En este documento, se explica a los investigadores, los científicos de datos y los analistas de datos los procesos y las consideraciones para analizar los datos de los recursos para una interoperabilidad de atención médica rápida (FHIR) en BigQuery.
En particular, este documento se centra en los datos de los recursos de pacientes que se exportan desde el almacén de FHIR en la API de Cloud Healthcare. En este documento, también se explica una serie de consultas que demuestran cómo funcionan los datos del esquema de FHIR en un formato relacional y se muestra cómo acceder a estas consultas para volver a usarlas mediante vistas.
Usa BigQuery para analizar datos de FHIR
La API específica de FHIR de la API de Cloud Healthcare está diseñada para la interacción de transacción en tiempo real con datos FHIR a nivel de un solo recurso de FHIR o un conjunto de recursos de FHIR. Sin embargo, la API de FHIR no está diseñada para casos de uso de estadísticas. Para estos casos de uso, recomendamos exportar tus datos desde la API de FHIR a BigQuery. BigQuery es un almacén de datos escalable y sin servidores que te permite analizar grandes cantidades de datos de manera retrospectiva o prospectiva.
Además, BigQuery cumple con ANSI:2011 SQL, que permite que los científicos de datos y analistas empresariales accedan a los datos mediante herramientas que suelen usar, como Tableau, Looker o Vertex AI Workbench.
En algunas aplicaciones, como Vertex AI Workbenchs, obtienes acceso a través de clientes integrados, como la biblioteca cliente de Python para BigQuery. En estos casos, los datos que se muestran a la aplicación están disponibles a través de estructuras de datos de lenguaje integradas.
Accede a BigQuery
Puedes acceder a BigQuery a través de la IU web de BigQuery en la consola de Google Cloud y, también, con las siguientes herramientas:
- Herramienta de línea de comandos de BigQuery
- API de REST o bibliotecas cliente de BigQuery
- Controladores de ODBC y JDBC
Con estas herramientas, puedes integrar BigQuery en casi cualquier aplicación.
Trabaja con la estructura de datos de FHIR
La estructura de datos estándar de FHIR integrada es compleja, y tiene tipos de datos FHIR incorporados y anidados en cualquier recurso de FHIR. Estos tipos de datos FHIR incorporables se denominan tipos de datos complejos.
Los arreglos y las estructuras también se denominan tipos de datos complejos en las bases de datos relacionales. La estructura de datos de FHIR estándar incorporada funciona bien serializada como archivos XML o JSON en un sistema orientado a los documentos, pero puede ser difícil operar con la estructura cuando se traduce en bases de datos relacionales.
En la siguiente captura de pantalla, se muestra una vista parcial de un tipo de datos patient resource de FHIR que ilustra la naturaleza compleja de la estructura de datos estándar de FHIR incorporada.
