パンや焼き菓子のレシピを AI で作成

Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
ケーキ、パン、クッキーの本質的な差異や科学的な違いを考えたことはありますか。私もありません。これまで議論が重ねられてきたこの重要な問題に、説明可能な機械学習がついに答えを見つけてくれました(答えのようなものと言った方がいいかもしれませんが)。
機械学習では、説明可能性とは、モデルが導き出した予測の根拠を少なくともある程度は理解できるように、モデルをどれだけ解釈しやすくできるかを追求することです。これは、モデルの判断結果に寄与したものを理解することなくディープ ニューラル ネットの予測をそのまま受け取るアプローチからのひとつの進展と言えます。本投稿では、パンや焼き菓子のレシピを分析する説明可能な機械学習モデルを構築する方法をご紹介します。さらに、そのモデルを使用して独自の新しいレシピを考え出します。ここでは、データ サイエンスの専門知識は必要ありません。
このプロジェクトの発案者は、Google Cloud で AI に取り組んでいる Sara Robinson です。4 月、Robinson はパンデミック時のパン菓子作りに没頭し始めました。そして機械学習の優秀な技術者がパン菓子作りをしたなら当然考えられることですが、モデリングの技術をすぐにパン菓子作りに取り入れました。レシピのデータセットを収集し、材料のリストを取り込んで次のような予測を提供する TensorFlow モデルを構築しました。Robinson はモデルを使って、レシピをタイプ別に正確に分類できただけでなく、まったく新しいレシピを生み出すこともできました。モデルで、おおよそ 50% がクッキーで 50% がケーキと判断された「ケイキー」というものです。

