Tutorial ini menjelaskan cara menjelajahi dan memvisualisasikan data menggunakan library klien BigQuery untuk Python dan pandas dalam instance notebook Jupyter yang dikelola di Vertex AI Workbench. Alat visualisasi data dapat membantu Anda menganalisis data BigQuery secara interaktif, serta mengidentifikasi tren dan menyampaikan insight dari data Anda. Tutorial ini menggunakan data yang ditemukan di set data publik BigQuery Google Trends.
Tujuan
- Buat instance notebook Jupyter terkelola menggunakan Vertex AI Workbench.
- Membuat kueri data BigQuery menggunakan perintah magic di notebook.
- Buat kueri dan visualisasikan data BigQuery menggunakan library klien BigQuery Python dan pandas.
Biaya
BigQuery adalah produk berbayar, sehingga Anda akan dikenai biaya penggunaan BigQuery saat mengakses BigQuery. Gratis 1 TB data kueri pertama yang diproses setiap bulan. Untuk informasi selengkapnya, lihat halaman harga BigQuery.
Vertex AI Workbench adalah produk berbayar, dan Anda akan dikenai biaya komputasi, penyimpanan, dan pengelolaan saat menggunakan instance Vertex AI Workbench. Untuk mengetahui informasi selengkapnya, lihat halaman harga Vertex AI Workbench.
Sebelum memulai
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Untuk project baru, BigQuery diaktifkan secara otomatis.
Aktifkan Notebooks API.
Ringkasan: Notebook Jupyter
Notebook menyediakan lingkungan untuk menulis dan mengeksekusi kode. Notebook pada dasarnya adalah artefak sumber, yang disimpan sebagai file IPYNB. File ini dapat berisi konten teks deskriptif, blok kode yang dapat dieksekusi, dan output yang dirender sebagai HTML interaktif.
Secara struktural, notebook adalah urutan sel. Sel adalah blok teks input yang dievaluasi untuk menghasilkan hasil. Sel dapat berupa tiga jenis:
- Sel kode berisi kode yang akan dievaluasi. Output atau hasil kode yang dieksekusi dirender sesuai dengan kode yang dieksekusi.
- Sel Markdown berisi teks Markdown yang dikonversi menjadi HTML untuk membuat header, daftar, dan teks berformat.
- Sel mentah dapat digunakan untuk merender berbagai format kode ke dalam HTML atau LaTeX.
Gambar berikut menunjukkan sel Markdown yang diikuti dengan sel kode Python, lalu diikuti dengan output:
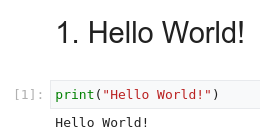
Setiap notebook yang dibuka dikaitkan dengan sesi yang sedang berjalan (juga dikenal sebagai kernel di Python). Sesi ini mengeksekusi semua kode di notebook, dan mengelola status. Status mencakup variabel dengan nilai, fungsi, dan class-nya, serta modul Python yang ada yang Anda muat.
Di Google Cloud, Anda dapat menggunakan lingkungan berbasis notebook Vertex AI Workbench untuk membuat kueri dan menjelajahi data, mengembangkan dan melatih model, serta menjalankan kode sebagai bagian dari pipeline. Dalam tutorial ini, Anda akan membuat instance notebook terkelola di Vertex AI Workbench, lalu menjelajahi data BigQuery dalam antarmuka JupyterLab.
Membuat instance notebook terkelola
Di bagian ini, Anda akan menyiapkan instance JupyterLab di Google Cloud sehingga Anda dapat membuat notebook terkelola.
Di konsol Google Cloud, buka halaman Workbench.
Klik News notebook.
Di kolom Notebook name, masukkan nama instance Anda.
Di daftar Region, pilih region untuk instance Anda.
Di bagian Permission, pilih opsi untuk menentukan pengguna mana yang dapat mengakses instance notebook terkelola:
- Service account: Opsi ini memberikan akses ke semua pengguna yang memiliki akses ke akun layanan Compute Engine yang Anda tautkan ke runtime. Untuk menentukan akun layanan Anda sendiri, hapus centang pada kotak Use Compute Engine default service account, lalu masukkan alamat email akun layanan yang ingin digunakan. Untuk mengetahui informasi selengkapnya tentang akun layanan, lihat Jenis akun layanan.
