Vos SLOs sont-ils réalistes ? Ou comment analyser vos risques comme un SRE

Ayelet Sachto
Strategic Cloud Engineer, Infra, AppMod, SRE
Essayer GCP
Les nouveaux clients peuvent explorer et évaluer Google Cloud avec des conditions exceptionnelles.
EssayerDéfinir les SLO (ou objectifs de niveau de service) est l’une des tâches fondamentales des pratiques SRE (Site Reliability Engineering ou « ingénierie de la fiabilité des sites »). Un SLO précise à l’équipe SRE, l’objectif cible à atteindre pour évaluer si un service est suffisamment fiable ou pas. L'inverse du SLO est ce qu’on appelle le « budget d'erreur » (error budget), c'est-à-dire le niveau de manque de fiabilité que vous êtes prêt à tolérer et à assumer financièrement. Une fois ces objectifs identifiés et leur définition apprivoisée, la question suivante consiste à savoir si vos SLO sont réalistes compte tenu de l’architecture de votre application et des pratiques de vos équipes. Êtes-vous sûr de pouvoir les atteindre ? Et qu'est-ce qui est le plus susceptible de dévorer votre budget d'erreur ?
Chez Google, les SRE répondent à ces questions dès la prise en charge d’un nouveau service, dans le cadre d'une revue de préparation à la production (PRR – Production Readiness Review). L'objectif de cette analyse des risques n'est pas de vous inciter à modifier vos SLO, mais plutôt de hiérarchiser (et de communiquer sur) les risques liés à un service donné, afin que vous puissiez évaluer si vous serez en mesure de respecter vos SLO, avec ou sans modification du service. En outre, une telle analyse peut vous aider à identifier les risques les plus importants, avec comme volonté finale de les hiérarchiser et de les atténuer.
« Vous pouvez rendre votre service plus fiable en identifiant et en atténuant les risques. »
Les bases de l'analyse des risques
Avant de pouvoir évaluer et hiérarchiser vos risques, vous devez dresser une liste exhaustive des éléments à surveiller. Cet article a justement pour vocation de fournir quelques lignes directrices aux équipes chargées de réfléchir à tous les risques potentiels liés à une application ou un service. Une fois cette liste établie, nous vous montrerons comment analyser et hiérarchiser les risques que vous avez identifiés.
Quels sont les risques à prendre en compte ?
Lors d’un brainstorming sur les risques potentiels, il est important d’essayer de les cartographier en les regroupant dans différentes catégories : risques liés aux dépendances, à la surveillance, aux ressources, aux opérations, au processus de publication. Pour chacun d’eux, imaginez ce qui se passera si des défaillances spécifiques se produisent, par exemple si un fournisseur tiers est en panne ou si vous introduisez un bug applicatif ou de configuration.
Lorsque vous réfléchissez aux mesures à mettre en place, posez-vous les questions suivantes :
Y a-t-il des lacunes dans vos capacités d’observabilité ?
Avez-vous des alertes pour ce SLI spécifique ?
Collectez-vous déjà les mesures utiles ?
Veillez également à cartographier toutes les dépendances de surveillance et d'alerte. Typiquement, que se passe-t-il si un système managé que vous utilisez tombe en panne ?
Idéalement, il vous faudra identifier les risques associés à chaque point de défaillance pour chaque composant critique dans un parcours utilisateur critique, ou CUJ. Et après avoir identifié ces risques, il vous faudra les quantifier :
Quel pourcentage d'utilisateurs sera affecté par la défaillance ?
À quelle fréquence estimez-vous que cette défaillance se produira ?
Combien de temps faudra-t-il pour détecter la défaillance ?
Il est également très utile de recueillir des informations sur tout incident survenu au cours de l'année écoulée et ayant impacté les CUJ. Un brainstorming repose essentiellement sur votre intuition. Mais s'appuyer sur des données historiques fournit des estimations plus précises et un bon point de départ pour cerner les incidents réels. Typiquement, vous pouvez envisager des incidents tels que :
Un incident de configuration qui réduit la capacité, provoquant une surcharge et des requêtes abandonnées.
Une nouvelle version qui casse un petit ensemble de requêtes. La panne n'est pas détectée pendant une journée. Un retour en arrière rapide lorsqu'elle est détectée.
Une panne de réseau ou de machine virtuelle dans une seule zone chez un fournisseur de services cloud.
Une panne régionale des VM ou du réseau d'un fournisseur Cloud.
