本教學課程說明如何連結 BigQuery 資料表或檢視區塊,以便從 Databricks 筆記本讀取及寫入資料。以下步驟將使用 Google Cloud 控制台和 Databricks 工作區說明。您也可以使用 gcloud 和 databricks 指令列工具執行這些步驟,但相關指引不在本教學課程的範圍內。
Databricks on Google Cloud 是託管於 Google Cloud的 Databricks 環境,在 Google Kubernetes Engine (GKE) 上執行,並與 BigQuery 和其他 Google Cloud 技術提供內建整合功能。如果您是 Databricks 新手,請觀看「Databricks 整合式資料平台簡介」影片,瞭解 Databricks lakehouse 平台。
目標
- 設定 Google Cloud ,以便與 Databricks 連線。
- 在 Google Cloud上部署 Databricks。
- 從 Databricks 查詢 BigQuery。
費用
本教學課程使用 Google Cloud 控制台的可計費元件,包括 BigQuery 和 GKE。適用 BigQuery 定價和 GKE 定價。如要瞭解在 Google Cloud上執行的 Databricks 帳戶相關費用,請參閱 Databricks 說明文件中的「設定帳戶並建立工作區」一節。
事前準備
將 Databricks 連結至 BigQuery 前,請先完成下列步驟:
- 啟用 BigQuery Storage API。
- 為 Databricks 建立服務帳戶。
- 建立 Cloud Storage bucket,用於暫時儲存資料。
