En este instructivo, se muestra cómo conectar una vista o tabla de BigQuery para leer y escribir datos desde un notebook de Datalab. Los pasos se describen mediante la consola de Google Cloud y los Databricks Workspaces.
También puedes seguir estos pasos mediante las herramientas de línea de comandos de gcloud y databricks, aunque esta guía está fuera del alcance de este instructivo.
Databricks en Google Cloud es un entorno de Databricks alojado en Google Cloud, que se ejecuta en Google Kubernetes Engine (GKE) y que proporciona integración incorporada a BigQuery y otras tecnologías de Google Cloud. Si no estás familiarizado con Databricks, mira el video Introduction to Databricks Unified Data Platform para obtener una descripción general de la plataforma de lakehouse de Databricks.
Objetivos
- Configurar Google Cloud para conectarse con Databricks
- Implementar Databricks en Google Cloud
- Consultar BigQuery desde Databricks.
Costos
En este instructivo, se usan componentes facturables de la consola de Google Cloud, como BigQuery y GKE. Se aplican los precios de BigQuery y los precios de GKE. Para obtener información sobre los costos asociados con la cuenta de Databricks que se ejecuta en Google Cloud, consulta la sección Configura tu cuenta y crear un lugar de trabajo en la documentación de Databricks.
Antes de comenzar
Antes de conectar Databricks a BigQuery, completa los siguientes pasos:
- Habilita la API de BigQuery Storage.
- Crea una cuenta de servicio para Databricks.
- Crea un bucket de Cloud Storage para el almacenamiento temporal.
Habilita la API de BigQuery Storage
La API de BigQuery Storage está habilitada de forma predeterminada para cualquier proyecto nuevo en el que se use BigQuery. Sigue estos pasos para proyectos existentes que no tengan la API habilitada:
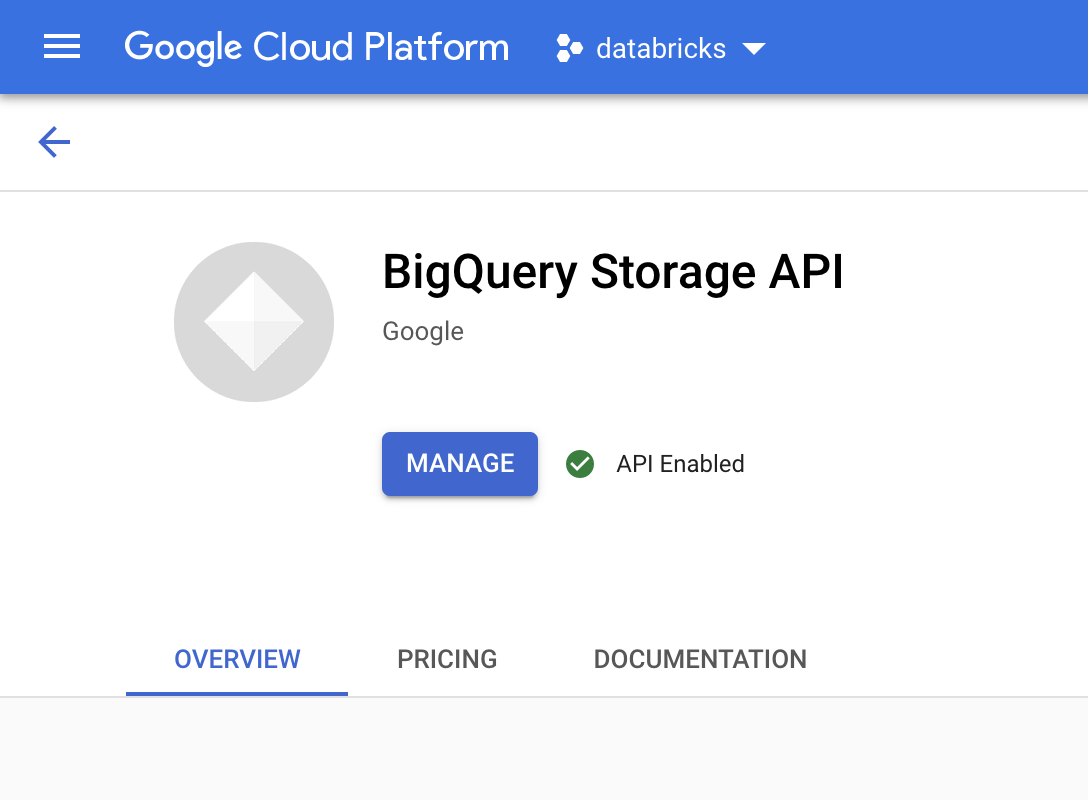
En la consola de Google Cloud, ve a la página API de BigQuery Storage.