Sara Robinson のオリジナル、ケーキとクッキーの合体「ケイキー」
このレシピは成功間違いなしでした。
「おいしいです。機械にケーキとクッキーの合体を作るように言ったら、不思議と想像どおりの味わいになっています。」
ケイキーのレシピは彼女の個人ブログに掲載されています。
今年の 12 月、Robinson は Markowitz と協力して、パン菓子作りの次のバージョンのモデルを構築しました。このモデルでは、より大規模なデータセット、新しいツール、そしてケーキをケーキにし、クッキーをクッキーにして、パンをパンにするものの分析情報を提供する説明可能なモデルを使用しています。そのうえ、新しい合体レシピも生まれました。パン(ブレッド)とクッキーの合体「ブレッキー」です(ブルッキーと呼びたかったのですが、この名前はすでに使われていました)。

モデル作成の詳細をお読みください。下までスクロールすると、ブルッキーのレシピもあります。
説明可能なコードなしのモデルを ML で構築する
このプロジェクトには、AutoML Tables という Google Cloud ツールを使用することにしました。このツールを使用すると、スプレッドシートやデータベースのような表形式のデータに対して、機械学習モデルをコードなしで構築できます。AutoML Tables を選択したのは、使いやすいことと、特徴アトリビューション(これについては後で詳しくご説明します)といった新しい説明可能性ツールが組み込まれてアップグレードされたばかりだったことが理由です。
