Le machine learning : guide du débutant

Dale Markowitz
Applied AI Engineer
Essayer GCP
Les nouveaux clients peuvent explorer et évaluer Google Cloud avec des conditions exceptionnelles.
EssayerCréer des applications basées sur l'IA n'est pas chose aisée. J'en sais quelque chose. Mais je me suis donné beaucoup de mal, car les retombées sont à la hauteur des efforts. Le jeu en vaut la chandelle, comme on dit.
Heureusement, ces cinq dernières années, des outils faciles à utiliser ont rendu le développement d'applications à l'aide du machine learning bien plus simple. Aujourd'hui, je passe très peu de temps à créer et régler des modèles de machine learning,
et j'en consacre beaucoup plus au développement d'applications traditionnelles.
Dans cet article, je vais vous présenter certains des outils d'IA de Google Cloud que je préfère en raison de leur facilité d'utilisation. Je vous livre aussi mes conseils pour créer rapidement des applications basées sur l'IA.
Utiliser des modèles pré-entraînés
L'une des étapes les plus fastidieuses des projets de machine learning est la collecte de données d'entraînement étiquetées, c'est-à-dire d'exemples étiquetés à partir desquels l'algorithme de machine learning va "apprendre".
Cela dit, dans de nombreux cas d'utilisation courants, il n'est pas nécessaire d'en passer par là. Au lieu de créer entièrement son propre modèle, on peut exploiter des modèles pré-entraînés créés, réglés et tenus à jour par quelqu'un d'autre. Les API basées sur l'IA de Google Cloud en sont un exemple.
Elles vous permettent d'utiliser le machine learning pour, par exemple :
lire le texte de documents ;
analyser des documents structurés tels que des formulaires ou des factures ;
détecter des visages, des émotions et des objets dans des images ;
et faire bien d'autres choses encore.
Les modèles de machine learning sur lesquels reposent ces API sont semblables à ceux utilisés par de nombreuses applications Google (comme Photos). Ils sont entraînés avec des ensembles de données colossaux et sont souvent d'une précision impressionnante. Par exemple, quand j'ai employé l'API Video Intelligence pour analyser mes vidéos familiales, elle a été capable de détecter des étiquettes bien précises, comme "enterrement de vie de jeune fille", "mariage", "jeux avec balle et batte" et même "bébé souriant".
Les API basées sur l'IA Cloud s'exécutent, comme leur nom l'indique, dans le cloud. Mais si vous recherchez une solution gratuite et hors connexion, TensorFlow.js et ML Kit proposent un grand nombre de modèles pré-entraînés que vous pouvez exécuter directement dans un navigateur ou sur un appareil mobile. Vous trouverez encore davantage de modèles TensorFlow pré-entraînés sur TensorFlow Hub.
Modèles personnalisés faciles à utiliser avec AutoML
Même s'il existe des modèles pré-entraînés pour de nombreux cas d'utilisation, on a parfois besoin d'en créer un vraiment personnalisé. Vous pouvez par exemple avoir besoin d'un modèle qui analyse des images médicales comme des radios pour détecter une maladie. Ou alors vous devez trier des trucs et des bidules sur une chaîne de montage. Ou encore, vous souhaitez déterminer lesquels de vos clients sont les plus susceptibles d'effectuer un achat quand vous leur envoyez un catalogue.
Pour cela, vous devez créer un modèle personnalisé. AutoML est un outil d'IA Google Cloud qui facilite autant que possible ce processus. Il vous permet d'entraîner un modèle personnalisé avec vos propres données, sans que vous ayez pour autant à écrire du code (sauf si vous y tenez vraiment).
Le GIF ci-dessous montre bien comment j'ai entraîné un modèle à détecter les composants cassés sur un circuit imprimé à l'aided'AutoML Vision. Pour étiqueter les données dans l'interface, il suffit de faire un cliquer-glisser. Et pour entraîner un modèle, rien de plus simple : on clique sur le bouton "Train New Model" (Entraîner le nouveau modèle). Lorsque l'entraînement du modèle est terminé, on peut en évaluer la qualité et voir les erreurs qu'il a commises dans l'onglet "Evaluate" (Évaluation).
Cet outil fonctionne avec les images (AutoML Vision), les vidéos (AutoML Video), les langues (AutoML Natural Language et AutoML Translation), les documents, et les données tabulaires (AutoML Tables) comme celles d'une base de données ou d'une feuille de calcul.
