Este tutorial mostra como associar uma tabela ou uma vista do BigQuery para ler e escrever dados a partir de um bloco de notas do Databricks. Os passos são descritos através da Google Cloud consola e dos espaços de trabalho do Databricks.
Também pode realizar estes passos através das ferramentas de linha de comandos gcloud e databricks, embora essas orientações estejam fora do âmbito deste tutorial.
O Databricks on Google Cloud é um ambiente do Databricks alojado no Google Cloud, executado no Google Kubernetes Engine (GKE) e que oferece integração incorporada com o BigQuery e outras tecnologias Google Cloud . Se for a primeira vez que usa o Databricks, veja o vídeo Introdução à plataforma de dados unificada do Databricks para uma vista geral da plataforma lakehouse do Databricks.
Objetivos
- Configure Google Cloud para estabelecer ligação ao Databricks.
- Implemente o Databricks no Google Cloud.
- Consultar o BigQuery a partir do Databricks.
Custos
Este tutorial usa componentes faturáveis da Google Cloud consola, incluindo o BigQuery e o GKE. Aplicam-se os preços do BigQuery e os preços do GKE. Para obter informações sobre os custos associados a uma conta do Databricks em execução no Google Cloud, consulte a secção Configure a sua conta e crie um espaço de trabalho na documentação do Databricks.
Antes de começar
Antes de associar o Databricks ao BigQuery, conclua os seguintes passos:
- Ative a API BigQuery Storage.
- Crie uma conta de serviço para o Databricks.
- Crie um contentor do Cloud Storage para armazenamento temporário.
Ative a API BigQuery Storage
A API BigQuery Storage está ativada por predefinição para todos os novos projetos onde o BigQuery é usado. Para projetos existentes que não tenham a API ativada, siga estas instruções:
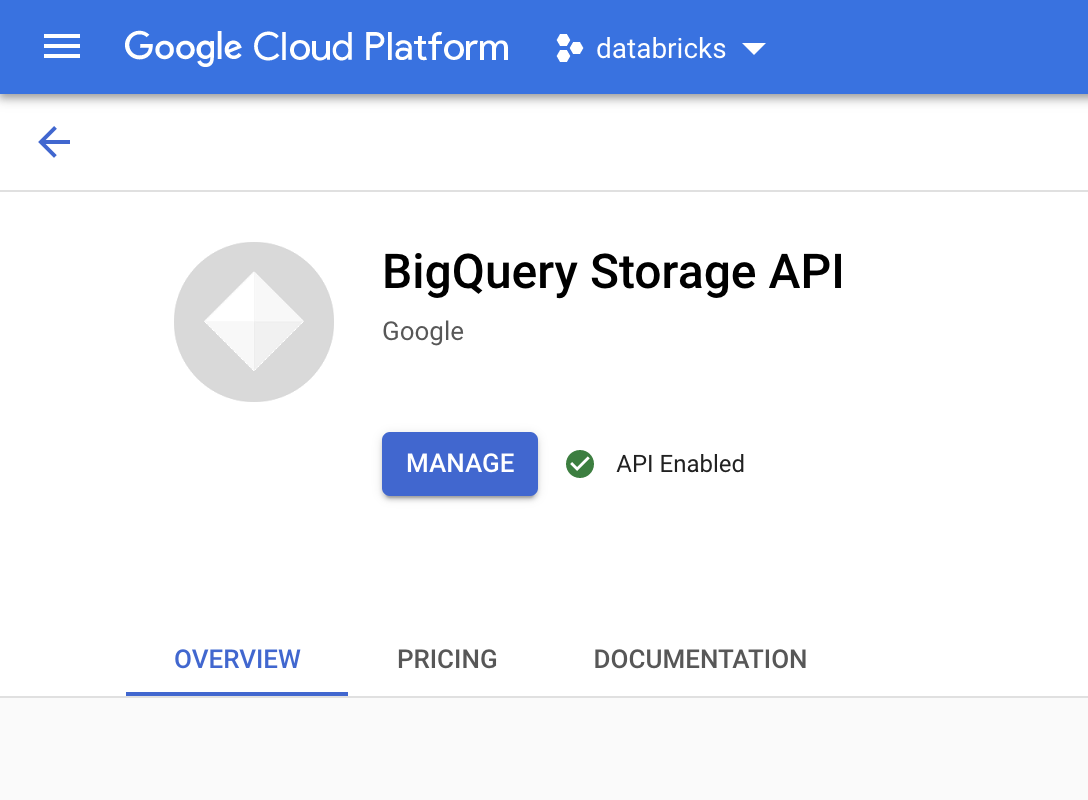
Na Google Cloud consola, aceda à página da API BigQuery Storage.
