Tutorial ini menunjukkan cara menghubungkan tabel atau tampilan BigQuery untuk membaca dan menulis data dari notebook Databricks. Langkah-langkahnya
dijelaskan menggunakan
konsolGoogle Cloud dan
Databricks Workspaces.
Anda juga dapat melakukan langkah-langkah ini menggunakan alat command line gcloud dan databricks, meskipun panduan tersebut berada di luar cakupan tutorial ini.
Databricks di Google Cloud adalah lingkungan Databricks yang dihosting di Google Cloud, berjalan di Google Kubernetes Engine (GKE) dan menyediakan integrasi bawaan dengan BigQuery dan teknologi Google Cloud lainnya. Jika Anda baru mengenal Databricks, tonton video Pengantar Databricks Unified Data Platform untuk mengetahui ringkasan platform lakehouse Databricks.
Tujuan
- Konfigurasi Google Cloud agar terhubung dengan Databricks.
- Men-deploy Databricks di Google Cloud.
- Membuat kueri BigQuery dari Databricks.
Biaya
Tutorial ini menggunakan komponen Google Cloud Console yang dapat ditagih, termasuk BigQuery dan GKE. Harga BigQuery dan harga GKE berlaku. Untuk mengetahui informasi tentang biaya terkait akun Databricks yang berjalan di Google Cloud, lihat bagian Menyiapkan akun dan membuat ruang kerja dalam dokumentasi Databricks.
Sebelum memulai
Sebelum menghubungkan Databricks ke BigQuery, selesaikan langkah-langkah berikut:
- Aktifkan BigQuery Storage API.
- Membuat akun layanan untuk Databricks
- Membuat bucket Cloud Storage untuk penyimpanan sementara.
Mengaktifkan BigQuery Storage API
BigQuery Storage API diaktifkan secara default untuk setiap project baru yang menggunakan BigQuery. Untuk project yang sudah ada dan tidak mengaktifkan API, ikuti petunjuk berikut:
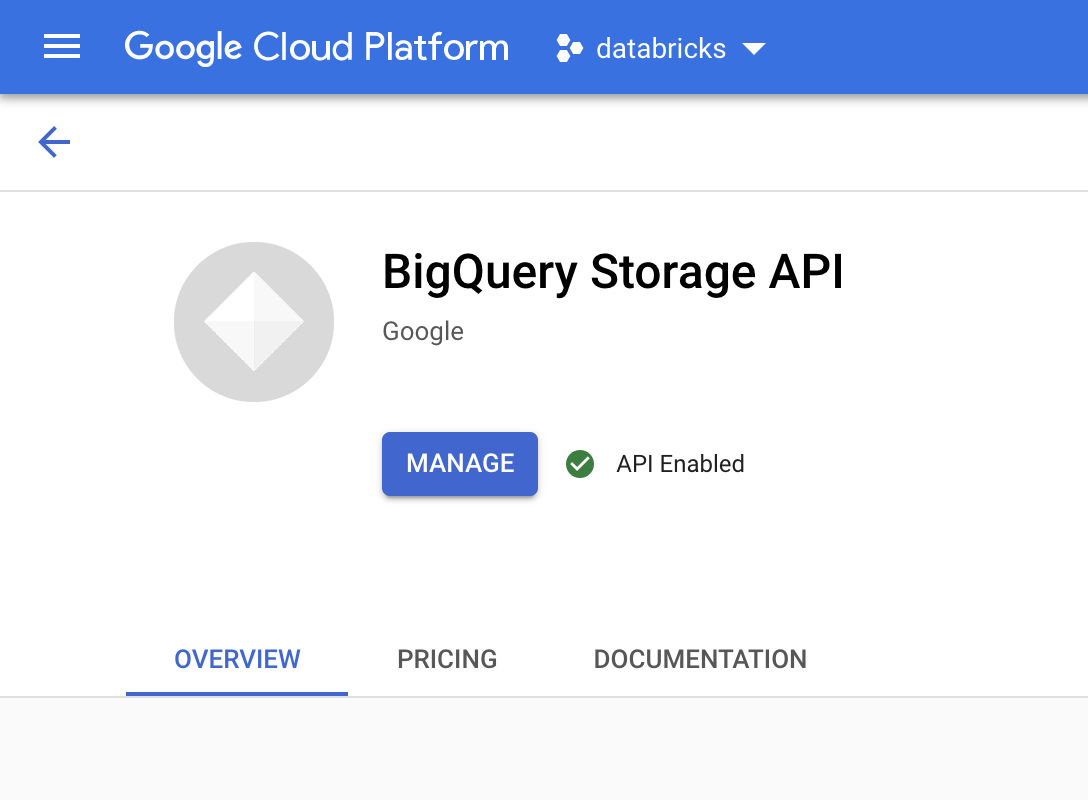
Di konsol Google Cloud , buka halaman BigQuery Storage API.