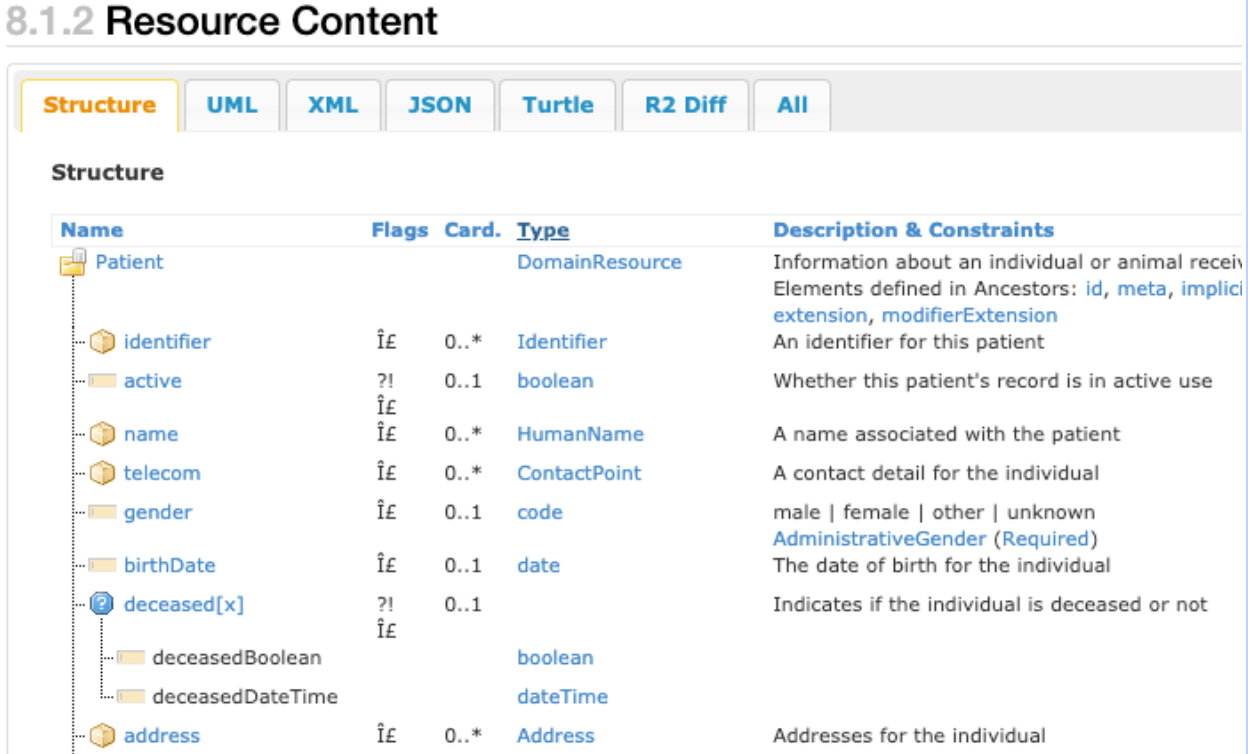
En la captura de pantalla anterior, se muestran los componentes principales de un tipo de datos patient
resource de FHIR. Por ejemplo, la columna cardinalidad (indicada en la tabla como Card.) muestra varios elementos que pueden tener cero entradas, una o más de una. La columna Tipo muestra los tipos de datos Identifier, HumanName y Address, que son ejemplos de tipos de datos complejos que incluyen el tipo patient
resource. Cada una de estas filas puede registrarse varias veces, como un arreglo de estructuras.
Usa arreglos y estructuras
BigQuery admite arreglos y tipos de datos STRUCT (estructuras de datos repetidas y anidadas), ya que se representan en recursos FHIR, lo que permite la conversión de datos de FHIR a BigQuery para ver sus detalles.
En BigQuery, un arreglo es una lista ordenada que consta de cero o más valores del mismo tipo de datos. Puedes construir arreglos de tipos de datos simples, como el tipo de datos INT64, y de tipos de datos complejos, como el tipo de datos STRUCT. La excepción es el tipo de datos ARRAY, porque en este momento no se admiten arreglos de arreglos. En BigQuery, un arreglo de estructuras aparece como un registro que se puede repetir.
Puedes especificar datos anidados, o datos anidados y repetidos, en la IU de BigQuery o en un archivo de esquema JSON. Para especificar columnas anidadas, o columnas anidadas y repetidas, usa el tipo de datos RECORD (STRUCT).
La API de Cloud Healthcare es compatible con el esquema de SQL en FHIR en BigQuery. Este esquema de estadísticas es el esquema predeterminado en el método ExportResources() y lo respalda la comunidad de FHIR.
BigQuery admite datos desnormalizados. Esto significa que cuando almacenas tus datos, en lugar de crear un esquema relacional como un esquema estrella o copo de nieve, puedes desnormalizar tus datos y usar columnas anidadas y repetidas. Las columnas anidadas y repetidas mantienen las relaciones entre los elementos de datos sin el impacto en el rendimiento que genera preservar un esquema relacional (normalizado).