Confirme que a API BigQuery Storage está ativada.
Crie uma conta de serviço para o Databricks
Em seguida, crie uma conta de serviço de gestão de identidade e de acesso (IAM) para permitir que um cluster do Databricks execute consultas no BigQuery. Recomendamos que conceda a esta conta de serviço o mínimo de privilégios necessários para realizar as respetivas tarefas. Consulte o artigo Funções e autorizações do BigQuery.
Na Google Cloud consola, aceda à página Contas de serviço.
Clique em Criar conta de serviço, atribua um nome à conta de serviço
databricks-bigquery, introduza uma breve descrição, comoDatabricks tutorial service account, e, de seguida, clique em Criar e continuar.Em Conceda a esta conta de serviço acesso ao projeto, especifique as funções da conta de serviço. Para conceder à conta de serviço autorização para ler dados com o espaço de trabalho do Databricks e a tabela do BigQuery no mesmo projeto, especificamente sem fazer referência a uma vista materializada, conceda as seguintes funções:
- Utilizador de sessão de leitura do BigQuery
- Visualizador de dados do BigQuery
Para conceder autorização para escrever dados, atribua as seguintes funções:
- Utilizador de tarefas do BigQuery
- Editor de dados do BigQuery
Registe o endereço de email da sua nova conta de serviço para referência nos passos futuros.
Clique em Concluído.
Crie um contentor do Cloud Storage
Para escrever no BigQuery, o cluster do Databricks precisa de acesso a um contentor do Cloud Storage para armazenar em buffer os dados escritos.
Na Google Cloud consola, aceda ao navegador do Cloud Storage.
Clique em Criar contentor para abrir a caixa de diálogo Criar um contentor.
Especifique um nome para o contentor usado para escrever dados no BigQuery. O nome do contentor tem de ser um nome exclusivo a nível global. Se especificar um nome de contentor que já existe, o Cloud Storage responde com uma mensagem de erro. Se isto ocorrer, especifique um nome diferente para o seu contentor.
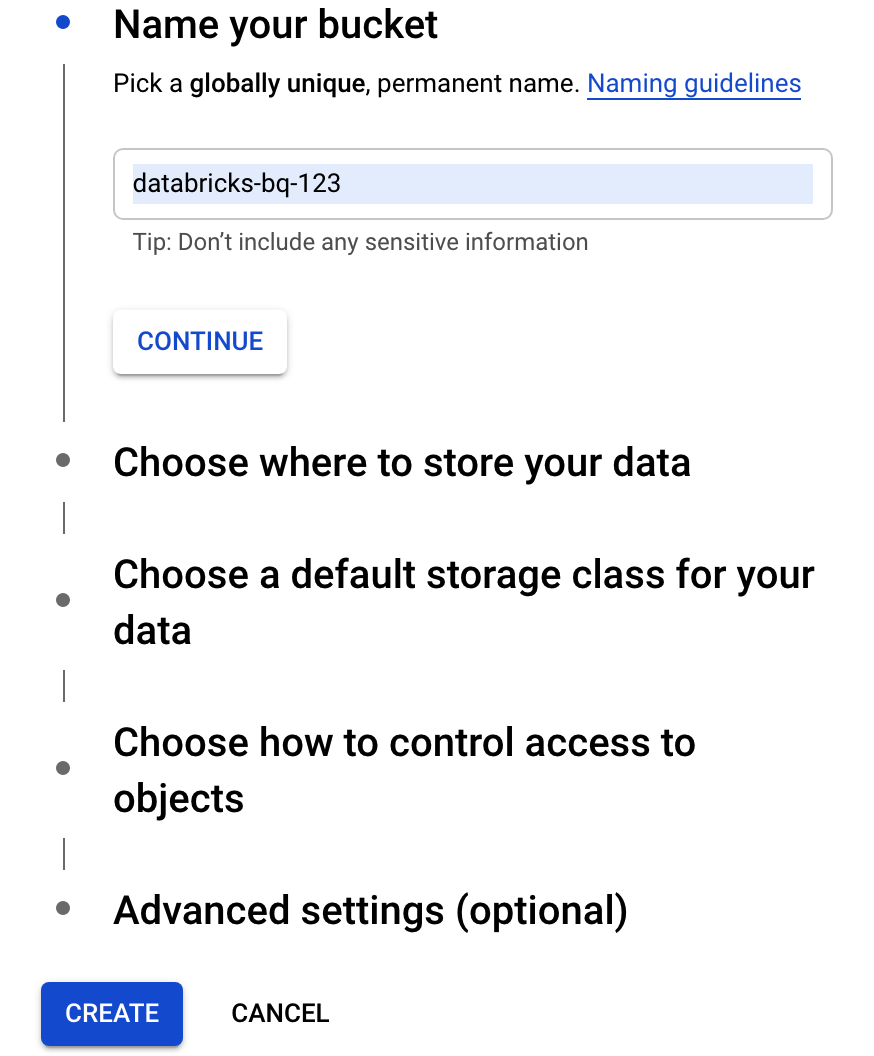
Para este tutorial, use as predefinições para a localização de armazenamento, classe de armazenamento, controlo de acesso e definições avançadas.