データの収集と準備
まず、ウェブからクッキー、ケーキ、パンのレシピのデータセットを約 600 件に収集しました(このデータセットは所有しているわけではないため、ここで共有することはできませんが、自分に合ったレシピのデータセットをオンラインで見つけられます)。次に、600 件のレシピそれぞれの材料から絞り込み、次の 16 個の主材料を選びました。
イースト
小麦粉
砂糖
卵
オイル(あらゆる種類)
牛乳
重曹
ベーキング パウダー
リンゴ酢
バターミルク
バナナ
かぼちゃのピューレ
アボカド
水
バター
塩
このモデルには、シナモン、チョコレート チップ、ナツメグといった他の材料は何も含めませんでした。これら 16 種類の材料は少し無作為に選んだところもありますが、食感と堅さに影響を与えるものを重視しました。食感に影響を与えることはなく、むしろモデルの「意図しない行為」につながる可能性がある材料は除外しました。たとえば、チョコレート チップは理論上どのようなレシピにも加えることができますが、パンに使われていることはめったにないので、このモデルが学習のヒントとして取り入れることがないように除外しました。
パンと言えば、甘いブレッドと呼ばれているもの(パンプキン ブレッド、バナナブレッド、ズッキーニ ブレッドなど)は「パン」のカテゴリから「ケーキ」のカテゴリに移しました。Great British Bake Off の審査員を務める Paul Hollywood 氏が Instagram で、バナナブレッドはパンではないと言っていることからも、このような思い切った決断に至りました。
