Google Distributed Cloud (logiciel uniquement) pour Bare Metal est compatible avec plusieurs options de journalisation et de surveillance des clusters, y compris les services gérés basés sur le cloud, les outils Open Source et la compatibilité validée avec des solutions commerciales tierces. Cette page décrit ces options et fournit des conseils de base pour sélectionner la solution adaptée à votre environnement.
Cette page s'adresse aux administrateurs, aux architectes et aux opérateurs qui souhaitent surveiller l'état des applications ou des services déployés, par exemple pour vérifier la conformité avec les objectifs de niveau de service (SLO). Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenu Google Cloud , consultez Rôles utilisateur et tâches courantes de GKE.
Options pour Google Distributed Cloud
Vous disposez de plusieurs options de journalisation et de surveillance pour votre cluster :
- Cloud Logging et Cloud Monitoring, activés par défaut sur les composants du système Bare Metal.
- Prometheus et Grafana, disponibles depuis Cloud Marketplace
- Configurations validées avec des solutions tierces
Cloud Logging et Cloud Monitoring
Google Cloud Observability est la solution d'observabilité intégrée pourGoogle Cloud. Elle offre une solution de journalisation entièrement gérée, la collecte de métriques, la surveillance, la création de tableaux de bord et les alertes. Cloud Monitoring surveille les clusters Google Distributed Cloud de la même manière que les clusters GKE basés dans le cloud.
Cloud Logging et Cloud Monitoring sont activés par défaut lorsque vous créez des clusters avec les comptes de service et les rôles Identity and Access Management (IAM) requis. Vous ne pouvez pas désactiver Cloud Logging ni Cloud Monitoring. Pour en savoir plus sur les comptes de service et les rôles requis, consultez Configurer des comptes de service.
Les agents peuvent être configurés pour modifier les éléments suivants :
- Le champ d'application de la journalisation et de la surveillance, qui peut être limité aux composants système uniquement (par défaut) ou étendu aux composants système et aux applications.
- Le niveau de métriques collectées, qui peut être limité à un ensemble optimisé de métriques (par défaut) ou inclure toutes les métriques.
Pour en savoir plus, consultez la section Configurer des agents Stackdriver pour Google Distributed Cloud.
Logging et Monitoring fournissent une solution d'observabilité basée sur le cloud unique, puissante et facile à configurer. Nous vous recommandons vivement d'utiliser Logging et Monitoring lorsque vous exécutez des charges de travail sur Google Distributed Cloud. Pour les applications avec des composants s'exécutant sur une infrastructure standard sur site et sur Google Distributed Cloud, vous pouvez envisager d'autres solutions pour une vue de bout en bout de ces applications.
Pour en savoir plus sur l'architecture, la configuration et les données répliquées par défaut dans votre projet Google Cloud , consultez la page Fonctionnement de Logging et Monitoring pour Google Distributed Cloud.
Pour en savoir plus sur Logging, consultez la documentation Cloud Logging.
Pour en savoir plus sur Monitoring, consultez la documentation Cloud Monitoring.
Pour découvrir comment afficher et utiliser les métriques d'utilisation des ressources Cloud Monitoring à partir de Google Distributed Cloud au niveau de l'ensemble de vos parcs, consultez la page Présentation de Google Kubernetes Engine.
Prometheus et Grafana
Prometheus et Grafana sont deux produits de surveillance Open Source populaires disponibles dans Cloud Marketplace :
Prometheus recueille des métriques sur les applications et le système.
Alertmanager gère l'envoi d'alertes à l'aide de différents mécanismes.
Grafana est un outil de création de tableaux de bord.
Nous vous recommandons d'utiliser Google Cloud Managed Service pour Prometheus, qui est basé dans Cloud Monitoring, pour tous vos besoins de surveillance. Avec Google Cloud Managed Service pour Prometheus, vous pouvez surveiller les composants système sans frais. Google Cloud Managed Service pour Prometheus est également compatible avec Grafana. Toutefois, si vous préférez un système de surveillance purement local, vous pouvez choisir d'installer Prometheus et Grafana dans vos clusters.