Clique em Criar para criar o contentor do Cloud Storage.
Clique em Autorizações, clique em Adicionar e, de seguida, especifique o endereço de email da conta de serviço que criou para o acesso ao Databricks na página Contas de serviço.
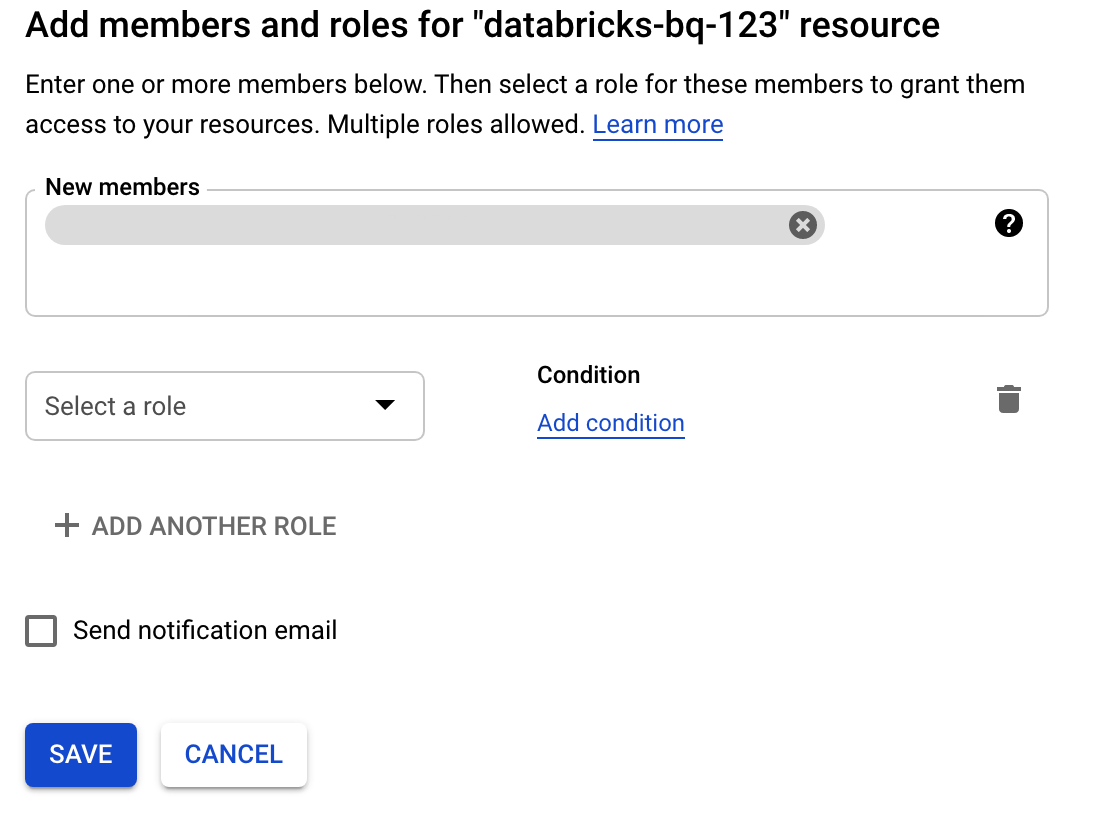
Clique em Selecionar uma função e adicione a função Administrador de armazenamento.