Confirma que la API de BigQuery Storage esté habilitada.
Crea una cuenta de servicio para Databricks
A continuación, crea una cuenta de servicio de administración de identidades y accesos (IAM) para permitir que un clúster de Databricks ejecute consultas en BigQuery. Te recomendamos que le otorgues a esta cuenta de servicio los privilegios mínimos necesarios para realizar sus tareas. Consulta Funciones y permisos de BigQuery.
En la consola de Google Cloud, ve a la página Cuentas de servicio.
Haz clic en Crear cuenta de servicio, asígnale el nombre
databricks-bigquerya la cuenta de servicio, ingresa una descripción breve comoDatabricks tutorial service accounty haz clic en Crear y continuar.En Otorga a esta cuenta de servicio acceso al proyecto, especifica las funciones para la cuenta de servicio. A fin de otorgar permiso a la cuenta de servicio para leer datos con el lugar de trabajo de Databricks y la tabla de BigQuery en el mismo proyecto, en particular sin hacer referencia a una vista materializada, otorga las siguientes funciones:
- Usuario de sesión de lectura de BigQuery
- Lector de datos de BigQuery
Si deseas otorgar permiso para escribir datos, otorga las siguientes funciones:
- Usuario de trabajo de BigQuery
- Editor de datos de BigQuery
Registra la dirección de correo electrónico de la cuenta de servicio nueva como referencia para los pasos futuros.
Haz clic en Listo.
Cree un bucket de Cloud Storage
Para escribir en BigQuery, el clúster de Databricks necesita acceso a un bucket de Cloud Storage a fin de almacenar en búfer los datos escritos.
En la consola de Google Cloud, ve a la página Navegador de Cloud Storage.
Haz clic en Crear bucket para abrir el diálogo Crear un bucket.
Especifica un nombre para el bucket que se usa a fin de escribir datos en BigQuery. El nombre del bucket debe ser un nombre único a nivel global. Si especificas un nombre de bucket que ya existe, Cloud Storage responde con un mensaje de error. Si esto ocurre, especifica un nombre diferente para tu bucket.
