Générer du texte à l'aide d'un modèle text-bison et de la fonction ML.GENERATE_TEXT
Ce tutoriel explique comment créer un modèle distant basé sur le grand modèle de langage text-bison@002 et l'utiliser avec la fonction ML.GENERATE_TEXT pour effectuer plusieurs tâches de génération de texte. Ce tutoriel utilise la table publique bigquery-public-data.imdb.reviews.
Autorisations requises
- Pour créer l'ensemble de données, vous devez disposer de l'autorisation Identity and Access Management (IAM)
bigquery.datasets.create. Pour créer la ressource de connexion, vous devez disposer des autorisations IAM suivantes :
bigquery.connections.createbigquery.connections.get
Pour accorder des autorisations au compte de service de la connexion, vous devez disposer de l'autorisation suivante :
resourcemanager.projects.setIamPolicy
Pour créer le modèle, vous avez besoin des autorisations suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatabigquery.jobs.create
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- BigQuery ML: You incur costs for the data that you process in BigQuery.
- Vertex AI: You incur costs for calls to the Vertex AI service that's represented by the remote model.
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Pour en savoir plus sur les tarifs de BigQuery, consultez la page Tarifs de BigQuery dans la documentation BigQuery.
Pour en savoir plus sur les tarifs de Vertex AI, consultez la page Tarifs de Vertex AI.
Avant de commencer
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Connection, and Vertex AI APIs.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Google Cloud, accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialavec l'emplacement des données défini surUSet une description deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Au lieu d'utiliser l'option
--dataset, la commande utilise le raccourci-d. Si vous omettez-det--dataset, la commande crée un ensemble de données par défaut.Vérifiez que l'ensemble de données a été créé:
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Créer une connexion
Créez une connexion de ressource cloud et obtenez le compte de service de la connexion. Créez la connexion dans le même emplacement que l'ensemble de données que vous avez créé à l'étape précédente.
Sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur Ajouter des données.
La boîte de dialogue Ajouter des données s'ouvre.
Dans le volet Filtrer par, dans la section Type de source de données, sélectionnez Bases de données.
Vous pouvez également saisir
Vertex AIdans le champ Rechercher des sources de données.Dans la section Sources de données sélectionnées, cliquez sur Vertex AI.
Cliquez sur la fiche de solution Modèles Vertex AI: fédération BigQuery.
Dans la liste Type de connexion, sélectionnez Modèles distants Vertex AI, fonctions distantes et BigLake (ressource Cloud).
Dans le champ ID de connexion, saisissez un nom pour votre connexion.
Cliquez sur Créer une connexion.
Cliquez sur Accéder à la connexion.
Dans le volet Informations de connexion, copiez l'ID du compte de service à utiliser à l'étape suivante.
bq
Dans un environnement de ligne de commande, créez une connexion :
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
Le paramètre
--project_idremplace le projet par défaut.Remplacez les éléments suivants :
REGION: votre région de connexionPROJECT_ID: ID de votre projet Google CloudCONNECTION_ID: ID de votre connexion
Lorsque vous créez une ressource de connexion, BigQuery crée un compte de service système unique et l'associe à la connexion.
Dépannage : Si vous obtenez l'erreur de connexion suivante, mettez à jour le Google Cloud SDK :
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Récupérez et copiez l'ID du compte de service pour l'utiliser lors d'une prochaine étape :
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
Le résultat ressemble à ce qui suit :
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Terraform
Utilisez la ressource google_bigquery_connection.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
L'exemple suivant crée une connexion de ressources Cloud nommée my_cloud_resource_connection dans la région US:
Pour appliquer votre configuration Terraform dans un projet Google Cloud, suivez les procédures des sections suivantes.
Préparer Cloud Shell
- Lancez Cloud Shell.
-
Définissez le projet Google Cloud par défaut dans lequel vous souhaitez appliquer vos configurations Terraform.
Vous n'avez besoin d'exécuter cette commande qu'une seule fois par projet et vous pouvez l'exécuter dans n'importe quel répertoire.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Les variables d'environnement sont remplacées si vous définissez des valeurs explicites dans le fichier de configuration Terraform.