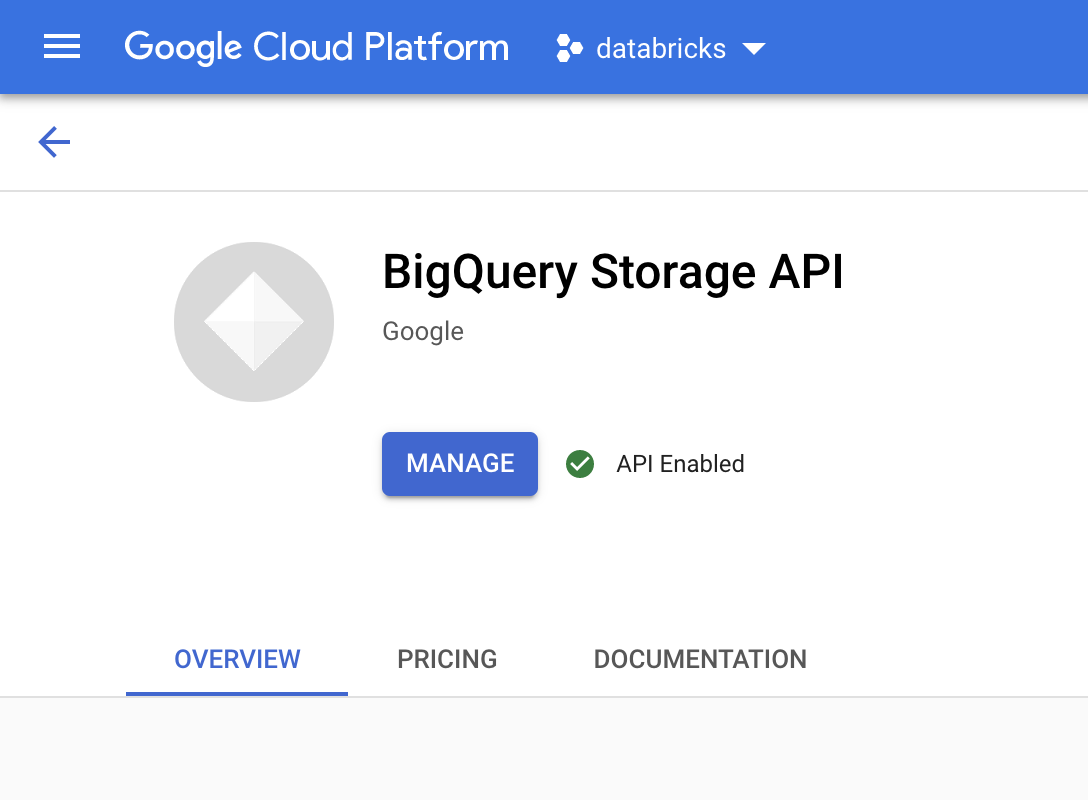
啟用 BigQuery Storage API
對於使用 BigQuery 的任何新專案,系統預設會啟用 BigQuery Storage API。如果現有專案尚未啟用 API,請按照下列操作說明進行:
前往 Google Cloud 控制台的「BigQuery Storage API」頁面。
確認已啟用 BigQuery Storage API。
建立 Databricks 的服務帳戶
接著,建立 Identity and Access Management (IAM) 服務帳戶,允許 Databricks 叢集對 BigQuery 執行查詢。建議您為這個服務帳戶提供執行工作所需的最低權限。請參閱「BigQuery 角色和權限」。
前往 Google Cloud 控制台的「Service Accounts」(服務帳戶) 頁面。
按一下「建立服務帳戶」,將服務帳戶命名為「
databricks-bigquery」,輸入簡短說明 (例如「Databricks tutorial service account」),然後按一下「建立並繼續」。在「將專案存取權授予這個服務帳戶」下方,指定服務帳戶的角色。如要授予服務帳戶權限,讓服務帳戶在同一個專案中讀取 Databricks 工作區和 BigQuery 資料表中的資料,且不參照具體化檢視區塊,請授予下列角色:
- BigQuery 讀取工作階段使用者
- BigQuery 資料檢視者
如要授予寫入資料的權限,請指派下列角色:
- BigQuery 工作使用者
- BigQuery 資料編輯者
記下新服務帳戶的電子郵件地址,以供後續步驟參考。
按一下 [完成]。
建立 Cloud Storage 值區
