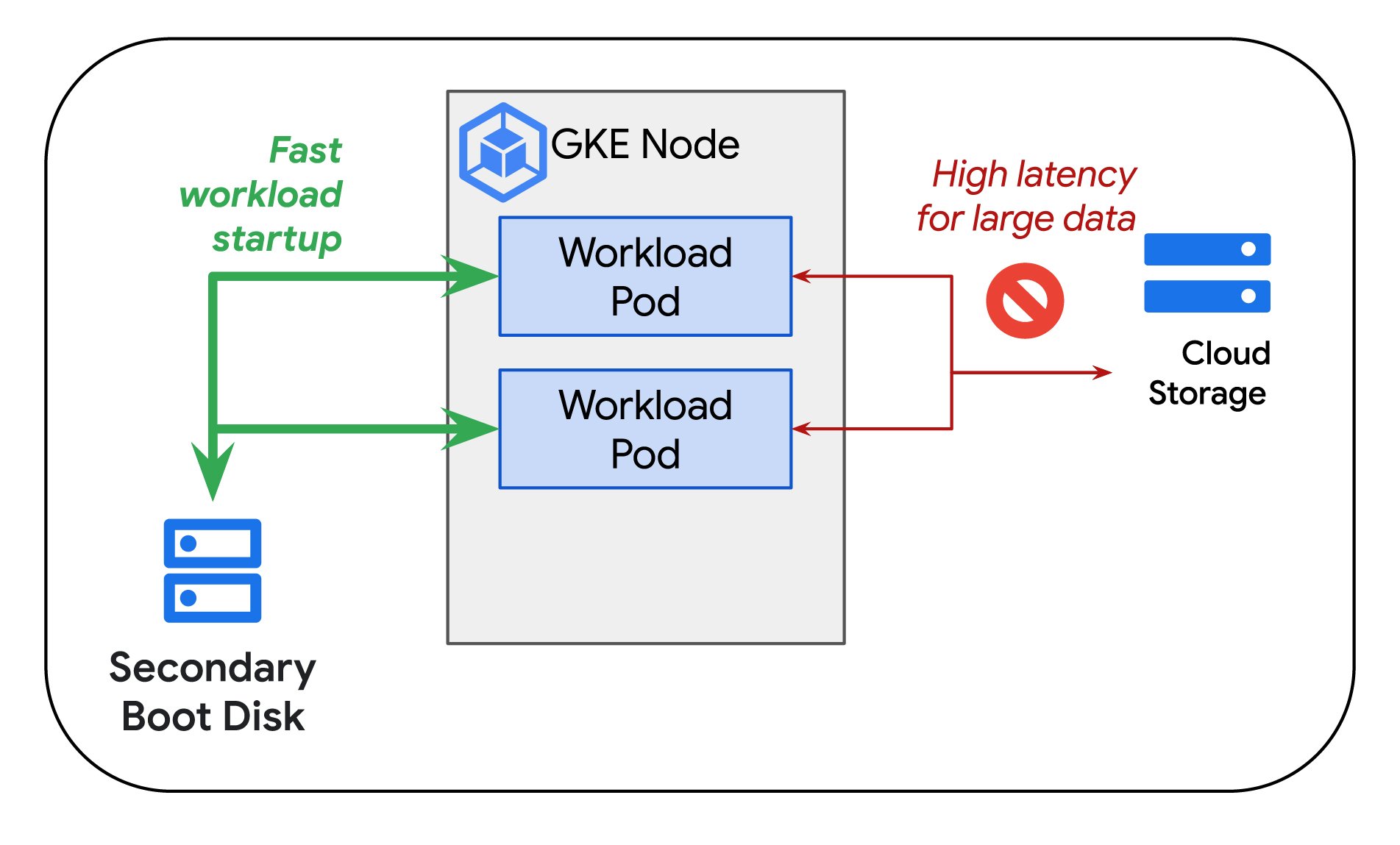
コンテナのプリロードを使用した場合、Google の測定では、16 GB のコンテナのイメージ pull オペレーションにかかる時間をベースラインと比較して約 29 倍高速化できました(Container Registry からのイメージの pull)。
永続コンパイル キャッシュ
ジャストインタイム コンパイルやシステムに対応した最適化は、XLA コンパイラ ベースのコンピューティング スタックにおいて重要な要素です。計算グラフを一度だけコンパイルし、異なる入力データを使用して多数回実行できれば効率が高まるため、ほとんどの高パフォーマンスなトレーニング ループではこの方法が使用されています。コンパイルをキャッシュすることにより、グラフの形状が同じであれば再コンパイルする必要がなくなります。しかし、障害や中断が発生した場合はこのキャッシュが失われる可能性があるため、トレーニングの再開プロセスに時間がかかり、ランタイム グッドプットが低下します。永続コンパイル キャッシュでは、コンパイル キャッシュを Cloud Storage に保存し、再起動イベントの前後を通してキャッシュを永続化できるため、この問題が解決されます。
さらに、AI ハイパーコンピュータの推奨オーケストレーション レイヤである GKE では、最近ジョブ スケジューリングのスループットが 3 倍向上したため、再開までの時間(trm)の短縮につながります。
プログラム グッドプットの最大化
プログラム グッドプット(モデルの FLOP 使用率)は、トレーニング プログラムが進行する際に、基盤となるコンピューティング リソースを効率的に利用できるかどうかに左右されます。プログラム グッドプットを高めるうえで大切なのは、分散戦略、効率的なコンピューティングと通信のオーバーラップ、最適化されたメモリアクセス、効率的なパイプライン設計です。XLA コンパイラは、プログラム グッドプットを最大化できるように設計された AI ハイパーコンピュータのコア コンポーネントの一つです。