Préparer le répertoire
Chaque fichier de configuration Terraform doit avoir son propre répertoire (également appelé module racine).
-
Dans Cloud Shell, créez un répertoire et un nouveau fichier dans ce répertoire. Le nom du fichier doit comporter l'extension
.tf, par exemplemain.tf. Dans ce tutoriel, le fichier est appelémain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si vous suivez un tutoriel, vous pouvez copier l'exemple de code dans chaque section ou étape.
Copiez l'exemple de code dans le fichier
main.tfque vous venez de créer.Vous pouvez également copier le code depuis GitHub. Cela est recommandé lorsque l'extrait Terraform fait partie d'une solution de bout en bout.
- Examinez et modifiez les exemples de paramètres à appliquer à votre environnement.
- Enregistrez les modifications.
-
Initialisez Terraform. Cette opération n'est à effectuer qu'une seule fois par répertoire.
terraform init
Vous pouvez également utiliser la dernière version du fournisseur Google en incluant l'option
-upgrade:terraform init -upgrade
Appliquer les modifications
-
Examinez la configuration et vérifiez que les ressources que Terraform va créer ou mettre à jour correspondent à vos attentes :
terraform plan
Corrigez les modifications de la configuration si nécessaire.
-
Appliquez la configuration Terraform en exécutant la commande suivante et en saisissant
yeslorsque vous y êtes invité :terraform apply
Attendez que Terraform affiche le message "Apply completed!" (Application terminée).
- Ouvrez votre projet Google Cloud pour afficher les résultats. Dans la console Google Cloud, accédez à vos ressources dans l'interface utilisateur pour vous assurer que Terraform les a créées ou mises à jour.
Accorder des autorisations au compte de service de la connexion
Attribuez le rôle d'utilisateur Vertex AI au compte de service de la connexion. Vous devez accorder ce rôle dans le projet que vous avez créé ou sélectionné dans la section Avant de commencer. L'attribution du rôle dans un autre projet génère l'erreur bqcx-1234567890-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com does not have the permission to access resource.
Pour accorder le rôle, procédez comme suit :
Accédez à la page IAM et administration.
Cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez l'ID du compte de service que vous avez copié précédemment.
Dans le champ Sélectionner un rôle, sélectionnez Vertex AI, puis le rôle Utilisateur Vertex AI.
Cliquez sur Enregistrer.
Créer le modèle distant
Créez un modèle distant représentant un grand modèle de langage (LLM) hébergé sur Vertex AI :
SQL
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, exécutez l'instruction suivante :
CREATE OR REPLACE MODEL `bqml_tutorial.llm_model` REMOTE WITH CONNECTION `LOCATION.CONNECTION_ID` OPTIONS (ENDPOINT = 'text-bison@002');
Remplacez les éléments suivants :
LOCATION: emplacement de la connexionCONNECTION_ID: ID de votre connexion BigQuery.Lorsque vous affichez les détails de la connexion dans la console Google Cloud, il s'agit de la valeur de la dernière section de l'ID de connexion complet affiché dans ID de connexion (par exemple,
projects/myproject/locations/connection_location/connections/myconnection).
L'exécution de la requête prend plusieurs secondes, après quoi le modèle
llm_modelapparaît dans l'ensemble de donnéesbqml_tutorialdans le volet Explorateur. Étant donné que la requête utilise une instructionCREATE MODELpour créer un modèle, il n'y a aucun résultat de requête.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'ADC pour un environnement de développement local.