- Hanya satu pengguna: Opsi ini hanya memberikan akses kepada pengguna tertentu. Di kolom User email, masukkan alamat email akun pengguna milik pengguna yang akan menggunakan instance notebook terkelola.
Opsional: Untuk mengubah setelan lanjutan instance, klik Setelan lanjutan. Untuk mengetahui informasi selengkapnya, lihat Membuat instance menggunakan setelan lanjutan.
Klik Buat.
Tunggu beberapa menit hingga instance selesai dibuat. Vertex AI Workbench akan otomatis memulai instance. Saat instance siap digunakan, Vertex AI Workbench akan mengaktifkan link Open JupyterLab.
Menjelajahi resource BigQuery di JupyterLab
Di bagian ini, Anda akan membuka JupyterLab dan menjelajahi resource BigQuery yang tersedia di instance notebook terkelola.
Pada baris untuk instance notebook terkelola yang Anda buat, klik Buka JupyterLab.
Jika diminta, klik Autentikasi jika Anda menyetujui persyaratannya. Instance notebook terkelola Anda akan membuka JupyterLab di tab browser baru.
Di menu navigasi JupyterLab, klik
 BigQuery di Notebooks.
BigQuery di Notebooks.Panel BigQuery mencantumkan project dan set data yang tersedia, tempat Anda dapat melakukan tugas sebagai berikut:
- Untuk melihat deskripsi set data, klik dua kali pada nama set data.
- Untuk menampilkan tabel, tampilan, dan model set data, luaskan set data.
- Untuk membuka deskripsi ringkasan sebagai tab di JupyterLab, klik dua kali pada tabel, tampilan, atau model.
Catatan: Pada deskripsi ringkasan untuk tabel, klik tab Preview untuk melihat pratinjau data tabel. Gambar berikut menunjukkan pratinjau tabel