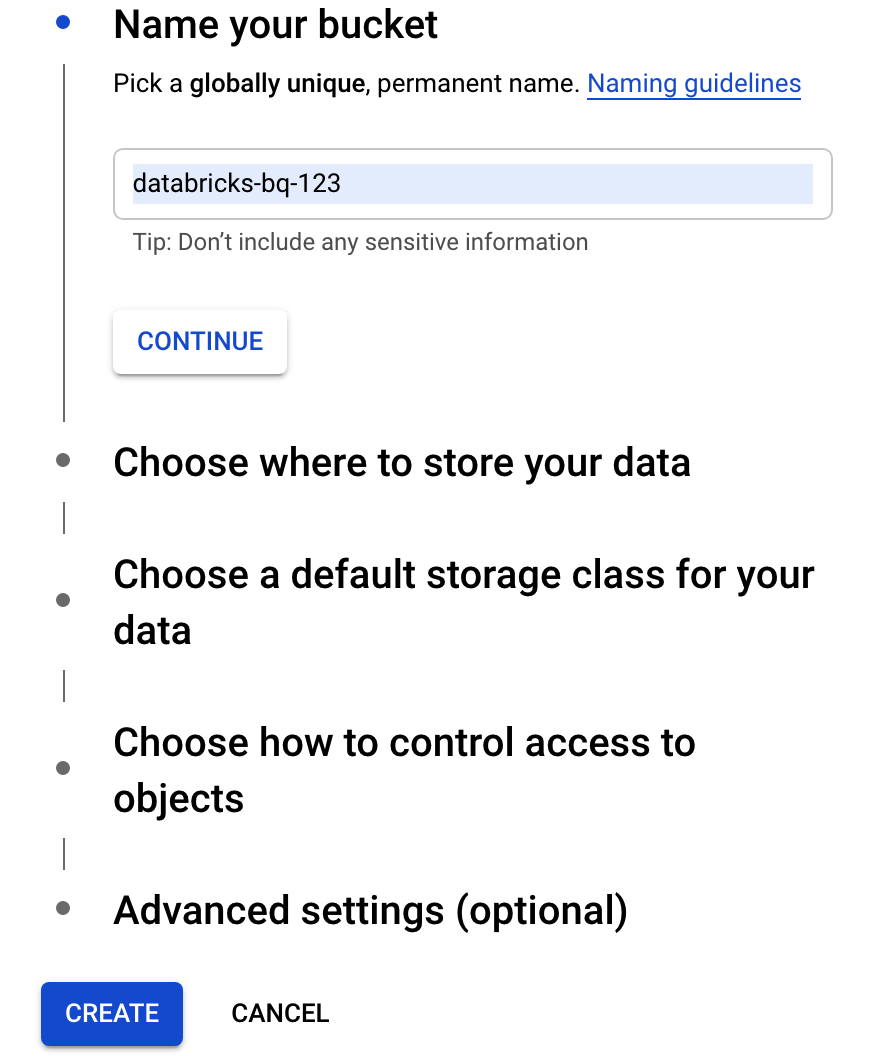
En este instructivo, se usa la configuración predeterminada para la ubicación de almacenamiento, la clase de almacenamiento, el control de acceso y la configuración avanzada.
Haz clic en Crear para crear un bucket de Cloud Storage.
Haz clic en Permisos, en Agregar y, luego, especifica la dirección de correo electrónico de la cuenta de servicio que creaste para el acceso a Databricks en la página Cuentas de servicio.
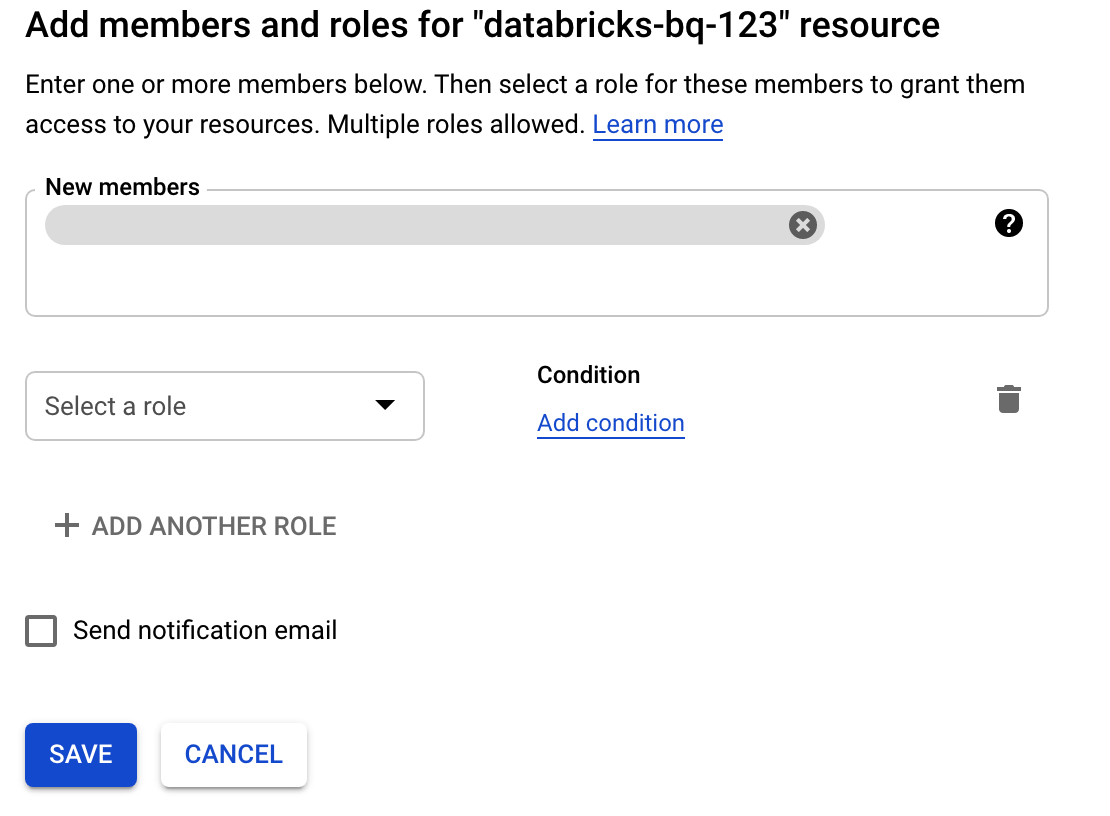
Haz clic en Selecciona una función y agrega el rol Administrador de almacenamiento.
Haz clic en Guardar.
Implementa Databricks en Google Cloud
Completa los siguientes pasos a fin de prepararte para implementar Databricks en Google Cloud.