Clique em Guardar.
Implemente o Databricks no Google Cloud
Conclua os passos seguintes para se preparar para implementar o Databricks no Google Cloud.
- Para configurar a sua conta do Databricks, siga as instruções na documentação do Databricks, Configure a sua conta do Google Cloud Databricks.
- Após o registo, saiba como gerir a sua conta do Databricks.
Crie um espaço de trabalho, um cluster e um notebook do Databricks
Os passos seguintes descrevem como criar um espaço de trabalho do Databricks, um cluster e um bloco de notas do Python para escrever código para aceder ao BigQuery.
Confirme os pré-requisitos do Databricks.
Crie o seu primeiro espaço de trabalho. Na consola da conta do Databricks, clique em Criar espaço de trabalho.
Especifique
gcp-bqpara o Nome do espaço de trabalho e selecione a sua Região.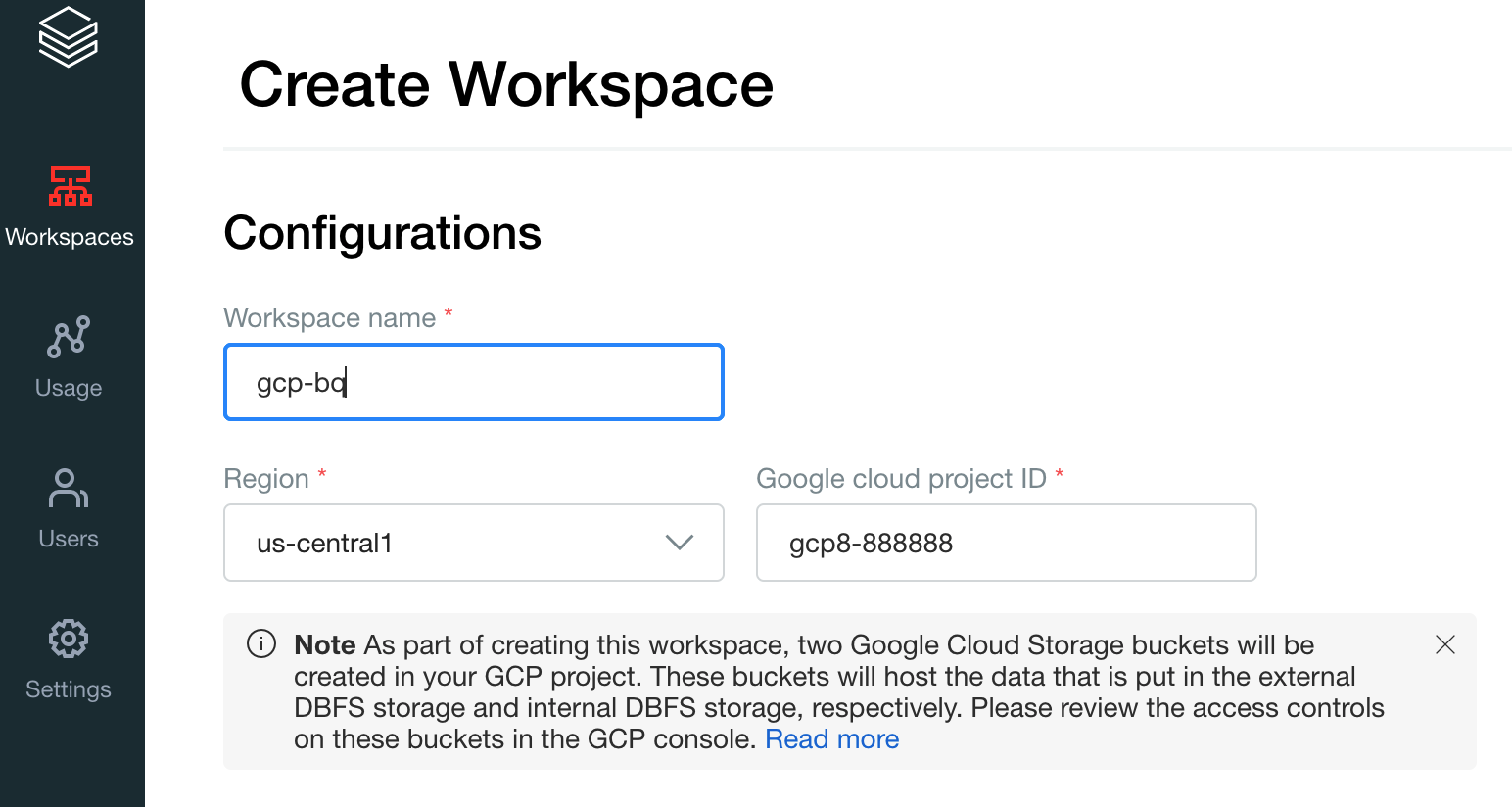
Para determinar o Google Cloud ID do projeto, aceda à Google Cloud consola e, de seguida, copie o valor para o campo Google Cloud ID do projeto.