Pastikan BigQuery Storage API sudah diaktifkan.
Membuat akun layanan untuk Databricks
Selanjutnya, buat akun layanan Identity and Access Management (IAM) agar cluster Databricks dapat menjalankan kueri terhadap BigQuery. Sebaiknya beri akun layanan ini hak istimewa terendah yang diperlukan untuk melakukan tugasnya. Lihat Peran dan Izin BigQuery.
Di konsol Google Cloud , buka halaman Service Accounts.
Klik Buat akun layanan, namai akun layanan
databricks-bigquery, masukkan deskripsi singkat sepertiDatabricks tutorial service account, lalu klik Buat dan lanjutkan.Di bagian Berikan akses project ke akun layanan ini, tentukan peran untuk akun layanan. Untuk memberi akun layanan izin membaca data dengan ruang kerja Databricks dan tabel BigQuery dalam project yang sama, terutama tanpa merujuk tampilan terwujud, berikan peran berikut:
- BigQuery Read Session User
- BigQuery Data Viewer
Untuk memberikan izin menulis data, berikan peran berikut:
- BigQuery Job User
- BigQuery Data Editor
Catat alamat email akun layanan baru Anda sebagai referensi dalam langkah-langkah mendatang.
Klik Selesai.
Membuat bucket Cloud Storage
Untuk menulis ke BigQuery, cluster Databricks memerlukan akses ke bucket Cloud Storage untuk melakukan buffering data tertulis.
Di konsol Google Cloud , buka Browser Cloud Storage.
Klik Buat bucket untuk membuka dialog Membuat bucket.
Tentukan nama untuk bucket yang digunakan untuk menulis data ke BigQuery. Nama bucket harus berupa nama yang unik secara global. Jika Anda menentukan nama bucket yang sudah ada, Cloud Storage akan merespons dengan pesan error. Jika hal ini terjadi, tentukan nama yang berbeda untuk bucket Anda.