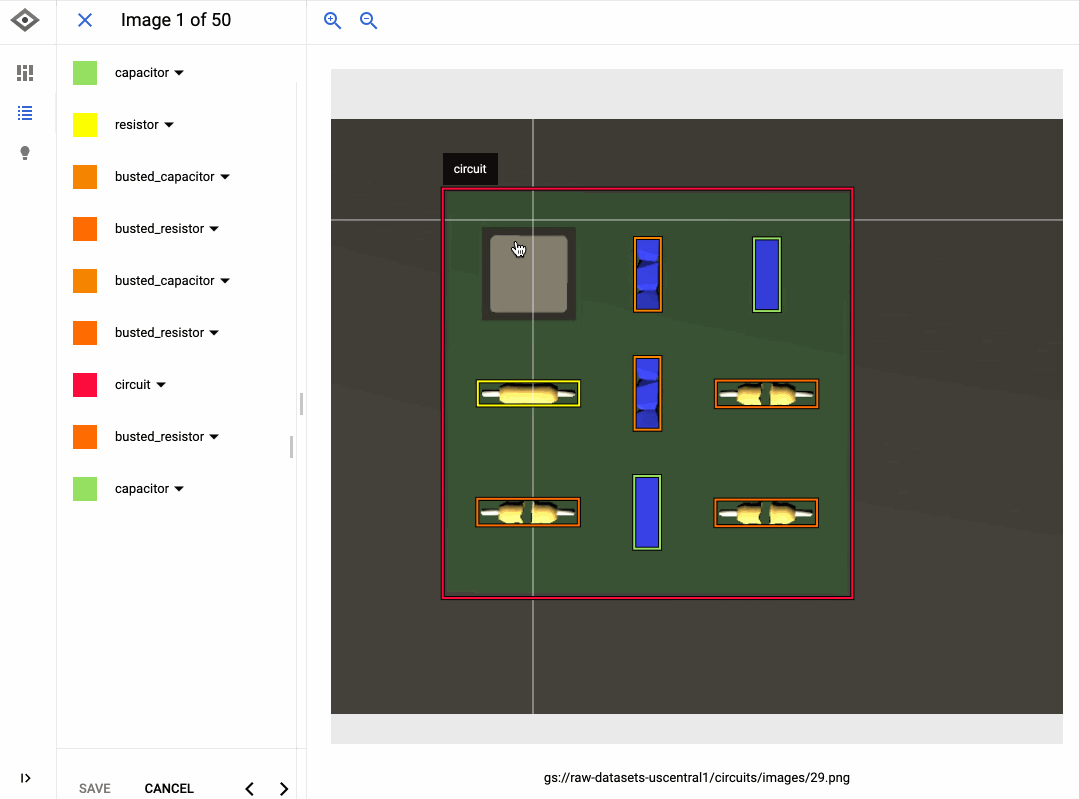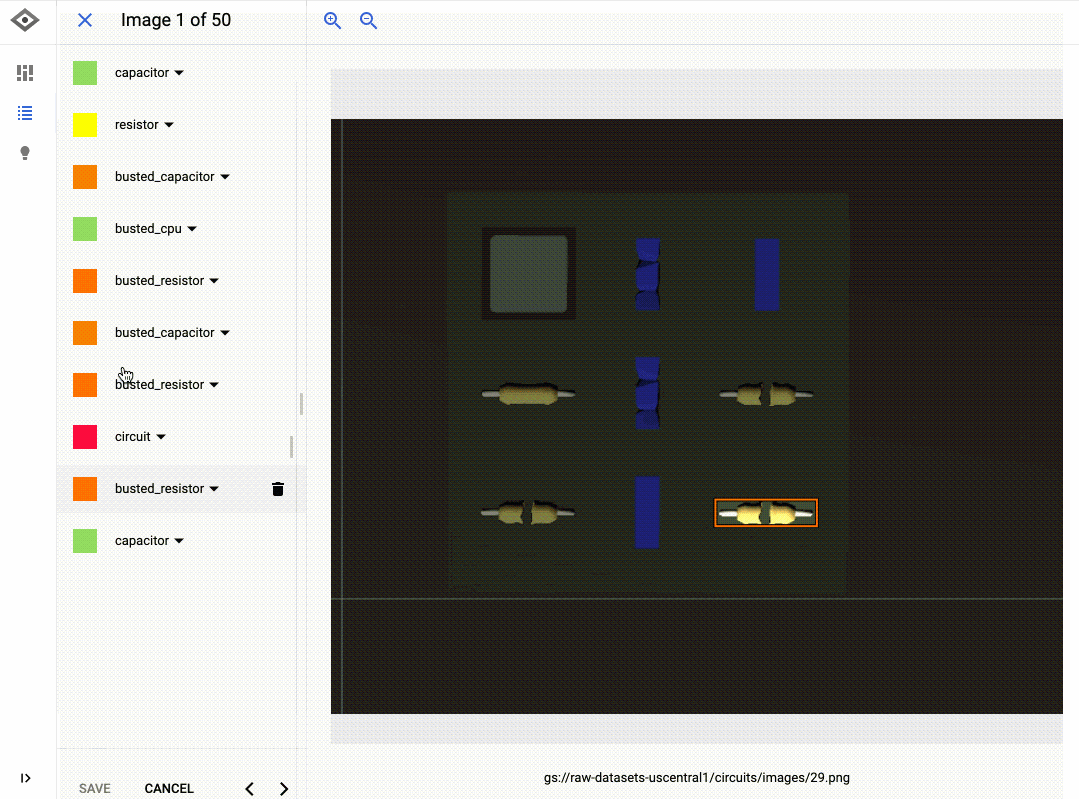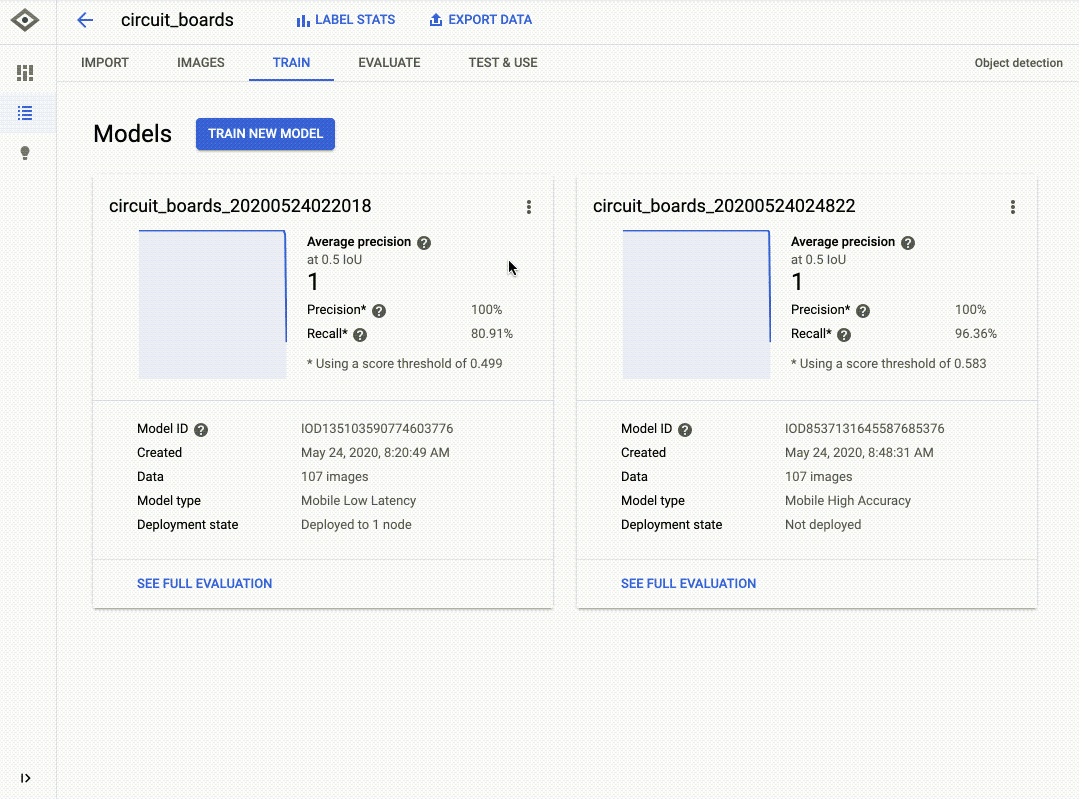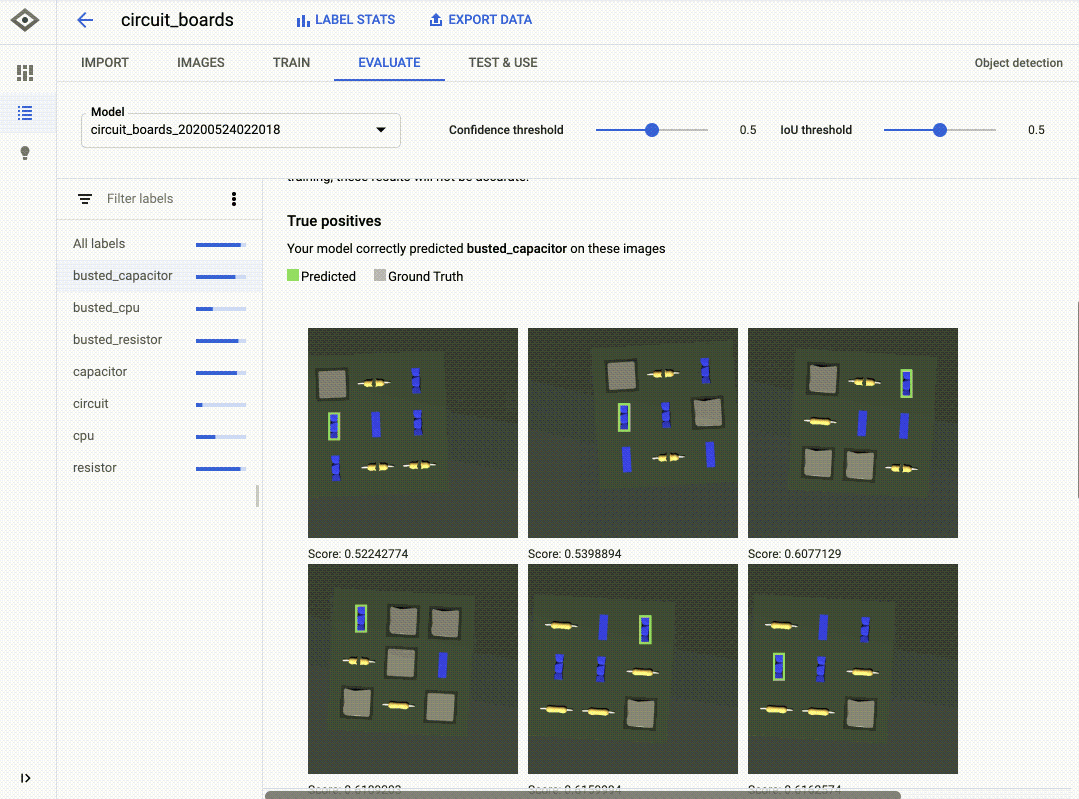
Bien que son interface soit très simple, AutoML produit souvent des modèles d'une qualité impressionnante. L'outil entraîne différents modèles en arrière-plan (comme des réseaux de neurones), et compare des architectures et paramètres variés afin de choisir les combinaisons les plus justes.