Accede a tus datos a través del operador UNNEST
Cada recurso de FHIR en la API de FHIR se exporta a BigQuery como una fila de datos. Puedes considerar un arreglo o la estructura de las filas como una tabla incorporada. Puedes acceder a los datos de esa “tabla” en la cláusula SELECT o en la WHERE de tu consulta si compactas el arreglo o la estructura con el operador UNNEST.
El operador UNNEST toma un arreglo y, luego, muestra una tabla con una sola fila para cada elemento del arreglo. Para obtener más información, consulta cómo trabajar con arreglos en SQL estándar.
La operación UNNEST no conserva el orden de los elementos del arreglo, pero puedes reordenar la tabla con la cláusula opcional WITH OFFSET. Con esto, se muestra una columna adicional con la cláusula OFFSET por cada elemento del arreglo.
Luego, puedes usar la cláusula ORDER BY para ordenar las filas por su desplazamiento.
Cuando unes datos no anidados, BigQuery usa una operación correlacionada CROSS JOIN que alude a la columna de arreglos de cada elemento del arreglo con la tabla de origen, que es la tabla que precede directamente a la llamada a UNNEST en la cláusula FROM. En cada fila de la tabla de origen, la operación UNNEST compacta el arreglo en un conjunto de filas que contienen los elementos del arreglo. La operación correlacionada CROSS JOIN se une a este conjunto nuevo de filas con la fila única de la tabla de origen.
Investiga el esquema mediante consultas
Para consultar datos de FHIR en BigQuery, es importante comprender el esquema que se crea mediante del proceso de exportación. BigQuery te permite inspeccionar la estructura de las columnas de cada tabla del conjunto de datos con la función INFORMATION_SCHEMA, una serie de vistas en las que se muestran metadatos. En el resto de este documento, se hace referencia al esquema SQL en FHIR, que está diseñado para ser accesible a fin de recuperar datos.
La siguiente consulta de muestra explora los detalles de la columna de la tabla de pacientes en el esquema de SQL en FHIR. La consulta hace referencia al conjunto de datos públicos de los datos sintéticos que genera Synthea en FHIR, que aloja más de 1 millón de registros de pacientes sintéticos generados en formatos de Synthea y FHIR.
Cuando consultas la vista
INFORMATION_SCHEMA.COLUMNS
los resultados contienen una fila por cada columna (campo) de una tabla. La siguiente consulta muestra todas las columnas de la tabla de pacientes:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
En la siguiente captura de pantalla del resultado de la consulta, se muestran el tipo de datos identifier y su arreglo que contiene los tipos de datos STRUCT.

Usa el recurso de pacientes de FHIR en BigQuery
El número de historia clínica (MRN) de los pacientes, un dato crítico almacenado en tus datos de FHIR, se usa en los sistemas de datos clínicos y operativos de una organización de todos los pacientes. Cualquier método de acceso a los datos de un paciente individual o un conjunto de pacientes debe filtrar o mostrar el MRN, o hacer ambas acciones.
Mediante la siguiente consulta de muestra, se muestra el identificador del servidor de FHIR interno al recurso de pacientes, incluido el MRN y la fecha de nacimiento de todos los pacientes. El filtro para consultar en un MRN específico también se incluye, pero se analiza en este ejemplo.
En esta consulta, debes desanidar el tipo de datos complejo identifier dos veces. También debes usar las operaciones CROSS JOIN correlacionadas para unir datos sin anidar con su tabla de origen.