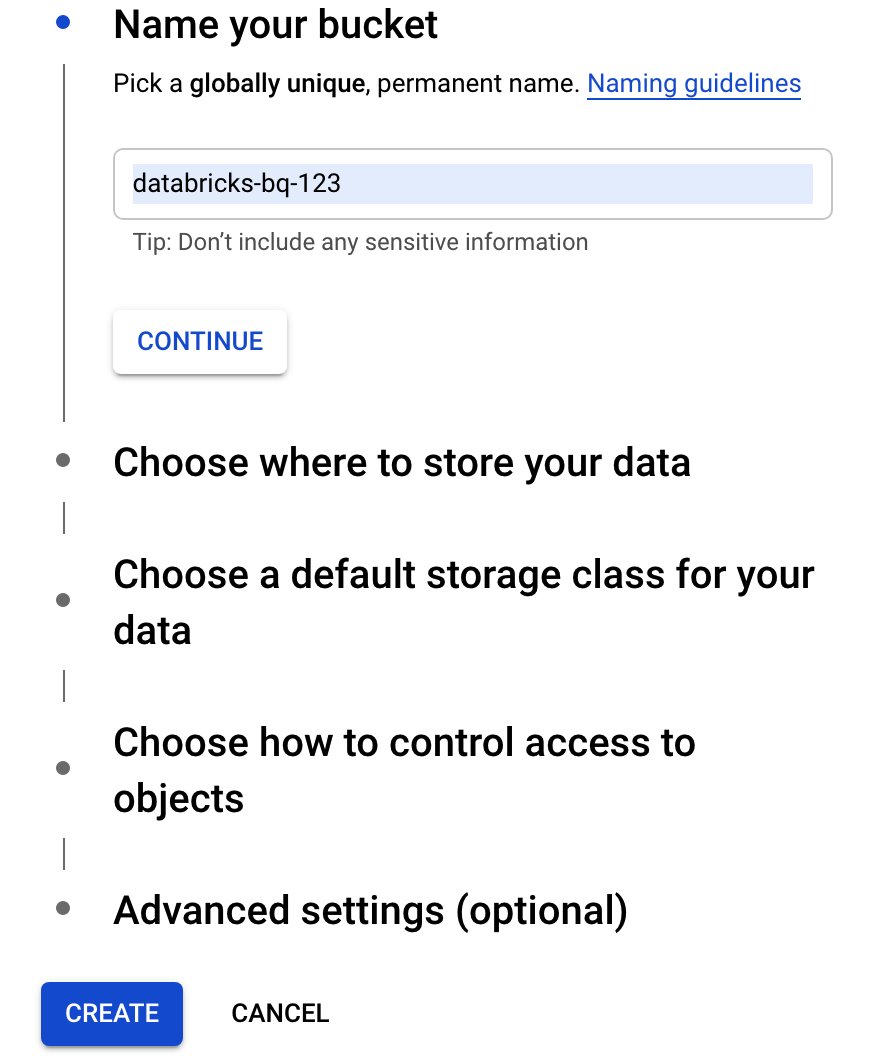
Untuk tutorial ini, gunakan setelan default untuk lokasi penyimpanan, kelas penyimpanan, kontrol akses, dan setelan lanjutan.
Klik Buat untuk membuat bucket Cloud Storage.
Klik Izin, klik Tambah, lalu tentukan alamat email akun layanan yang Anda buat untuk akses Databricks padaHalaman Akun Layanan ini.
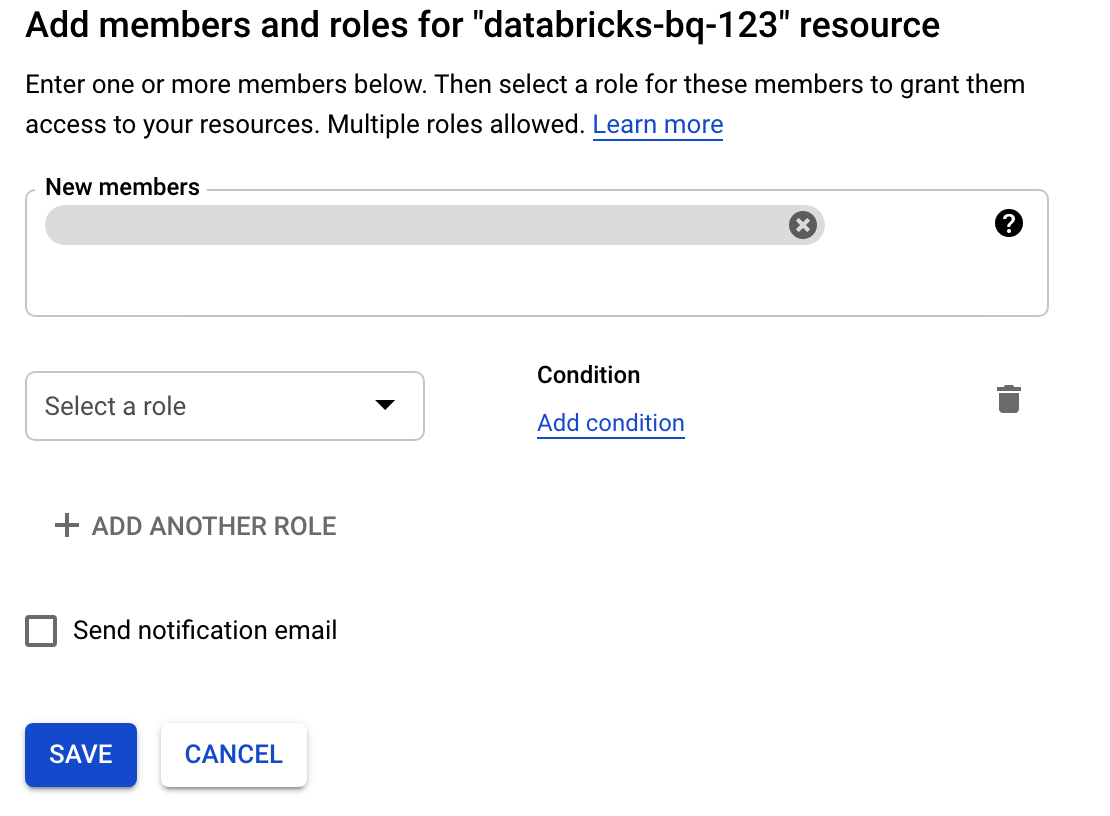
Klik Pilih peran, lalu tambahkan peran Admin penyimpanan.
Klik Simpan.
Men-deploy Databricks di Google Cloud
Selesaikan langkah-langkah berikut untuk menyiapkan deployment Databricks di Google Cloud.