如要寫入 BigQuery,Databricks 叢集必須有權存取 Cloud Storage 值區,才能緩衝處理寫入的資料。
前往 Google Cloud 控制台的「Cloud Storage 瀏覽器」。
按一下「建立值區」,開啟「建立值區」對話方塊。
指定用於將資料寫入 BigQuery 的 bucket 名稱。bucket 名稱必須是全域不重複名稱。 如果您指定的值區名稱已存在,Cloud Storage 會傳回錯誤訊息。如果發生這種情況,請為 bucket 指定其他名稱。
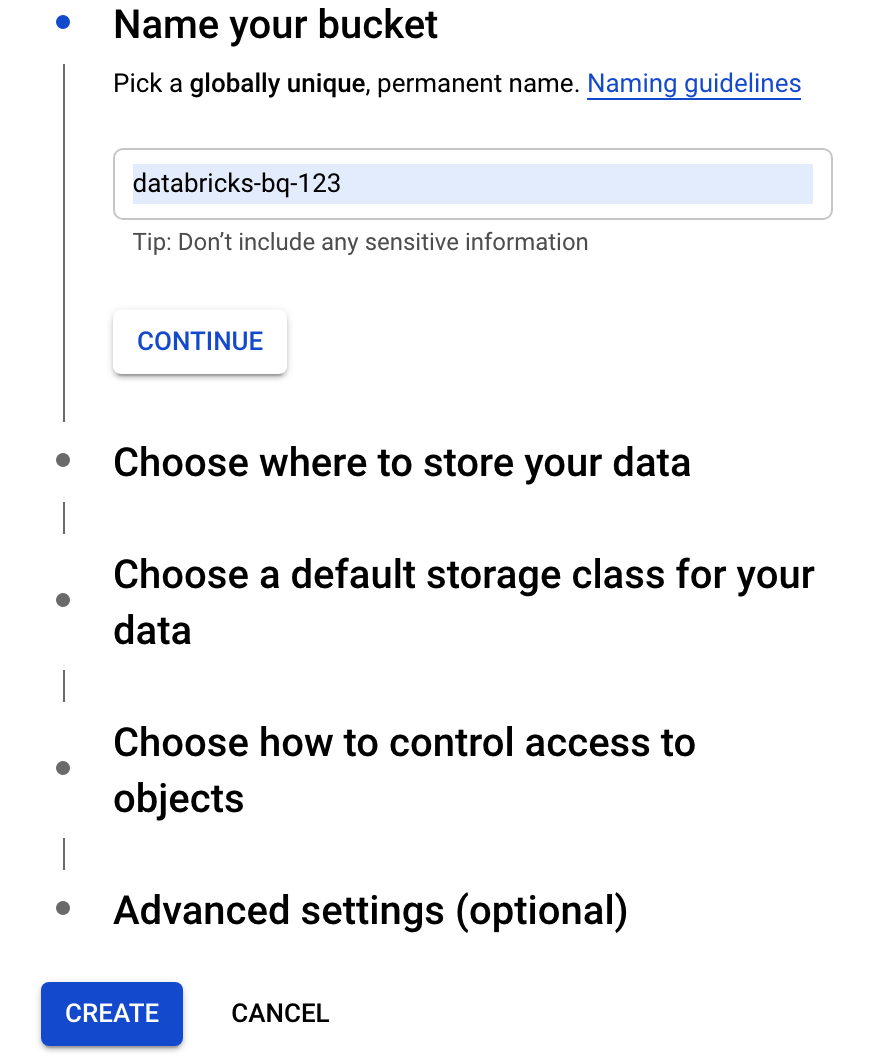
在本教學課程中,請使用儲存位置、儲存空間類別、存取控管和進階設定的預設設定。
按一下「建立」建立 Cloud Storage 值區。
按一下「權限」,然後按一下「新增」,並在「服務帳戶」頁面上,指定您為 Databricks 存取權建立的服務帳戶電子郵件地址。
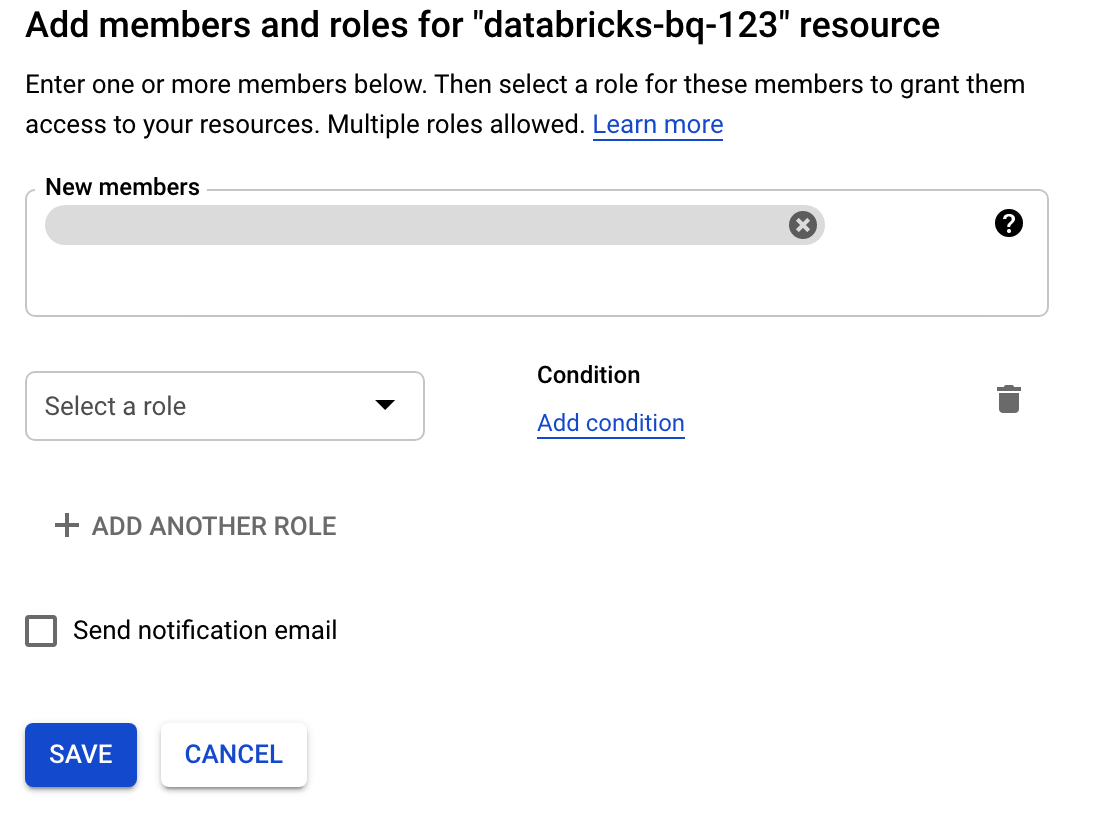
按一下「選取角色」,然後新增「Storage 管理員」角色。
按一下 [儲存]。
在 Google Cloud上部署 Databricks
請完成下列步驟,準備在 Google Cloud上部署 Databricks。
- 如要設定 Databricks 帳戶,請按照 Databricks 文件「設定 Databricks on Google Cloud帳戶」中的操作說明進行。
- 註冊後,請參閱這篇文章,進一步瞭解如何管理 Databricks 帳戶。
建立 Databricks 工作區、叢集和筆記本
下列步驟說明如何建立 Databricks 工作區、叢集和 Python 筆記本,以便編寫程式碼來存取 BigQuery。
確認 Databricks 必要條件。