Clique em Guardar para criar o seu espaço de trabalho do Databricks.
Para criar um cluster do Databricks com o tempo de execução do Databricks 7.6 ou posterior, na barra de menu do lado esquerdo, selecione Clusters e, de seguida, clique em Create Cluster na parte superior.
Especifique o nome do cluster e o respetivo tamanho e, de seguida, clique em Opções avançadas e especifique os endereços de email da sua Google Cloudconta de serviço.
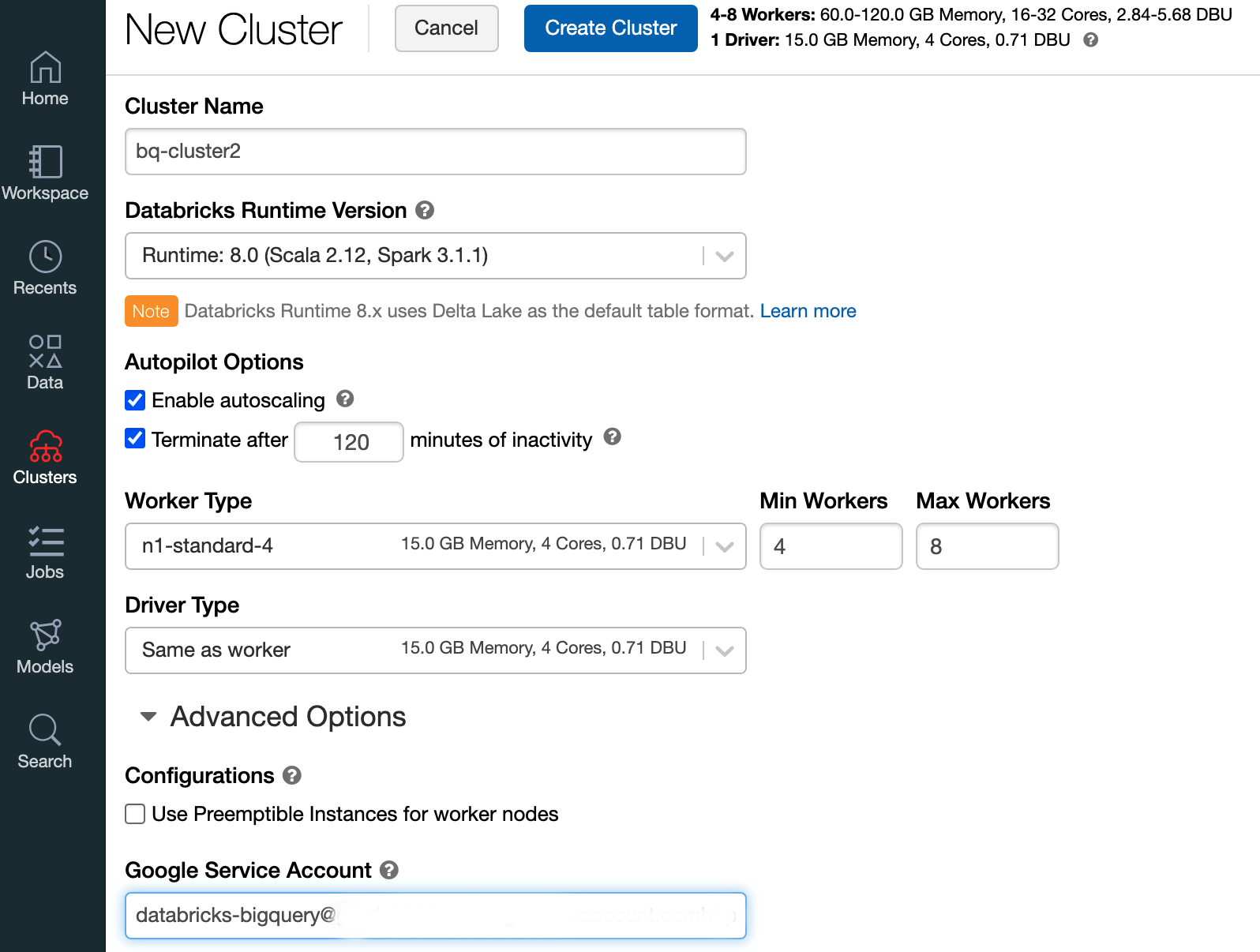
Clique em Criar cluster.