international_top_termsyang ditemukan dalam set datagoogle_trendsdi projectbigquery-public-data: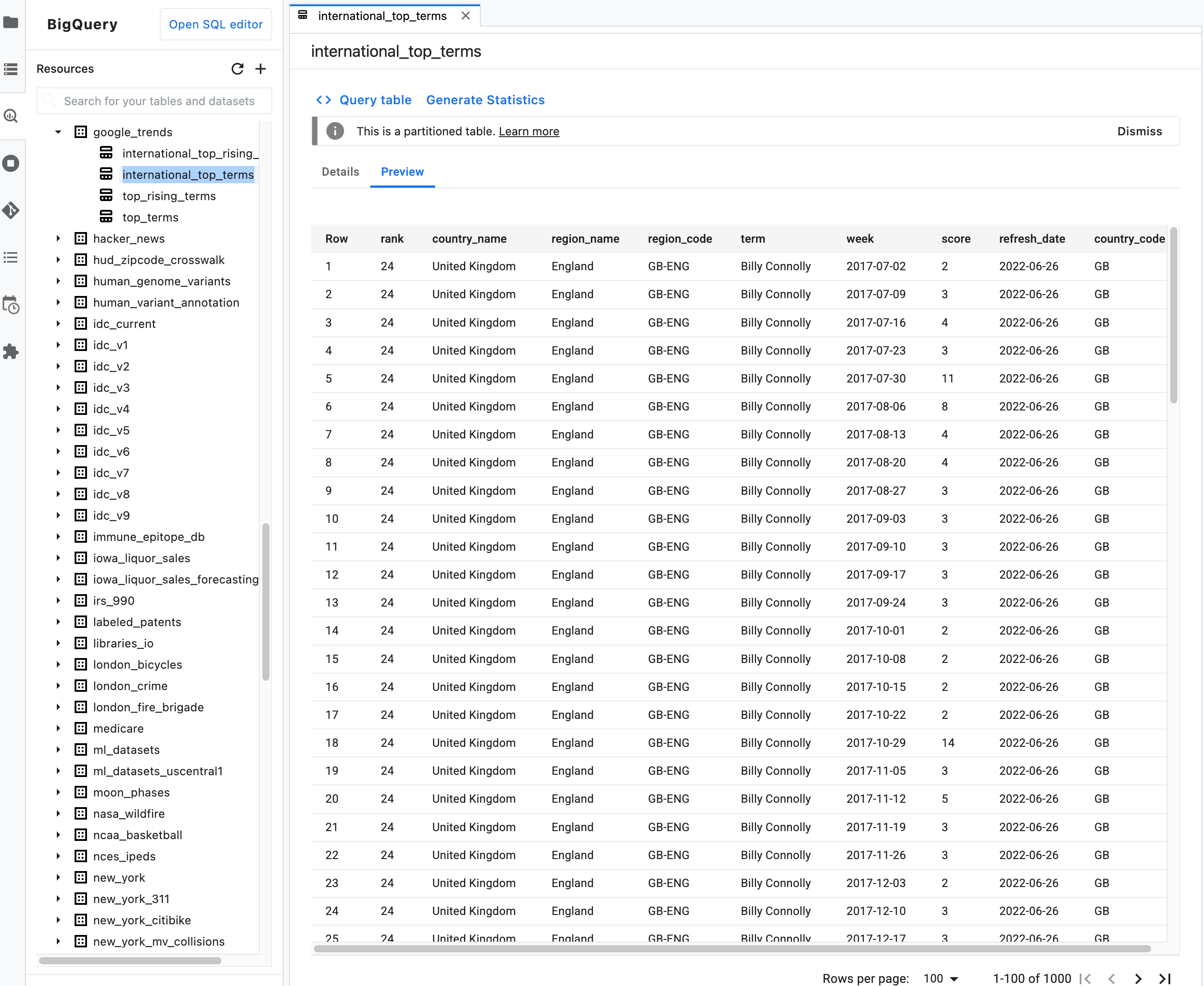
Membuat kueri data notebook menggunakan perintah magic %%bigquery
Di bagian ini, Anda akan menulis SQL langsung di sel notebook dan membaca data dari BigQuery ke dalam notebook Python.
Perintah magic yang menggunakan karakter persentase tunggal atau ganda (% atau %%) memungkinkan Anda menggunakan sintaksis minimal untuk berinteraksi dengan BigQuery dalam notebook. Library klien BigQuery untuk Python otomatis diinstal di instance notebook terkelola. Di balik layar, perintah magic %%bigquery menggunakan library klien BigQuery agar Python dapat menjalankan kueri yang diberikan, mengonversi hasilnya menjadi DataFrame pandas, menyimpan hasil ke variabel secara opsional, dan kemudian menampilkan hasil tersebut.
Catatan: Mulai versi 1.26.0 paket Python google-cloud-bigquery, BigQuery Storage API digunakan secara default untuk mendownload hasil dari perintah magic %%bigquery.
Untuk membuka file notebook, pilih File > New > Notebook.
Dalam dialog Select Kernel, pilih Python (Local), lalu klik Select.
File IPYNB baru Anda akan terbuka.
Untuk mendapatkan jumlah region berdasarkan negara dalam set data
international_top_terms, masukkan pernyataan berikut:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Klik Run cell.
Outputnya mirip dengan hal berikut ini:
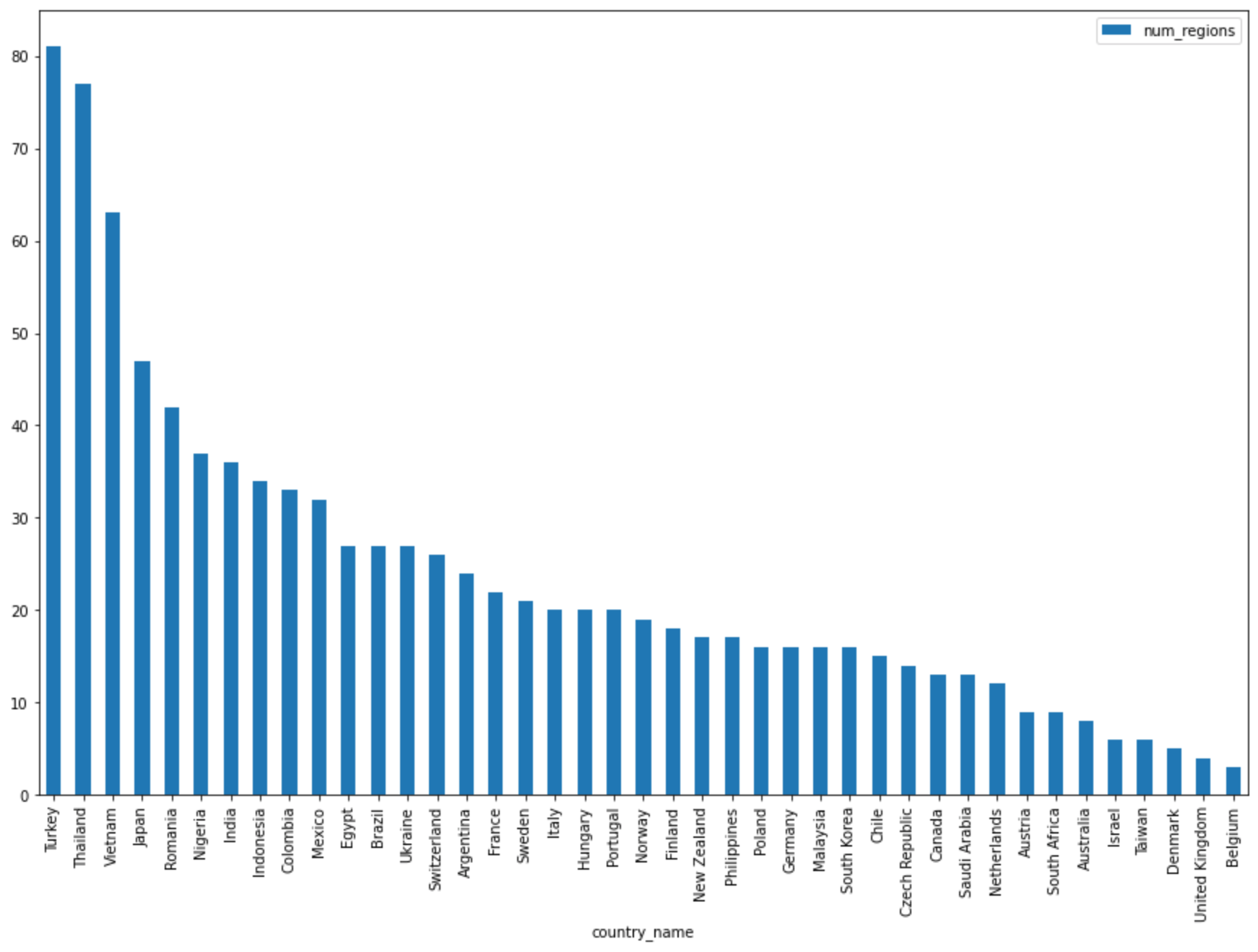
