Faça a gestão de tabelas agrupadas
Este documento descreve como obter informações sobre o acesso a tabelas agrupadas no BigQuery e controlá-lo.
Para mais informações, consulte o seguinte:
- Para saber mais sobre a compatibilidade com tabelas agrupadas no BigQuery, consulte o artigo Introdução às tabelas agrupadas.
- Para saber como criar tabelas agrupadas, consulte o artigo Criar tabelas agrupadas.
Antes de começar
Para obter informações sobre tabelas, tem de ter a autorização bigquery.tables.get. As seguintes funções do IAM predefinidas incluem autorizações bigquery.tables.get:
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
Além disso, se um utilizador tiver a autorização bigquery.datasets.create, quando esse utilizador cria um conjunto de dados, é-lhe concedido acesso bigquery.dataOwner ao mesmo.
O acesso bigquery.dataOwner dá ao utilizador a capacidade de obter informações sobre tabelas num conjunto de dados.
Para mais informações acerca das funções e autorizações do IAM no BigQuery, consulte o artigo Funções e autorizações predefinidas.
Controle o acesso a tabelas agrupadas
Para configurar o acesso a tabelas e vistas, pode conceder uma função do IAM a uma entidade nos seguintes níveis, apresentados por ordem do intervalo de recursos permitidos (do maior para o menor):
- um nível elevado na Google Cloud hierarquia de recursos, como o nível do projeto, da pasta ou da organização
- ao nível do conjunto de dados
- Ao nível da tabela ou da vista
Também pode restringir o acesso aos dados nas tabelas através dos seguintes métodos:
O acesso com qualquer recurso protegido pela IAM é cumulativo. Por exemplo, se uma entidade não tiver acesso ao nível superior, como um projeto, pode conceder-lhe acesso ao nível do conjunto de dados. Em seguida, a entidade tem acesso às tabelas e às visualizações de propriedade no conjunto de dados. Da mesma forma, se a entidade não tiver acesso ao nível superior ou ao nível do conjunto de dados, pode conceder-lhe acesso ao nível da tabela ou da visualização.
A concessão de funções da IAM a um nível superior na Google Cloud hierarquia de recursos , como o nível do projeto, da pasta ou da organização, dá à entidade acesso a um conjunto vasto de recursos. Por exemplo, conceder uma função a uma entidade ao nível do projeto dá a essa entidade autorizações que se aplicam a todos os conjuntos de dados ao longo do projeto.
A concessão de uma função ao nível do conjunto de dados especifica as operações que uma entidade tem permissão para realizar em tabelas e visualizações de propriedade nesse conjunto de dados específico, mesmo que a entidade não tenha acesso a um nível superior. Para ver informações sobre a configuração dos controlos de acesso ao nível do conjunto de dados, consulte o artigo Controlar o acesso aos conjuntos de dados.
A atribuição de uma função ao nível da tabela ou da visualização de propriedade especifica as operações que uma entidade tem autorização para realizar em tabelas e visualizações de propriedade específicas, mesmo que a entidade não tenha acesso a um nível superior. Para obter informações sobre a configuração de controlos de acesso ao nível da tabela, consulte o artigo Controlar o acesso a tabelas e vistas.
Também pode criar funções personalizadas do IAM. Se criar uma função personalizada, as autorizações que concede dependem das operações específicas que quer que a entidade possa realizar.
Não pode definir uma autorização "negar" em nenhum recurso protegido pelo IAM.
Para mais informações acerca das funções e autorizações, consulte o artigo Compreender as funções na documentação do IAM e as autorizações e funções do IAM do BigQuery.
Receba informações sobre tabelas agrupadas
Selecione uma das seguintes opções:
Consola
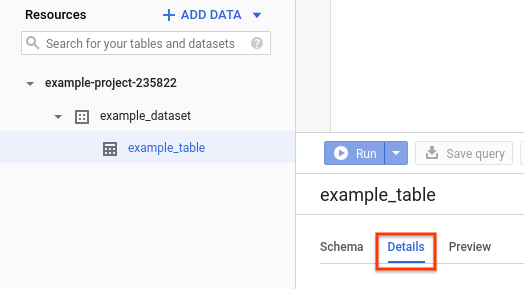
Na Google Cloud consola, aceda ao painel Recursos.
Clique no nome do conjunto de dados para o expandir e, de seguida, clique no nome da tabela que quer ver.
Clique em Detalhes.
São apresentados os detalhes da tabela, incluindo as colunas de agrupamento.
SQL
Para tabelas agrupadas, pode consultar a coluna CLUSTERING_ORDINAL_POSITION na vista INFORMATION_SCHEMA.COLUMNS para encontrar o desvio indexado a 1 da coluna nas colunas de agrupamento da tabela:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
Clique em Executar.
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
A posição ordinal da agrupagem é 1 para column1 e 2 para column2.
Estão disponíveis mais metadados de tabelas através das vistas TABLES, TABLE_OPTIONS,
COLUMNS e COLUMN_FIELD_PATH em INFORMATION_SCHEMA.
bq
Emita o comando bq show para apresentar todas as informações da tabela. Use a flag
--schema para apresentar apenas informações do esquema da tabela. A flag --format
pode ser usada para controlar a saída.
Se estiver a receber informações sobre uma tabela num projeto diferente do seu projeto predefinido, adicione o ID do projeto ao conjunto de dados no seguinte formato: project_id:dataset.
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
Substitua o seguinte:
PROJECT_ID: o ID do seu projetoDATASET: o nome do conjunto de dadosTABLE: o nome da tabela
Exemplos:
Introduza o seguinte comando para apresentar todas as informações sobre
myclusteredtable em mydataset. mydataset no seu projeto predefinido.
bq show --format=prettyjson mydataset.myclusteredtable
O resultado deve ter o seguinte aspeto:
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
Chame o método bigquery.tables.get
e forneça todos os parâmetros relevantes.
Liste tabelas agrupadas num conjunto de dados
As autorizações necessárias para listar tabelas agrupadas e os passos para as listar são os mesmos que para as tabelas padrão. Para mais informações, consulte o artigo Listar tabelas num conjunto de dados.
Modifique a especificação de agrupamento
Pode alterar ou remover as especificações de clustering de uma tabela, ou alterar o conjunto de colunas agrupadas numa tabela agrupada. Este método de atualização do conjunto de colunas de agrupamento é útil para tabelas que usam inserções de streaming contínuo, porque essas tabelas não podem ser facilmente trocadas por outros métodos.
Siga estes passos para aplicar uma nova especificação de agrupamento a tabelas não particionadas ou particionadas.
Na ferramenta bq, atualize a especificação de clustering da sua tabela para corresponder ao novo clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Substitua o seguinte:
CLUSTER_COLUMN: a coluna na qual está a fazer o agrupamento, por exemplo,mycolumnDATASET: o nome do conjunto de dados que contém a tabela, por exemplo,mydatasetORIGINAL_TABLE: o nome da tabela original, por exemplo,mytable
Também pode chamar o método da API
tables.updateoutables.patchpara modificar a especificação de agrupamento.Para agrupar todas as linhas de acordo com a nova especificação de clustering, execute a seguinte declaração
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
O que se segue?
- Para obter informações sobre como consultar tabelas agrupadas, consulte o artigo Consultar tabelas agrupadas.
- Para uma vista geral da compatibilidade com tabelas particionadas no BigQuery, consulte o artigo Introdução às tabelas particionadas.
- Para saber como criar tabelas particionadas, consulte o artigo Crie tabelas particionadas.