建立第一個工作區。在 Databricks 帳戶控制台中,按一下「Create Workspace」(建立工作區)。
指定
gcp-bq做為工作區名稱,然後選取區域。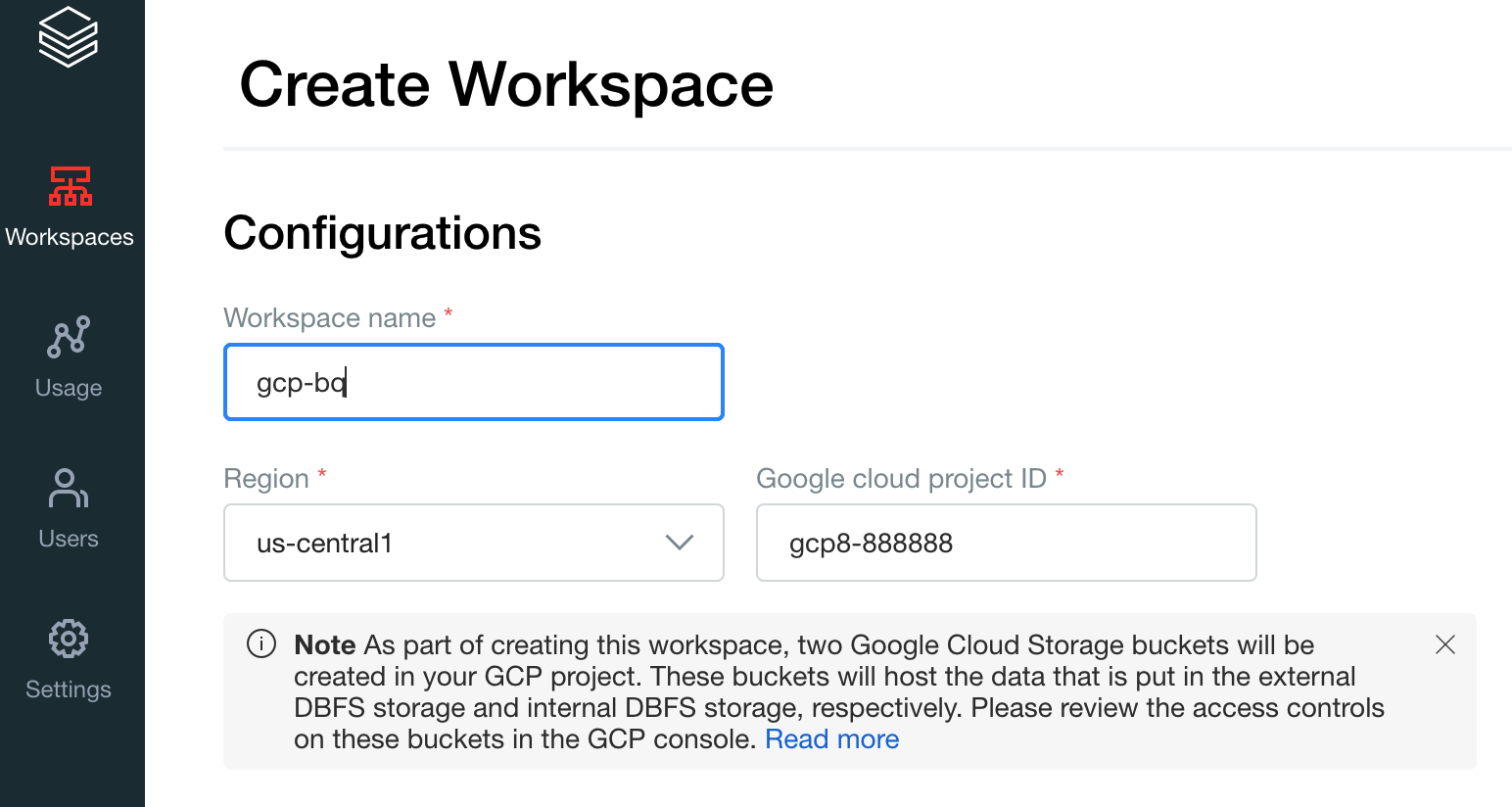
如要判斷 Google Cloud 專案 ID,請前往 Google Cloud 主控台,然後將值複製到「Google Cloud 專案 ID」欄位。
按一下「儲存」,即可建立 Databricks 工作區。
如要使用 Databricks 執行階段 7.6 以上版本建立 Databricks 叢集,請在左側選單列選取「Clusters」(叢集),然後點選頂端的「Create Cluster」(建立叢集)。
指定叢集名稱和大小,然後按一下「進階選項」,並指定服務帳戶的電子郵件地址。 Google Cloud
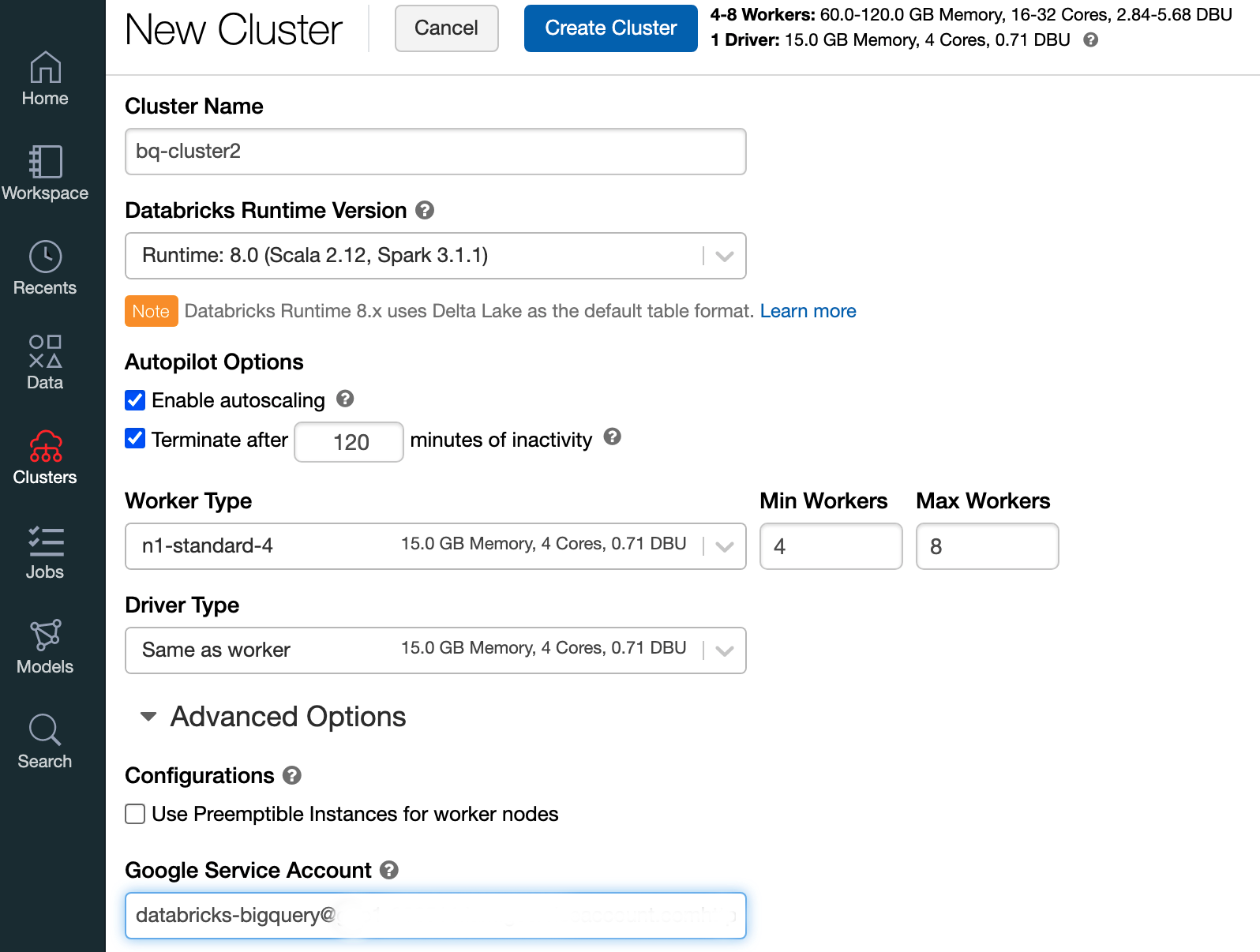
點選「建立叢集」。
如要建立 Databricks 適用的 Python 筆記本,請按照「建立筆記本」一文的說明操作。
從 Databricks 查詢 BigQuery
完成上述設定後,您就能安全地將 Databricks 連線至 BigQuery。Databricks 會使用開放原始碼 Google Spark Adapter 的分支版本存取 BigQuery。
Databricks 會自動將特定查詢述詞 (例如篩選巢狀資料欄) 下推至 BigQuery,藉此減少資料移轉量並加快查詢速度。此外,新增的這項功能可先透過 query() API 在 BigQuery 上執行 SQL 查詢,再進行資料移轉,因此可縮減產生的資料集移轉大小。
