Wie Delivery Hero mit Vertex AI und GitHub Machine-Learning-Modelle gegen Gutscheinbetrug einsetzt

Artem Yushkovskiy
ML Engineer at Delivery Hero
Dr. Sören Petersen
Sr. AI/ML Specialist Google
In der sich ständig weiterentwickelnden Machine-Learning-Landschaft ist effizientes Modellmanagement entscheidend. Das gilt besonders für die Betrugserkennung, bei der die Modelle regelmäßig ausgetauscht werden müssen, damit sie gegen menschliche Gegner bestehen können, die die Logik von Fraud-Detection-Modellen per Reverse Engineering untersuchen und ihre Taktiken entsprechend anpassen.
Die weltweit führende lokale Lieferplattform Delivery Hero hat ein Incentive-Fraud-Team zusammengestellt, das ML-gestützte, regelbasierte Dienste zur Erkennung und Verhinderung des Missbrauchs von Incentive-Gutscheinen aufbaut. Diese Gutscheine werden beispielsweise als Anreiz für die erste Essensbestellung an neu registrierte Nutzerinnen und Nutzer ausgegeben. Deshalb muss es möglich sein, echte Neukund*innen zuverlässig von Personen zu unterscheiden, die für jede Bestellung einen neuen Account anlegen. Das ist nicht zuletzt deshalb besonders schwierig, weil Delivery Hero in mehr als 70 Ländern mit jeweils eigenen Datenschutzbestimmungen und unterschiedlichen lokalen Vorschriften tätig ist.
Technisches Setup
Überblick der Modell-Bereitstellung
Im Großen und Ganzen ist das Setup des Teams ein REST-API-Dienst, der regelbasierte Logik auf der Grundlage von Entscheidungen einer Reihe miteinander verbundener ML-Modelle implementiert. Da die API bei jeder Essensbestellung aufgerufen wird, unterliegt das Setup strengen Latenzbeschränkungen. Um diese Latenzanforderungen zu erfüllen, laufen der Dienst und die Modelle in regionalen Kubernetes-Clustern mit horizontalem Autoscaling und anderen Hochverfügbarkeitsverfahren.
Die grundlegende Modell-Bereitstellungsarchitektur ist im unten stehenden Diagramm dargestellt:
- Der blaue Pfad zeigt die Vorausberechnung mehrerer von anderen Modellen erzeugter ML-basierter Merkmale und die Speicherung der Ergebnisse im Zwischenspeicher.
- Der gelbe Pfad zeigt die eigentliche Betrugserkennungsanfrage, bei der Informationen über Bestellungen und Nutzer*innen zusammengefasst, mit der Anfrage an das eigentliche Betrugserkennungsmodell übergeben, und die Ergebnisse anschließend gemäß der konfigurierbaren regelbasierten Logik verarbeitet werden.