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Pada sel berikutnya (di bawah output dari sel sebelumnya), masukkan perintah berikut untuk menjalankan kueri yang sama, tetapi kali ini simpan hasilnya ke DataFrame pandas baru yang bernama
regions_by_country. Anda memberikan nama tersebut menggunakan argumen dengan perintah magic%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Catatan: Untuk informasi selengkapnya tentang argumen yang tersedia untuk perintah
%%bigquery, lihat dokumentasi keajaiban library klien.Klik Run cell.
Di sel berikutnya, masukkan perintah berikut untuk melihat beberapa baris pertama hasil kueri yang baru saja Anda baca:
regions_by_country.head()Klik Run cell.
DataFrame
regions_by_countrypandas siap dipetakan.
Membuat kueri data di notebook menggunakan library klien BigQuery secara langsung
Di bagian ini, Anda akan langsung menggunakan library klien BigQuery untuk Python untuk membaca data ke notebook Python.
Library klien memberi Anda kontrol lebih besar atas kueri dan memungkinkan Anda menggunakan konfigurasi yang lebih kompleks untuk kueri dan tugas. Integrasi library dengan pandas memungkinkan Anda menggabungkan kecanggihan SQL deklaratif dengan kode imperatif (Python) untuk membantu Anda menganalisis, memvisualisasikan, dan mengubah data.
Catatan: Anda dapat menggunakan sejumlah library analisis data, data wrangling, dan visualisasi Python, seperti numpy, pandas, matplotlib, dan banyak lagi. Beberapa library ini dibangun di atas objek DataFrame.