レシピの材料の分量にはあらゆる単位が使われているため(たとえば、バターの場合、本、大さじ、オンスがあります)、すべての分量単位をオンスに変換しました(長々とした精巧とは言い難い if ステートメントを使いました)。
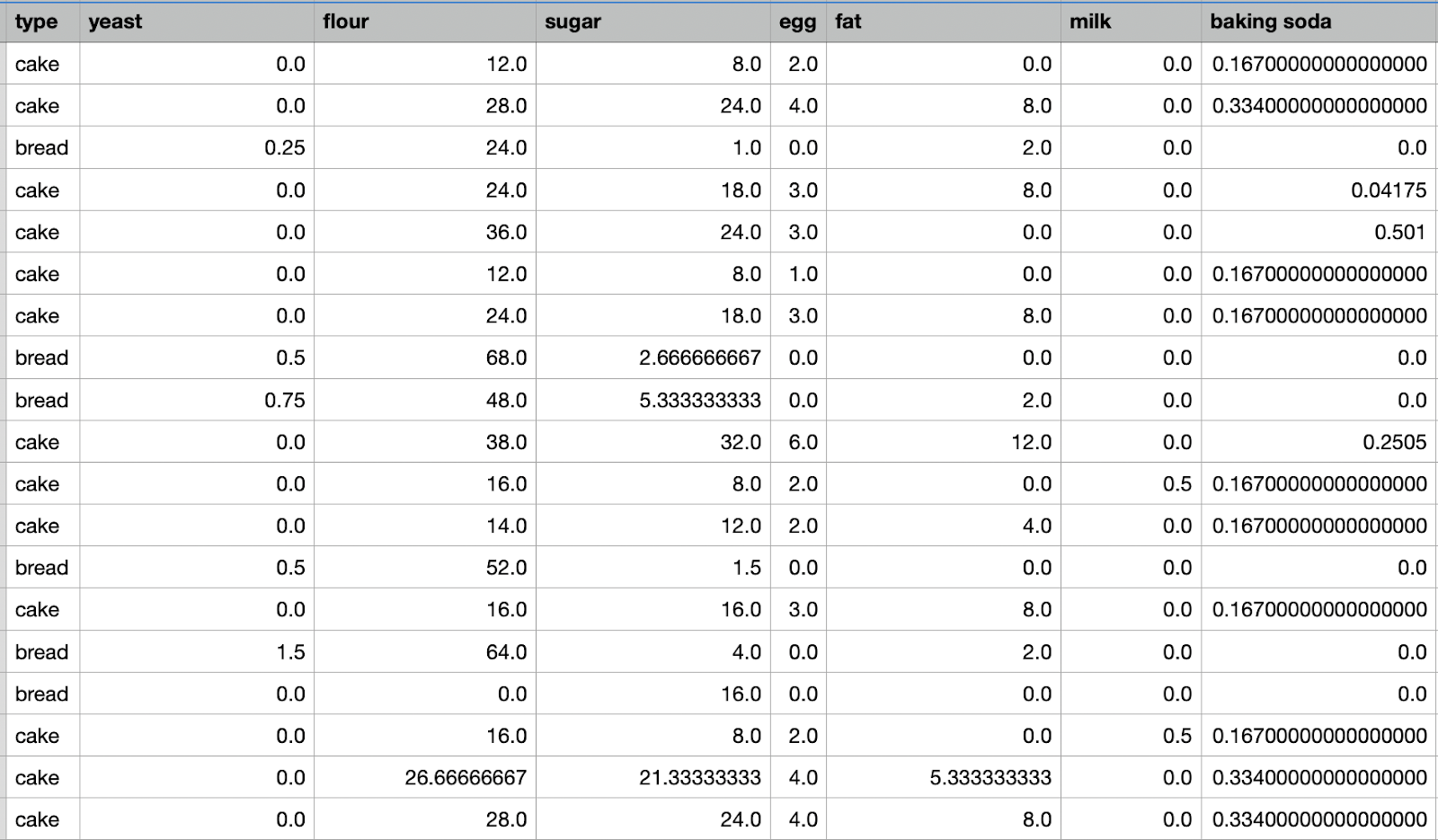
そして、前処理の最後のステップとして、データ拡大の技術を少し使用しました。データ拡大は、既存のデータから新しいトレーニング例(ここでは行)を作成する方法のひとつです。モデルではレシピのできあがりの大きさは考慮されないようにしていたので、材料の分量を無作為に 2 倍や 3 倍にすることにしました。分量を 2 倍や 3 倍にしたレシピのケーキは、元のレシピの場合とほぼ同じになるはずなので、新しいレシピ例を無償で生成できたことになります(やりました!)。
モデルの構築
次に、AutoML Tables を使用して、分類モデルを作成しました。これは、このプロジェクトで最も簡単な部分でした。AutoML Tables は、GCP Console の [人工知能] セクションの [テーブル] から利用できます。
新しい AutoML Tables モデルを作成したら、CSV、Google スプレッドシート、BigQuery データベースからデータを直接インポートできます。
インポートしたデータは、[トレーニング] タブで確認できます。
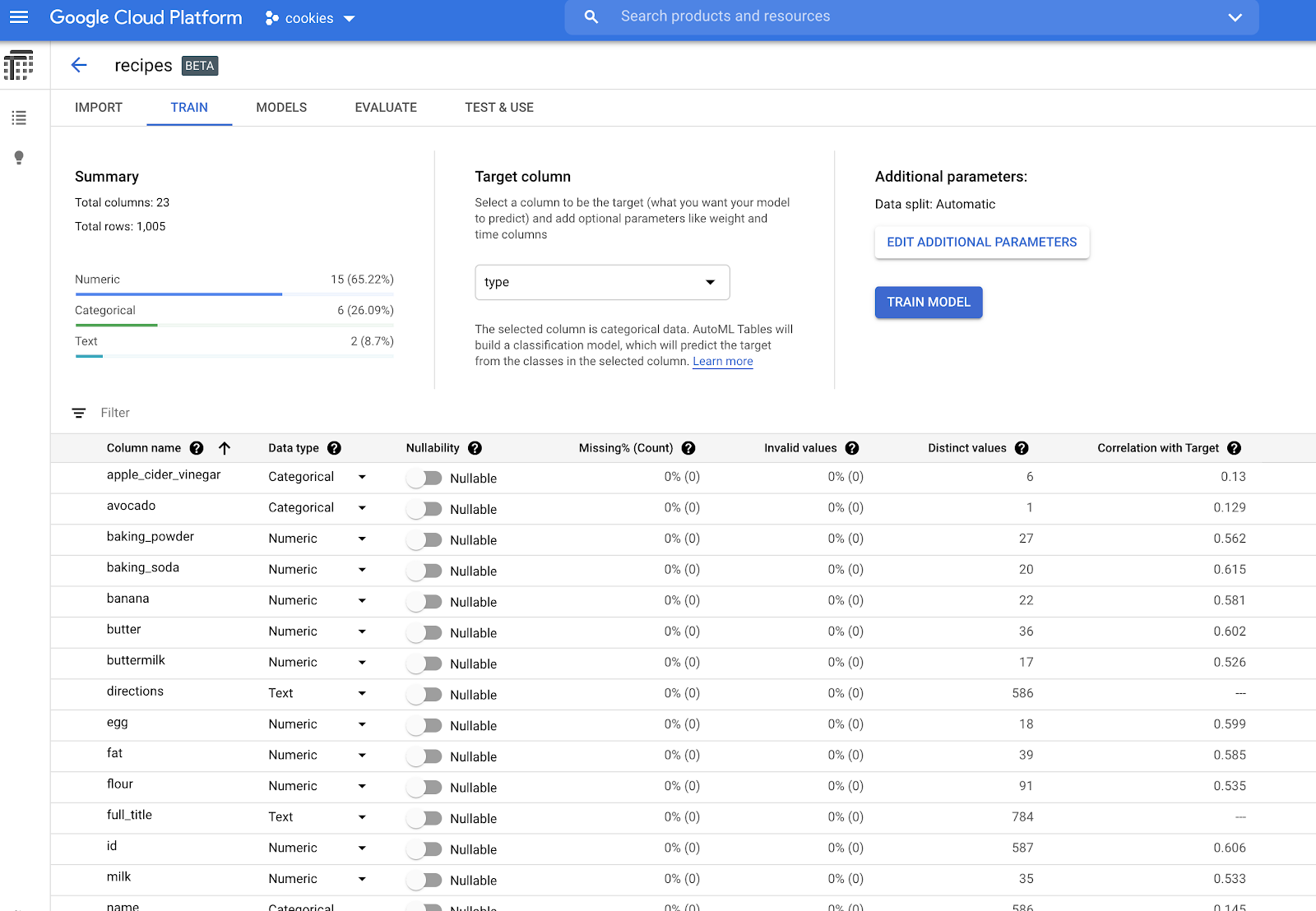