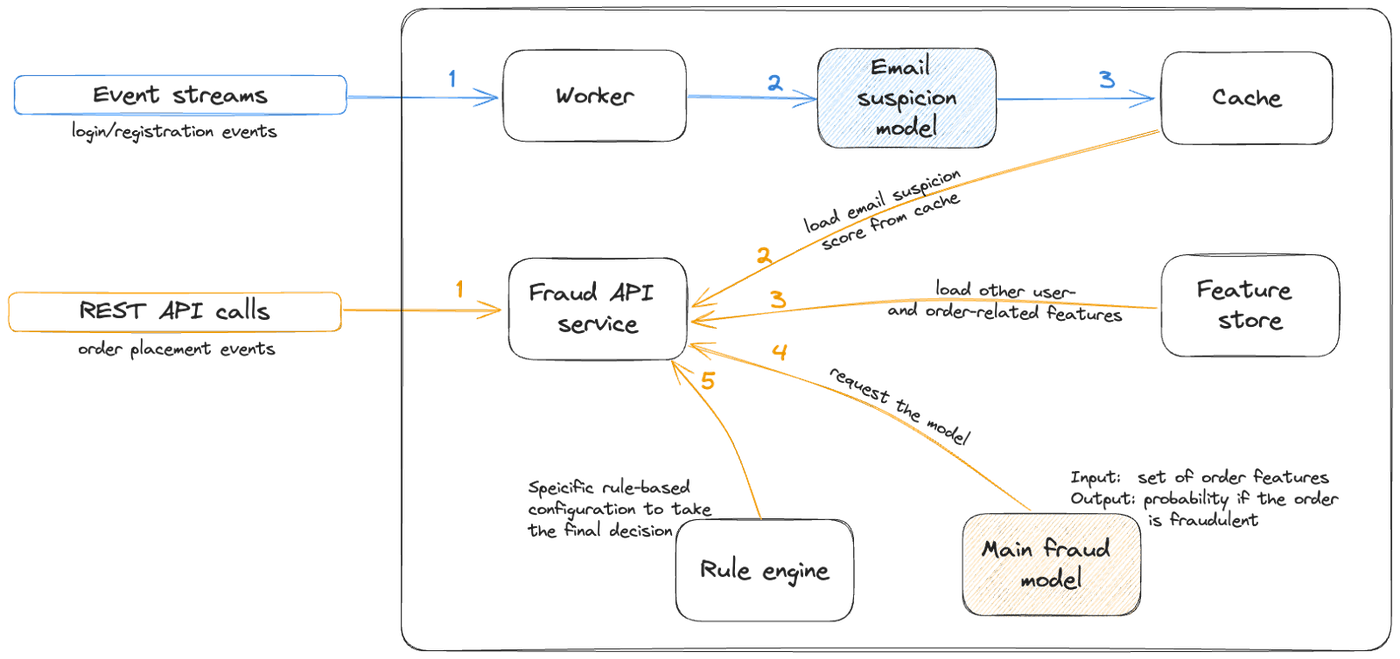
Die Gründe, aus denen sich das Team für Vertex AI als Entwicklungsumgebung für ML-Modelle entschieden hat, sind ihre Skalierbarkeit sowie ihre enge Integration mit BigQuery – dem primären Data Warehouse bei Delivery Hero – und anderen Google Cloud-Diensten. Die Modelle werden in Vertex AI Pipelines trainiert, die ihre Metadaten in der Vertex AI Model Registry speichern. Nach dem Training und der Analyse werden die Modelle dann von Cloud Build in ein FastAPI-Docker-Image eingebaut.
CI/CD für ML
Um schnelle Iterationen der Modellentwicklung zu ermöglichen, wurden alle Workflows in GitHub Actions CI/CD integriert. So können sich die Nutzerinnen und Nutzer beim Trainieren von Modellen und Erstellen von Images an Best Practices für Softwareentwicklung und MLOps-Modelle orientieren:
- Version Control (VC) – alle Änderungen werden sowohl auf der Modell- als auch auf der Datenseite nachverfolgt und die Daten als Snapshot einer in Form von Parquet-Dateien auf GCS gespeicherten BigQuery-Tabelle mit dem Parameter-Suffix ‚DATASET_VERSION‘ an Vertex Pipelines übergeben.
- Continuous Integration (CI) – zuverlässige trunk-basierte Entwicklung in einem GitHub-Repository, bei der Workflows ohne Auslösen der Pipelines auf dem lokalen Rechner an gemeinsame GCP Vertex AI-Umgebungen übermittelt werden. Dadurch können die Nutzer*innen (Data Scientists) Experimente mit expliziter Experimentverfolgung direkt in den Pull Requests (PR) durchführen.
- Continuous Deployment (CD) – ermöglicht den Nutzer*innen, neue Modelle ohne Unterstützung durch die Entwicklungsabteilung selbständig und sicher für die Produktion freizugeben („Friday Night Release“).
- Continuous Testing (CT) – Sichtbarkeit von Modellqualitätsmetriken und Artefaktabfolge mit CI/CD-Integration für bessere Zusammenarbeit zwischen Data Scientists, ML Engineers, Stakeholdern und Entscheidungsträger*innen.
Einer der Gründe für die Einführung von CT war, dass mehrere Modelle auf derselben Codebasis entwickelt und gepflegt, aber mit unterschiedlichen Datengruppen trainiert werden müssen. Nur so kann Delivery Hero dutzende länderspezifische Modelle unterhalten und in regionalen Clustern (EMEA, APAC usw.) bereitstellen. Dabei muss über jedes Modell individuell entschieden, die Entwicklung, Auswertung und manchmal auch die Bereitstellung von Iterationen jedoch für alle Modelle gemeinsam durchgeführt werden.