Il n'est pas compliqué d'utiliser des modèles AutoML dans votre application. Soit vous autorisez Google à héberger le modèle dans le Cloud et vous y accédez via une API REST standard ou une bibliothèque cliente (Go, Java, Node, Python, etc.), soit vous exportez le modèle vers TensorFlow afin de pouvoir l'utiliser hors connexion.
Entraîner un modèle est donc globalement simple. Mais où trouver un grand ensemble de données d'entraînement ?
N'étiquetez jamais vos propres données
Je suis sérieuse.
Quand je lance un projet de ML, je vérifie d'abord s'il n'existe pas déjà un modèle pré-entraîné qui fait ce dont j'ai besoin.
Si ce n'est pas le cas, je me pose la même question pour les ensembles de données. Sur Kaggle, un site d'hébergement d'ensembles de données et de compétitions, on trouve presque tous les ensembles de données imaginables. Tweets sur le COVID-19, liste de restaurants de fast-food tex-mex, articles de fausses nouvelles ("fake news")… Sur Kaggle, vous trouverez bien un ensemble de données quelconque pour entraîner le modèle de démonstration de faisabilité dont vous avez besoin. Google Recherche d'ensembles de données est un outil tout aussi utile qui envoie des requêtes à Kaggle et à d'autres sources pour trouver des ensembles de données.