- Untuk menyiapkan akun Databricks, ikuti petunjuk dalam dokumentasi Databricks, Menyiapkan Databricks di akun Google Cloud.
- Setelah mendaftar, pelajari lebih lanjut cara Mengelola akun Databricks Anda.
Membuat ruang kerja, cluster, dan notebook Databricks
Langkah-langkah berikut menjelaskan cara membuat ruang kerja Databricks, cluster, dan notebook Python untuk menulis kode guna mengakses BigQuery.
Konfirmasi prasyarat Databrick.
Buat workspace pertama Anda. Di konsol akun Databricks, klik Buat Workspace.
Tentukan
gcp-bquntuk Nama Workspace, lalu pilih Region Anda.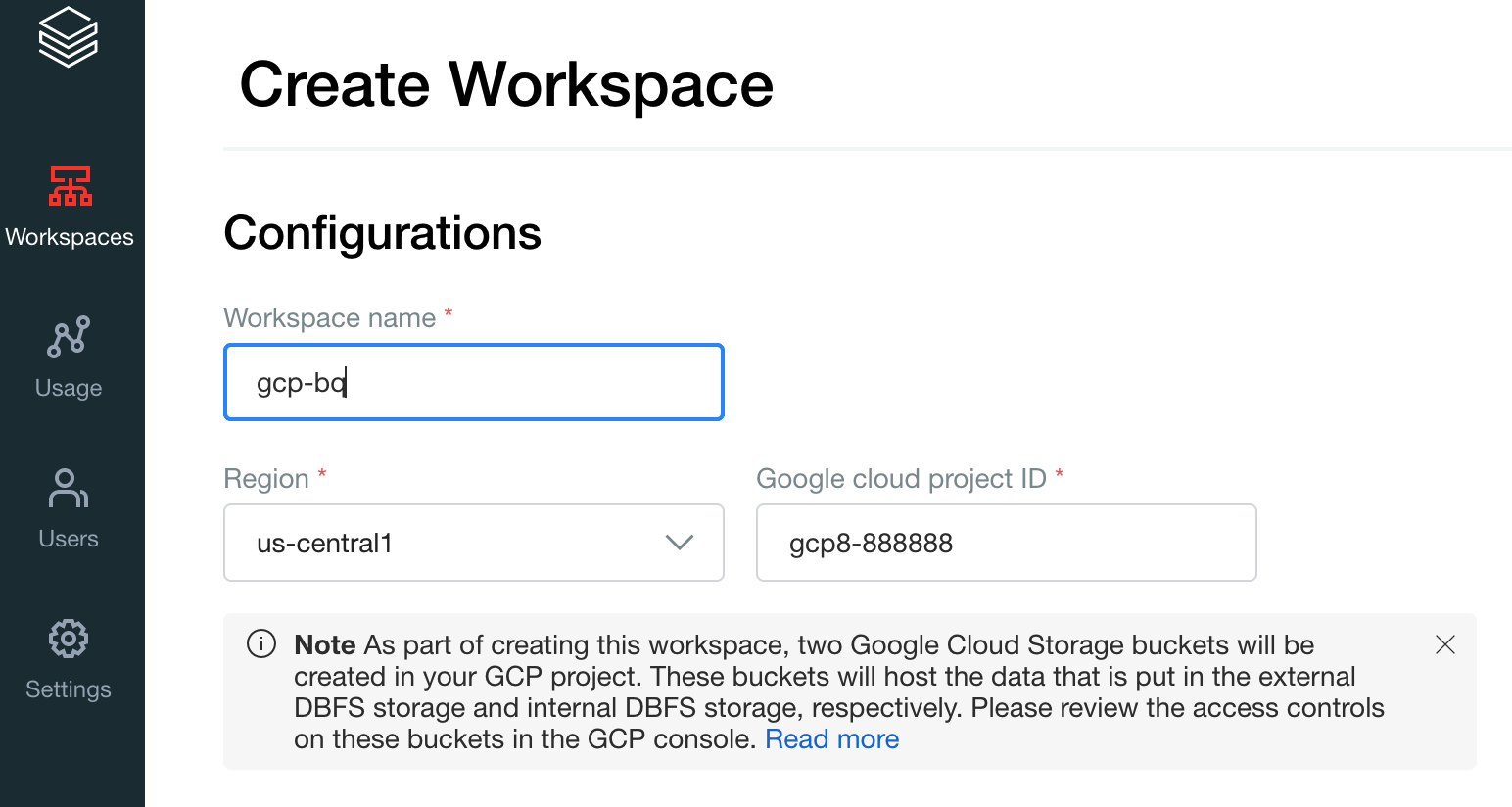
Untuk menentukan Google Cloud project ID, buka Google Cloud konsol, lalu salin nilainya ke kolom Google Cloud project ID.
Klik Simpan untuk membuat workspace Databricks Anda.
Untuk membuat cluster Databricks dengan runtime Databricks 7.6 atau yang lebih baru, di panel menu kiri, pilih Cluster, lalu klik Buat Cluster di bagian atas.
Tentukan nama cluster dan ukurannya, lalu klik Opsi Lanjutan dan tentukan alamat email akun layanan Google CloudAnda.