Un opérateur qui supprime accidentellement une base de données, ce qui nécessite une restauration à partir d'une sauvegarde.
Autre aspect à ne pas négliger, les facteurs de risque ! Il s'agit de facteurs globaux qui affectent le temps global de détection (TTD) et le temps de réparation (TTR). Il s'agit généralement de facteurs opérationnels qui peuvent augmenter le temps nécessaire à la détection des pannes (par exemple lors de l'utilisation de mesures en appui sur les logs) ou nécessiter l'alerte des ingénieurs d'astreinte. Un autre exemple pourrait être le manque de documentations ou le manque de procédures automatiques. Par exemple, vous constatez :
Un temps estimé de détection (ETTD) de +30 minutes en raison d'une surcharge opérationnelle notamment liée à des alertes bruyantes.
Une fréquence accrue de 10 % d'une éventuelle défaillance, en raison du manque de « post-mortems » (analyses post-incident) ou de suivi des actions.
Bonnes pratiques de Brainstorming…
Au-delà des aspects techniques d’un risque potentiel pour un service donné et des questions vues ci-dessus et qu’il est essentiel de se poser, il existe aussi quelques bonnes pratiques à prendre en compte lors de la tenue d'une session de brainstorming avec votre équipe.
Commencez la discussion par un schéma fonctionnel de haut niveau de votre service, de ses utilisateurs et de ses dépendances.
Collectez un ensemble d'opinions diverses dans la salle en interrogeant différents rôles dont le rapport avec le produit au cœur des discussions diffère du vôtre. Évitez de donner la parole à une seule partie. Demandez aux participants comment chaque élément du diagramme pourrait provoquer une erreur perceptible par l'utilisateur. Regroupez les causes similaires dans une seule catégorie de risque, telle que "panne de la base de données" par exemple.
Essayez d'éviter de passer trop de temps à discuter de choses pour lesquelles le temps estimé entre deux défaillances est supérieur à quelques années, ou pour lesquelles l'impact est limité à un très petit sous-ensemble d'utilisateurs.
Création du catalogue de risques
Soyons clairs. Il ne sert à rien d’élaborer une liste interminable de risques. En pratique, sept à douze risques par indicateur de niveau de service (SLI) sont suffisants. L'essentiel, c’est que les données collectées capturent les risques critiques et à forte probabilité.
Il est préférable de commencer par des pannes réelles, déjà rencontrées sur ce service ou un service similaire. Des pannes qui peuvent être aussi banales que l’indisponibilité d’un service appelé ou du réseau.
Intéressez-vous à la fois aux problèmes liés à l'infrastructure et à ceux liés aux logiciels.
Pensez aux risques qui peuvent affecter le SLI, le temps de détection et le temps de résolution, ainsi que la fréquence - plus de détails sur ces mesures ci-dessous.
Collectez à la fois les risques issus du catalogue de risques et les facteurs de risques (facteurs globaux). Typiquement, le risque de ne pas disposer d'un playbook augmente le délai de réparation ; le risque de ne pas disposer d'alertes pour les CUJ augmente le délai de détection ; le risque d'un retard de synchronisation des journaux de x minutes augmente d'autant le délai de détection. Ensuite, cataloguez tous ces risques et leurs impacts associés dans un onglet d'impacts globaux.
Voici quelques exemples de risques :
Une nouvelle version interrompt un petit nombre de requêtes ; l’anomalie reste non détectée pendant une journée ; retour en arrière rapide une fois détectée.
Une nouvelle version brise un sous-ensemble important de requêtes ; et pas de retour en arrière automatique.
Un incident de configuration réduit la capacité ; il engendre un pic d'utilisation non immédiatement repéré.
Recommandation : L'examen des données ou des résultats de la mise en œuvre du SLI vous donnera une bonne indication de votre situation par rapport à la réalisation de vos objectifs. Je recommande de commencer par créer un tableau de bord pour chaque CUJ - idéalement un tableau de bord comprenant des mesures qui vous permettront également de dépanner et de déboguer les problèmes de réalisation des SLO.
Analyse des risques
Maintenant que vous avez dressé une liste des risques potentiels, il est temps de les analyser, afin de hiérarchiser leur probabilité et de trouver les éventuels moyens de les atténuer. En d'autres termes, il est temps de procéder à une analyse des risques.
L’analyse de risques doit s’appuyer sur une approche basée sur les données afin d’adresser et prioriser les risques en les évaluant selon 4 dimensions clés : les TTD et TTR déjà susmentionnés, le délai entre les défaillances (TBF), et leur impact sur les utilisateurs.