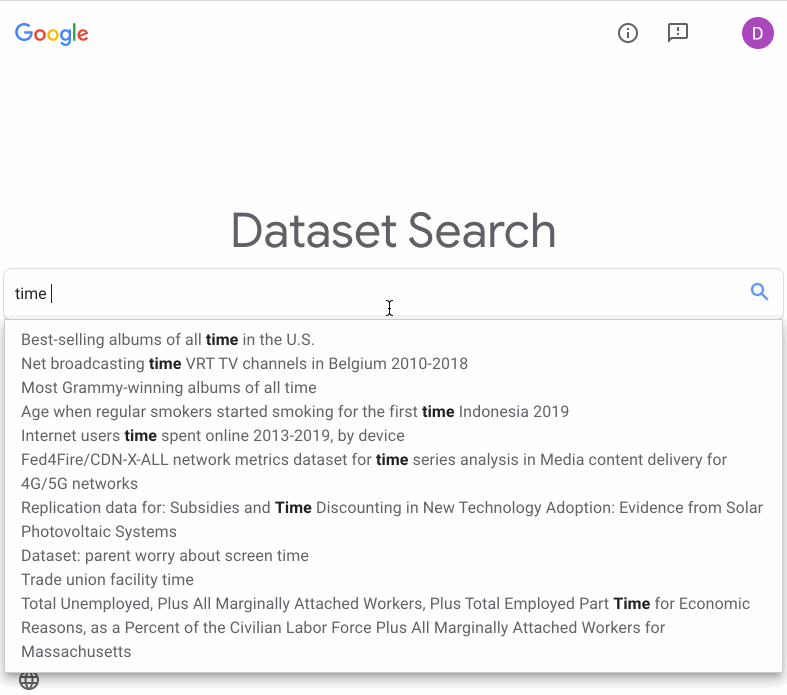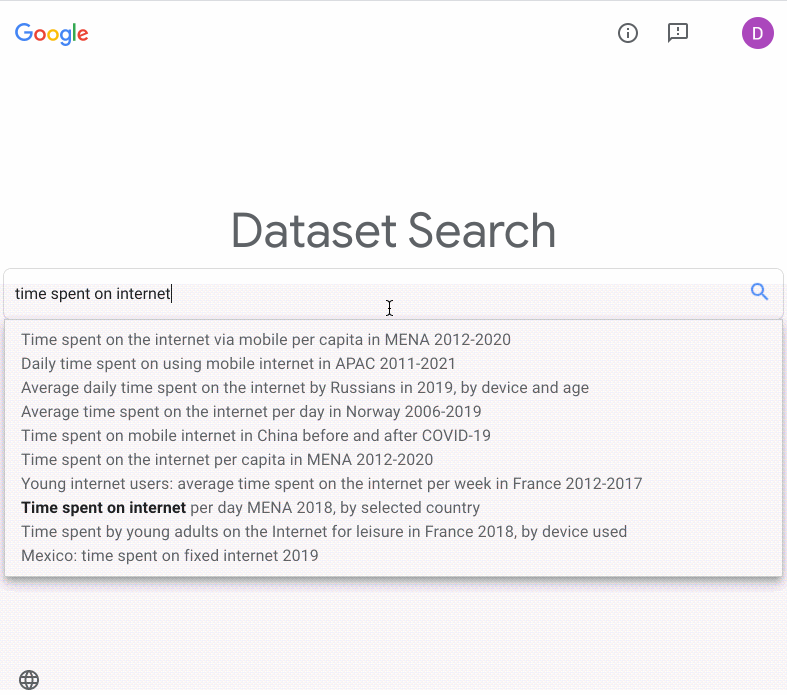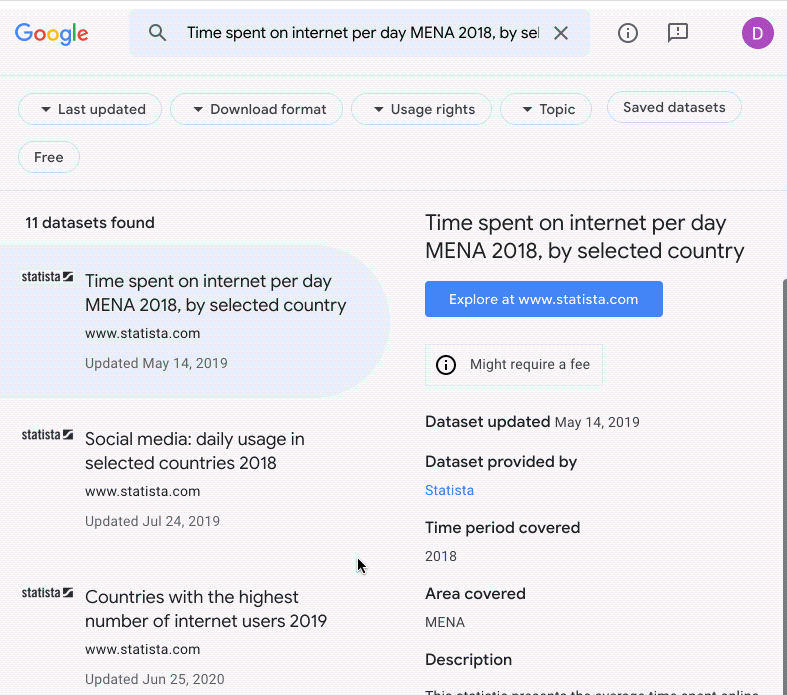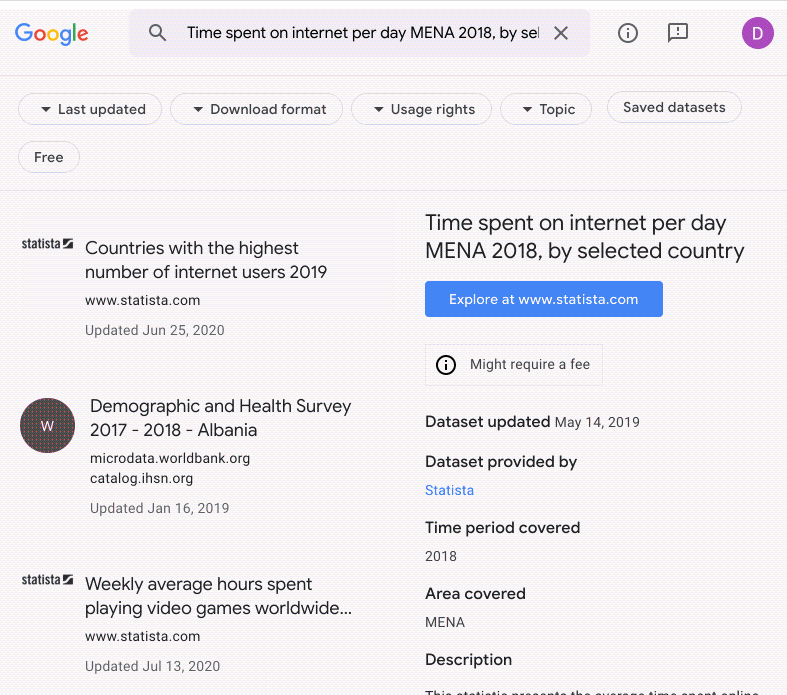
Parfois, évidemment, vous n'avez pas d'autres choix que d'étiqueter vos propres données. Toutefois, avant d'engager des centaines de stagiaires, envisagez d'utiliser le service d'étiquetage de données de Google. Pour employer cet outil, vous précisez d'abord comment vous souhaitez étiqueter vos données, puis Google les envoie à des équipes d'étiqueteurs humains. L'ensemble de données étiquetées obtenu peut être importé directement dans des modèles AutoML ou d'autres modèles AI Platform afin de les entraîner.
Du modèle à l'application opérationnelle
Bien souvent, la partie la plus compliquée du projet n'est pas de créer (ou trouver) un modèle de machine learning qui fonctionne. C'est de permettre aux autres membres de l'équipe d'utiliser le modèle avec leurs propres données. C'est un problème auquel nous avons souvent été confrontés avec l'IA Google Cloud, c'est pourquoi nous avons décidé d'ajouter des démonstrations interactives à nos pages de produits API. Ainsi, vous pouvez essayer rapidement nos API.