AutoML Tables は、各列の欠損値の割合や各列に含まれる固有の値の数といった、データに関する有用な指標を自動的に計算します。また、便利な [ターゲットとの相関] という指標も計算します。「ターゲット」は予測の対象のことで、このケースではクッキー、ケーキ、パンです。ターゲットは、上部にあるプルダウンで設定できます。このケースでは、「type」という列にしました。
「ターゲット」を設定したら、AutoML が材料ごとに個別にターゲットとの相関を計算します。上述のデータでは、重曹でレシピタイプとの相関が最も高くなっています(0.615)。つまり、判断の基準として材料を 1 つだけ選択しなければならない場合、重曹が適していると言えます。
しかしながら実際は、パンや焼き菓子は材料同士の複雑な相互作用によって特徴が生まれるため、重曹だけに注目することで、十分な精度を得られるとは思えません。そこで、UI の右上部にある [モデル トレーニング] ボタンをクリックして、レシピを予測する機械学習モデルを構築することにしました。このボタンをクリックすると、ダイアログが表示され、モデルの名前付け、モデルのトレーニング期間の指定、トレーニングに使用する列の指定(これは「入力特徴量」と呼ばれます)を行えます。
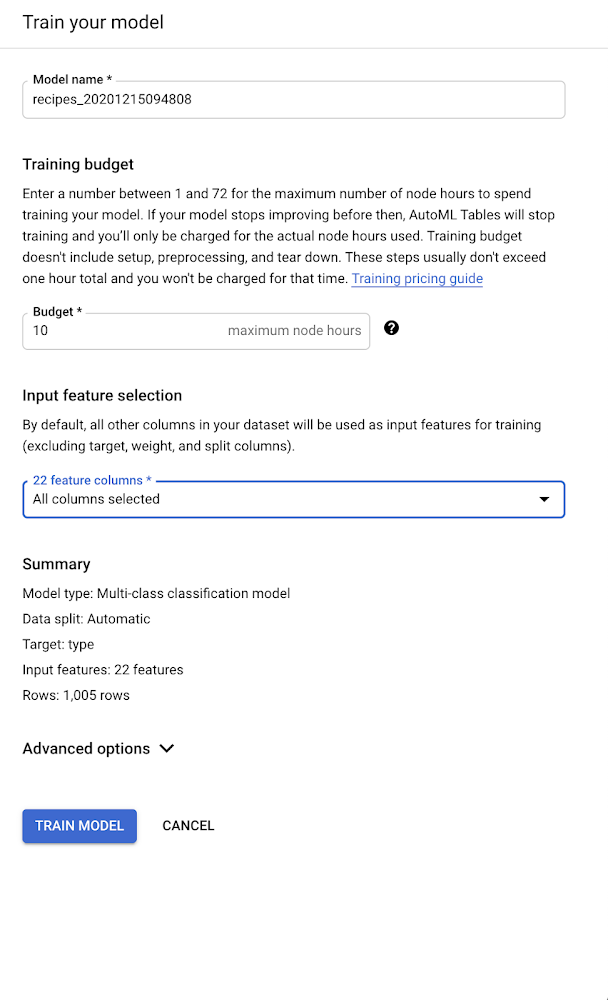
このモデルでは材料のみを考慮に入れるため、[入力特徴量の選択] プルダウンで材料の列のみを選択します。
次に、[モデル トレーニング] をクリックして、待機します。バックグラウンドで、AutoML が大量の機械学習モデルのトレーニングと比較を行い、精度の高いものを見つけ出します。これには数時間かかることがあります。