すぐに使用できる最適化機能や、GSPMD などのシンプルで高パフォーマンスなスケーリング API を備えており、ユーザーはさまざまな並列処理を簡単に記述して効率的にスケーリングを利用できます。JAX および PyTorch/XLA ユーザー向けに、プログラム グッドプットを最大化するための 3 つの主な機能を最近導入しました。
XLA によるカスタム カーネル
コンパイラによるコンピューティングの最適化においては、ユーザーが基本プリミティブを使用して複雑な計算ブロックのより効率的な実装を記述できる「非常口」とも呼べるものが必要になることがよくあります。これにより、デフォルトのパフォーマンスをさらに高めることを目指します。JAX/Pallas は、Cloud TPU および GPU のためのカスタム カーネルをサポートできるよう構築されたライブラリで、JAX および PyTorch/XLA の両方をサポートしています。Pallas を使用して記述されたカスタム カーネルの例としては、Flash Attention やブロック スパース カーネルがあります。Flash Attention カーネルは、シーケンス長が長い場合にプログラム グッドプット(モデルの FLOP 使用率)改善に役立ちます(4K 以上のシーケンス長の場合に特に 顕著な効果が見られます)。
ホストへのオフロード
大規模なモデルのトレーニングではアクセラレータのメモリリソースに制約があるため、活性化や再実体化などで、コンピューティング サイクルとアクセラレータのメモリリソースのトレードオフが生じることがよくあります。ホストへのオフロードも最近 XLA コンパイラに導入された手法で、ホストの DRAM を利用して、フォワードパスで計算される活性化をオフロードし、バックワード パスでの勾配計算で再利用します。これにより、活性化の再計算サイクルを省略できるので、プログラム グッドプットが向上します。
AQT を使用した int8 による混合精度トレーニング