Si vous avez installé Prometheus localement et que vous souhaitez collecter des métriques à partir de composants système, vous devez autoriser votre instance Prometheus locale à accéder aux points de terminaison de métriques des composants système :
Associez le compte de service de votre instance Prometheus au ClusterRole prédéfini
gke-metrics-agentet utilisez le jeton de compte de service comme identifiant pour extraire les métriques des composants système suivants :kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Utilisez la clé et le certificat client stockés dans le secret
kube-system/stackdriver-prometheus-etcd-scrapepour authentifier le scraping des métriques à partir d'etcd.Créez un objet NetworkPolicy pour autoriser l'accès de votre espace de noms à kube-state-metrics.
Solutions tierces
Google a collaboré avec plusieurs fournisseurs de solutions tierces de journalisation et de surveillance pour faire en sorte que leurs produits fonctionnent bien avec Google Distributed Cloud. Ces fournisseurs incluent notamment Datadog, Elastic et Splunk. D'autres solutions tierces validées seront ajoutées ultérieurement.
Les guides de solution suivants sont disponibles pour utiliser des solutions tierces avec Google Distributed Cloud :
- Surveiller Google Distributed Cloud avec Elastic Stack
- Collecter des journaux sur Google Distributed Cloud avec Splunk Connect
Fonctionnement de Logging et Monitoring pour Google Distributed Cloud
Cloud Logging et Cloud Monitoring sont installés et activés dans chaque cluster dès la création d'un cluster d'administrateur ou d'utilisateur.
Les agents Stackdriver incluent plusieurs composants sur chaque cluster :
Opérateur Stackdriver (
stackdriver-operator-*). Gère le cycle de vie de tous les autres agents Stackdriver déployés sur le cluster.Ressource personnalisée Stackdriver. Ressource créée automatiquement dans le cadre du processus d'installation de Google Distributed Cloud.
Agent de métriques GKE (
gke-metrics-agent-*). Un DaemonSet basé sur un collecteur OpenTelemetry qui récupère les métriques de chaque nœud pour Cloud Monitoring. Un DaemonSetnode-exporteret un déploiementkube-state-metricssont également inclus pour fournir plus de métriques sur le cluster.Transfert de journaux Stackdriver (
stackdriver-log-forwarder-*). Un daemonset Fluent Bit qui transmet les journaux de chaque machine à Cloud Logging. Le transfert de journaux met en mémoire tampon les entrées de journal sur le nœud localement et les renvoie pendant quatre heures maximum. Si la mémoire tampon est saturée ou si le service de transfert de journaux ne peut pas atteindre l'API Cloud Logging pendant plus de quatre heures, les journaux sont supprimés.Agent de métadonnées (
stackdriver-metadata-agent-). Un déploiement qui envoie des métadonnées pour des ressources Kubernetes telles que des pods, des déploiements ou des nœuds à l'API Config Monitoring pour Ops. L'ajout de métadonnées vous permet d'interroger vos données de métriques par nom de déploiement, nom de nœud ou même nom de service Kubernetes.
Vous pouvez afficher les agents installés par Stackdriver en exécutant la commande suivante :
kubectl -n kube-system get pods -l "managed-by=stackdriver"
La sortie de la commande ressemble à ceci :
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Métriques Cloud Monitoring
Pour obtenir la liste des métriques collectées par Cloud Monitoring, consultez Afficher les métriques Google Distributed Cloud.
Configurer des agents Stackdriver pour Google Distributed Cloud
Les agents Stackdriver installés avec Google Distributed Cloud collectent des données sur les composants système à des fins de maintenance et de dépannage des clusters. Les sections suivantes décrivent la configuration de Stackdriver et les modes de fonctionnement.
Composants système uniquement (mode par défaut)
Lors de l'installation, les agents Stackdriver sont configurés par défaut pour collecter les journaux et les métriques, y compris les détails des performances (par exemple, l'utilisation du processeur et de la mémoire) et les métadonnées similaires pour les composants système fournis par Google, y compris toutes les charges de travail du cluster d'administrateur et, pour les clusters d'utilisateur, les charges de travail dans les espaces de noms kube-system, gke-system, gke-connect, istio-system et config-management-system.
Composants système et applications
Pour activer la journalisation et la surveillance des applications en plus du mode par défaut, suivez la procédure décrite dans Activer la journalisation et la surveillance des applications.