Details der Implementierung
Für den Anwendungsfall Incentive Fraud konnten die Workflows dieser ML-Operationen mit der GCP Vertex AI Model Registry über ein internes, vom Team entwickeltes Python-Paket ml-utils am Backend implementiert werden. Dieses Paket stellt eine einheitliche CLI- oder Python-API-Schnittstelle für die Verbindung der von GCP Vertex AI-Pipelines intern genutzten Kubeflow-Pipeline-Entitäten bereit: Pipelines (oder Pipeline Runs), Experimente (Gruppierung der Pipelines) sowie Modelle und Datasets (Output-Artefakte der Pipelines). Indem ml-utils intern die großen json-Definitionen der Kubeflow Pipeline Runs lädt, die benötigten Artefakte ermittelt und sie in einem vordefinierten Format herunterlädt, bietet das Paket den Nutzer*innen eine einheitliche Möglichkeit zur Interaktion mit der Vertex Model Registry.
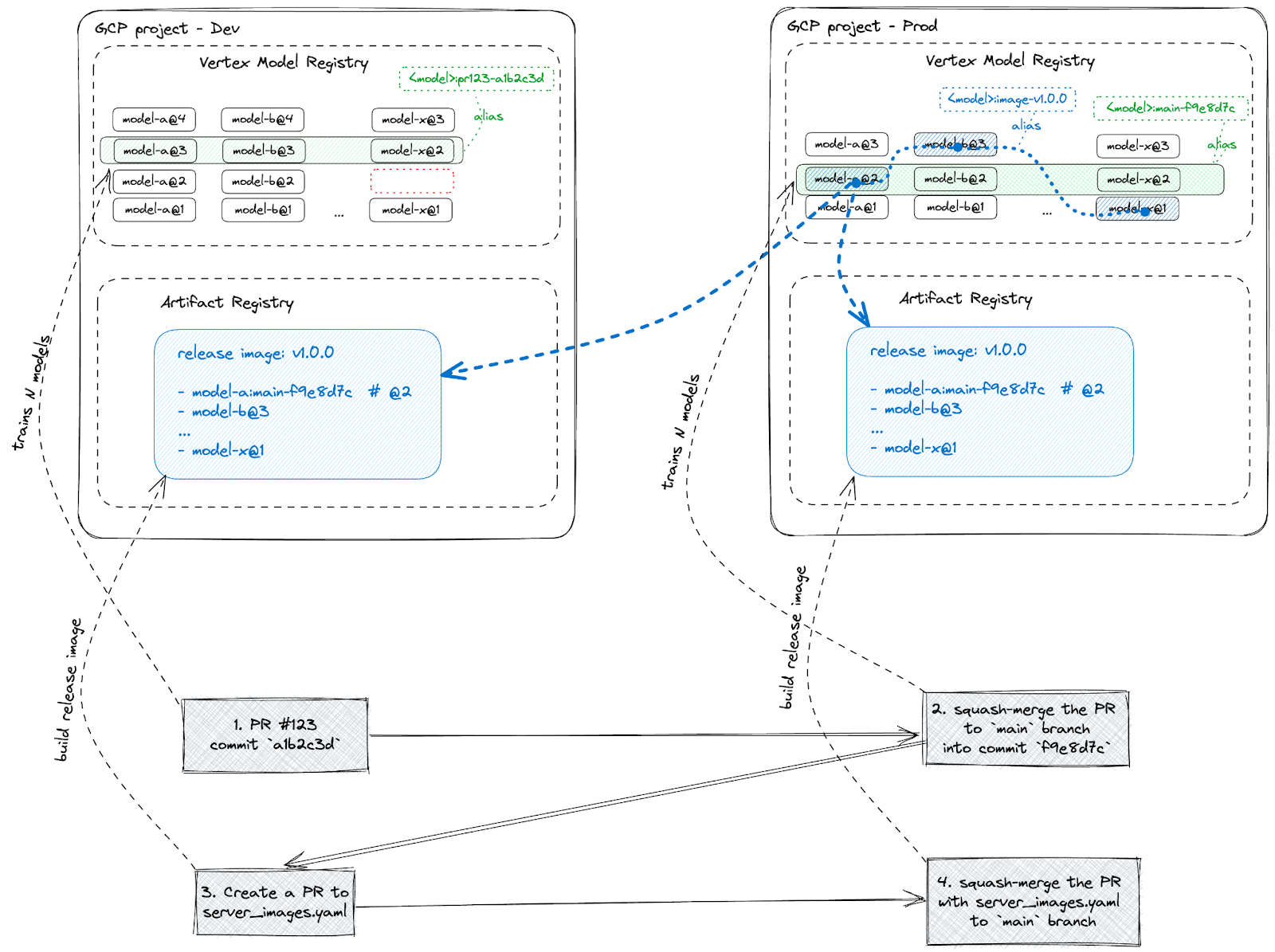
Die unten stehende Abbildung verdeutlicht den Einsatz des beschriebenen CI/CD-Workflows auf Basis von Vertex AI mit dem benutzerdefinierten Tool ml-utils:
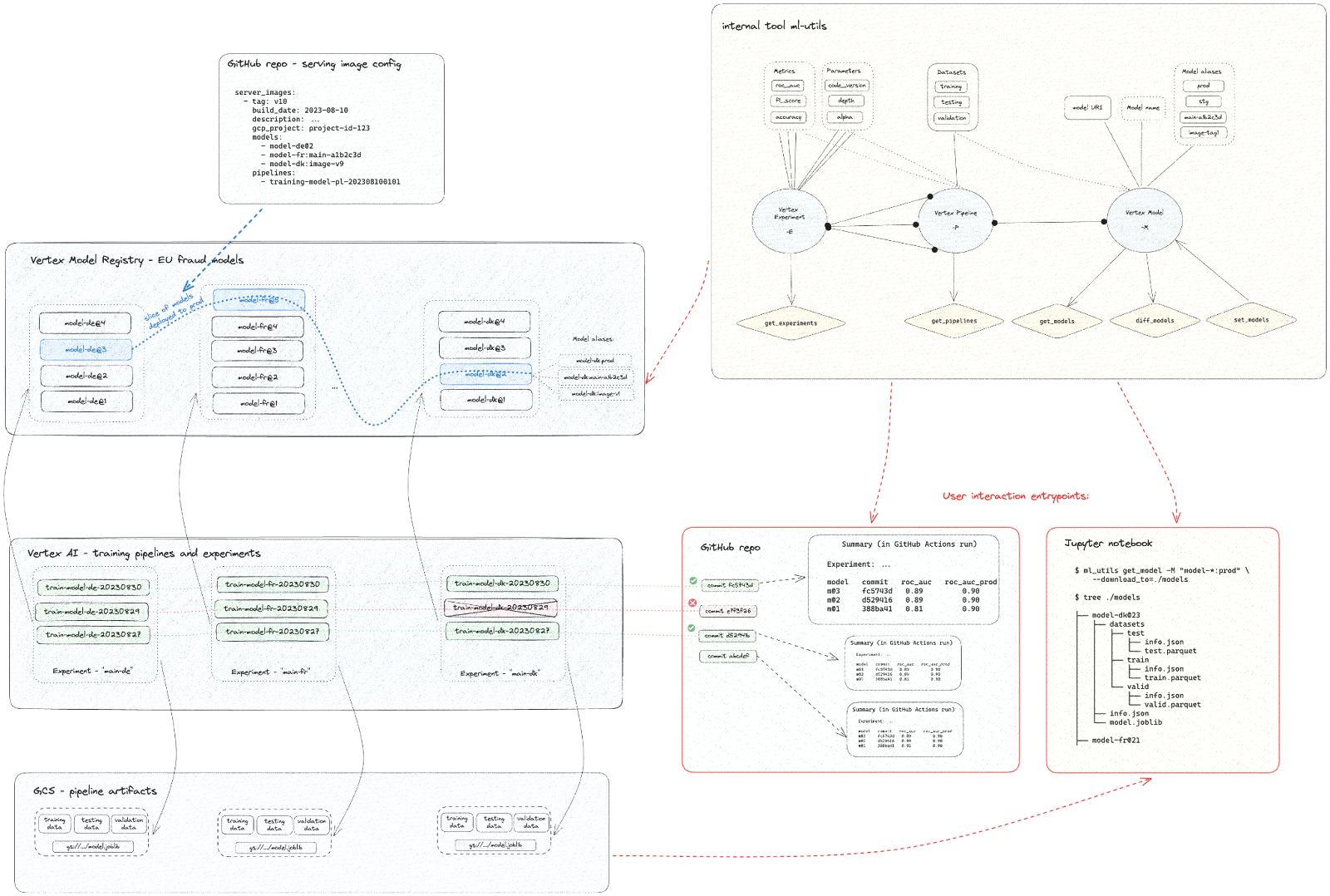
Wie die obige Abbildung zeigt, löst jeder im GitHub-Repository erstellte Commit in Vertex AI für jedes Land eine eigene Trainingspipeline aus. Einige der Pipelines können fehlschlagen (rot markiert), andere sind erfolgreich (grün).