- Para configurar tu cuenta de Databricks, sigue las instrucciones en la documentación de Databricks, Configura tu cuenta de Databricks en Google Cloud.
- Después de registrarte, obtén más información para administrar tu cuenta de Databricks.
Crea un lugar de trabajo, un clúster y un notebook de Databricks
En los pasos siguientes, se describe cómo crear un lugar de trabajo de Databricks, un clúster y un notebook de Python para escribir el código a fin de acceder a BigQuery.
Confirma los requisitos de Databrick.
Crea tu primer lugar de trabajo. En la consola de la cuenta de Databricks, haz clic en Crear lugares de trabajo.
Especifica
gcp-bqpara el Nombre del lugar de trabajo y selecciona tu Región.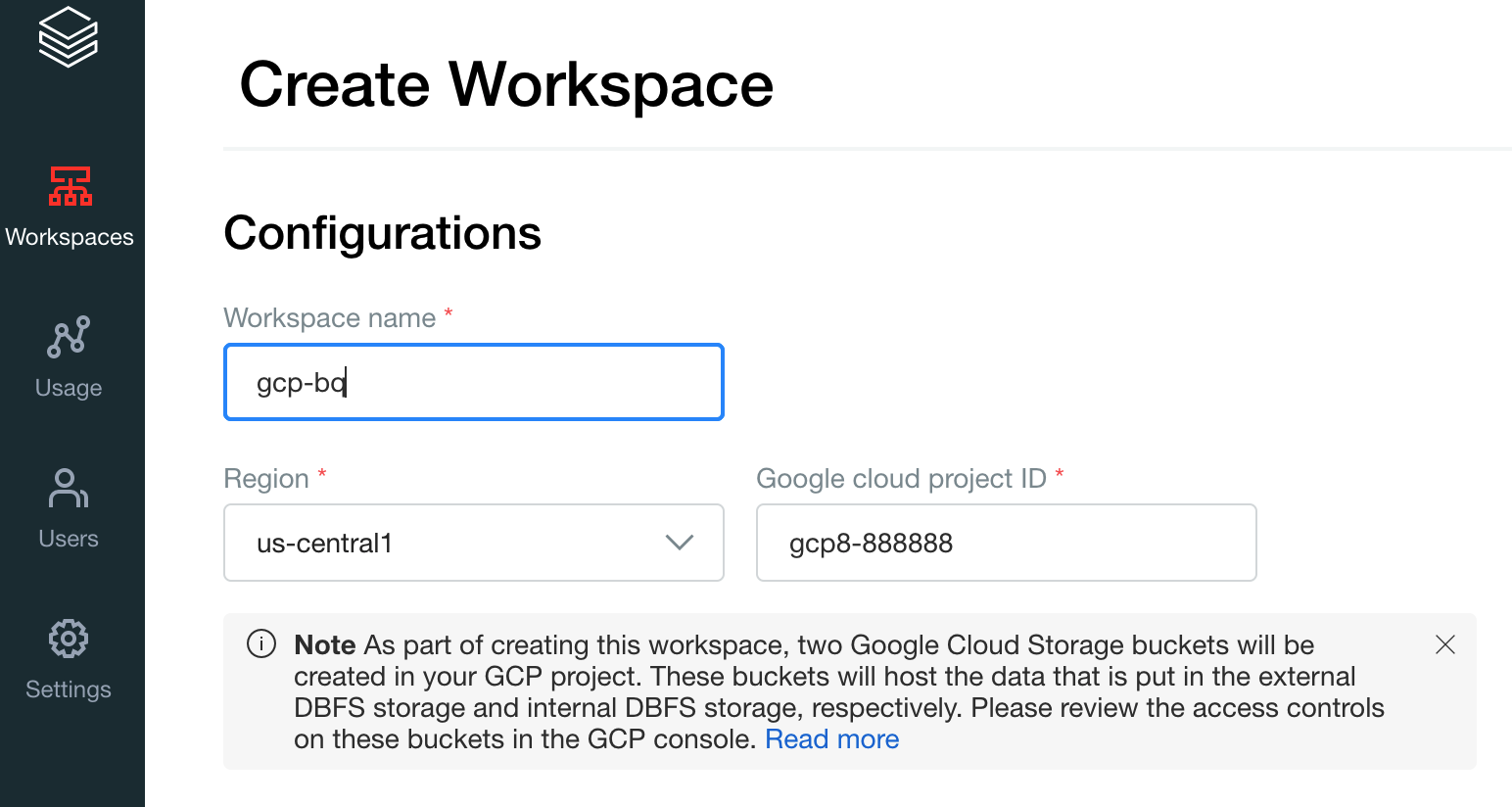
Para determinar el ID de tu proyecto de Google Cloud, visita la consola de Google Cloud y, luego, copia el valor en el campo ID del proyecto de Google Cloud.
Haz clic en Guardar para crear tu lugar de trabajo de Databricks.
Para crear un clúster de Databricks con el entorno de ejecución de Databricks 7.6 o una versión posterior, en la barra de menú de la izquierda, selecciona Clústeres y, luego, haz clic en Crear clúster en la parte superior.
Especifica el nombre de tu clúster y su tamaño, luego, haz clic en Opciones avanzadas y especifica las direcciones de correo electrónico de tu cuenta de servicio de Google Cloud.