以下步驟說明如何在 BigQuery 中存取資料集,以及將自己的資料寫入 BigQuery。
存取 BigQuery 的公開資料集
BigQuery 提供可用公開資料集清單。如要查詢屬於公開資料集的 BigQuery 莎士比亞資料集,請按照下列步驟操作:
如要讀取 BigQuery 資料表,請在 Databricks 筆記本中使用下列程式碼片段。
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")按下
Shift+Return執行程式碼。現在,您可以透過 Spark DataFrame (
df) 查詢 BigQuery 資料表。舉例來說,使用下列指令即可顯示 DataFrame 的前三列:df.show(3)如要查詢其他資料表,請更新
table變數。Databricks 筆記本的主要功能是,您可以在單一筆記本中混合使用不同語言的儲存格,例如 Scala、Python 和 SQL。
執行上一個建立暫時檢視區塊的儲存格後,您可以使用下列 SQL 查詢,以視覺化方式呈現莎士比亞作品的字數。
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12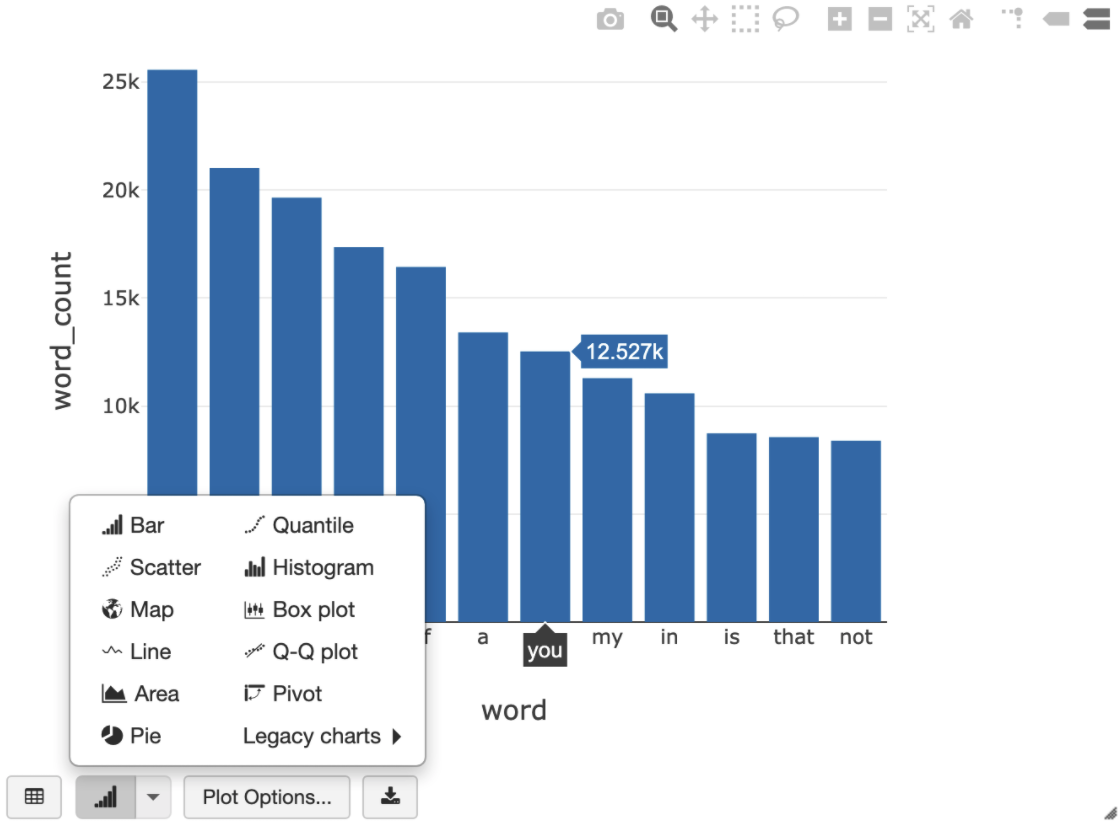
上方的儲存格會針對 Databricks 叢集中的資料架構執行 Spark SQL 查詢,而非 BigQuery。這種做法的好處是資料分析會在 Spark 層級進行,不會再發出 BigQuery API 呼叫,因此不會產生額外的 BigQuery 費用。
或者,您也可以使用
query()API 將 SQL 查詢的執行作業委派給 BigQuery,並進行最佳化,以減少產生的資料架構傳輸大小。與上述範例 (處理作業在 Spark 中完成) 不同,如果您使用這種方法,在 BigQuery 中執行查詢時,會套用定價和查詢最佳化。以下範例使用 Scala、