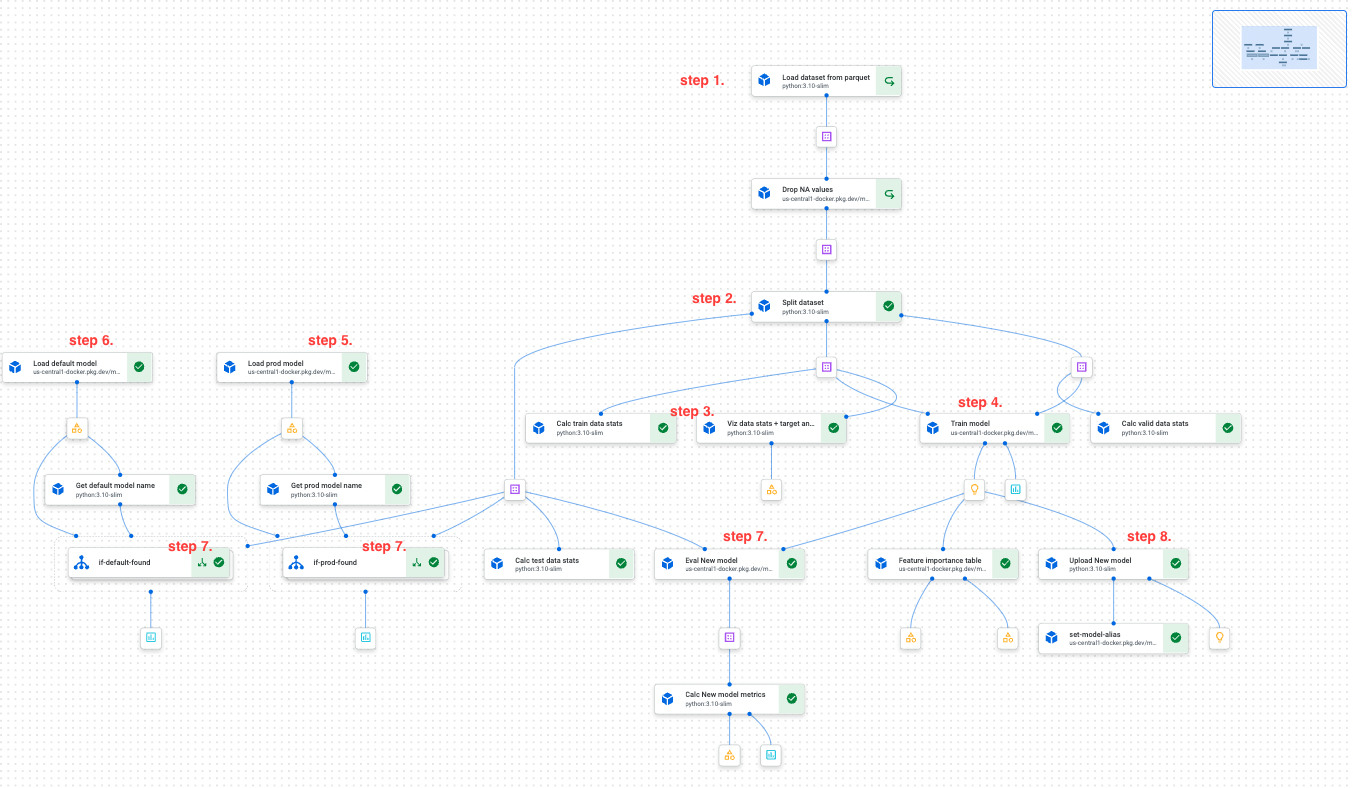
Schritte der Vertex AI Trainingspipeline (siehe unten stehender Screenshot):
- Den angegebenen Dataset-Snapshot aus GCS laden
- Die Daten in Training/Test/Validierung aufteilen
- Die Eigenschaften des Datasets (Statistik und Visualisierung, Datendrift usw.) berechnen
- Ein neues Modell trainieren
- Das derzeit für die Produktion bereitgestellte Modell laden (mit ml-utils)
- Das gemäß bestimmten Metriken beste Modell („Champion-Modell“) laden (mit ml-utils)
- Alle drei Modelle anhand desselben Dataset-Testsegments evaluieren und die Evaluierungsmetriken in der Vertex AI Model Registry speichern – als Experiment-Metadaten, die mit ml-utils abgerufen werden können
- Das neue Modell in die Vertex AI Model Registry hochladen und seine Aliasse aktualisieren:
- Ein Alias, der den Git-Commit-Hash enthält: ‚pr123-a1b2c3d‘ für einen PR-Commit oder ‚main-a1b2c3d‘ für einen Main Branch-Commit
- Wenn das Modell das Champion-Modell übertrifft, den Alias ‚champ‘ diesem Modell zuweisen.
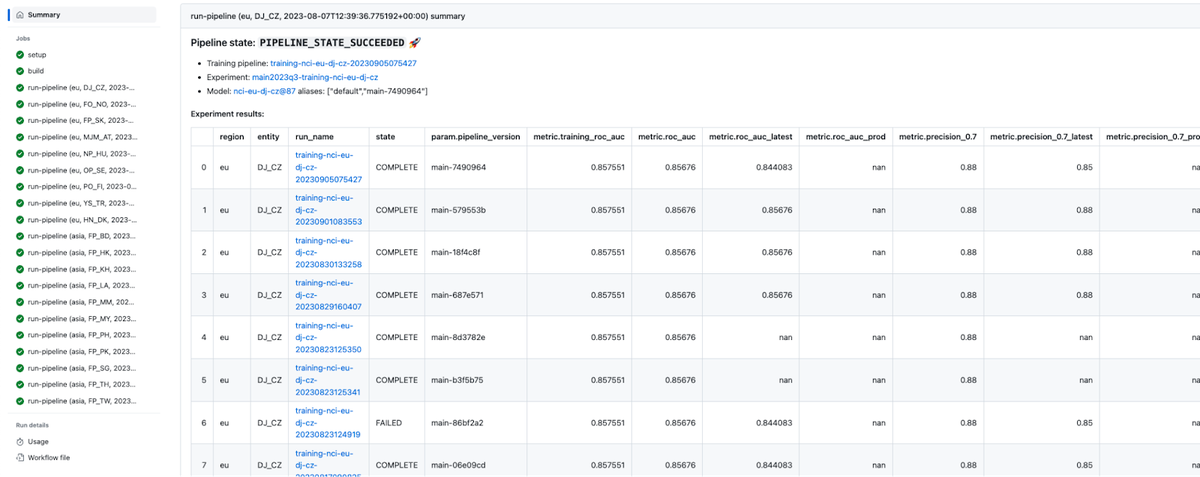
Alle Artefakte der Pipeline (Datenabschnitte, Modelle usw.) werden automatisch auf GCS gespeichert. Sobald alle Vertex AI-Pipelines erfolgreich sind, nutzt der GitHub Actions-Job, der die Pipelines ausgelöst hat, ml-utils, um die Evaluierungsmetriken aus der Vertex AI Model Registry abzurufen und als Markdown sichtbar auf der Übersichtsseite des GitHub Action-Jobs auszugeben (siehe unten stehende Abbildung). Auf diese Weise ist jeder Git-Commit mit einem Satz Vertex-Pipelines und mit dem Modellqualitätsbericht verknüpft, der Data Scientists und Managern als Entscheidungsgrundlage dient.