Para criar um notebook Python para o Databricks, siga as instruções em Criar um notebook.
Consultar o BigQuery a partir do Databricks
Com a configuração acima, pode associar o Databricks ao BigQuery de forma segura. O Databricks usa uma ramificação do adaptador Google Spark de código aberto para aceder ao BigQuery.
O Databricks reduz a transferência de dados e acelera as consultas ao enviar automaticamente determinados predicados de consulta, por exemplo, a filtragem em colunas aninhadas, para o BigQuery. Além disso, a capacidade adicionada de executar primeiro uma consulta SQL no BigQuery com a API query() reduz o tamanho da transferência do conjunto de dados resultante.
Os passos seguintes descrevem como aceder a um conjunto de dados no BigQuery e escrever os seus próprios dados no BigQuery.
Aceda a um conjunto de dados público no BigQuery
O BigQuery fornece uma lista de conjuntos de dados públicos disponíveis. Para consultar o conjunto de dados Shakespeare do BigQuery que faz parte dos conjuntos de dados públicos, siga estes passos:
Para ler a tabela do BigQuery, use o seguinte fragmento de código no seu bloco de notas do Databricks.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Execute o código premindo
Shift+Return.Agora, pode consultar a sua tabela do BigQuery através do Spark DataFrame (
df). Por exemplo, use o seguinte para mostrar as três primeiras linhas do DataFrame:df.show(3)Para consultar outra tabela, atualize a variável
table.Uma funcionalidade essencial dos blocos de notas do Databricks é que pode misturar as células de diferentes linguagens, como Scala, Python e SQL, num único bloco de notas.
A seguinte consulta SQL permite-lhe visualizar a contagem de palavras em Shakespeare depois de executar a célula anterior que cria a vista temporária.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12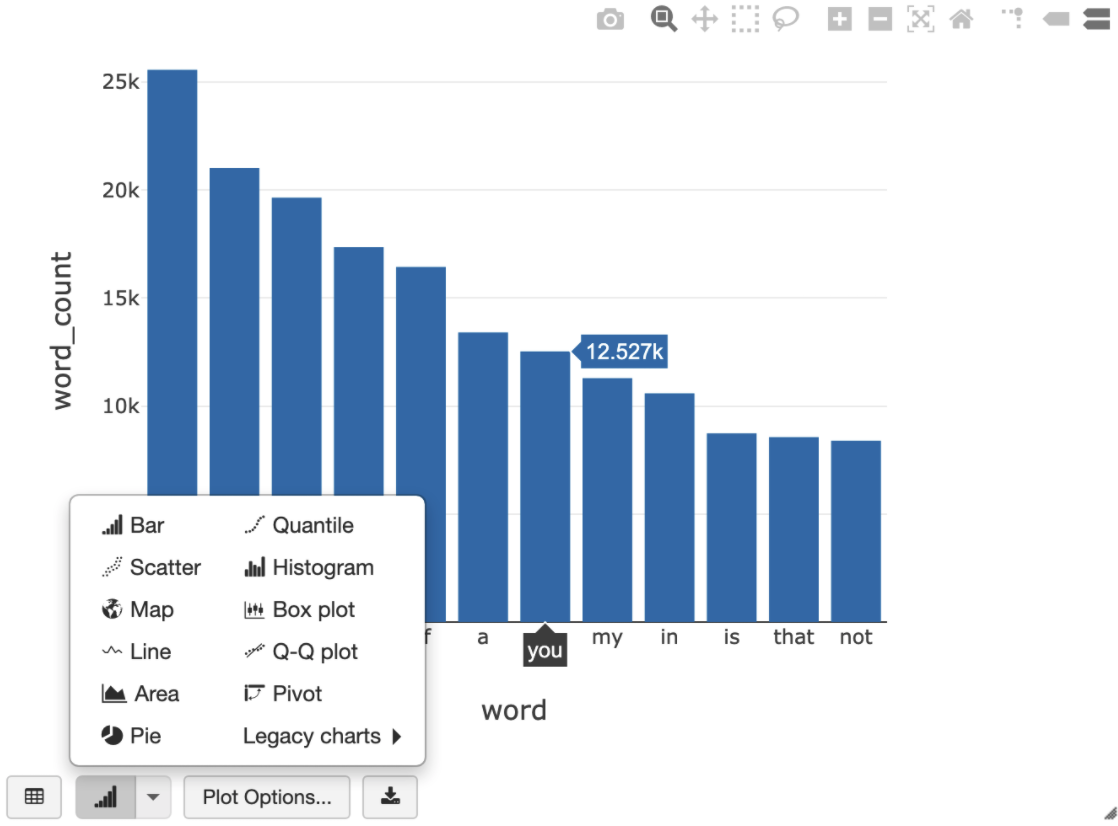
A célula acima executa uma consulta SQL do Spark no dataframe no seu cluster do Databricks e não no BigQuery. A vantagem desta abordagem é que a análise de dados ocorre ao nível do Spark, não são emitidas mais chamadas da API BigQuery, e não incorre em custos adicionais do BigQuery.