query()API 和 BigQuery 中的莎士比亞公開資料集,計算莎士比亞作品中最常見的五個字詞。執行程式碼前,請先在 BigQuery 中建立名為mdataset的空白資料集,供程式碼參照。詳情請參閱「將資料寫入 BigQuery」。%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)如需更多程式碼範例,請參閱 Databricks BigQuery 範例筆記本。
將資料寫入 BigQuery
BigQuery 資料表位於資料集中。 如要將資料寫入 BigQuery 資料表,您必須先在 BigQuery 中建立新資料集。如要為 Databricks Python 筆記本建立資料集,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
展開「動作」選項,按一下「建立資料集」,然後將資料集命名為
together。在 Databricks Python 筆記本中,使用下列程式碼片段,從含有三個字串項目的 Python 清單建立簡單的 Spark 資料架構:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())在筆記本中新增另一個儲存格,將上一個步驟中的 Spark 資料架構寫入資料集
together的 BigQuery 資料表myTable。系統會建立或覆寫資料表。使用您先前指定的值區名稱。bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()如要確認資料是否已成功寫入,請透過 Spark DataFrame (
df) 查詢及顯示 BigQuery 資料表:display(spark.read.format("bigquery").option("table", table).load)
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本教學課程中所用資源的相關費用,請刪除含有該項資源的專案,或者保留專案但刪除個別資源。
移除 Databricks 前,請務必先備份資料和筆記本。如要清除並徹底移除 Databricks,請在Google Cloud 控制台中取消 Databricks 訂閱,並從Google Cloud 控制台中移除您建立的所有相關資源。
如果刪除 Databricks 工作區,系統可能不會刪除 Databricks 建立的 兩個 Cloud Storage bucket (名稱為 databricks-WORKSPACE_ID 和 databricks-WORKSPACE_ID-system),除非這些 bucket 為空。工作區刪除後,您可以在專案的Google Cloud 控制台中手動刪除這些物件。
後續步驟
本節提供其他文件和教學課程的清單:
- 瞭解 Databricks 免費試用詳細資料。
- 瞭解 Databricks on Google Cloud。
- 瞭解 Databricks BigQuery。
- 請參閱 BigQuery 支援 Databricks 的網誌公告。
- 瞭解 BigQuery 範例筆記本。
- 瞭解 Databricks 的 Terraform 供應商 Google Cloud。
- 請參閱 Databricks 網誌,進一步瞭解資料科學主題和資料集。