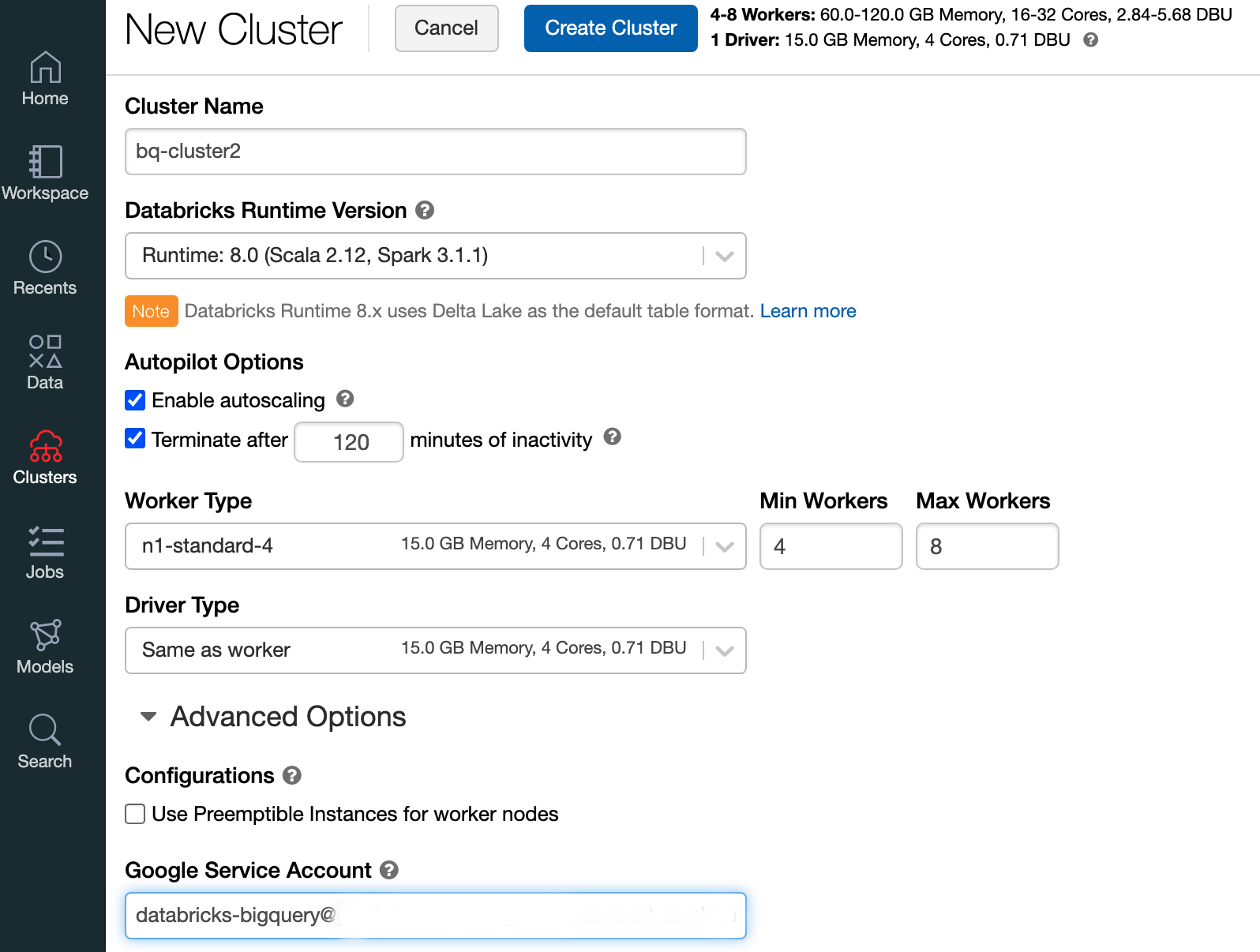
Haz clic en Crear clúster.
A fin de crear un notebook de Python para Databricks, sigue las instrucciones en Create a notebook.
Consulta BigQuery desde Databricks
Con la configuración anterior, puedes conectar Databricks a BigQuery de forma segura. Databricks usa una bifurcación del adaptador de código abierto de Google Spark para acceder a BigQuery.
Databricks reduce la transferencia de datos y acelera las consultas por medio de la eliminación automática de ciertos predicados de consulta, por ejemplo, el filtrado en columnas anidadas a BigQuery. Además, la capacidad adicional de ejecutar primero una consulta de SQL en BigQuery con la API de query() reduce el tamaño de transferencia del conjunto de datos resultante.