Métriques optimisées (métriques par défaut)
Par défaut, les déploiements kube-state-metrics exécutés dans le cluster collectent et signalent un ensemble optimisé de métriques kube à Google Cloud Observability (anciennement Stackdriver).
Moins de ressources sont nécessaires pour collecter cet ensemble optimisé de métriques, ce qui améliore les performances globales et l'évolutivité.
Pour désactiver les métriques optimisées (non recommandé), remplacez le paramètre par défaut dans votre ressource personnalisée Stackdriver.
Utiliser Google Cloud Managed Service pour Prometheus pour certains composants système
Google Cloud Managed Service pour Prometheus fait partie de Cloud Monitoring et est disponible en option pour les composants système. Voici quelques avantages de Google Cloud Managed Service pour Prometheus :
Vous pouvez continuer à utiliser votre surveillance existante basée sur Prometheus sans modifier vos alertes ni vos tableaux de bord Grafana.
Si vous utilisez à la fois GKE et Google Distributed Cloud, vous pouvez utiliser le même langage de requête Prometheus (PromQL) pour les métriques de tous vos clusters. Vous pouvez également utiliser l'onglet PromQL de l'explorateur de métriques dans la console Google Cloud .
Activer et désactiver Google Cloud Managed Service pour Prometheus
À partir de la version 1.30.0-gke.1930 de Google Distributed Cloud, Google Cloud Managed Service pour Prometheus est toujours activé. Dans les versions antérieures, vous pouvez modifier la ressource Stackdriver, stackdriver, pour activer ou désactiver Google Cloud Managed Service pour Prometheus. Pour désactiver Google Cloud Managed Service pour Prometheus pour les versions de cluster antérieures à 1.30.0-gke.1930, définissez spec.featureGates.enableGMPForSystemMetrics sur false dans la ressource stackdriver.
Afficher les données de métriques
Lorsque enableGMPForSystemMetrics est défini sur true, les métriques des composants suivants ont un format différent pour leur stockage et les requêtes dans Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet and cadvisor
- Métriques des kube-state
- node-exporter
Dans le nouveau format, vous pouvez interroger les métriques précédentes à l'aide du langage de requête Prometheus (PromQL).
Exemple de requête PromQL :
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Configurer des tableaux de bord Grafana avec Google Cloud Managed Service pour Prometheus
Pour utiliser Grafana avec des données de métriques provenant de Google Cloud Managed Service pour Prometheus, vous devez d'abord configurer et authentifier la source de données Grafana. Pour configurer et authentifier la source de données, vous utilisez le synchronisateur de sources de données (datasource-syncer) afin de générer des identifiants OAuth2 et de les synchroniser avec Grafana via l'API de source de données Grafana. Le synchronisateur de sources de données définit l'API Cloud Monitoring comme URL du serveur Prometheus (la valeur de l'URL commence par https://monitoring.googleapis.com) sous la source de données dans Grafana.
Suivez la procédure décrite dans Interroger à l'aide de Grafana pour authentifier et configurer une source de données Grafana afin d'interroger les données de Google Cloud Managed Service pour Prometheus.
Un ensemble d'exemples de tableaux de bord Grafana est fourni dans le dépôt anthos-samples sur GitHub. Pour installer les exemples de tableaux de bord, procédez comme suit :
Téléchargez les exemples de fichiers JSON :
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Si votre source de données Grafana a été créée avec un nom différent de
Managed Service for Prometheus, modifiez le champdatasourcedans tous les fichiers JSON :sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Remplacez [DATASOURCE_NAME] par le nom de la source de données dans votre Grafana qui pointait vers le service Prometheus
frontend.Accédez à l'interface utilisateur de Grafana depuis votre navigateur, puis sélectionnez + Import (Importer) dans le menu Dashboards (Tableaux de bord).
Importez le fichier JSON, ou copiez et collez son contenu, puis sélectionnez Charger. Une fois le contenu du fichier chargé, sélectionnez Importer. Vous pouvez également modifier le nom et l'UID du tableau de bord avant de l'importer.
