Neste tutorial, descrevemos como explorar e visualizar dados usando a biblioteca de cliente do BigQuery para Python e pandas em um notebook do Jupyter gerenciado no Vertex AI Workbench. As ferramentas de visualização de dados podem ajudar você a analisar os dados do BigQuery de maneira interativa, além de identificar tendências e comunicar insights dos dados. Neste tutorial, usamos os dados encontrados no conjunto de dados públicos do Google Trends para o BigQuery.
Objetivos
- Criar uma instância gerenciada do notebook do Jupyter usando o Vertex AI Workbench.
- Consultar dados do BigQuery usando comandos mágicos em notebooks
- Consultar e visualizar dados do BigQuery usando o Pandas e a biblioteca de cliente em Python do BigQuery.
Custos
É necessário pagar para usar o BigQuery. O primeiro 1 TB de dados de consulta processados por mês não tem custo algum. Para mais informações, consulte a página "Preços" do BigQuery.
O Vertex AI Workbench é um produto pago, e você gera custos de computação, armazenamento e gerenciamento ao usar instâncias do Vertex AI Workbench. Para mais informações, consulte a página de preços do Vertex AI Workbench.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
O BigQuery é ativado automaticamente para novos projetos.
Ative a API Notebooks.
Visão geral dos notebooks do Jupyter
Um notebook fornece um ambiente onde é possível criar e executar códigos. Um notebook é basicamente um artefato de origem, salvo como um arquivo IPYNB. Ele pode ter conteúdo de texto descritivo, blocos de código executáveis e saída renderizada como HTML interativo.
Estruturalmente, um notebook é uma sequência de células. Uma célula é um bloco de texto de entrada que é avaliado para produzir resultados. As células podem ser de três tipos:
- Células de código: contêm códigos a serem avaliados. A saída ou os resultados do código executado são renderizados de acordo com o código executado.
- Células Markdown: contêm texto Markdown convertido em HTML para produzir cabeçalhos, listas e texto formatado.
- As células brutas podem ser usadas para renderizar diferentes formatos de código em HTML ou LaTeX.
A imagem a seguir mostra uma célula Markdown seguida por uma célula de código Python e, em seguida, pela saída:
Cada notebook aberto está associado a uma sessão em execução (também conhecida como kernel em Python). Esta sessão executa todo o código no notebook e gerencia o estado. O estado inclui as variáveis com os respectivos valores, funções e classes e todos os módulos do Python que você carregar.
No Google Cloud, é possível usar um ambiente baseado em notebook do Vertex AI Workbench para consultar e explorar dados, desenvolver e treinar um modelo e executar o código como parte de um pipeline. Neste tutorial, você vai criar uma instância de notebook gerenciado no Vertex AI Workbench e analisar os dados do BigQuery na interface do JupyterLab.
Criar uma instância de notebooks gerenciados
Nesta seção, você vai configurar uma instância do JupyterLab no Google Cloud para criar notebooks gerenciados.
No console do Google Cloud, acesse a página Workbench.
Clique em Novo notebook.
No campo Nome do notebook, insira um nome para sua instância.
Na lista Região, selecione uma região para sua instância.
Na seção Permissão, selecione uma opção para definir quais usuários podem acessar a instância de notebooks gerenciados:
- Conta de serviço: essa opção dá acesso a todos os usuários que têm acesso à conta de serviço do Compute Engine que você vincula ao ambiente de execução. Para especificar sua própria conta de serviço, desmarque a caixa de seleção Usar a conta de serviço padrão do Compute Engine e insira o endereço de e-mail da conta de serviço que você quer usar. Para mais informações sobre contas de serviço, consulte Tipos de contas de serviço.
- Apenas um usuário: essa opção dá acesso apenas a um usuário específico. No campo E-mail do usuário, insira o endereço de e-mail da conta de usuário que usará a instância de notebooks gerenciados.
Opcional: para modificar as configurações avançadas da instância, clique em Configurações avançadas. Para mais informações, consulte Criar uma instância usando configurações avançadas.
Clique em Criar.