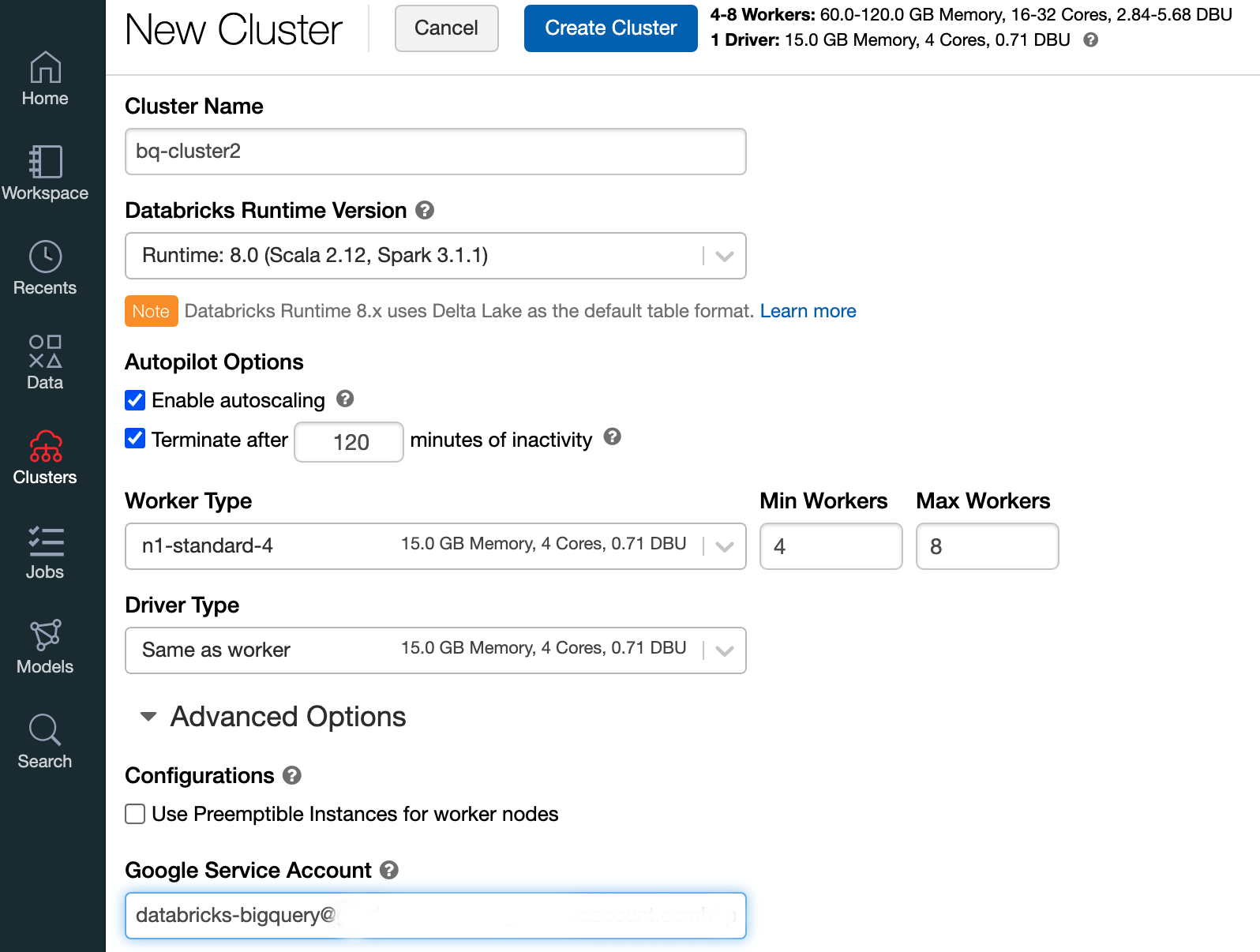
Klik Buat Cluster.
Guna membuat notebook Python untuk Databricks, ikuti petunjuk di Membuat notebook.
Membuat kueri BigQuery dari Databricks
Dengan konfigurasi di atas, Anda dapat menghubungkan Databricks ke BigQuery dengan aman. Databricks menggunakan fork open source Google Spark Adapter untuk mengakses BigQuery.
Databricks mengurangi transfer data dan mempercepat kueri dengan otomatis mendorong predikat kueri tertentu ke bawah, misalnya pemfilteran pada kolom bertingkat ke BigQuery. Selain itu, kemampuan tambahan untuk menjalankan kueri SQL
di BigQuery terlebih dahulu dengan query() API akan mengurangi ukuran transfer
set data yang dihasilkan.