Le tableau de bord importé devrait se charger correctement si votre Google Distributed Cloud et la source de données sont correctement configurés. Par exemple, la capture d'écran suivante montre le tableau de bord configuré par
cluster-capacity.json.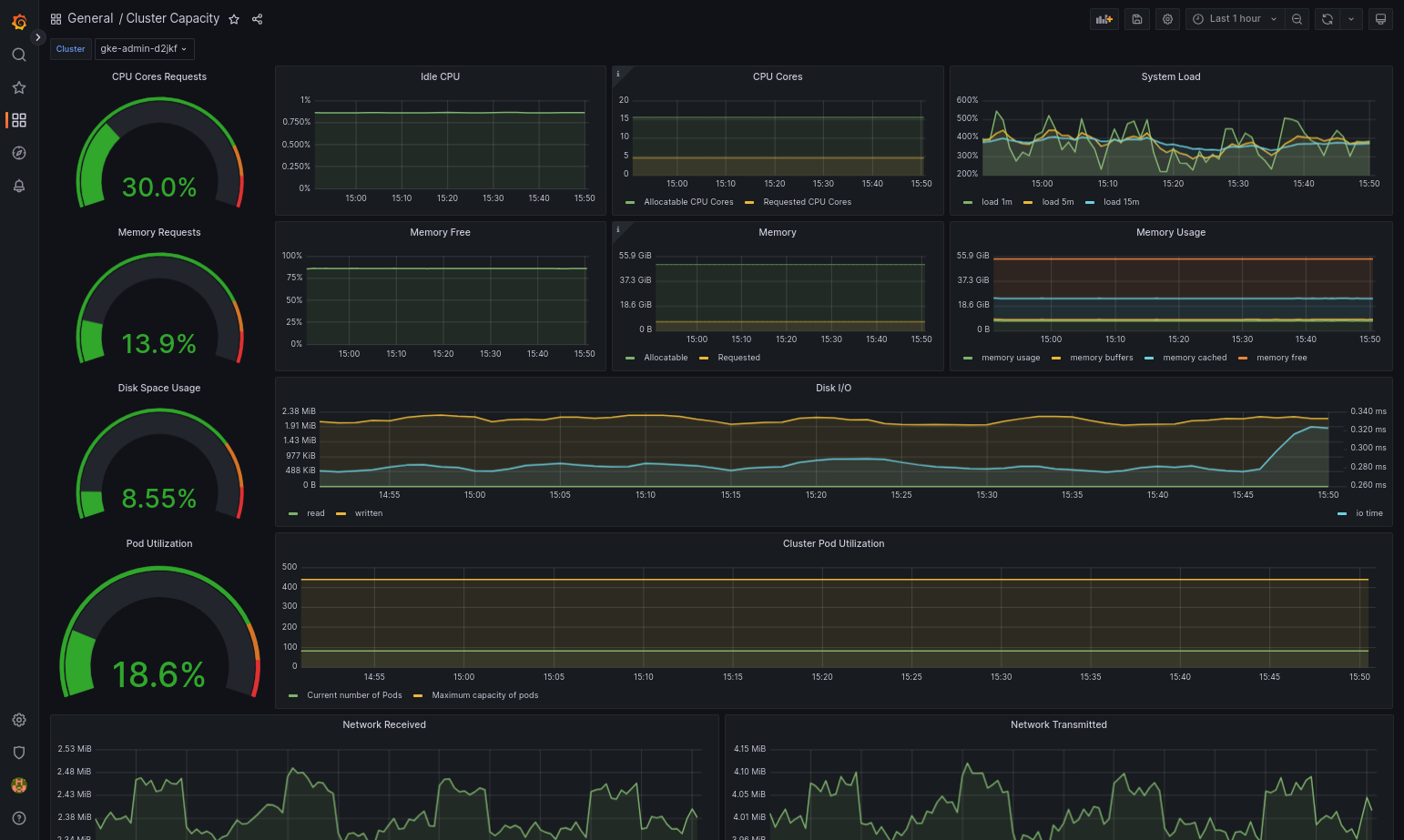
Autres ressources
Pour en savoir plus sur Google Cloud Managed Service pour Prometheus, consultez les ressources suivantes :
Configurer les ressources des composants Stackdriver
Lorsque vous créez un cluster, Google Distributed Cloud crée automatiquement une ressource personnalisée Stackdriver. Vous pouvez modifier la spécification de la ressource personnalisée pour remplacer les valeurs par défaut des demandes et limites de processeurs et de mémoire d'un composant Stackdriver, et remplacer séparément le paramètre de métrique optimisée par défaut.