Aguarde alguns minutos para que a instância seja criada. O Vertex AI Workbench inicia automaticamente a instância. Quando a instância estiver pronta para uso, o Vertex AI Workbench ativa um link Abrir JupyterLab.
Procurar recursos do BigQuery no JupyterLab
Nesta seção, você abre o JupyterLab e explora os recursos do BigQuery que estão disponíveis em uma instância de notebooks gerenciados.
Na linha da instância de notebooks gerenciados que você criou, clique em Abrir JupyterLab.
Caso seja solicitado, clique em Autenticar se concordar com os termos. Sua instância de notebooks gerenciados abre o JupyterLab em uma nova guia do navegador.
No menu de navegação do JupyterLab, clique em
 BigQuery em Notebooks.
BigQuery em Notebooks.O painel do BigQuery lista projetos e conjuntos de dados disponíveis, em que é possível realizar tarefas da seguinte maneira:
- Para ver a descrição de um conjunto de dados, clique duas vezes no nome dele.
- Para mostrar as tabelas, visualizações e modelos de um conjunto de dados, expanda o conjunto de dados.
- Para abrir uma descrição resumida como uma guia no JupyterLab, clique duas vezes em uma tabela, visualização ou modelo.
Observação: na descrição resumida de uma tabela, clique na guia Visualização para visualizar os dados de uma tabela. A imagem a seguir mostra uma visualização da tabela
international_top_termsencontrada no conjunto de dadosgoogle_trendsno projetobigquery-public-data: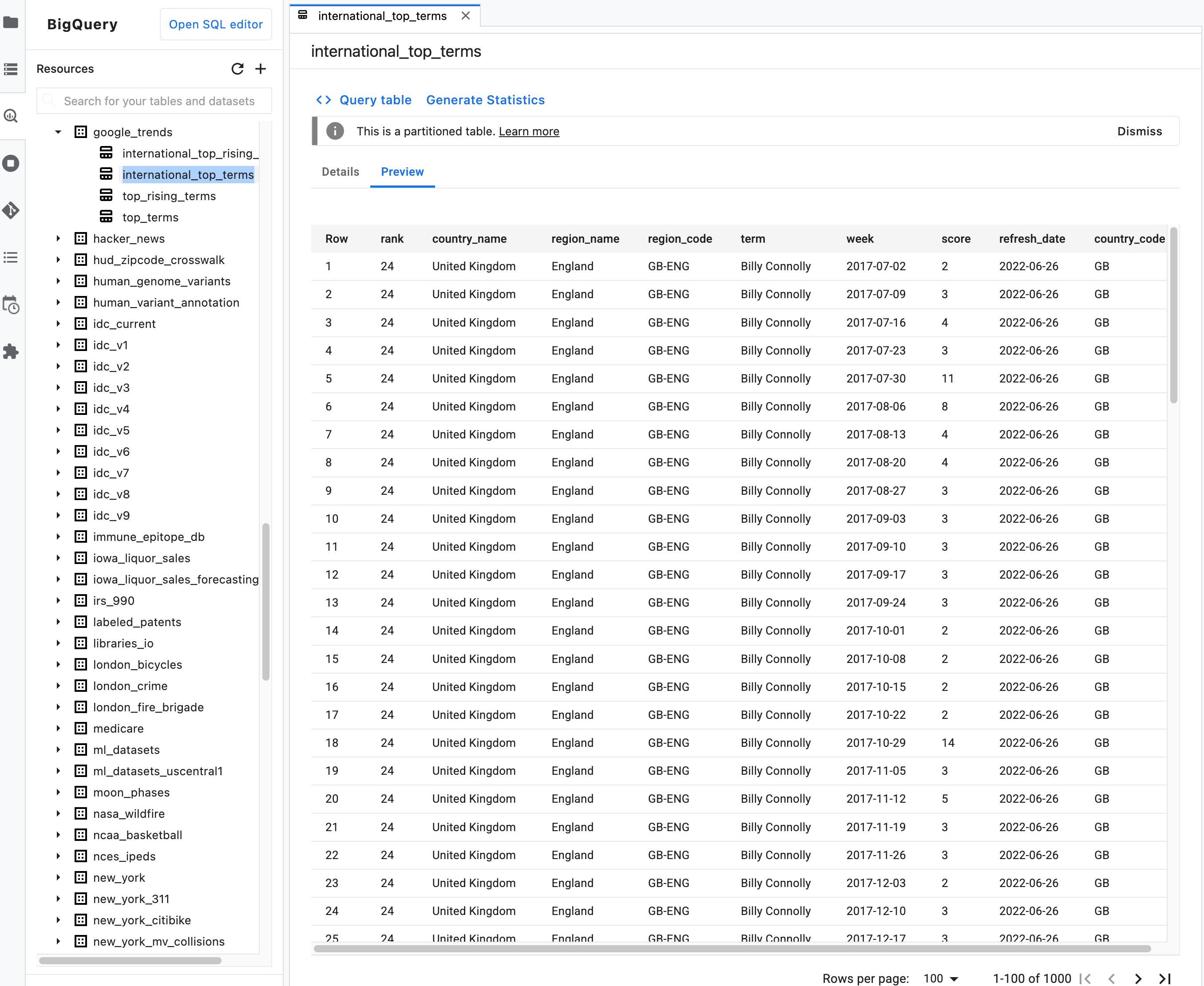
Consultar dados do notebook usando o comando mágico %%bigquery
