ドキュメントに質問する: Document AI と PaLM2 をベースとする質問応答
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
ドキュメントは、従業員が仕事をするうえでそのすべてのデータとコンテンツを実際に活用できると想定した場合、紙かデジタルかを問わず情報の宝庫です。手作業で探さなくてもドキュメント(もっといえば、ドキュメント コーパス)にアクセスできる仕組みをナレッジ ワーカーに用意することは、社内の IT チームやコンテンツ管理チームにとって長らく課題となっていました。
この課題を長年解決できずにいたことには理由があります。PaLM 2 のような生成 AI モデルが登場する前の技術では、さまざまなドキュメント タイプで質問応答を処理するために必要な文脈理解を提供することが困難だったのです。しかし現在、デベロッパーは、Google Cloud Document AI、テキスト エンベディング モデル、PaLM 2 を活用して「ドキュメントに質問する」ツールを構築できるようになりました。この投稿ではその方法をご紹介します。
ドキュメント Q&A アプリケーションを構築するために Document AI と PaLM2 を使用する理由
ドキュメントの質問応答(ドキュメント Q&A)には、特定のドキュメントから情報を抽出し、自然言語で質問に答えることが含まれます。このタイプのワークフローに適用できるユースケースはさまざまな業界や分野に及び、たとえば次のようなものが考えられます。
- 弁護士などの法律専門家が、ドキュメント Q&A を使用して法的文書、法令、判例法を検索し、案件に関連する情報や前例を見つける。
- 生徒と教育者が、研究論文、教科書、教材のコンセプトをより的確に理解するためにドキュメント Q&A を活用する。
- IT サポートチームが、ドキュメント Q&A を介して技術ドキュメントやトラブルシューティング ガイドから情報をすばやく見つけ、技術的な問題の解決に役立てる。
検索拡張生成(RAG)は、Vector Store などのナレッジベースにある関連情報に依拠することで、質問に対してより正確で情報豊かな回答を生成できます。このタスクでは、Document AI OCR(光学式文字認識)と PaLM の優れた機能が活きます。
このブログで提案するソリューションとアーキテクチャでは、RAG ベースのアーキテクチャを大規模に実装するためのスケーラブルなサーバーレス フレームワークを作成します。また、長いドキュメントの Q&A ユースケースに焦点を当てます。
アーキテクチャの概要
この投稿では、エンタープライズ向けの高品質な AI ドキュメント処理モデルを提供する Document AI を使用します。Document AI はスケーラブル、フルマネージド、サーバーレスのソリューションで、インフラストラクチャをスピンアップせずに何百万件ものドキュメントを処理できます。
加えて、ドキュメント ファイルからテキストとレイアウト情報を抽出する事前トレーニング済みモデルである Enterprise Document OCR を使用します。また、生成 AI でテキスト エンベディング(テキストのベクトル表現)を作成するために、Vertex AI の textembedding-gecko モデルも使用します。最後に、PaLM2(具体的には Vertex AI text-bison 基盤モデル)を活用し、エンべディング データストアを基に質問に回答します。下の図は、Document AI と PaLM2 生成 AI 基盤モデルによるドキュメント Q&A のサーバーレス アーキテクチャです。
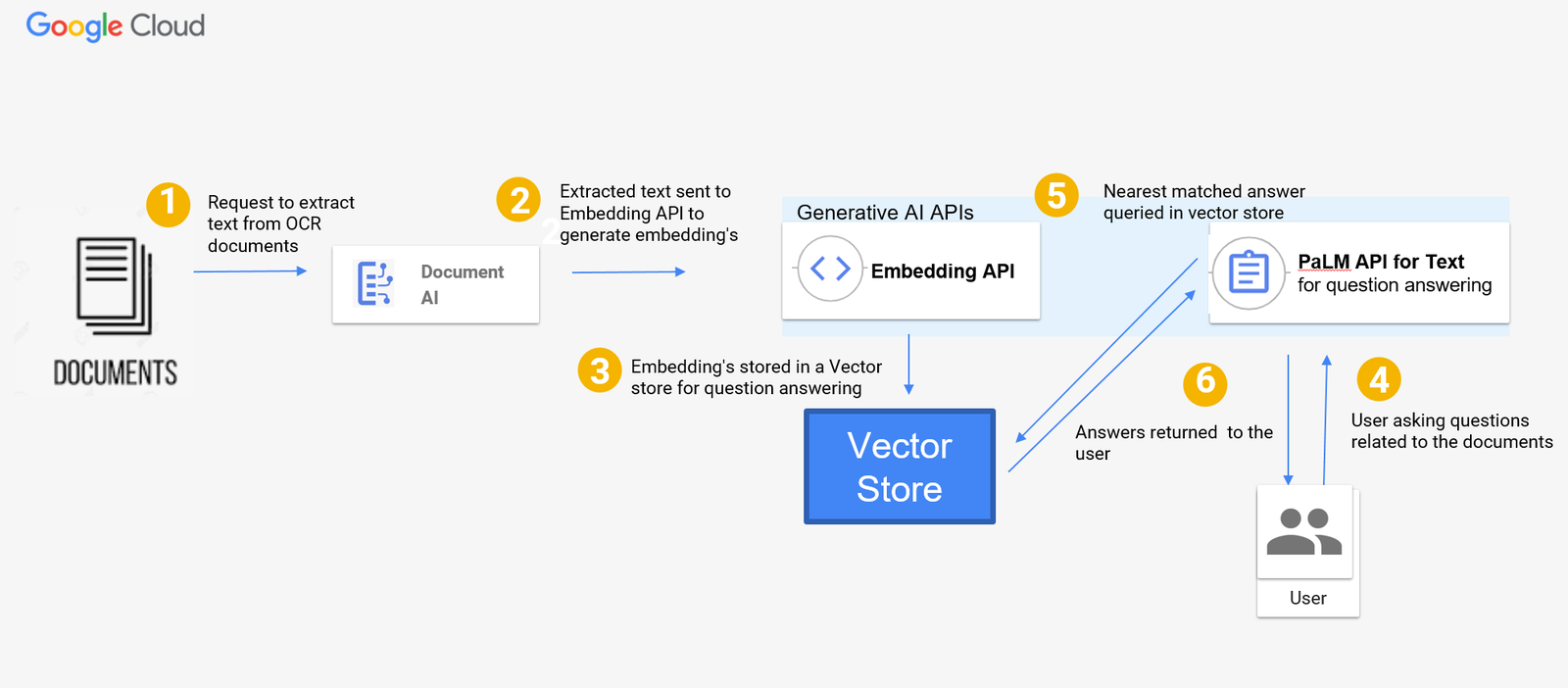
Q&A ツールのアーキテクチャ図のフローは以下のとおりです。
- スキャンした PDF や画像などのドキュメントが OCR 処理とテキスト抽出のために Document AI に送信されます。