Remplacer les valeurs par défaut de processeur et les demandes de mémoire et limites pour un composant Stackdriver
Les clusters à densité élevée des pods introduit des volumes de journalisation et de surveillance plus importants.accrues. Dans les cas extrêmes, les composants Stackdriver peuvent indiquer être à proximité de la limite d'utilisation du processeur et de la mémoire, ou même de subir des redémarrages constants du fait des limites de ressources. Dans ce cas, pour remplacer les valeurs par défaut des demandes de ressources mémoire et de processeur et des limites d'un composant Stackdriver, procédez comme suit :
Exécutez la commande suivante pour ouvrir la ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl -n kube-system edit stackdriver stackdriver
Dans la ressource personnalisée Stackdriver, ajoutez la section
resourceAttrOverridesous le champspec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYNotez que la section
resourceAttrOverrideremplace toutes les limites et demandes par défaut du composant spécifié. Les composants suivants sont compatibles avecresourceAttrOverride:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Voici un exemple de fichier :
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiPour enregistrer les modifications apportées à la ressource personnalisée Stackdriver, enregistrez et quittez l'éditeur de ligne de commande.
Vérifiez l'état du pod :
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Une réponse pour un pod opérationnel se présente comme suit :
gke-metrics-agent-4th8r 1/1 Running 1 40h
Vérifiez la spécification du pod du composant pour vous assurer que les ressources sont définies correctement.
kubectl -n kube-system describe pod POD_NAME
Remplacez
POD_NAMEpar le nom du pod que vous venez de modifier. Par exemple,gke-metrics-agent-4th8r.La réponse se présente comme suit :
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Désactiver les métriques optimisées
Par défaut, les déploiements kube-state-metrics exécutés dans le cluster collectent et transmettent un ensemble optimisé de métriques kube à Stackdriver. Si vous avez besoin de métriques supplémentaires, nous vous recommandons de trouver un remplacement dans la liste des métriques de Google Distributed Cloud.
Voici quelques exemples de remplacements que vous pouvez utiliser :
| Métrique désactivée | Remplacements |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Pour désactiver le paramètre par défaut des métriques optimisées (non recommandé), procédez comme suit:
Ouvrez votre ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl -n kube-system edit stackdriver stackdriver
Définissez le champ
optimizedMetricssurfalse.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Enregistrez les modifications et quittez l'éditeur de ligne de commande.
Serveur de métriques
Metrics-server est la source des métriques de ressources de conteneur pour divers pipelines d'autoscaling. Metrics-server extrait les métriques des kubelets et les expose via l'API Metrics de Kubernetes. AHP et vertical de pods exploitent ensuite ces métriques pour savoir à quel moment déclencher l'autoscaling. Metrics-server est mis à l'échelle à l'aide du module addon-resizer.
Dans les cas extrêmes où la densité de pods élevée entraîne trop de journalisation et de surveillance, metrics-server peut être arrêté et redémarré en raison de limites de ressources. Dans ce cas, vous pouvez allouer davantage de ressources au serveur de métriques en modifiant le fichier ConfigMap metrics-server-config dans l'espace de noms gke-managed-metrics-server, et en modifiant la valeur de cpuPerNode et memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
L'exemple de contenu du fichier ConfigMap est le suivant :
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Après avoir mis à jour le fichier ConfigMap, recréez les pods metrics-server à l'aide de la commande suivante :
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Routage des journaux et des métriques
L'agent de transfert de journaux Stackdriver (stackdriver-log-forwarder) envoie les journaux de chaque machine de nœud à Cloud Logging. De même, l'agent de métriques GKE (gke-metrics-agent) envoie les métriques de chaque nœud à Cloud Monitoring. Avant l'envoi des journaux et des métriques, l'opérateur Stackdriver (stackdriver-operator) associe la valeur du champ clusterLocation de la ressource personnalisée stackdriver à chaque entrée de journal et métrique avant leur routage vers Google Cloud. De plus, les journaux et les métriques sont associés au projet Google Cloud spécifié dans la spécification de la ressource personnalisée stackdriver (spec.projectID).
La ressource stackdriver obtient les valeurs des champs clusterLocation et projectID à partir des champs location et projectID de la section clusterOperations de la ressource Cluster lors de la création du cluster.