Nesta seção, você escreverá o SQL diretamente nas células do notebook e lerá os dados do BigQuery no notebook do Python.
Os comandos mágicos que usam um caractere de porcentagem única ou dupla (% ou %%)
permitem usar sintaxe mínima para interagir com o BigQuery no
notebook. A biblioteca de cliente do BigQuery para Python é instalada automaticamente em uma instância de notebooks gerenciados. Em segundo plano, o comando mágico %%bigquery
usa a biblioteca de cliente do BigQuery para Python para executar a
consulta especificada, converter os resultados em um DataFrame do Pandas, salvá-los em
uma variável e exibir os resultados.
Observação: a partir da versão 1.26.0 do pacote google-cloud-bigquery do Python,
a API BigQuery Storage é usada por padrão para fazer o download dos resultados dos comandos mágicos %%bigquery.
Para abrir um arquivo de notebook, selecione File > New > Notebook.
Na caixa de diálogo Selecionar kernel, selecione Python (local) e clique em Selecionar.
O novo arquivo IPYNB será aberto.
Para ver o número de regiões por país no conjunto de dados
international_top_terms, insira a seguinte instrução:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Clique em Executar célula.
O resultado será assim:
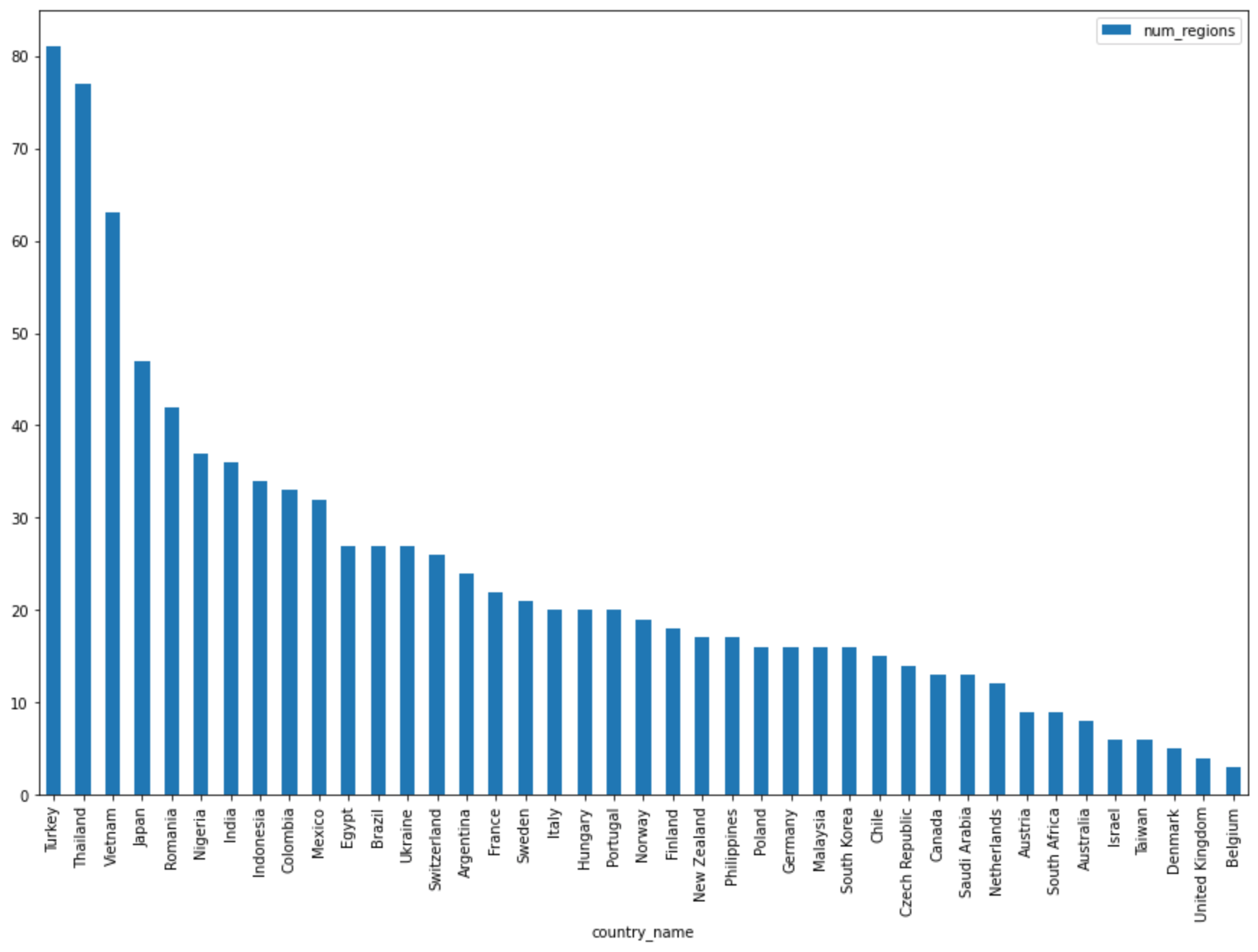
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Na próxima célula (abaixo da saída da célula anterior), insira o comando a seguir para executar a mesma consulta, mas desta vez salve os resultados em um novo DataFrame do Pandas chamado