La tabla bigquery-public-data.fhir_synthea.patient en la consulta se creó mediante el SQL en la versión del esquema de FHIR de la exportación de FHIR a BigQuery.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
El resultado es similar al siguiente:
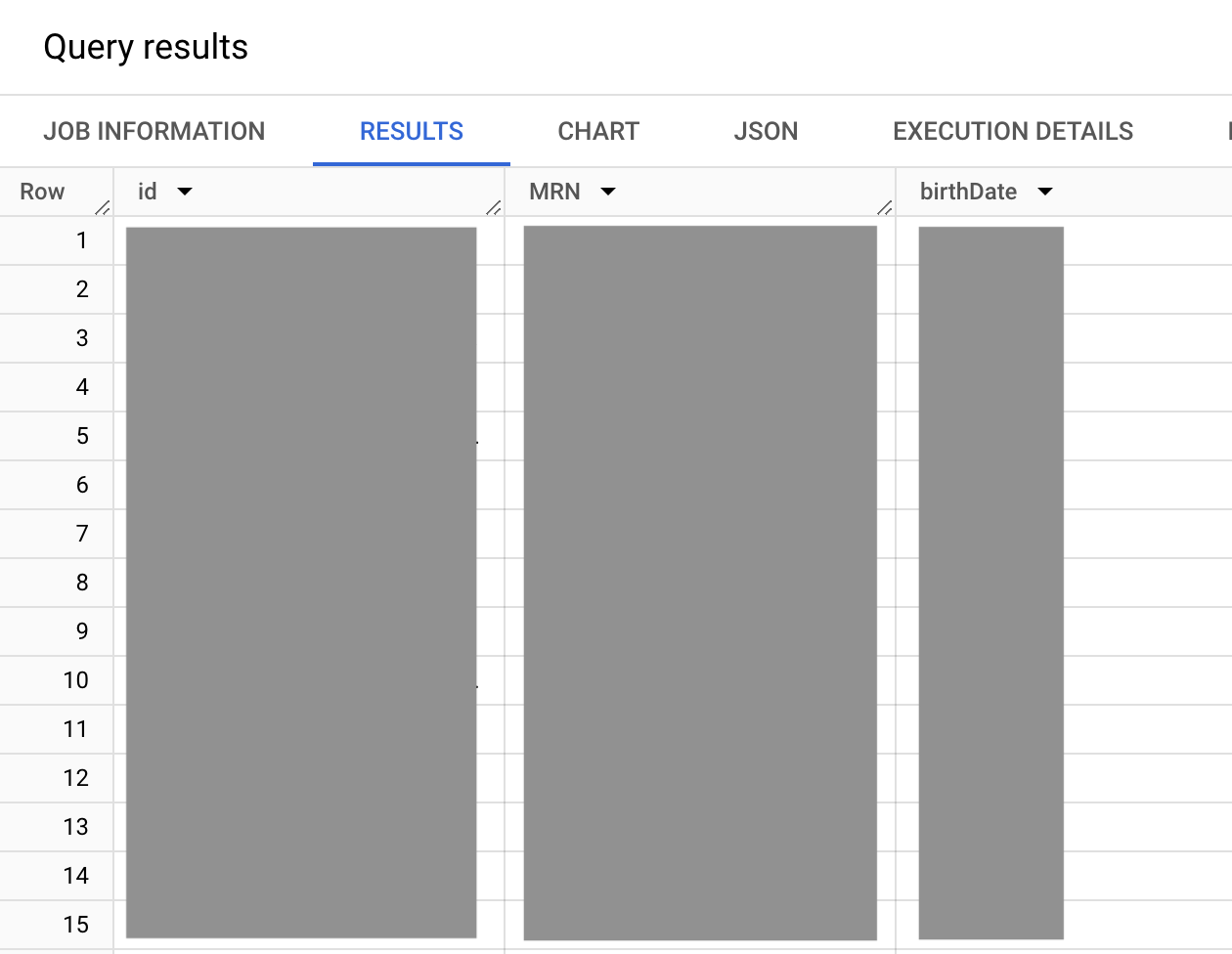
En la consulta anterior, el conjunto de valores identifier.type.coding.code es el conjunto de valores identifier de FHIR que enumera los tipos de datos de identidad disponibles, como el MRN (el tipo de datos de identidad MR), la licencia de conducir (el tipo de datos de identidad DL) y el número de pasaporte (el tipo de datos de identidad PPN). Debido a que el conjunto de valores identifier.type.coding es un arreglo, puede haber cualquier cantidad de identificadores enumerados para un paciente. Sin embargo, en este caso, deseas obtener el MRN (el tipo de datos de identidad MR).