Accurated Quantized Training は、トレーニング ステップの行列乗算のサブセットを int8 にマッピングすることにより、収束に悪影響を与えることなくトレーニングの効率性とプログラム グッドプットを向上させる手法です。
以下のベンチマークは、MaxText を使用した 1,280 億個のパラメータによる高密度 LLM 実装について、上記の手法を組み合わせることでプログラム グッドプットが向上する様子を示しています。
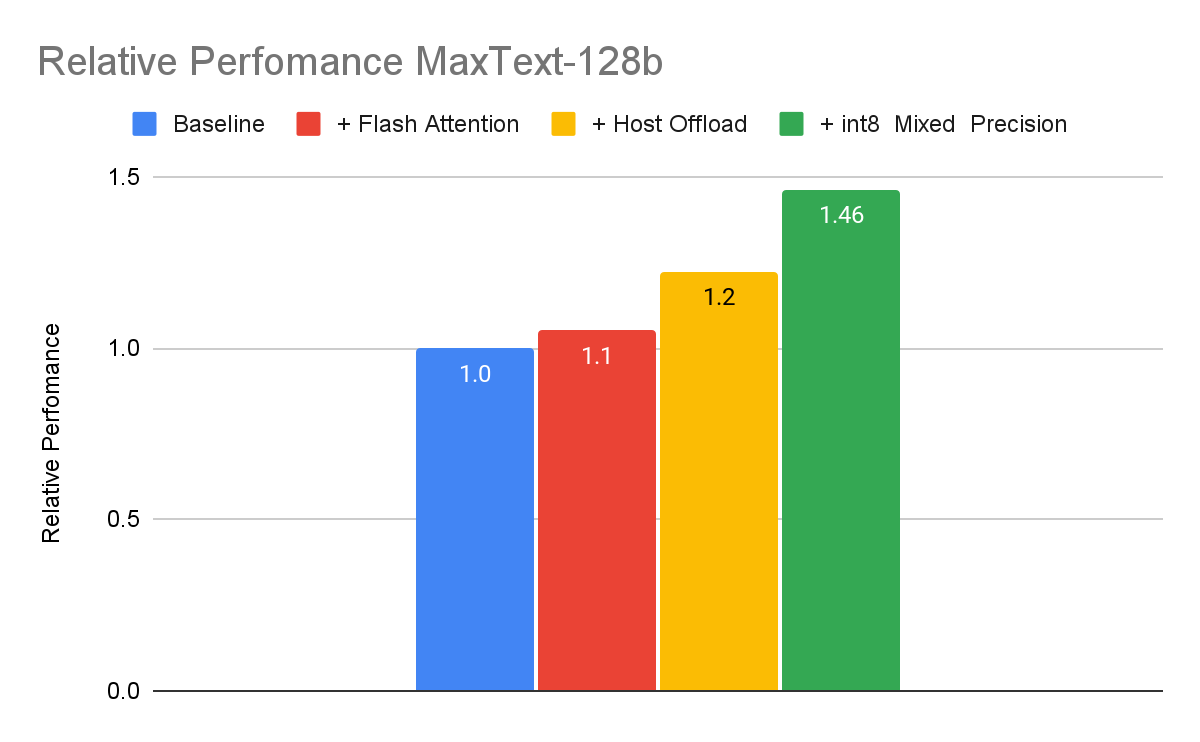
EMFU が MaxText 128b を使用して測定、コンテキスト長 2048、合成データでトレーニング、Cloud TPU v5e-256 を使用。測定日: 2024 年 4 月
このベンチマークでは、これら 3 つの手法を組み合わせることで、プログラム グッドプットを累計で最大 46% 高めることができました。多くの場合、反復的なプロセスを通してプログラム グッドプットの改善が進められます。具体的なトレーニング ジョブにおける実際の改善効果は、トレーニングのハイパーパラメータやモデルのアーキテクチャによって異なります。
まとめ
生成モデルの大規模なトレーニングはビジネス上の価値を高めるためには欠かせませんが、規模が大きくなるにつれて ML トレーニングの生産性の確保が課題となります。この投稿では、大規模なトレーニング ジョブにおける全体的な ML の生産性を測定する ML 生産性グッドプットという指標を定義しました。Goodput Measurement API について紹介し、大規模なトレーニングにおいて ML 生産性グッドプットを最大化するのに役立つ AI ハイパーコンピュータの要素について説明しました。AI ハイパーコンピュータを活用して、大規模なトレーニングにおける ML 生産性を最大化するお手伝いができれば幸いです。
ー シニア プロダクト マネージャー Vaibhav Singh
ー プロダクト マネージャー Daniel Herrington