regions_by_country. Para isso, use um argumento com o comando mágico%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Observação: para mais informações sobre os argumentos disponíveis para o comando
%%bigquery, consulte a documentação de comandos mágicos da biblioteca de cliente.Clique em Executar célula.
Na próxima célula, insira o comando a seguir para ver as primeiras linhas dos resultados da consulta que você acabou de ler:
regions_by_country.head()Clique em Executar célula.
O DataFrame
regions_by_countrydo pandas está pronto para ser plotado.
Consultar dados em um notebook usando a biblioteca de cliente do BigQuery
Nesta seção, você usará a biblioteca de cliente do BigQuery para Python diretamente para ler dados no notebook do Python.
A biblioteca de cliente oferece mais controle sobre suas consultas e permite usar configurações mais complexas para consultas e jobs. As integrações da biblioteca com o Pandas permitem combinar o poder do SQL declarativo com o código imperativo (Python) para ajudar a analisar, visualizar e transformar os dados.
Observação: é possível usar várias bibliotecas de visualização e de análise e conversão
de dados para Python, como numpy, pandas, matplotlib e muitos
outros. Várias dessas bibliotecas são criadas com base em um objeto DataFrame.
Na próxima célula, insira o seguinte código Python para importar a biblioteca de cliente do BigQuery para Python e inicializar um cliente:
from google.cloud import bigquery client = bigquery.Client()O cliente do BigQuery é usado para enviar e receber mensagens da API BigQuery.