Une la tabla de pacientes con otras tablas
A partir de la consulta de la tabla de pacientes, puedes unir la tabla de pacientes con otras tablas de este conjunto de datos, como la tabla de afecciones. En la tabla de afecciones, se registran los diagnósticos de los pacientes.
La siguiente consulta de muestra recupera todas las entradas para la afección médica de hipertensión.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
El resultado es similar al siguiente:
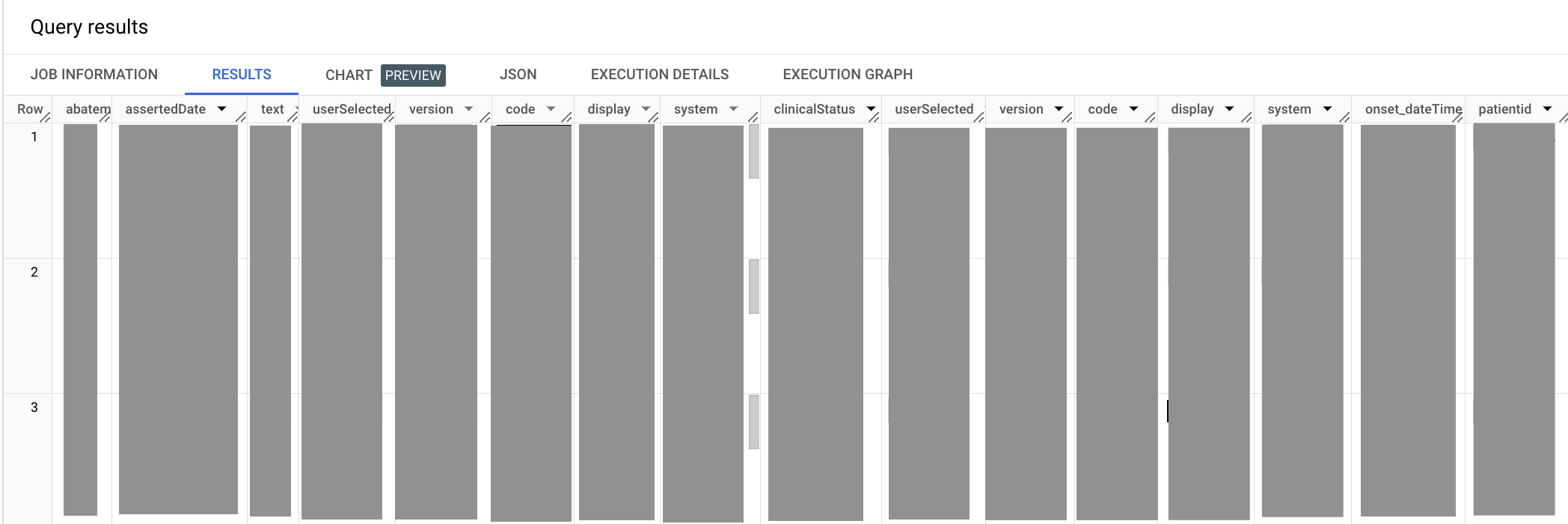
En la consulta anterior, vuelve a usar el método UNNEST para compactar el campo code.coding. Los elementos de código abatement.dateTime y onset.dateTime de la sentencia SELECT tienen alias, ya que ambos terminan en dateTime, lo que daría como resultado nombres de columnas ambiguos en el resultado de una sentencia SELECT. Cuando seleccionas el código Hypertension, también debes declarar el sistema de terminología del que proviene el código, que en este caso es el sistema de terminología clínica SNOMED CT.