Di sel berikutnya, masukkan kode Python berikut untuk mengimpor library klien BigQuery untuk Python dan melakukan inisialisasi klien:
from google.cloud import bigquery client = bigquery.Client()Klien BigQuery digunakan untuk mengirim dan menerima pesan dari BigQuery API.
Klik Run cell.
Di sel berikutnya, masukkan kode berikut untuk mengambil persentase istilah teratas harian di
top_termsAS yang tumpang-tindih dengan istilah teratas dari beberapa hari sebelumnya. Intinya adalah melihat istilah teratas setiap hari dan mencari tahu berapa persen yang tumpang tindih dengan istilah teratas dari hari sebelumnya, 2 hari sebelumnya, 3 hari sebelumnya, dan seterusnya (untuk semua pasangan tanggal selama rentang waktu sekitar satu bulan).sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
SQL yang digunakan digabungkan dalam string Python, lalu diteruskan ke metode
query()untuk menjalankan kueri. Metodeto_dataframemenunggu kueri selesai dan mendownload hasilnya ke DataFrame pandas menggunakan BigQuery Storage API.Klik Run cell.
Beberapa baris pertama hasil kueri muncul di bawah sel kode.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Untuk mengetahui informasi lebih lanjut tentang cara menggunakan library klien BigQuery, lihat panduan memulai Menggunakan library klien.
Memvisualisasikan data BigQuery
Di bagian ini, Anda akan menggunakan kemampuan plot untuk memvisualisasikan hasil dari kueri yang sebelumnya Anda jalankan di notebook Jupyter.
Di sel berikutnya, masukkan kode berikut untuk menggunakan metode