Clique em Executar célula.
Na próxima célula, insira o código a seguir para recuperar a porcentagem de principais termos diários nos
top_termsdos EUA que se sobrepõem ao longo do tempo por números de dias. A ideia é analisar os principais termos de cada dia e ver qual porcentagem deles se sobrepõe aos principais termos do dia anterior, 2 dias antes, 3 dias antes e assim por diante (para todos pares de datas durante aproximadamente um mês).sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
O SQL usado é encapsulado em uma string Python e transmitido para o método
query()para executar uma consulta. O métodoto_dataframeaguarda a conclusão da consulta e faz o download dos resultados em um DataFrame de pandas usando a API BigQuery Storage.Clique em Executar célula.
As primeiras linhas dos resultados da consulta são exibidas abaixo da célula de código.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Para mais informações sobre o uso de bibliotecas de cliente do BigQuery, consulte o guia de início rápido Como usar bibliotecas de cliente.
Visualizar dados do BigQuery
Nesta seção, você usará os recursos de plotagem para visualizar os resultados das consultas executadas anteriormente no notebook do Jupyter.
Na próxima célula, insira o código a seguir para usar o método
DataFrame.plot()de pandas e criar um gráfico de barras que visualize os resultados da consulta que retorna o número de regiões por país:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Clique em Executar célula.