- 抽出されたテキストは、エンベディングを生成するために textembedding-gecko モデルに送信されます。
- エンべディングは任意の Vector Store に保存できます。このブログでは Vector Store を使わず、代わりにベクトルをデータ構造に保存し、少量のドキュメントに対する実装がどのようなものかをお見せしますが、ソリューションをスケールするために、エンべディングを保存するペタバイト規模の Vector Store であるベクトル検索を使用することもできます。
- ユーザーがドキュメントに関連する質問をします。
- PaLM text-bison モデルは Vector Store 内を検索し、その中の最も類似したエンべディングを使用して回答を出力します。
- 回答がユーザーに返されます。
実装
ここまでアーキテクチャについて説明してきました。次に、Vertex AI SDK を使用して質問応答アプリケーションを構築できるように、Q&A ツールの構築に必要な大まかな手順を概説します。
実装に関する各ステップの詳細については、こちらのノートブックをご覧ください。
はじめに
以下の例では、Alphabet の収益レポートを使用します。PDF は、この一般公開 Google Cloud Storage バケットでホストされています。
ステップ 1: Document AI OCR プロセッサを作成する
Document AI プロセッサは、ドキュメント ファイルと、ドキュメント処理を行う ML モデルとの間のインターフェースです。プロセッサはドキュメントの分類、分割、解析、分析に使用されます。Google Cloud プロジェクトごとに、独自のプロセッサ インスタンスを作成する必要があります。
Document AI プロセッサは、PDF または画像ファイルを入力として受け取り、そのデータをドキュメント形式で出力します。ここでは、Document AI ライブラリ用の Python クライアントを使用して Enterprise Document OCR プロセッサを作成してから、このプロセッサ メソッドを呼び出してドキュメントを処理します。
ステップ 2: ドキュメントを処理する
作成した Enterprise Document OCR プロセッサを使用してドキュメントの処理を開始できます。ドキュメントを処理するには、プロセッサ名とファイルパスを入力として指定し、以下のドキュメント処理関数を呼び出します。
ステップ 3: データチャンクを作成する
タスクによっては Vertex AI Search のようなソリューションで簡単にドキュメントのコーパスを選択できますが、柔軟性をとりわけ重視するなら、企業に合ったカスタムのアプローチを採用し、費用、複雑さ、精度のバランスを取ることができます。このようなカスタム実装の場合、プロンプトに追加する前にドキュメントのテキストを小さな「チャンク」に分割すると、LLM から最良の結果が得られます。チャンキングは、処理しやすい小さなチャンク(塊)にドキュメントを分割するために使用される手法で、ドキュメントを文、段落、またはセクションに分割します。
現在の PaLM2 text-bison@02 モデルのトークンサイズの上限は 8,196 です。つまり、PaLM API への 1 回のリクエストで処理できるのは、最大 8,196 トークンまでのドキュメントに限られます。ドキュメントがこれより長い場合は、小さなチャンクに分割する必要があります。また、最大 32,000 トークンを入力として処理できる、プレビュー版の PaLM2 32K を使用することもできます。
注: すでに PaLM2 32K text-bison モデルを使用している場合は、次のステップを省略できます。モデル バージョンの完全なリストについては、こちらのリストをご覧ください。
ステップ 4: モデルをインポートする
次に、PaLM2 text-bison と Vertex AI SDK for Python の gecko-embedding モデルを使用して、次のステップのエンベディングを実行します。これはステップ 6 で質問に応答する際にも使用します。