Langkah-langkah berikut menjelaskan cara mengakses set data di BigQuery dan menulis data Anda sendiri ke BigQuery.
Mengakses set data publik di BigQuery
BigQuery menyediakan daftar set data publik yang tersedia. Untuk membuat kueri terhadap set data BigQuery Shakespeare yang merupakan bagian dari set data publik, ikuti langkah-langkah berikut:
Untuk membaca tabel BigQuery, gunakan cuplikan kode berikut di notebook Databricks Anda.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Jalankan kode dengan menekan
Shift+Return.Sekarang Anda dapat membuat kueri tabel BigQuery melalui Spark DataFrame (
df). Misalnya, gunakan cara berikut untuk menampilkan tiga baris pertama frame data:df.show(3)Untuk membuat kueri tabel lain, perbarui variabel
table.Fitur utama dari notebook Databricks adalah Anda dapat menggabungkan sel-sel dari berbagai bahasa seperti Scala, Python, dan SQL dalam satu notebook.
Kueri SQL berikut memungkinkan Anda memvisualisasikan jumlah kata di Shakespeare setelah menjalankan sel sebelumnya yang membuat tampilan sementara.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12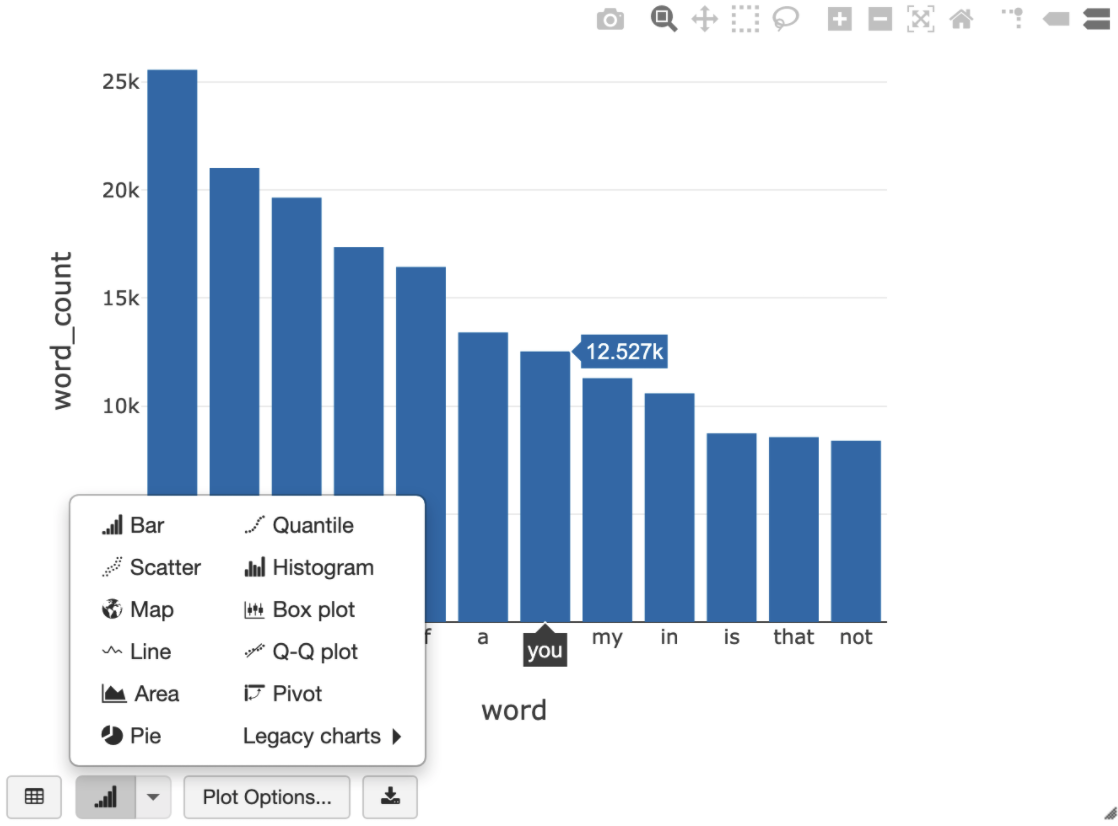
Sel di atas menjalankan kueri SQL Spark terhadap frame data di cluster Databricks Anda, bukan di BigQuery. Keuntungan dari pendekatan ini adalah analisis data terjadi di level Spark, tidak ada panggilan BigQuery API yang dikeluarkan, dan Anda tidak dikenai biaya BigQuery tambahan.