A gráfico é semelhante a:
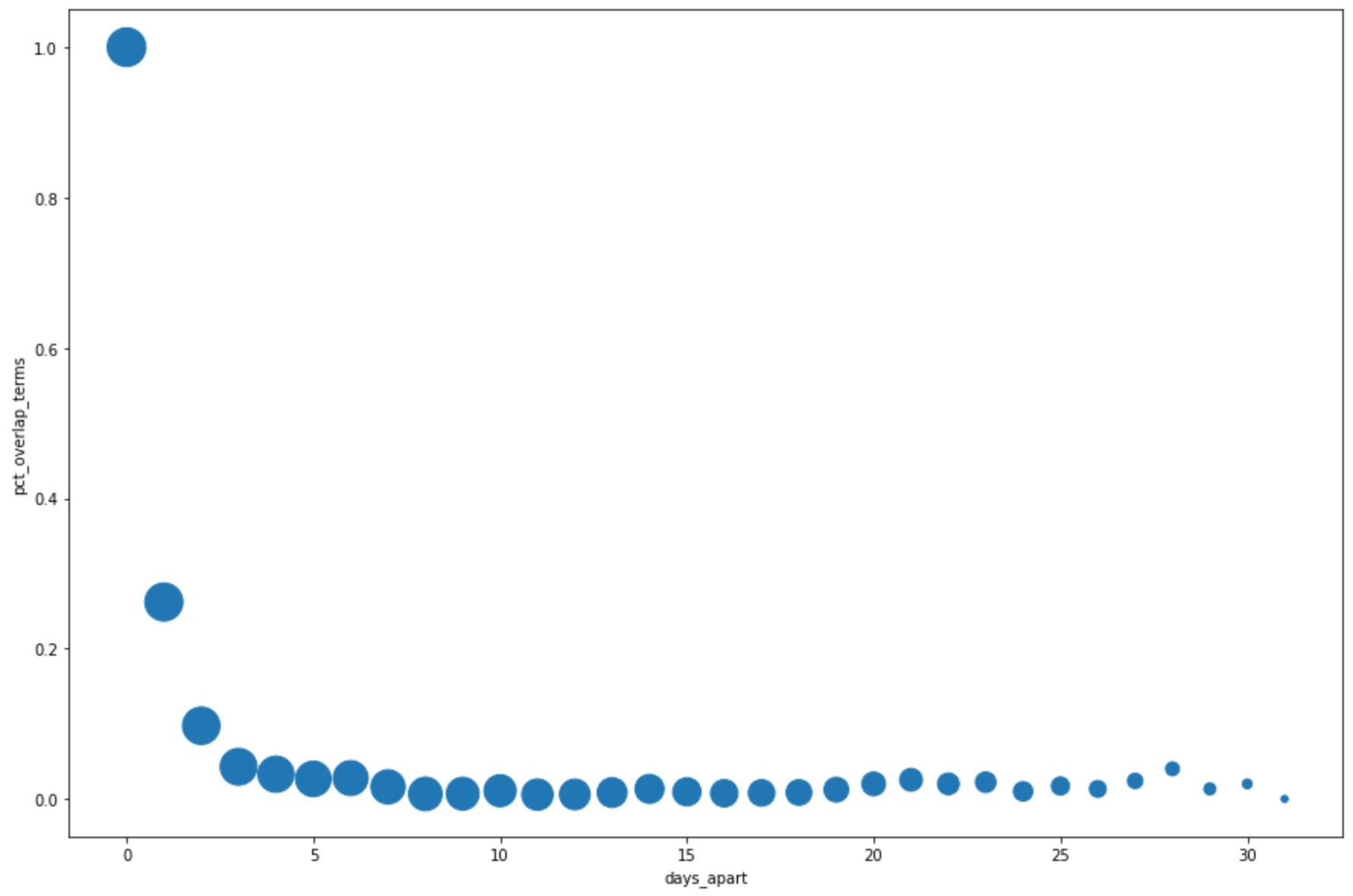
Na próxima célula, insira o código a seguir para usar o método
DataFrame.plot()do pandas e criar um gráfico de dispersão que visualize os resultados da consulta para a porcentagem de sobreposição nos principais termos de pesquisa por dias de intervalo:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Clique em Executar célula.
O gráfico é semelhante a: O tamanho de cada ponto reflete o número de pares de datas com quantos dias de intervalo entre os dados. Por exemplo, há mais pares com um dia de intervalo do que 30 dias de intervalo porque os principais termos de pesquisa aparecem diariamente em aproximadamente um mês.
Para mais informações sobre a visualização de dados, consulte a documentação do pandas.
Use o comando mágico %bigquery_stats para ver estatísticas e visualizações de todas as colunas da tabela.
Nesta seção, você usará um atalho do notebook para ver estatísticas e visualizações resumidas de todos os campos de uma tabela do BigQuery.
A biblioteca de cliente do BigQuery fornece um comando mágico,
%bigquery_stats, que pode ser chamado com um nome de tabela específico para fornecer uma
visão geral da tabela e estatísticas detalhadas em cada uma das colunas
da tabela.
Na próxima célula, insira o código a seguir para executar essa análise na tabela
top_termsdos EUA:%bigquery_stats bigquery-public-data.google_trends.top_termsClique em Executar célula.
Depois de ser executada por algum tempo, uma imagem aparece com várias estatísticas em cada uma das sete variáveis na tabela