モデルのトレーニングが完了すると、完了したことが [評価] タブに示されます。このタブでは、モデルの品質に関する有用なさまざまな統計情報を確認できます。このモデルはきわめて精度が高いことがわかります。
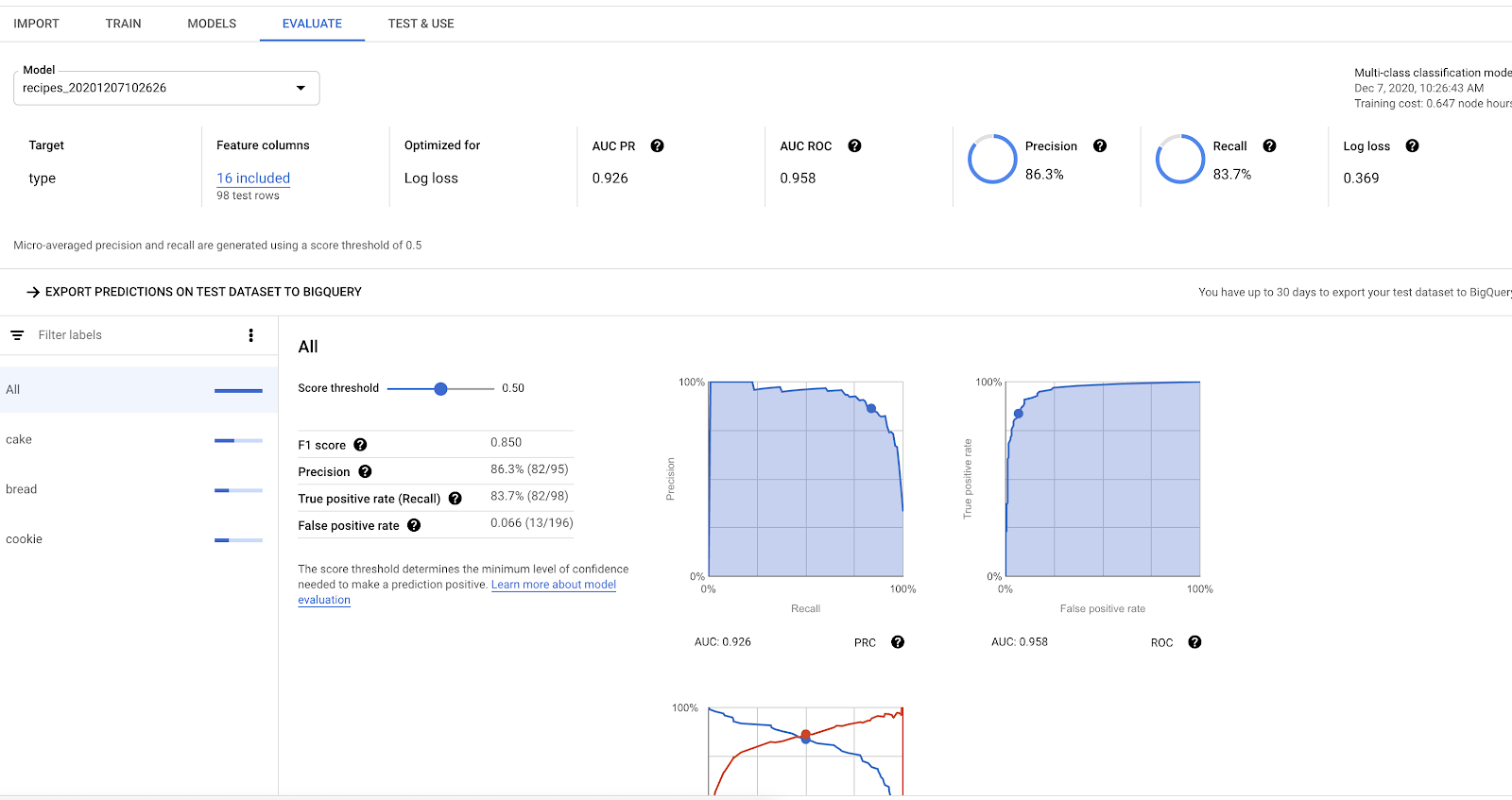
特徴量の重要度によるモデルの説明可能性
[評価] タブで下にスクロールすると、[特徴量の重要度] のスコアから、モデルの詳細な分析情報を得られます。
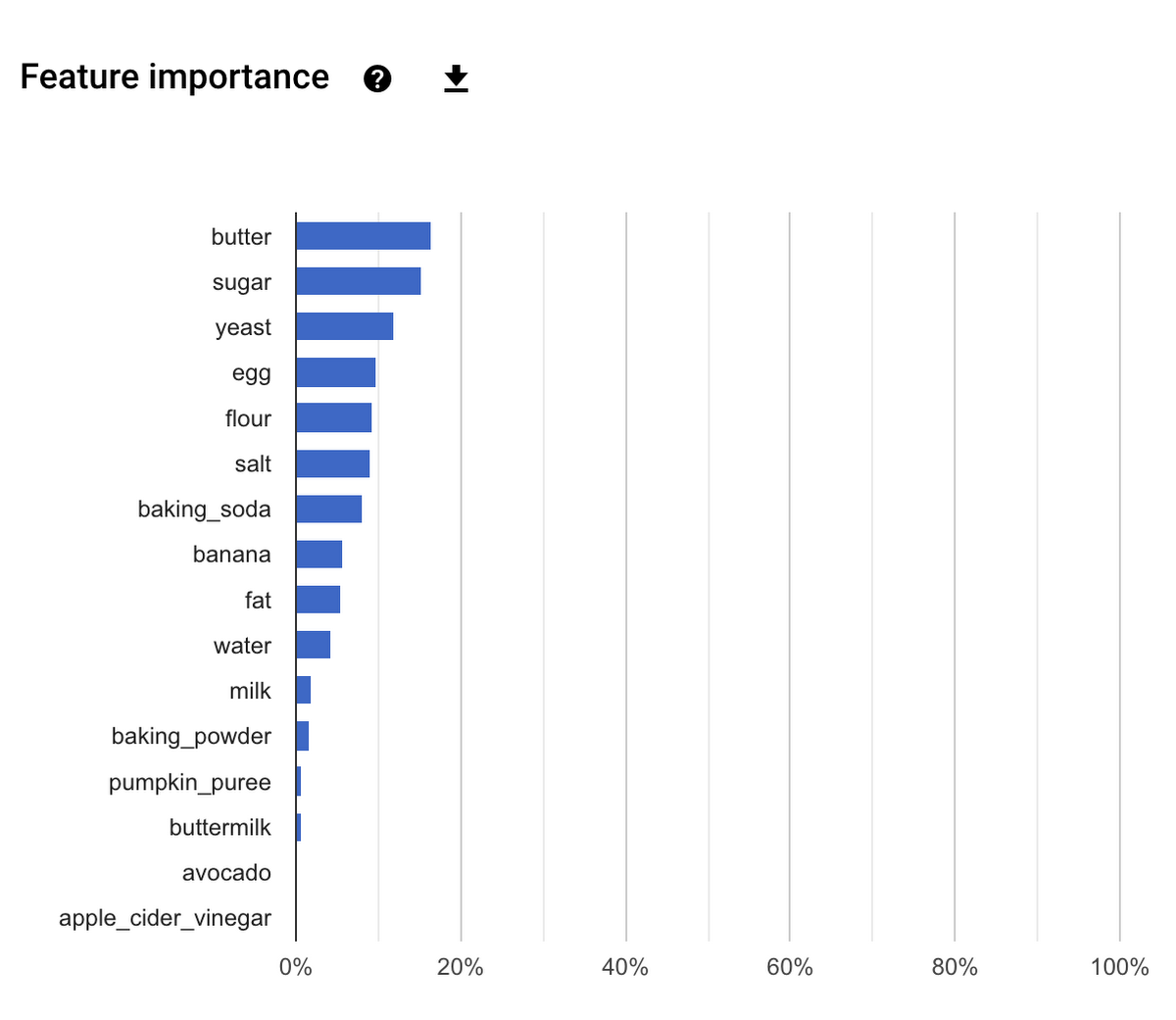
これらのスコアは、モデルによる予測にそれぞれの材料がどれほど関係しているかをまとめたものです。このケースでは、レシピがクッキー、ケーキ、パンのいずれであるかの予測に、バター、砂糖、イースト、卵が重要な要素となっていることがわかります。
上述の特徴量の重要度スコアは、モデルに対する各材料の全体的な重要度を示しています。これは、AutoML がテストセット全体にわたって合計特徴重要度を確認することによって算出した値です。しかしながら、1 つの予測の視点から特徴量の重要度を見ることもでき、その場合は異なる結果となる可能性があります。
たとえば、全体として牛乳は重要なモデル特徴量ではないかもしれませんが、砂糖とバターの値が低い場合、牛乳の重要度は増します。つまり、モデルで 1 つの特定の予測のみを行った場合、その予測に大きく関係した特徴量はどれであったかを知ることが必要になります。
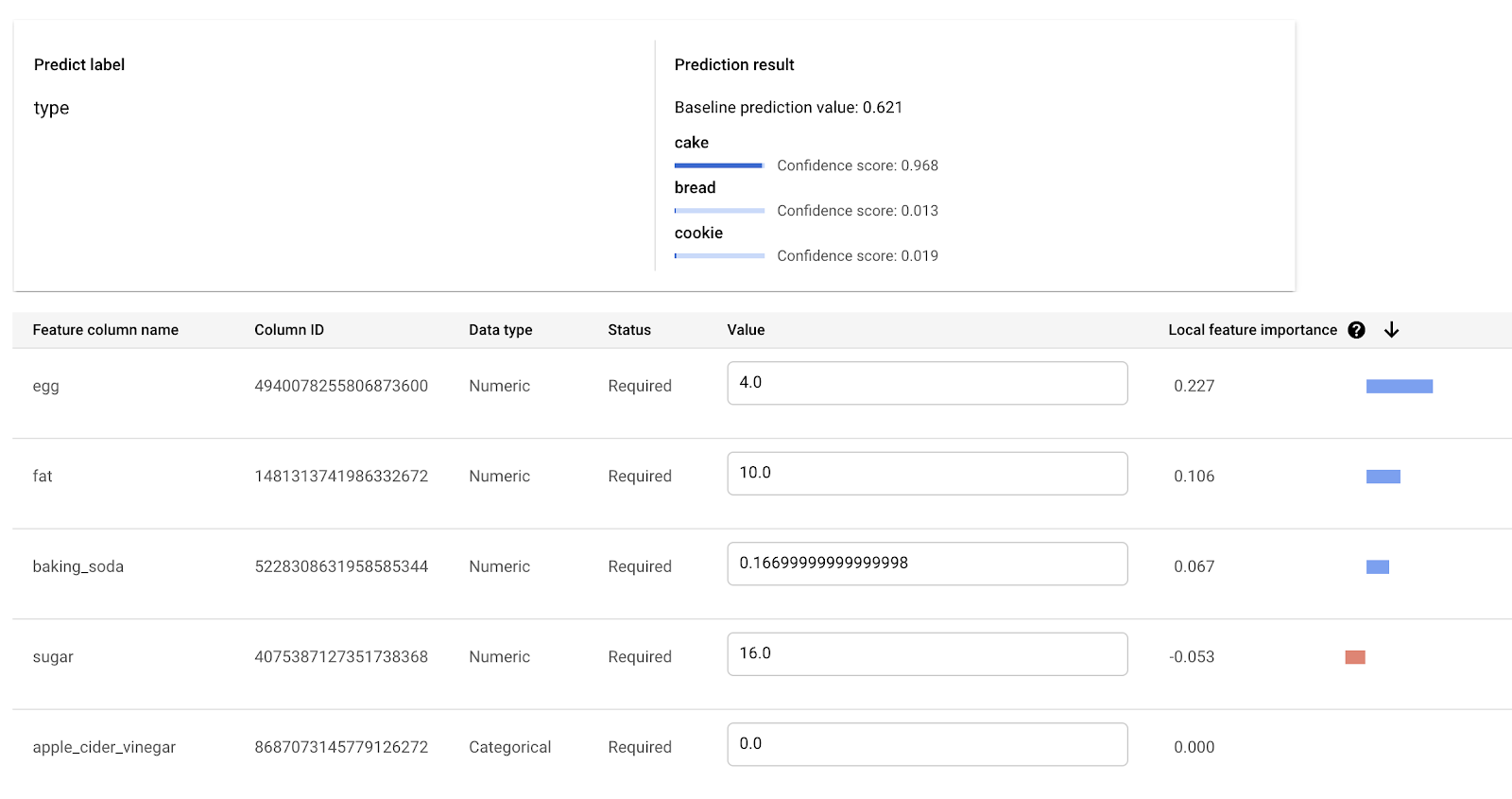
[テストと使用] タブでは、個々のレシピに関して予測を行い、その局部的な特徴量の重要度スコアを確認できます。