En los siguientes pasos, se describe cómo acceder a un conjunto de datos en BigQuery y escribir tus propios datos en BigQuery.
Accede a un conjunto de datos públicos en BigQuery
BigQuery proporciona una lista de los conjuntos de datos públicos disponibles. Para consultar el conjunto de datos de BigQuery Shakespeare, que forma parte de los conjuntos de datos públicos, sigue estos pasos:
Para leer la tabla de BigQuery, usa el siguiente fragmento de código en tu notebook de Databricks.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Para ejecutar el código, presiona
Shift+Return.Ahora puedes consultar tu tabla de BigQuery a través del marco de datos de Spark (
df). Por ejemplo, usa lo siguiente para mostrar las primeras tres filas de DataFrame:df.show(3)Para consultar otra tabla, actualiza la variable
table.Una característica clave de los notebooks de Databricks es que puedes combinar las celdas de diferentes lenguajes, como Scala, Python y SQL, en un solo notebook.
En la siguiente consulta de SQL, se puede visualizar el recuento de palabras en Shakespeare después de ejecutar la celda anterior que crea la vista temporal.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12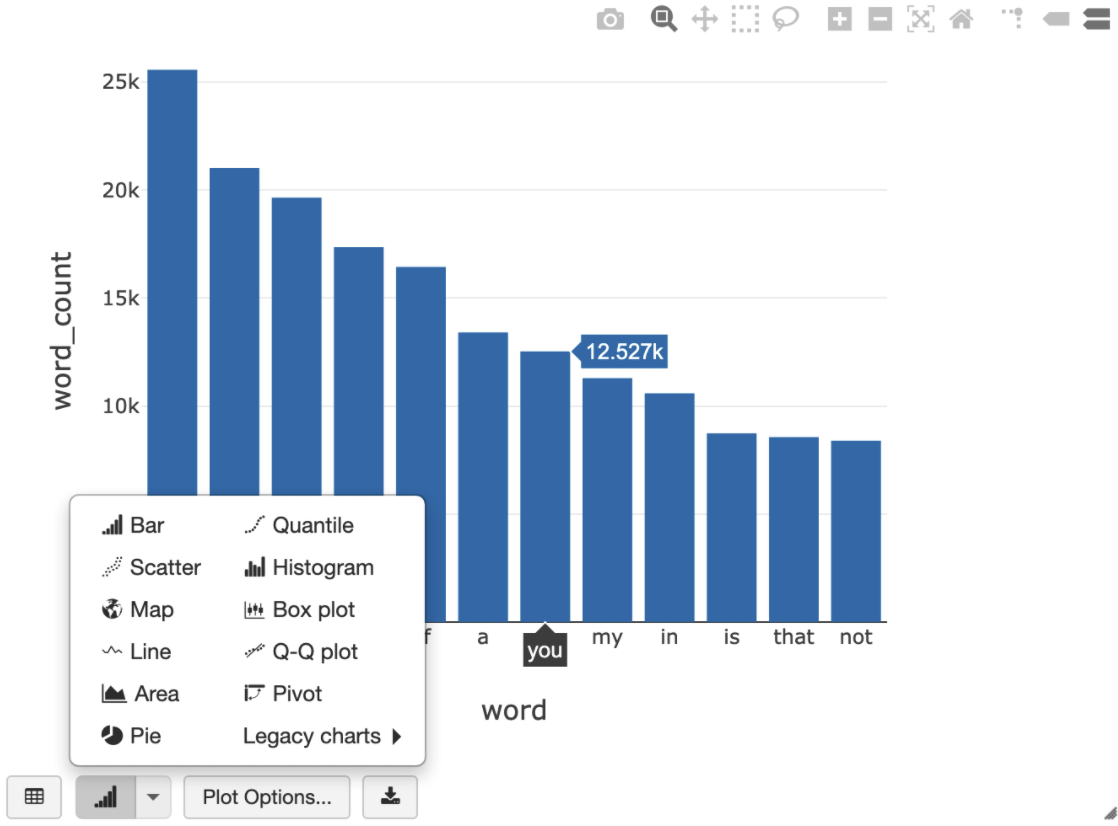
La celda anterior ejecuta una consulta de Spark SQL en el marco de datos de tu clúster de Databricks, no en BigQuery. El beneficio de este enfoque es que el análisis de datos se produce en un nivel de Spark, no se emiten más llamadas a la API de BigQuery y no se generan costos adicionales de BigQuery.