Sobald das Team bereit ist, einige der Modelle auszutauschen, erstellt es einen Pull Request (PR), um die Konfiguration des Bereitstellungs-Image zu ändern, die angibt, welche Abschnitte der Modelle für die Produktion bereitgestellt werden sollen. Das ist die blaue gestrichelte Linie in der Vertex Model Registry. Dieser PR löst einen weiteren GitHub Actions-Workflow aus, der einen Cloudbuild-Workflow übermittelt. Darin werden die angegebenen Modell-Pickles geladen, das FastAPI Server-Image mit den eingebundenen Modellen erstellt, Integrationstests durchgeführt und die Aliasse der Modelle aktualisiert (mit dem Alias „image-{imagetag}“ versehen).
Der folgende Screenshot zeigt die GitHub Actions-Seite mit der Trainings-Übersichtsseite für eines der Modelle:
Überblick der Infrastruktur
Für die Incentive Fraud-Projekte nutzte das Team zwei Umgebungen:
- Dev – eine Umgebung mit lockeren Sicherheitsbeschränkungen für Experimente mit den Modellen und End-to-End (e2e)-Tests der Pipelines für das Modell-Training
- Prod – eine Umgebung mit strengen Sicherheitsbeschränkungen für die Produktion von Modell-Release-Kandidaten
Um die Arbeit mit den beiden Projekten zu erleichtern, hat das Team fünf grundlegende Regeln implementiert:
- GitHub Actions verhält sich bei der Ausführung von GCP-Workflows in Dev-Umgebungen genauso wie in Prod-Umgebungen.
- Jeder PR-Commit löst GCP-Workflows in der Dev-Umgebung aus.
- Jeder Main Branch-Commit löst GCP-Workflows in der Prod-Umgebung aus.
- Dev- und Prod-Pipelines verwenden dieselben Code- und Dataset-Snapshots.
- Jeder PR wird zunächst in einen einzelnen Commit gepackt und erst dann in den Main Branch eingebunden.
Dank dieser Regeln verfügt das Team über eine saubere, lineare Main-Branch-Historie, in der jeder Commit, der den Modellcode, die Dataset-Version oder die Konfiguration ändert, für jedes Land einen Satz Modell-Release-Kandidaten mit den erwarteten Qualitätsmetriken erstellt:
Ergebnisse
Dank des beschriebenen MLOps-Setups war das Team in der Lage, die vorgegebenen KPIs zu erreichen und die Zeit bis zum Server-Modell-Release durch Automatisieren des gesamten Prozesses und Implementieren von Best Practices für Softwareentwicklung und MLOps-Modelle von mehreren Tagen auf eine Stunde zu verkürzen.
Konkret konnte das Team:
- Modelle sicher für mehr als 20 Länder in zwei Weltregionen skalieren
- Für lückenlose Nachverfolgbarkeit in Git und Modellabfolge in Vertex AI sorgen
- „Zeitreisen“ durchführen (mit neuem Modellcode auf älteren Dataset-Snapshots experimentieren)
- Ein geeignetes Pipeline-Caching zur Kostenoptimierung implementieren
- Training, Batch-Scoring-Pipelines sowie Modellanalyse-Notebooks und Modellbereitstellungs-Workflows automatisieren
- MLOps-Level 2 mit vollständiger Automatisierung von CI/CD-Pipeline, Quellcodekontrolle und Bereitstellungsprozessen effektiv umsetzen
Highlights der Umsetzung:
- Von mehr als 20 Entwicklern, Data Scientists und Managern gemeinsam genutzte Lösung
- Von mehreren Tagen auf vier Stunden verkürzter ML-Zyklus
- Über einen Zeitraum von zehn Monaten genutzte Lösung (Stand: Oktober 2023)
- Für zwei verschiedene ML-Anwendungsfälle implementiert
- Für zwei verschiedene ML-Anwendungsfälle pro Woche
- Mehr als 20 vollautomatische Bereitstellungen pro Projekt, durchschnittlich zwei Bereitstellungen pro Monat
- Rückgang des Gutscheinbetrugs um 70 %.
Wenn Sie mehr darüber erfahren möchten, wie Delivery Hero durch den Aufbau eines BigQuery-gestützten Datennetzes unternehmensweite Demokratisierung von Daten erreichen und datenbasierte Lösungen beschleunigen konnte, lesen Sie diese Fallstudie.