DataFrame.plot()pandas untuk membuat diagram batang yang memvisualisasikan hasil kueri yang menampilkan jumlah region berdasarkan negara:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Klik Run cell.
Outputnya mirip dengan yang berikut ini:
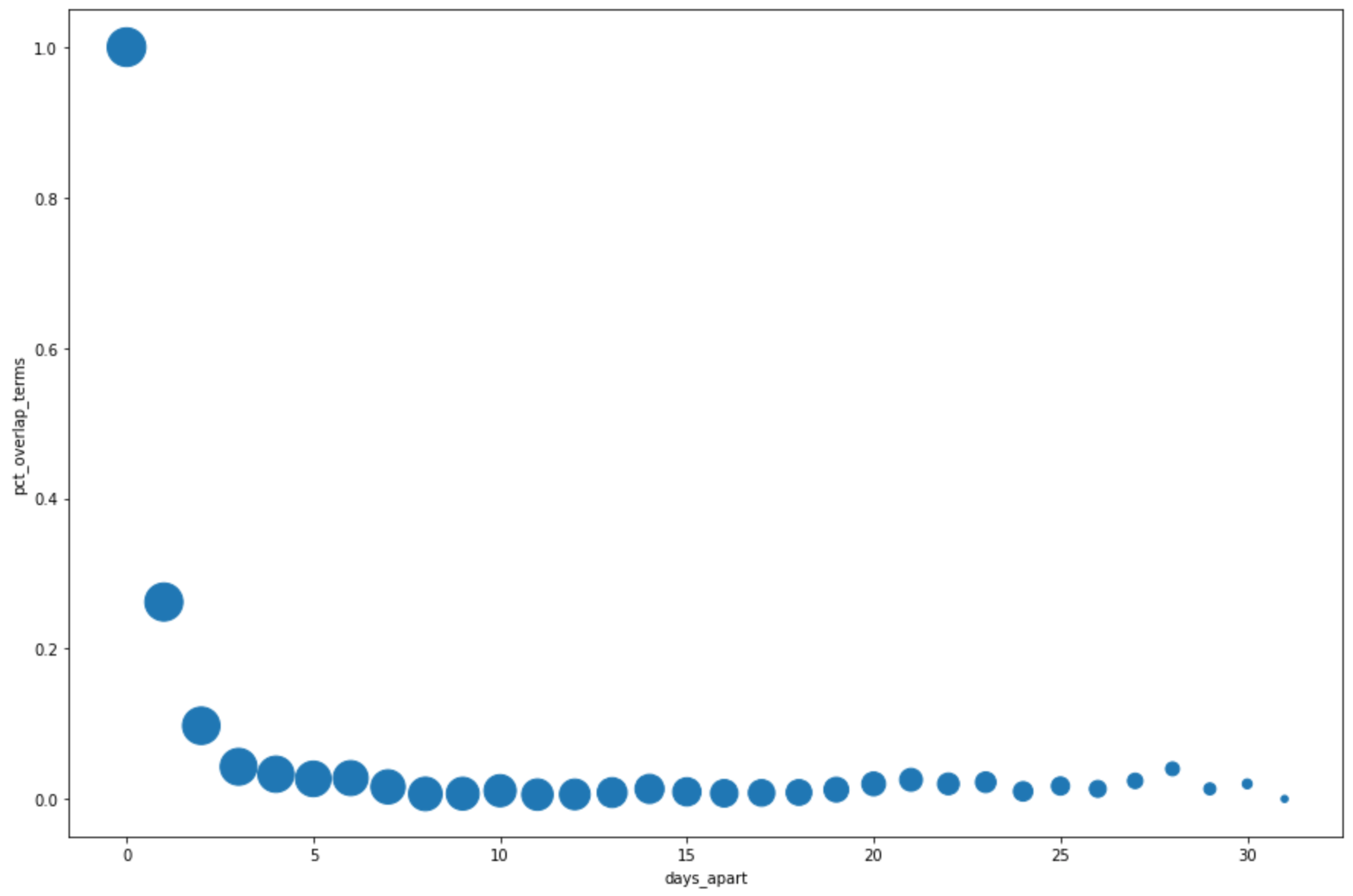
Di sel berikutnya, masukkan kode berikut untuk menggunakan metode
DataFrame.plot()pandas guna membuat diagram sebar yang memvisualisasikan hasil dari kueri untuk persentase tumpang tindih dengan istilah penelusuran teratas dari beberapa hari sebelumnya:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Klik Run cell.
Outputnya serupa dengan yang berikut ini: Ukuran setiap titik mencerminkan jumlah pasangan tanggal yang berjarak beberapa hari dalam data. Misalnya, ada lebih banyak pasangan yang berjarak 1 hari daripada yang berjarak 30 hari karena istilah penelusuran teratas muncul setiap hari selama sekitar satu bulan.
Untuk mengetahui informasi selengkapnya tentang visualisasi data, lihat dokumentasi pandas.
Menggunakan magic %bigquery_stats untuk mendapatkan statistik dan visualisasi untuk semua kolom tabel
Di bagian ini, Anda akan menggunakan pintasan notebook guna mendapatkan ringkasan statistik dan visualisasi untuk semua kolom tabel BigQuery.
Library klien BigQuery menyediakan perintah magic,
%bigquery_stats, yang dapat Anda panggil dengan nama tabel tertentu untuk memberikan
ringkasan tabel dan statistik mendetail dari setiap kolom
tabel.
Di sel berikutnya, masukkan kode berikut untuk menjalankan analisis tersebut di tabel
top_termsAS:%bigquery_stats bigquery-public-data.google_trends.top_termsKlik Run cell.
