Concevoir des applications GenAI avec les bases de données de Google Cloud
Sean Rhee
Product Management, Google Cloud
Contactez-nous
Si vous êtes une entreprise et que vous souhaitez vous développer, découvrez comment gagner en productivité avec Google Cloud ou contactez notre équipe commerciale.
Commencer iciEntraînés avec d’énormes volumes de données publiques portant sur un large éventail de sujets, les grands modèles de langage (LLM) se montrent pertinents dans bien des domaines mais ils peuvent aussi être améliorés sur d’autres.
Compte-tenu de la volumétrie nécessaire pour entraîner un modèle, des entraînements trop fréquents peuvent s’avérer très coûteux. Cependant, faute de mise à jour régulière, ils ne disposent pas toujours des informations les plus récentes. De plus, les modèles sont formés avec les données disponibles. Dès lors, ils n’ont pas accès à tout ce qui se trouve derrière le pare-feu d’entreprise, autrement dit ils ignorent tout du patrimoine informationnel de votre entreprise. Demandez à un LLM qui a gagné le match de football hier soir ou à combien se monte votre prime de votre assurance maladie ? Il ne connaîtra probablement pas la réponse.
Sur des questions d’ordre général, ces limites n’ont pas vraiment d’importance. Mais les entreprises qui exploitent les LLM - pour créer des applications et offrir des expériences conversationnelles avancées et ancrées dans leur réalité - en attendent de la précision, des informations à jour et une prise en compte de leurs savoirs et de leurs contextes.
Pour éviter d’avoir à réentraîner les modèles en permanence tout en leur permettant d’intégrer les données en temps réel, y compris celles derrière les pare-feux, il existe une technique de plus en plus prisée : le RAG (Retrieval Augmented Generation) ou génération augmentée de récupération en français. Cette technique ouvre de nouvelles opportunités et permet d’ancrer les LLM au contexte de l’entreprise. Autrement dit, le RAG permet aux entreprises de créer des applications utilisant une IA générative capable d’exploiter des données « fraiches » et propriétaires en enrichissant les prompts afin de permettre au LLM de fournir des données pertinentes et précises. Cette approche est particulièrement cruciale pour les entreprises et les industries soumises aux réglementations sur les données sensibles.
L’approche RAG
Voyons plus en détail comment cela fonctionne. Prenons l’exemple d’un chatbot « service client », capable de répondre à un large éventail de questions clients comme la disponibilité d’un produit, les prix pratiqués ou les politiques de retour. Si vous posez une question générique à un LLM classique de type « quels sont les jouets les plus populaires pour les enfants de moins de 5 ans ? », il sera en mesure de répondre. Mais comme il n’a pas la connaissance de l’inventaire en magasin, sa réponse ne sera pas forcément pertinente si votre question sous-entendait que vous vouliez acheter un produit populaire, donc en stock. C’est sur ce type de problématique que la technique RAG s’avère particulièrement efficace parce qu’elle permet au LLM d’enrichir sa réponse avec des données propriétaires (l’inventaire dans ce cas) à jour.
Découpé en une étape préliminaire suivie de quatre phases, cet exemple simplifié de RAG illustre comment une application peut fournir des réponses pertinentes en s’appuyant sur la fonction de recherche de similarité d'une base de données qui prend en charge l'indexation vectorielle.
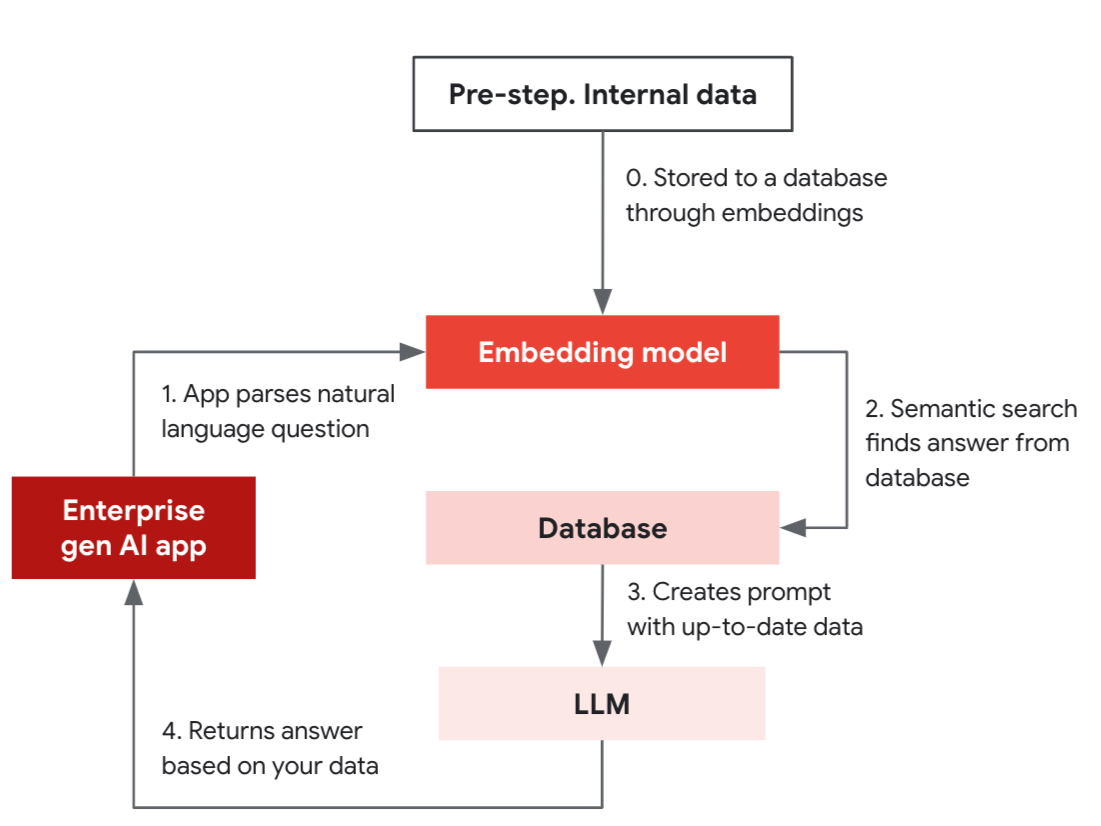