たとえば、モデルにケーキのレシピを入力した場合、このカテゴリは「ケーキ」であると正しく予測されます(0.968 の信頼度)。一方、局部的な特徴量の重要度スコアでは、卵、オイル、重曹がこの予測に大きく関係したことが示されます。
ブレッキーのレシピが生まれる
これらの特徴量の重要度スコアから、モデルによってレシピがクッキー、ケーキ、パンであると判断される根拠を見つけ出すことができました。そして、その知識を活用してブレッキーを考案しました。ブレッキーとは、モデルでおおよそ 50% がクッキーで 50% がパンだと判断されたものです。
ブレッキーのレシピを考案したら、すぐにラボで実験して確認したことは、言うまでもありません。

結果は大成功です。クッキーのような味わいですが、パンのようにふわふわした食感のものができあがりました。機械学習がうまくいきました。
モデルは材料を提示しましたが、作り方は教えてくれませんでした。そのため、作り方は自分たちで即興で考えて行う必要がありました。また、おまけとしてチョコレート チップとシナモンも追加しました。
この結果を(科学として)検証したい場合は、ぜひブレッキーを作ってみてください。さらに機械学習への意欲が湧いてきたなら、YouTube で ML を使用した作成シリーズをぜひご覧ください。他にもさまざまなプロジェクトのアイデアをご紹介しています。
ブレッキー
パン風クッキー約 16 個分
材料
ドライイースト(活性)、小さじ 2
温めた牛乳、60 cc
小麦粉、250 g
卵、1 個(軽く溶いておく)
重曹、小さじ 1
塩、小さじ ½
シナモン、小さじ ¼
白砂糖、100 g
ブラウン シュガー、50 g