Sebagai alternatif, Anda dapat mendelegasikan eksekusi kueri SQL ke BigQuery dengan
query()API dan mengoptimalkan untuk mengurangi ukuran transfer frame data yang dihasilkan. Tidak seperti contoh di atas, yang pemrosesannya dilakukan di Spark, jika Anda menggunakan pendekatan ini, pengoptimalan harga dan kueri akan berlaku untuk menjalankan kueri di BigQuery.Contoh di bawah ini menggunakan Scala,
query()API, dan set data Shakespeare publik di BigQuery untuk menghitung lima kata yang paling umum dalam karya Shakespeare. Sebelum menjalankan kode, Anda harus terlebih dahulu membuat set data kosong di BigQuery yang disebutmdatasetyang dapat direferensikan oleh kode tersebut. Untuk mengetahui informasi selengkapnya, lihat Menulis data ke BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Untuk contoh kode lainnya, lihat notebook contoh BigQuery Databricks.
Menulis data ke BigQuery
Tabel BigQuery tersedia di set data. Sebelum dapat menulis data ke tabel BigQuery, Anda harus membuat set data baru di BigQuery. Untuk membuat set data untuk notebook Python Databricks, ikuti langkah-langkah berikut:
Buka halaman BigQuery di Google Cloud konsol.
Luaskan opsi Tindakan, klik Buat set data, lalu beri nama
together.Di notebook Python Databricks, buat frame data Spark sederhana dari daftar Python dengan tiga entri string menggunakan cuplikan kode berikut:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Tambahkan sel lain ke notebook Anda yang menulis frame data Spark dari langkah sebelumnya ke tabel BigQuery
myTabledi set datatogether. Tabel akan dibuat atau ditimpa. Gunakan nama bucket yang Anda tentukan sebelumnya.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Untuk memverifikasi bahwa Anda telah berhasil menulis data, membuat kueri, dan menampilkan tabel BigQuery melalui DataFrame Spark (
df):display(spark.read.format("bigquery").option("table", table).load)
Pembersihan
Agar tidak dikenakan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource-nya.
Sebelum menghapus Databricks, selalu cadangkan data dan notebook Anda. Untuk membersihkan dan sepenuhnya menghapus Databricks, batalkan langganan Databricks Anda di konsolGoogle Cloud dan hapus semua resource terkait yang dibuat dari konsolGoogle Cloud .
Jika Anda menghapus ruang kerja Databricks, kedua bucket Cloud Storage dengan nama databricks-WORKSPACE_ID dan databricks-WORKSPACE_ID-system yang dibuat oleh Databricks mungkin tidak dihapus jika bucket Cloud Storage tidak kosong. Setelah penghapusan ruang kerja, Anda dapat menghapus objek tersebut secara manual di konsolGoogle Cloud untuk project Anda.
Langkah berikutnya
Bagian ini menyediakan daftar dokumen dan tutorial tambahan:
- Pelajari detail uji coba gratis Databricks.
- Pelajari Databricks di Google Cloud.
- Pelajari BigQuery Databricks.
- Baca pengumuman blog dukungan BigQuery untuk Databricks.
- Pelajari Notebook Contoh BigQuery.
- Pelajari penyedia Terraform untuk Databricks di Google Cloud.
- Baca blog Databricks, termasuk informasi selengkapnya tentang topik data science dan set data.