Em alternativa, pode delegar a execução de uma consulta SQL no BigQuery com a API
query()e otimizar para reduzir o tamanho da transferência do frame de dados resultante. Ao contrário do exemplo acima, em que o processamento foi feito no Spark, se usar esta abordagem, a determinação de preços e as otimizações de consultas aplicam-se à execução da consulta no BigQuery.O exemplo abaixo usa o Scala, a API
query()e o conjunto de dados público Shakespeare no BigQuery para calcular as cinco palavras mais comuns nas obras de Shakespeare. Antes de executar o código, tem de criar um conjunto de dados vazio no BigQuery denominadomdatasetque o código possa referenciar. Para mais informações, consulte o artigo Escrever dados no BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Para mais exemplos de código, consulte o Bloco de notas de exemplo do BigQuery do Databricks.
Escrever dados no BigQuery
As tabelas do BigQuery existem em conjuntos de dados. Antes de poder escrever dados numa tabela do BigQuery, tem de criar um novo conjunto de dados no BigQuery. Para criar um conjunto de dados para um bloco de notas Python do Databricks, siga estes passos:
Aceda à página do BigQuery na Google Cloud consola.
Expanda a opção Ações, clique em Criar conjunto de dados e, de seguida, atribua-lhe um nome
together.No bloco de notas Python do Databricks, crie um dataframe Spark simples a partir de uma lista Python com três entradas de string através do seguinte fragmento de código:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Adicione outra célula ao bloco de notas que escreve o dataframe do Spark do passo anterior na tabela do BigQuery
myTableno conjunto de dadostogether. A tabela é criada ou substituída. Use o nome do contentor que especificou anteriormente.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Para verificar se escreveu os dados com êxito, consulte e apresente a sua tabela do BigQuery através do Spark DataFrame (
df):display(spark.read.format("bigquery").option("table", table).load)
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Antes de remover o Databricks, faça sempre uma cópia de segurança dos seus dados e blocos de notas. Para limpar e remover completamente o Databricks, cancele a sua subscrição do Databricks na consolaGoogle Cloud e remova todos os recursos relacionados que criou na consolaGoogle Cloud .
Se eliminar um espaço de trabalho do Databricks, os dois contentores do Cloud Storage com os nomes databricks-WORKSPACE_ID e databricks-WORKSPACE_ID-system que foram criados pelo Databricks podem não ser eliminados se os contentores do Cloud Storage não estiverem vazios. Após a eliminação do espaço de trabalho, pode eliminar esses objetos manualmente naGoogle Cloud consola do seu projeto.
O que se segue?
Esta secção fornece uma lista de documentos e tutoriais adicionais:
- Saiba mais sobre os detalhes da avaliação gratuita do Databricks.
- Saiba mais sobre o Databricks no Google Cloud.
- Saiba mais sobre o Databricks BigQuery.
- Leia o anúncio no blogue sobre o suporte do BigQuery para o Databricks.
- Saiba mais acerca dos blocos de notas de exemplo do BigQuery.
- Saiba mais sobre o fornecedor do Terraform para o Databricks no Google Cloud.
- Leia o blogue da Databricks, incluindo mais informações sobre tópicos de ciência de dados e conjuntos de dados.