Como paso final, usa la clave subject.patientid para unir la tabla de afecciones con la tabla de pacientes. Esta clave apunta al identificador del recurso de los pacientes en el servidor de FHIR.
Cómo unir las consultas
En la siguiente consulta de muestra, debes usar las consultas de las dos secciones anteriores y unirlas mediante la cláusula WITH, mientras realizas algunos cálculos simples.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
El resultado es similar a este:
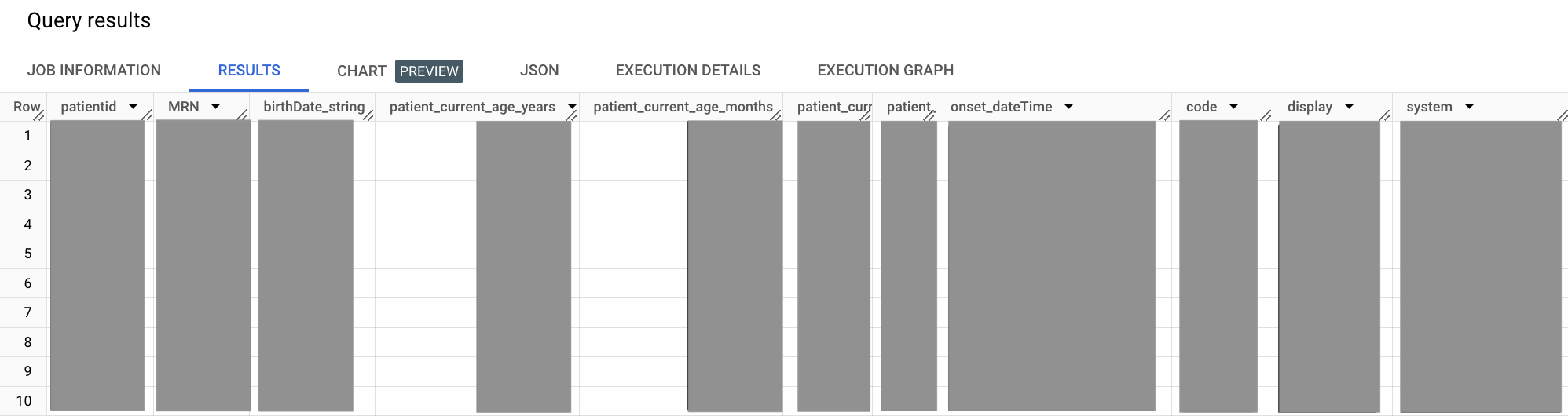
En la consulta de la muestra anterior, la cláusula WITH te permite aislar subconsultas en sus propios segmentos definidos. Este enfoque puede ayudar con la legibilidad, que se vuelve más importante a medida que tu consulta crece. En esta consulta, se aisla la subconsulta sobre pacientes y afecciones en sus propios segmentos de WITH y, luego, se une en el segmento principal SELECT.
También puedes aplicar cálculos a datos sin procesar. El siguiente código de muestra, una declaración SELECT, se muestra cómo calcular la edad del paciente cuando comenzó con una enfermedad.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Como se indica en la muestra de código anterior, puedes realizar una serie de operaciones en la string dateTime proporcionada, condition.onset_dateTime. Primero, selecciona el componente de fecha de la string con el valor SUBSTR. Luego, debes convertir la string en un tipo de datos DATE con la sintaxis CAST. También debes convertir el campo patient.birthDate en el campo DATE.
Por último, calcula la diferencia entre las dos fechas con la función DATE_DIFF.
¿Qué sigue?
- Analiza datos clínicos con BigQuery y AI Platform Notebooks.
- Visualizar datos de BigQuery en un notebook de Jupyter
- Seguridad de la API de Cloud Healthcare.
- Control de acceso a BigQuery.
- Soluciones de atención médica y ciencias biológicas en Google Cloud Marketplace
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.