Phase préliminaire : les données internes sont stockées dans une base grâce à un modèle d’« embedding » (représentation vectorielle de données) aussi appelé « modèle d’incorporation » en français.
- L’application GenAI utilise le modèle « embedding » pour convertir la question en langage naturel (« Avez-vous le produit X avec les caractéristiques A, B, C ? ») en vecteur.
- Le modèle « embedding » utilisé pour convertir la question en vecteur effectue une recherche sémantique dans la base de données.
- La base de données renvoie alors les données à utiliser sous forme de complément à l’invite envoyée au LLM.
- Le LLM élabore une réponse précise basée sur les données.
LLM et base de données collaborent donc pour fournir des résultats actualisés.
Dans l’étape préliminaire, vous stockez vos données internes, telles que les descriptions de produits, sous forme de vecteurs grâce à un modèle d’incorporation (embedding). Votre application peut ainsi effectuer des recherches et trouver des résultats actualisés et précis, basés sur vos données. Elle peut alors répondre aux questions des utilisateurs en s’appuyant sur la fonction de recherche par similarité de la base de données vectorielle (Similarity Search) et en combinant les résultats obtenus à l’invite envoyée au LLM afin d’améliorer la pertinence de la réponse.
Les « embeddings » permettent de filtrer des données selon leur degré de similarité, en se servant d'algorithmes qui identifient de manière approximative les éléments les plus proches ou les plus similaires dans un espace vectoriel. Ils sont particulièrement utiles pour mettre en place des services tels que les recommandations de produits, la recherche portant sur les produits similaires avec lesquels le client a déjà interagi. Dès lors, les « embeddings » rendent les LLM plus puissants quand ils sont utilisés pour élaborer des prompts.
Plus concrètement, les LLM sont limités en taille d’instructions (ce qu’on appelle la fenêtre contextuelle du LLM) et ils n’ont pas de concept d’état. Dès lors, il n’est pas toujours possible de fournir un contexte complet dans le prompt (et ce serait de toute façon trop fastidieux).
Grâce aux « embeddings », il est possible d’effectuer des requêtes bien mieux contextualisées en élargissant le champ de recherche aux bases de données internes, à une documentation interne ou encore à un historique de discussion – et ainsi de « simuler une mémoire à long terme » du LLM – tout en lui permettant « d’acquérir » les connaissances spécifiques à une entreprise.
Bases de données vectorielles
Les incorporations vectorielles (vector embeddings) constituent la pierre angulaire de l’approche RAG. Google Cloud propose plusieurs options pour les stocker. Les trois principales sont :
- Vertex AI Vector Search, un outil spécialement conçu pour stocker et récupérer des vecteurs en grande quantité et avec une faible latence.
- Si vous êtes familiarisé avec PostgreSQL, pgvector extension permet d'ajouter facilement des requêtes vectorielles à votre base de données pour gérer les applications GenAI.
- Cloud SQL et AlloyDB prennent également en charge pgvector, AlloyDB AI gérant des tailles de vecteurs jusqu'à 4 fois plus grandes avec des performances jusqu'à 10 fois plus élevées par rapport à un PostgreSQL standard lors de l'utilisation du mode d'indexation IVFFlat.
Construire une application GenAI peut sembler difficile, mais en utilisant des outils compatibles open source tel que LangChain et en exploitant les ressources de Google Cloud, vous pouvez facilement commencer avec les concepts et outils décrits dans cet article.
Pour en savoir plus sur pgvector dans Cloud SQL et AlloyDB, consultez cet article.