Dans le guide « Shrinking the impact of production incidents using SRE principles » (réduire l’impact des incidents en production à l’aide des principes SRE), nous proposons un diagramme du cycle des incidents de production. Dans ce dernier, reproduit ci-dessous, la zone bleue représente les moments où les utilisateurs sont satisfaits, et celle en rouge ceux où ils sont mécontents.
Le temps pendant lequel vos services ne sont pas fiables et vos utilisateurs sont mécontents dépend directement du temps de détection et du temps de réparation. Il est aussi affecté par la fréquence des incidents (qui peut être traduit en temps entre les défaillances).
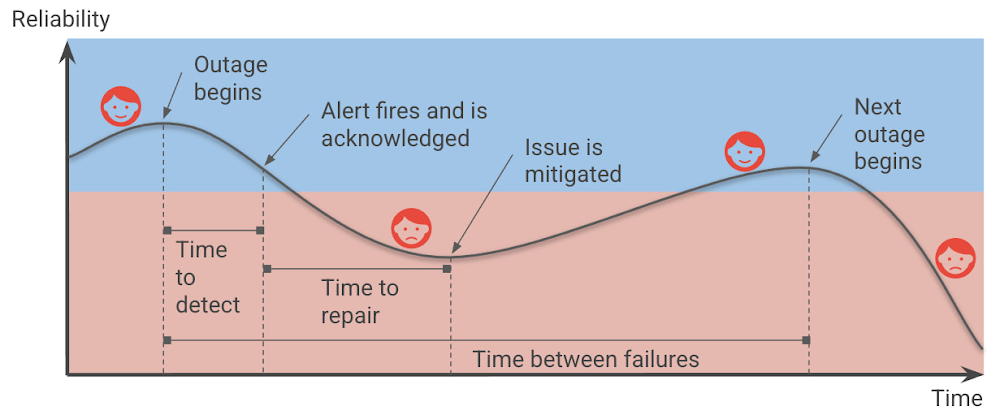
Il en résulte que l’on peut améliorer « la fiabilité » en augmentant le temps entre les pannes, en diminuant le temps de détection ou le délai de réparation et, bien sûr, en réduisant l'impact des pannes en premier lieu.
Concevoir votre service pour qu’il soit résilient contribue à réduire la fréquence des pannes générales. Il faut éviter les points de défaillance uniques (single points of failure) au sein de votre architecture, qu'il s'agisse d'une instance individuelle, d'une zone de disponibilité ou même d'une région entière. Objectif : empêcher qu'une petite panne localisée ne fasse boule de neige et n'entraîne un temps d'arrêt mondial...
Pour réduire l’impact d’un incident sur vos utilisateurs, il faut chercher soit à réduire le pourcentage d’infrastructure affectée ou le pourcentage d’utilisateurs touchés, soit à diminuer les requêtes (par exemple en limitant une partie des demandes plutôt que de toutes les traiter). Afin de réduire le rayon d’action des pannes, cherchez à éviter les changements globaux et optez pour des stratégies de déploiement avancées qui permettent un déploiement progressif des changements sur plusieurs heures, jours voire semaines. Ceci permet de réduire le risque de panne majeure et l’identification des problèmes avant que tous les utilisateurs n’en soient affectés.
Au-delà de ces mesures de bon sens, disposer de pipelines robustes d'intégration continue et de livraison continue (CI/CD) vous permet de déployer et de revenir en arrière en toute confiance et de réduire l'impact sur les clients (voir : SRE Book : Chapitre 8 - Release Engineering). La création d'un processus intégré de révision et de test du code vous aidera à trouver les problèmes à un stade précoce, avant que les utilisateurs ne soient affectés.
Améliorer le temps de détection (TTD) permet de s’assurer de corriger les pannes au plus vite. Le TTD estimé (ETTD) exprime le temps nécessaire pour qu’un être humain soit informé du problème. Il doit inclure tous les délais qui retardent l’assimilation de l’information. Par exemple, si l’entreprise utilise une alerte basée sur les logs et que le système de log affiche un temps d’ingestion des données de 5 minutes, cela accroit d’autant le TTD pour chaque alerte.