top_terms. A imagem a seguir mostra parte de alguns exemplos de saída: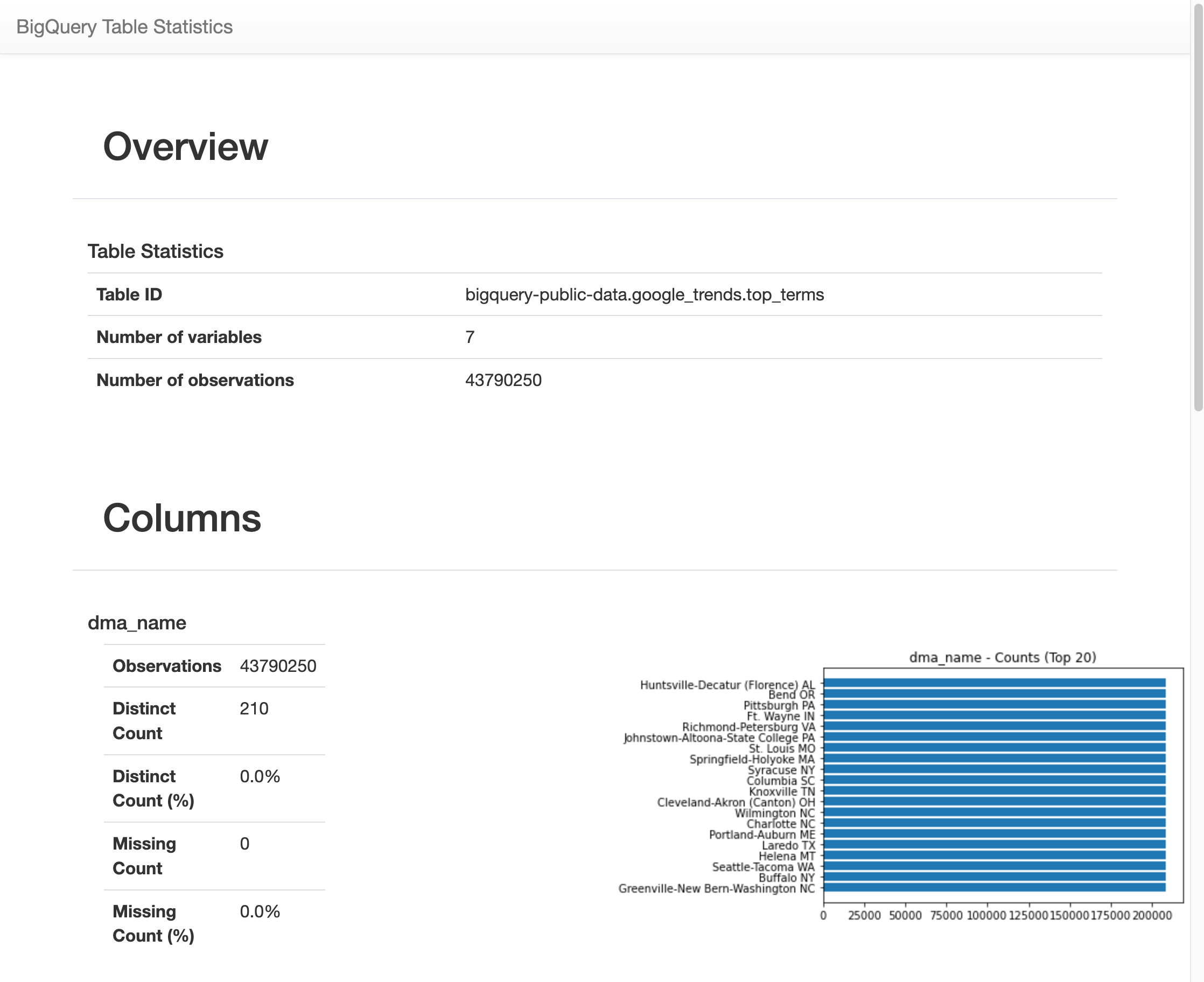
Ver seu histórico de consultas e reutilizar consultas
Para ver seu histórico de consultas como uma guia no JupyterLab, siga estas etapas:
No menu de navegação do JupyterLab, clique em
BigQuery em Notebooks para abrir o
painel BigQuery.No painel do BigQuery, role para baixo e clique em Histórico de consultas.
Uma lista de consultas será aberta em uma nova guia com as seguintes tarefas:
- Para ver os detalhes de uma consulta, como o ID do job, quando a consulta foi executada e quanto tempo levou, clique na consulta.
- Para revisar a consulta, executá-la novamente ou copiá-la no notebook para uso futuro, clique em Abrir consulta no editor.
Salvar e fazer o download do notebook
Nesta seção, você vai salvar o notebook e fazer o download dele se quiser para uso futuro após limpar os recursos usados neste tutorial.
- Selecione Arquivo > Salvar notebook.
- Selecione Arquivo > Fazer download para salvar uma cópia local do notebook como um arquivo IPYNB no seu computador.
Limpar
A maneira mais fácil de eliminar o faturamento é excluir o projeto do Google Cloud que você criou para o tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para saber mais sobre como criar consultas para o BigQuery, consulte Como executar jobs de consulta interativos e em lote.
- Para saber mais sobre o Vertex AI Workbench, consulte Vertex AI Workbench.