Effectuer une extraction de mots clés
Effectuez une extraction de mots clés sur des avis de films IMDB à l'aide du modèle distant et de la fonction ML.GENERATE_TEXT :
SQL
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante pour effectuer l'extraction de mots clés sur cinq avis de films :
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
Le résultat ressemble à ce qui suit, les colonnes non générées étant omises pour plus de clarté :
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " Keywords:\n- British Airways\n- | {"blocked":false,"categories": | | Extract the key words from | | | acting\n- story\n- kid\n- switch off" | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | | "Finance","Health","Insult", | | see this on the British | | | | "Profanity","Religion & Belief", | | Airways plane. It was | | | | "Sexual","Toxic"] | | terribly bad acting and | | | | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " - Family movie\n- ITV station\n- THE | {"blocked":false,"categories": | | Extract the key words from | | | REAL HOWARD SPITZ\n- Roald Dahl\n- | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | DOCTOR WHO\n- Pulp fiction\n- Child | "Health","Illicit Drugs","Insult", | | a family movie that was | | | abuse\n- KINDERGARTEN COP\n- PC\n- | "Legal","Profanity","Public Safety", | | broadcast on my local | | | Children's author\n- Vadim Jean\n- | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | Haphazard\n- Kelsey Grammar\n- | "safetyRatings":[{"category": | | couple of nights ago. | | | Dead pan\n- Ridiculous camera angles" | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+Les résultats incluent les colonnes suivantes :
generated_text: texte généré.safety_attributes: attributs de sécurité et informations indiquant si le contenu est bloqué en raison de l'une des catégories bloquantes. Pour en savoir plus sur les attributs de sécurité, consultez API PaLM de Vertex AI.ml_generate_text_status: état de réponse d'API pour la ligne correspondante. Si l'opération a abouti, cette valeur est vide.prompt: requête utilisée pour l'analyse des sentiments.- Toutes les colonnes de la table
bigquery-public-data.imdb.reviews.
Facultatif : Au lieu d'analyser manuellement le fichier JSON renvoyé par la fonction comme vous l'avez fait à l'étape précédente, utilisez l'argument
flatten_json_outputpour renvoyer le texte généré et les attributs de sécurité dans des colonnes distinctes.Dans l'éditeur de requête, exécutez l'instruction suivante :
SELECT * FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens, TRUE AS flatten_json_output));
Le résultat ressemble à ce qui suit, les colonnes non générées étant omises pour plus de clarté :
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | ml_generate_text_llm_result | ml_generate_text_rai_result | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | Keywords: | {"blocked":false,"categories": | | Extract the key words from | | | - British Airways | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | - acting | "Finance","Health","Insult", | | see this on the British | | | - story | "Profanity","Religion & Belief", | | Airways plane. It was | | | - kid | "Sexual","Toxic"] | | terribly bad acting and | | | - switch off | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | - Family movie | {"blocked":false,"categories": | | Extract the key words from | | | - ITV station | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | - THE REAL HOWARD SPITZ | "Health","Illicit Drugs","Insult", | | a family movie that was | | | - Roald Dahl | "Legal","Profanity","Public Safety", | | broadcast on my local | | | - DOCTOR WHO | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | - Pulp Fiction | "safetyRatings":[{"category": | | couple of nights ago. | | | - ... | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+Les résultats incluent les colonnes suivantes :
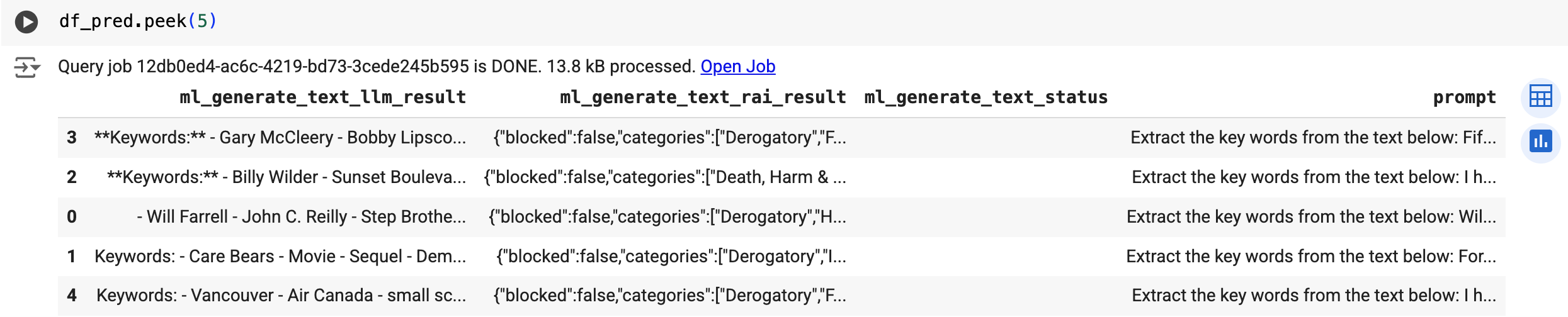
ml_generate_text_llm_result: texte généré.ml_generate_text_rai_result: attributs de sécurité et informations indiquant si le contenu est bloqué en raison de l'une des catégories bloquantes. Pour en savoir plus sur les attributs de sécurité, consultez API PaLM de Vertex AI.ml_generate_text_status: état de réponse d'API pour la ligne correspondante. Si l'opération a abouti, cette valeur est vide.prompt: requête utilisée pour l'extraction de mots clés.- Toutes les colonnes de la table
bigquery-public-data.imdb.reviews.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'ADC pour un environnement de développement local.