無塩バター、142 g(常温に戻しておく)
チョコレート チップ、60 g
手順
オーブンを 180 度に温めておきます。天板にクッキング シートを敷き、軽くスプレーオイルをかけておきます。
パンの部分を作ります。電子レンジで牛乳を人肌程度に温めます。熱くしすぎないようにします。温めた牛乳にイーストを溶かし入れておきます。大きめのボウルで、小麦粉、重曹、塩、シナモンを混ぜます。牛乳とイーストを混ぜたものを小麦粉のボウルに入れ、混ぜてまとめます。このボウルに、軽く溶いた卵を加えて混ぜます。この生地は小麦粉が多すぎると思うかもしれませんが、これでかまいません。生地を休ませておきます。
クッキーの部分を作ります。平面型ビーターを取り付けた卓上ミキサーに、室温に戻したバターと 2 種類の砂糖を入れて混ぜ、なめらかになるまで中速で攪拌します。
バターと砂糖を混ぜたところに、小麦粉の生地を一度に 1 カップずつぐらい数回に分けて加えます。チョコレート チップを入れて混ぜます。
生地をボール状に丸めていきます。このレシピのテストでは、1 つを大さじ 2.5 で作りました(キッチン スケールがある場合は 1 つを 50 g にしてください)。用意した天板にボール状の生地を 5~6 cm の間隔を空けて並べます。オーブンに入れ、ブレッキーに焼き色がつき、上部に少し割れ目がつき始めるまで 13~15 分間焼きます。金網台の上で冷まします。
どうぞ召し上がれ。パンとクッキーの比率をどう思うかぜひお知らせください。
-AI 応用エンジニア Dale Markowitz
-デベロッパー アドボケイト Sara Robinson