Setelah berjalan selama beberapa waktu, gambar akan muncul dengan berbagai statistik untuk masing-masing dari 7 variabel dalam tabel
top_terms. Gambar berikut menunjukkan bagian dari beberapa contoh output: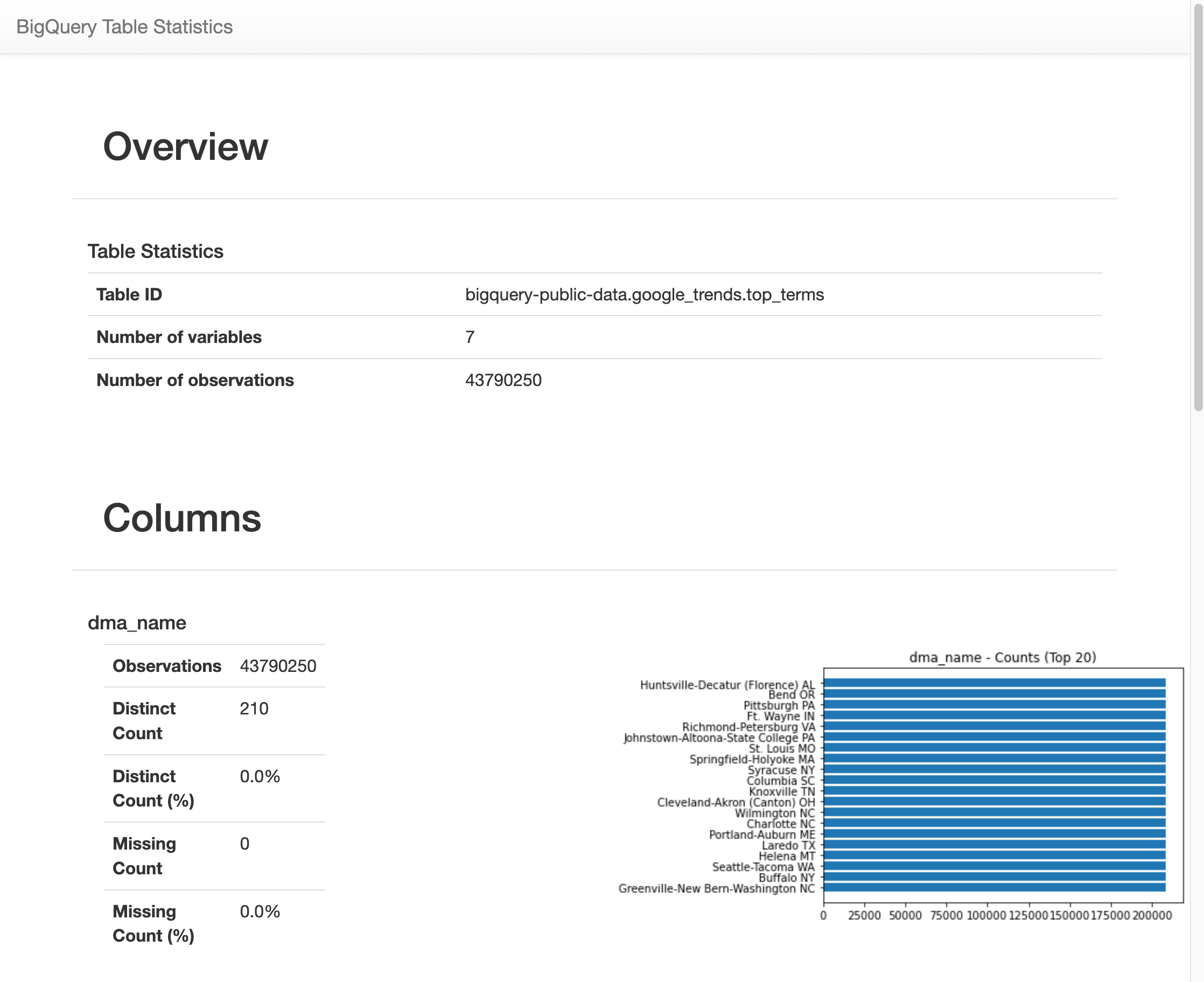
Melihat histori kueri dan menggunakan kembali kueri
Untuk melihat histori kueri Anda sebagai tab di JupyterLab, lakukan langkah-langkah berikut:
Di menu navigasi JupyterLab, klik
BigQuery di Notebooks untuk membuka panel BigQuery.Di panel BigQuery, scroll ke bawah, lalu klik Query history.
Daftar kueri akan terbuka di tab baru, tempat Anda dapat melakukan tugas seperti berikut:
- Untuk melihat detail kueri seperti ID pekerjaannya, kapan kueri dijalankan, dan berapa lama waktu yang diperlukan, klik kueri tersebut.
- Untuk merevisi kueri, menjalankannya lagi, atau menyalinnya ke dalam notebook untuk digunakan di lain waktu, klik Open query in editor.
Menyimpan dan mendownload notebook
Di bagian ini, Anda akan menyimpan notebook dan mendownloadnya jika ingin menggunakannya lagi di masa mendatang setelah membersihkan resource yang digunakan dalam tutorial ini.
- Pilih File > Save Notebook.
- Pilih File > Download untuk mendownload salinan lokal notebook Anda sebagai file IPYNB di komputer.
Pembersihan
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project Google Cloud yang Anda buat untuk tutorial ini.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Guna mempelajari lebih lanjut cara menulis kueri untuk BigQuery, baca Menjalankan tugas kueri batch dan interaktif.
- Untuk mempelajari Vertex AI Workbench lebih lanjut, lihat Vertex AI Workbench.