Como alternativa, puedes delegar la ejecución de una consulta de SQL a BigQuery con la API de
query()y optimizar para reducir el tamaño de transferencia del marco de datos resultante. A diferencia del ejemplo anterior, en el que el procesamiento se realizó en Spark, si usas este enfoque, los precios y las optimizaciones de consultas se aplican para ejecutar la consulta en BigQuery.En el siguiente ejemplo, se usa Scala, la API de
query()y el conjunto de datos públicos de Shakespeare en BigQuery para calcular las cinco palabras más comunes en las obras de Shakespeare. Antes de ejecutar el código, debes crear un conjunto de datos vacío en BigQuery llamadomdatasetal que el código pueda hacer referencia. Para obtener más información, consulta Escribe datos en BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Para ver más ejemplos de código, consulta el notebook de muestra de Databricks de BigQuery.
Escribe datos en BigQuery
Las tablas de BigQuery existen en los conjuntos de datos. Antes de poder escribir datos en una tabla de BigQuery, debes crear un conjunto de datos nuevo en BigQuery. Si deseas crear un conjunto de datos para un notebook de Python de Databricks, sigue estos pasos:
Ve a la página de BigQuery en la consola de Google Cloud.
Expande la opción Acciones, haz clic en Crear conjunto de datos (Create dataset) y, luego, asígnale el nombre
together.En el notebook de Python de Databricks, crea un marco de datos de Spark simple desde una lista de Python con tres entradas de string mediante el siguiente fragmento de código:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Agrega otra celda a tu notebook que escriba el marco de datos de Spark del paso anterior en la tabla
myTablede BigQuery en el conjunto de datostogether. La tabla se creará o se reemplazará. Usa el nombre de bucket que especificaste antes.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Para verificar que escribiste los datos correctamente, consulta y muestra tu tabla de BigQuery a través del marco de datos de Spark (
df):display(spark.read.format("bigquery").option("table", table).load)
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Antes de quitar los datos, siempre debes crear una copia de seguridad de los datos y los notebooks. Para limpiar y quitar por completo Databricks, cancela tu suscripción a Databricks en la consola de Google Cloud y quita todos los recursos relacionados que creaste desde la consola de Google Cloud.
Si borras un espacio de trabajo de Databricks, es posible que los dos buckets de Cloud Storage con los
nombres databricks-WORKSPACE_ID y databricks-WORKSPACE_ID-system que
creó Databricks
no se borren si los buckets de Cloud Storage no están vacíos. Después de borrar el espacio de trabajo, puedes borrar esos objetos de forma manual en la consola de Google Cloud para tu proyecto.
¿Qué sigue?
En esta sección, se proporciona una lista de instructivos y documentos adicionales:
- Obtén más información sobre los detalles de la prueba gratuita de Databricks.
- Obtén más información sobre Databricks en Google Cloud.
- Obtén más información sobre Databricks BigQuery.
- Lee el anuncio del blog sobre la asistencia de BigQuery para Databricks.
- Obtén información sobre los notebooks de muestra de BigQuery.
- Obtén más información sobre el proveedor de Terraform para Databricks en Google Cloud.
- Lee el blog de Databricks, en el que se incluye más información sobre los temas de ciencia de datos y los conjuntos de datos.