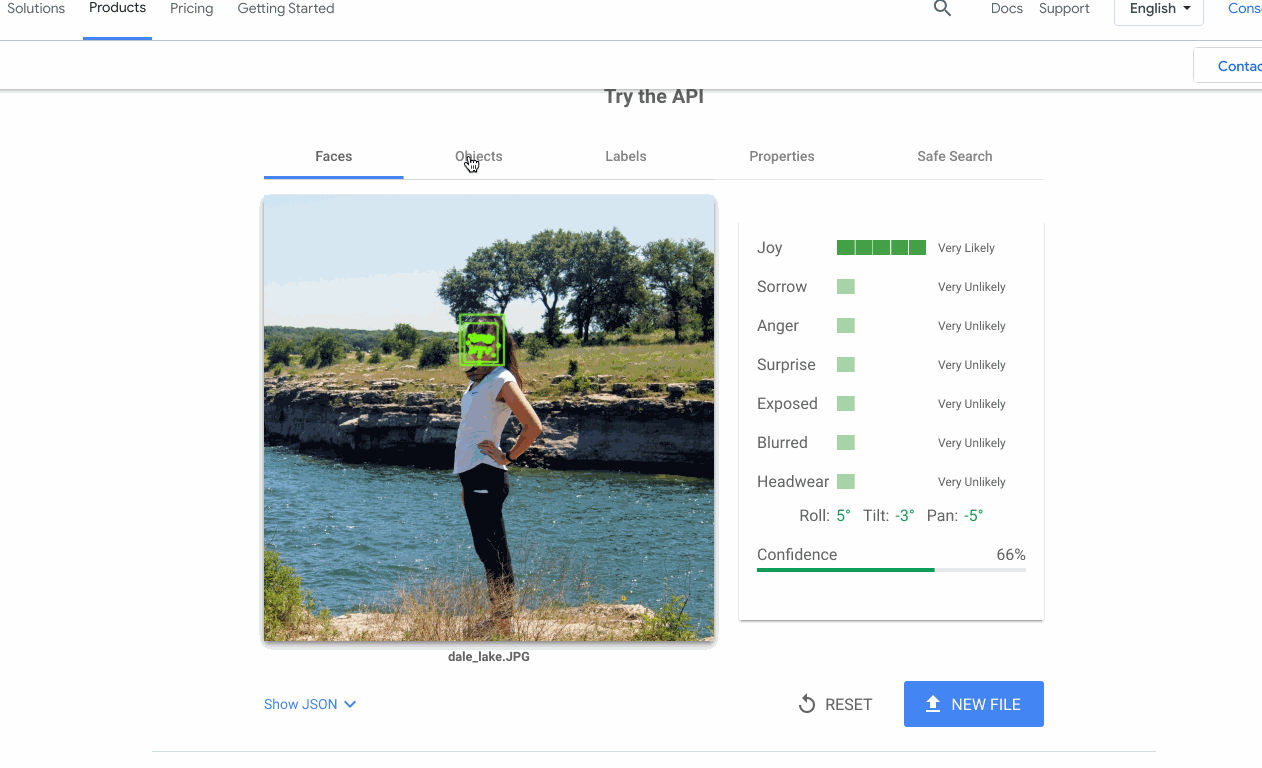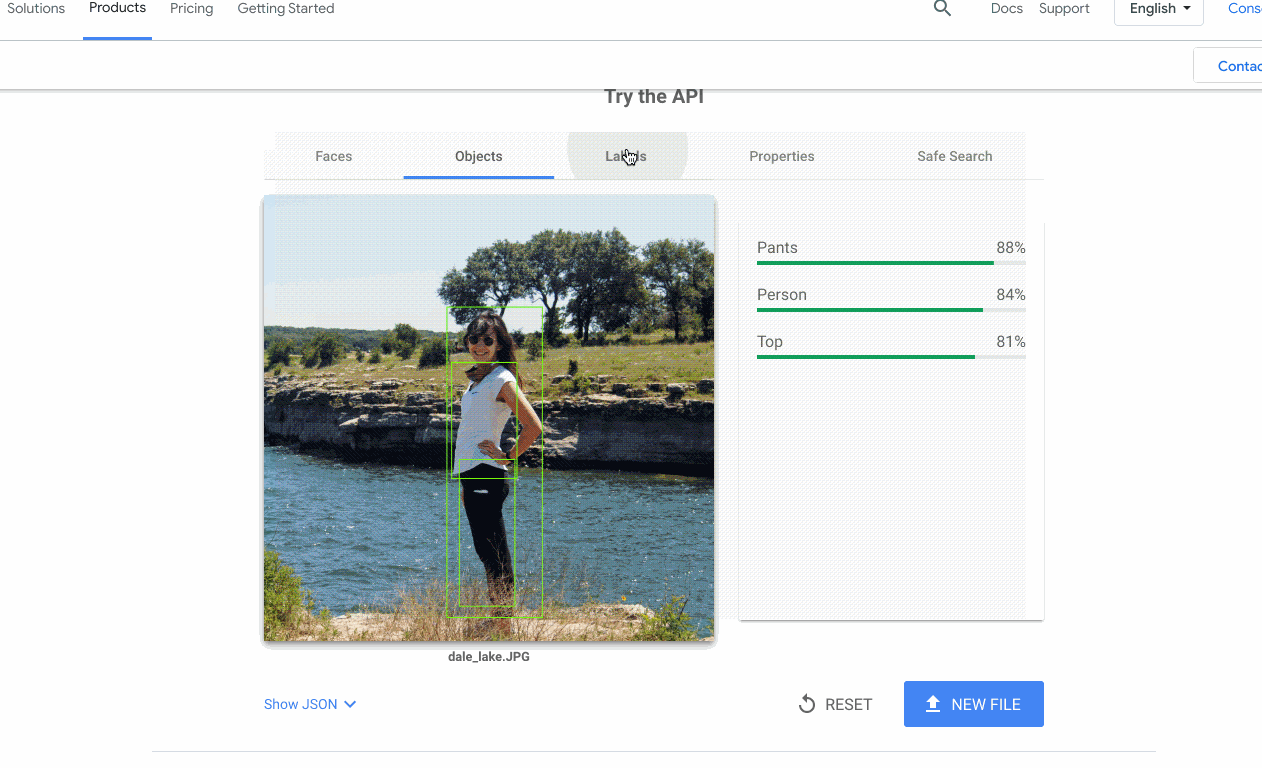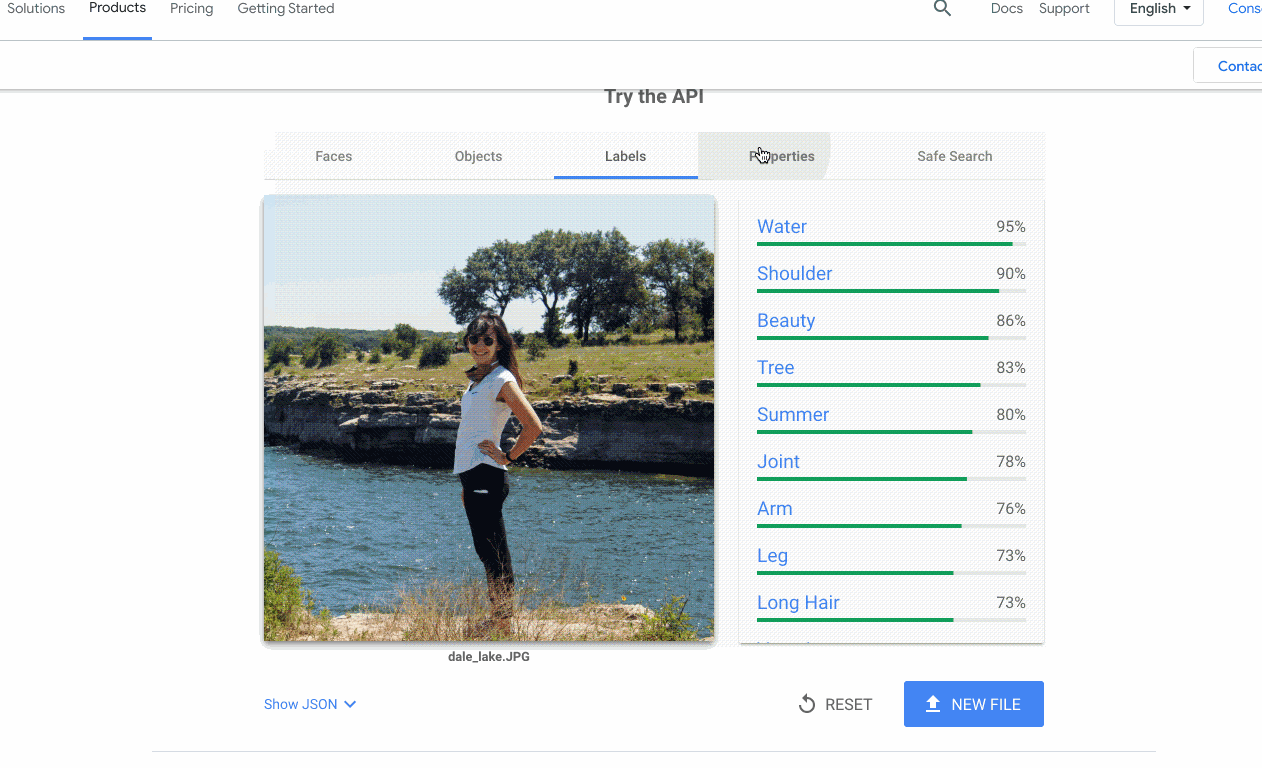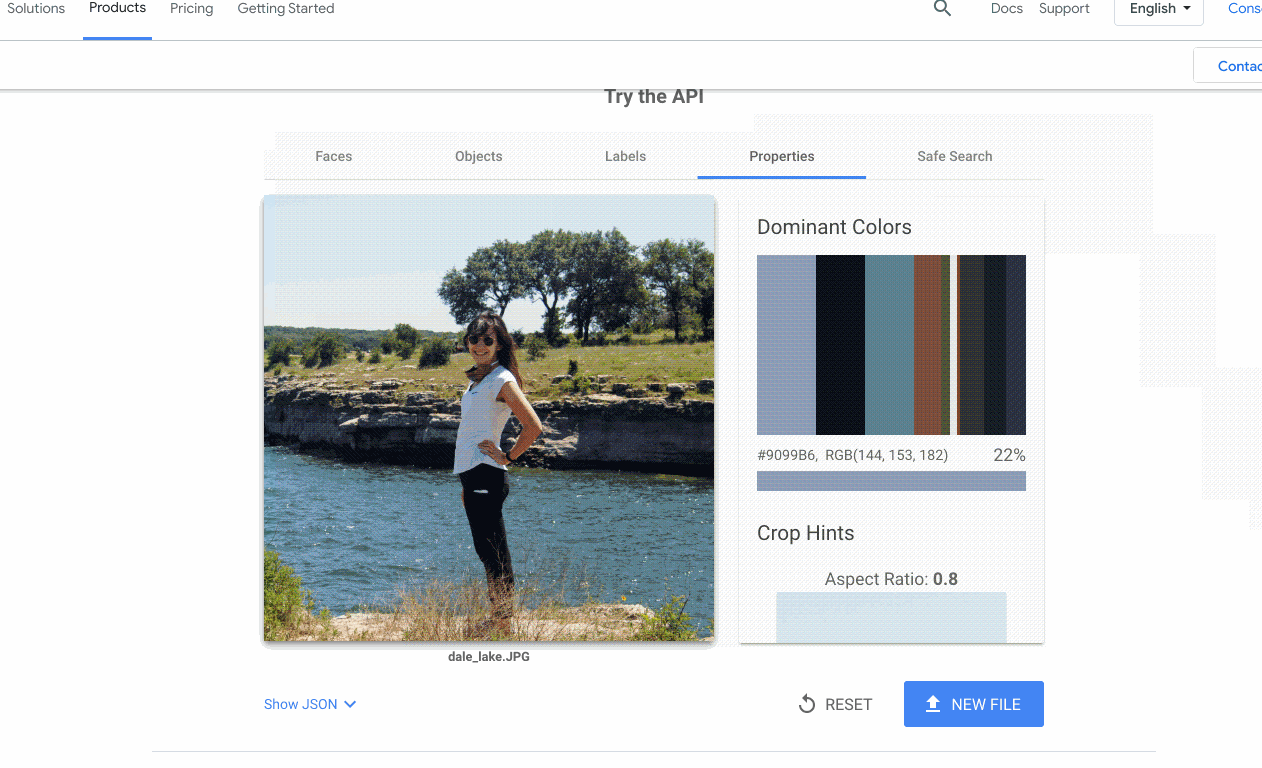
Mener à bien un projet de machine learning revient souvent à être capable de créer rapidement des prototypes. Pour cela, j'utilise systématiquement certains outils et architectures :
Ajouter le ML à Google Sheets : il est facile d'ajouter JavaScript aux applications G Suite comme Sheets, Docs et Forms à l'aide du framework Apps Script. Par exemple, on peut créer un modèle de classification de texte qui s'exécute chaque fois qu'on ajoute une ligne dans une feuille de calcul Google Sheets. On peut également créer un formulaire Google Forms qui permet d'importer des images et de les analyser à l'aide d'un modèle de ML, puis qui reporte les résultats dans une feuille de calcul Google Sheets.