L'ETTR (estimated time-to-repair) est le délai entre le moment où un humain découvre l'alerte et le moment où vos utilisateurs voient un retour à la normale. L’amélioration du TTR (time-to-repair) signifie en principe que les pannes sont plus rapidement réparées. Cela dit, nous devons toujours nous demander si l’incident affecte toujours nos utilisateurs. Dans la plupart des cas, des mesures d'atténuation comme le roll-back des nouvelles versions ou le détournement du trafic vers des régions non affectées peuvent réduire ou éliminer l'impact d'une panne en cours sur les utilisateurs beaucoup plus rapidement que d'essayer de passer à une nouvelle version corrigée du service. La cause profonde n'est pas encore résolue, mais les utilisateurs ne le savent pas ou ne s'en soucient pas - tout ce qu'ils voient, c'est que le service fonctionne à nouveau.
Si l’automatisation tend à mettre hors du jeu l’être humain, elle permet de réduire le TTR et peut s’avérer cruciale pour atteindre des objectifs de fiabilité toujours plus élevés. Cependant, elle n’élimine jamais totalement le TTR. Si une mesure d'atténuation telle que le basculement vers une autre région est automatisée, il lui faut du temps pour se mettre en place et avoir un impact.
Une remarque sur les valeurs "estimées" : Au début d'une analyse de risques, vous pouvez commencer par des estimations approximatives de ces paramètres. Mais au fur et à mesure que vous collectez davantage de données sur les incidents, vous devez mettre à jour ces estimations en vous basant sur les données des pannes précédentes afin de refléter l’expérience utilisateur.
Un processus d'analyse des risques à haut niveau
Comme déjà évoqué, tout processus d'analyse de risques débute par un brainstorming sur les risques pour chacun de vos SLO, et plus précisément pour chacun de vos SLI, car différents SLI seront exposés à différents risques.
Dans la phase suivante, construisez un catalogue de risques et itérez pour l’enrichir et le mettre à jour.
Créez une fiche d'analyse de risques pour deux ou trois SLI, en utilisant ce modèle. Pour en savoir plus, consultez la page « Comment hiérarchiser (et communiquer sur) les risques ».
Faites un brainstorming interne sur les risques, en considérant les éléments qui peuvent affecter vos SLO et en rassemblant quelques données initiales. Faites-le d'abord avec l'équipe d'ingénierie, puis avec l'équipe produit.
Les fiches d'analyse de risques pour chacun de vos SLI doivent inclure l'ETTD, l'ETTR, l'impact et la fréquence. Incluez les facteurs globaux et les risques suggérés et indiquez si ces risques sont acceptables ou non.
Recueillez des données historiques et consultez l'équipe produit concernant les besoins des métiers en termes de SLO.
Itérez et mettez à jour les données en fonction des incidents en production.
Acceptation des risques
Après avoir établi le catalogue des risques et déduit les facteurs de risques, finalisez les SLOs en fonction des besoins de l'entreprise et de l'analyse des risques.
Lors de cette étape, vous devez évaluer si votre SLO est réalisable compte tenu des risques encourus. Et, si ce n'est pas le cas, vous devez vous demander quoi faire pour atteindre vos objectifs.
Il est essentiel que les Product Managers participent à ce processus de révision, notamment parce qu'ils peuvent être amenés à donner la priorité aux travaux d'ingénierie qui atténuent ou éliminent tout risque inacceptable.
Dans l’article « how to prioritize and communicate risks », nous expliquons comment utiliser la fiche « Risk Stack Rank » pour évaluer combien un risque donné peut vous "coûter", et quels risques vous pouvez accepter (ou non) pour un SLO donné.
Typiquement, dans cette fiche modèle, vous pourriez accepter tous les risques et atteindre une fiabilité de 99,5 %, certains des risques pour atteindre 99,9 % et aucun d'entre eux pour atteindre 99,99 %. Si vous ne pouvez pas accepter un risque parce que vous estimez qu'il consommera plus de budgets d'erreur que ce que votre SLO vous permet, il vous faudra consacrer du temps d'ingénierie à la résolution de sa cause première ou à la mise en place d'une mesure d’atténuation.
Une dernière remarque : comme pour les SLO, vous voudrez itérer sur votre risque en affinant votre ETTD sur la base du TTD réel observé pendant les pannes. Idem pour votre ETTR. C’est pourquoi, après chaque incident, vous devez mettre à jour les données et voir où vous en êtes par rapport à ces estimations. En outre, réexaminez périodiquement ces estimations pour évaluer si vos risques sont toujours pertinents, si vos estimations sont correctes ou s'il existe des risques supplémentaires que vous devez prendre en compte. À l’instar du principe SRE d'amélioration continue, c'est un travail qui n'est jamais vraiment terminé, mais qui en vaut la peine !