ステップ 5: 各チャンクのエンべディングを取得する
ステップ 3 で行ったチャンキングを使用して、Embeddings API で各チャンクのエンべディングを呼び出すだけで実装を開始できます。ステップ 3 でチャンキングを行わなかった場合は、Embeddings API を使ってエンべディングを生成できます。
以下のコードでは、各チャンクのエンべディング(ベクトル / 数値表現)を別の列として追加しています。
以下の関数は、質問に対して関連性の高いカスタム コンテキストを返します。新しく質問するたびに呼び出せます。このコードは、エンべディングが保存されている Vector Store 内を検索し、最も関連性の高い回答を見つけます。
ステップ 6: PaLM テキスト生成 API を呼び出して質問する
次に、前のステップで作成した get_context_from_question(question, vector_store, sort_index_value) 関数を使用した PaLM text-bison API で、Vector Store から回答を取得する方法を説明します。
以下の関数を使って、ベクトル エンべディング検索から上位 N 個の結果を PaLM2 text-bison モデルにプロンプトとして渡し、質問に対する回答を取得します。上位 N 個のデータは、ユーザーの質問に基づいてモデルによって選択され、生成 AI モデルのプロンプトに渡すコンテキストとして使用されます。
次に、以下のコードを使用して、質問応答用のプロンプトを作成します。このコードでは、カスタムのコンテキスト(Vector Store からのエンべディング)と質問を定義し、PaLM2 text-bison モデルに渡す質問応答用プロンプトを作成しています。
PaLM API から得られる回答に、質問の答えが含まれています。
まとめ
お疲れさまでした。この投稿を通じて、Document AI と PaLM2 を質問応答に使用する方法をご理解いただけたと思います。以下を行う方法を紹介しました。
- Document AI OCR プロセッサを使用して PDF ドキュメントからテキストを抽出する。
- textembedding-gecko モデルを使用して抽出したテキストのエンべディングを生成する。
- PaLM text-bison モデルを使用し、エンべディング データストアを基に質問に回答する。GitHub リポジトリからぜひこのソリューションをお試しください。コーディングに関する投稿も歓迎いたします。
Document AI と大規模言語モデルを使用した RAG ベースのアーキテクチャをサーバーレスで構築することは、決して難しいことではありません。この投稿を通じてそのことをご理解いただけたら幸いです。特定のニーズに適した以下の Google Cloud プロダクトも併せてご確認ください。
- Document AI カスタム エクストラクタ: 契約書、請求書、源泉徴収票、船荷証券のようなドキュメントから特定のフィールドを抽出します。
- Document AI Summarizer: ユーザーが希望する長さと形式で要約をカスタマイズできる、トレーニング不要のツールです。最大 250 ページまでのドキュメントの要約を作成でき、ドキュメントのチャンクやモデルのコンテキスト期間を管理する必要はありません。
- Vertex AI Search and Conversation: エンタープライズ向けのエンドツーエンド RAG ソリューションです。デジタル PDF、HTML、TXT ドキュメントの検索と要約が可能なだけでなく、それらのドキュメント上に chat bot を構築することもできます。
こうしたツールを活用し、皆様が組織のワークフローにどのようなイノベーションをもたらすのか、心より楽しみにしています。
ー AI / ML スペシャリスト、Mona Mona
ー プロダクト マネージャー、Jill Daley