Utilisez la fonction predict pour exécuter le modèle distant :
Le résultat ressemble à ce qui suit :
Effectuer une analyse des sentiments
Effectuez une analyse des sentiments sur des avis de films IMDB à l'aide du modèle distant et de la fonction ML.GENERATE_TEXT :
SQL
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, exécutez l'instruction suivante pour effectuer une analyse des sentiments sur cinq avis de films :
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT( 'perform sentiment analysis on the following text, return one the following categories: positive, negative: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
Le résultat ressemble à ce qui suit, les colonnes non générées étant omises pour plus de clarté :
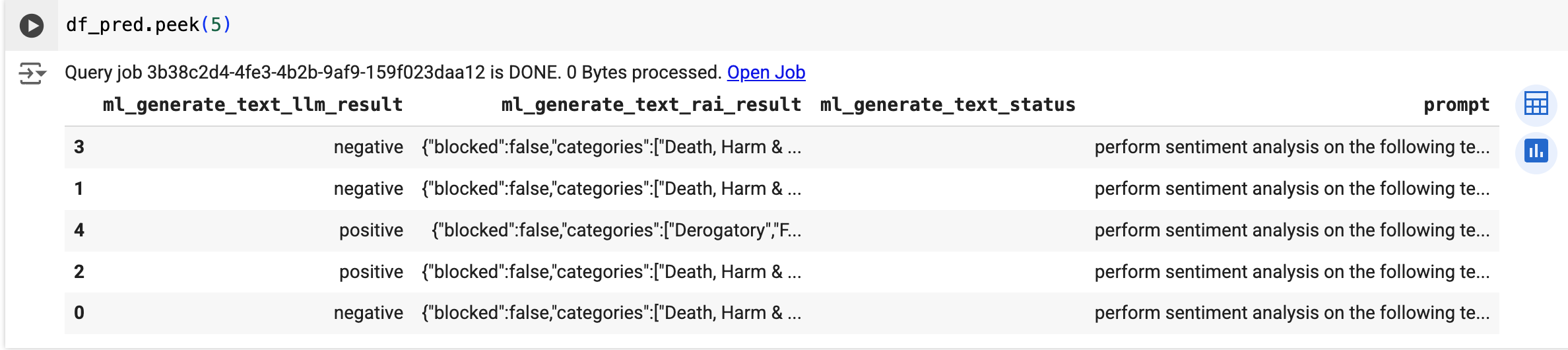
+----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Finance","Health","Insult", | | return one the following | | | | "Profanity","Religion & Belief", | | categories: positive, | | | | "Sexual","Toxic"] | | negative: I had to see | | | | "safetyRatings":[{"category": | | this on the British | | | | "Dangerous Content","probabilityScore"... | | Airways plane. It was... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Health","Illicit Drugs","Insult", | | return one the following | | | | "Legal","Profanity","Public Safety", | | categories: positive, | | | | "Sexual","Toxic","Violent"], | | negative: This is a family | | | | "safetyRatings":[{"category": | | movie that was broadcast | | | | "Dangerous Content","probabilityScore"... | | on my local ITV station... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+Les résultats incluent les mêmes colonnes que celles décrites dans la section Effectuer une extraction de mots clés.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'ADC pour un environnement de développement local.
Utilisez la fonction predict pour exécuter le modèle distant :
Le résultat ressemble à ce qui suit :
Effectuer un nettoyage
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.