Toutes les métriques et les entrées de journal envoyées par les agents Stackdriver sont acheminées vers un point de terminaison d'ingestion global. De là, les données sont transférées vers le point de terminaison régional Google Cloud le plus proche pour assurer la fiabilité du transport des données.
Une fois que le point de terminaison mondial reçoit la métrique ou l'entrée de journal, la suite dépend du service :
Configuration du routage des journaux : lorsque le point de terminaison de journalisation reçoit un message de journal, Cloud Logging le transmet au routeur de journaux. Les récepteurs et les filtres de la configuration du routeur de journaux déterminent comment acheminer le message. Vous pouvez acheminer les entrées de journal vers des destinations telles que les buckets Logging régionaux, qui stockent l'entrée de journal, ou vers Pub/Sub. Pour en savoir plus sur le fonctionnement du routage des journaux et sur la façon de le configurer, consultez Présentation du routage et du stockage.
Ni le champ
clusterLocationde la ressource personnaliséestackdriver, ni le champclusterOperations.locationde la spécification du cluster ne sont pris en compte dans ce processus de routage. Pour les journaux,clusterLocationest utilisé pour libeller les entrées de journal uniquement, ce qui peut être utile pour le filtrage dans l'explorateur de journaux.Configuration du routage des métriques : lorsque le point de terminaison des métriques reçoit une entrée de métrique, celle-ci est automatiquement routée pour être stockée à l'emplacement spécifié par la métrique. L'emplacement de la métrique provenait du champ
clusterLocationde la ressource personnaliséestackdriver.Planifiez votre configuration : lorsque vous configurez Cloud Logging et Cloud Monitoring, configurez le routeur de journaux et spécifiez un
clusterOperations.locationapproprié avec les emplacements qui répondent le mieux à vos besoins. Par exemple, si vous souhaitez que les journaux et les métriques soient envoyés au même emplacement, définissezclusterOperations.locationsur la même région Google Cloud que celle utilisée par le routeur de journaux pour votre projet Google Cloud .Mettez à jour la configuration de vos journaux si nécessaire : vous pouvez modifier à tout moment les paramètres de destination des journaux en fonction des besoins de votre entreprise, par exemple les plans de reprise après sinistre. Les modifications apportées à la configuration du routeur de journaux dansGoogle Cloud prennent effet rapidement. Les champs
locationetprojectIDde la sectionclusterOperationsde la ressource Cluster sont immuables. Vous ne pouvez donc pas les mettre à jour après avoir créé votre cluster. Nous vous déconseillons de modifier directement les valeurs dans la ressourcestackdriver. Cette ressource est rétablie dans l'état de création du cluster d'origine chaque fois qu'une opération de cluster, telle qu'une mise à niveau, déclenche une réconciliation.
Configuration requise pour Logging et Monitoring
Plusieurs configurations sont requises pour activer Cloud Logging et Cloud Monitoring avec Google Distributed Cloud. Ces étapes sont incluses dans la section Configurer un compte de service à utiliser avec Logging et Monitoring sur la page "Activer les services Google" et dans la liste suivante :
- Un espace de travail Cloud Monitoring doit être créé dans le projetGoogle Cloud . Pour ce faire, cliquez sur Monitoring dans la consoleGoogle Cloud et suivez le workflow.
Vous devez activer les API Stackdriver suivantes :
Vous devez attribuer les rôles IAM suivants au compte de service utilisé par les agents Stackdriver :
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Balises de journaux
De nombreux journaux Google Distributed Cloud comportent un tag F :
logtag: "F"
Ce tag signifie que l'entrée de journal est complète ou entière. Pour en savoir plus sur ce tag, consultez Format du journal dans les propositions de conception Kubernetes sur GitHub.
Tarifs
Dans un cluster Google Distributed Cloud, les journaux et les métriques du système incluent les éléments suivants :
- Journaux et métriques de tous les composants d'un cluster d'administrateur.
- Journaux et métriques des composants de ces espaces de noms dans un cluster d'utilisateur :
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system.
Pour en savoir plus, consultez la section Tarifs de Google Cloud Observability.
Pour en savoir plus sur l'attribution de crédits pour les métriques Cloud Logging, contactez le service commercial au sujet des tarifs.