Duo Google Cloud Storage + Cloud Functions : la plupart des projets de ML se résument à importer et exporter des données. Vous importez des données d'entrée (une image, une vidéo, un enregistrement audio, un extrait de texte, etc.), et un modèle réalise des prédictions à partir de ces données (les "données de sortie"). Cloud Storage et Cloud Functions sont d'excellents outils pour créer un prototype pour ce genre de projets. Cloud Storage est une sorte de dossier dans le cloud, un emplacement pour stocker des données de tous formats. Cloud Functions est un outil servant à exécuter des blocs de code dans le cloud sans avoir besoin d'un serveur dédié. Il est possible de configurer ces deux outils pour les utiliser conjointement : un fichier mis en ligne sur Cloud Storage va "déclencher" l'exécution d'une fonction Cloud.
Récemment, j'ai opté pour la configuration suivante pour créer un pipeline de documents utilisant l'IA :
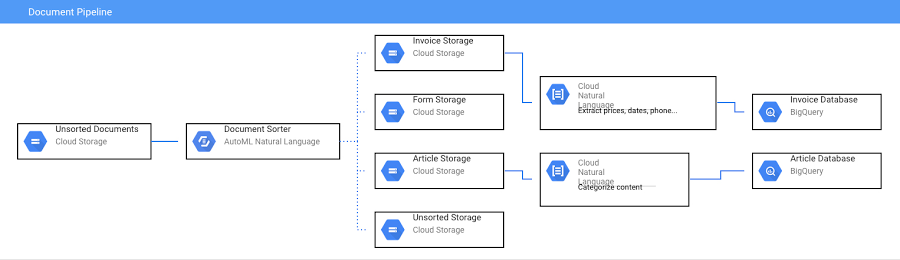
Lorsqu'un document est importé dans un bucket Cloud Storage, il déclenche une fonction Cloud qui analyse le type de document dont il s'agit et le déplace vers un autre bucket. Une autre fonction Cloud se déclenche alors : elle se sert de l'API Natural Language pour analyser le texte du document. Le code complet est consultable sur cette page.
Étapes suivantes
J'espère vous avoir convaincu qu'il n'est pas si compliqué de se mettre au machine learning. Vous trouverez ci-dessous quelques tutoriels et démonstrations utiles pour commencer à utiliser le ML :
Développeurs logiciel : vous apprenez à vous servir du machine learning
à l'enversClasser les projets de loi du congrès grâce au machine learning | par Sara Robinson
Découvrir l'API Cloud Vision : le machine learning vous intéresse, mais… |
par Sara RobinsonSérie YouTube "Créer des contenus à l'aide du machine learning"
(en ma compagnie)"AI Adventures" (aventures de l'intelligence artificielle) avec Yufeng Guo
Présentation de TensorFlow pour l'intelligence artificielle, le machine
learning et le deep learning

