La pagina descrive le metriche OpenTelemetry disponibili per monitorare le risorse Config Sync.
Prezzi
Le metriche di Config Sync utilizzano Google Cloud Managed Service per Prometheus per caricare le metriche in Cloud Monitoring. I costi di Cloud Monitoring per l'importazione di queste metriche si basano sul numero di campioni importati.
Per maggiori informazioni, consulta la pagina Prezzi di Cloud Monitoring.
Come Config Sync raccoglie le metriche
Config Sync utilizza OpenCensus per creare e registrare le metriche e OpenTelemetry per esportarle in Prometheus e Cloud Monitoring. Le seguenti guide spiegano come esportare le metriche:
- Cloud Monitoring
- Prometheus
- Sistema di monitoraggio personalizzato (non consigliato)
Per configurare OpenTelemetry Collector, per impostazione predefinita Config Sync crea un
ConfigMap denominato otel-collector. Il deployment otel-collector viene eseguito
nello spazio dei nomi config-management-monitoring.
La creazione di ConfigMap otel-collector configura l'esportatore prometheus, che espone un endpoint delle metriche per la scansione di Prometheus.
Quando esegui Config Sync su GKE o in un altro ambiente Kubernetes configurato con le credenziali Google Cloud , Config Sync crea un ConfigMap denominato otel-collector-google-cloud. otel-collector-google-cloud esegue l'override della configurazione in ConfigMap otel-collector. Config Sync ripristina le modifiche apportate ai ConfigMap
otel-collector o otel-collector-google-cloud.
La creazione di ConfigMap otel-collector-google-cloud aggiunge anche l'esportatore cloudmonitoring, che esporta in Cloud Monitoring, e l'esportatore kubernetes, che esporta nel servizio di metriche interno di Google. L'esportatore
kubernetes invia a Google metriche selezionate e anonimizzate per contribuire a migliorare
Config Sync.
Cloud Monitoring archivia le metriche che invii nel tuo progettoGoogle Cloud . Gli esportatori cloudmonitoring e kubernetes utilizzano lo stesso
service accountGoogle Cloud , che richiede l'autorizzazione IAM per scrivere
in Cloud Monitoring. Per configurare queste autorizzazioni, vedi
Concedere l'autorizzazione di scrittura delle metriche per Cloud Monitoring.
Metriche OpenTelemetry
Config Sync e Resource Group Controller raccolgono le seguenti metriche con OpenCensus e le rendono disponibili tramite OpenTelemetry Collector . La colonna Tag elenca i tag specifici di Config Sync applicabili a ogni metrica. Le metriche con tag rappresentano più misurazioni, una per ogni combinazione di valori dei tag.
Metriche di Config Sync
| Nome | Tipo | Tag | Descrizione |
|---|---|---|---|
| api_duration_seconds | Distribuzione | operazione, stato | La distribuzione della latenza delle chiamate al server API. |
| apply_duration_seconds | Distribuzione | stato | La distribuzione della latenza dell'applicazione delle risorse dichiarate dalla sorgente attendibile a un cluster. |
| apply_operations_total | Conteggio | operazione, stato, controller | Il numero totale di operazioni eseguite per sincronizzare le risorse dall'origine attendibile a un cluster. |
| declared_resources | Ultimo valore | Il numero di risorse dichiarate analizzate da Git. | |
| internal_errors_total | Conteggio | origine | Il numero totale di errori interni rilevati da Config Sync. La metrica potrebbe non essere visualizzata nei risultati della query se non si è verificato alcun errore interno. |
| last_sync_timestamp | Ultimo valore | stato | Il timestamp dell'ultima sincronizzazione da Git. |
| parser_duration_seconds | Distribuzione | stato, trigger, origine | La distribuzione della latenza delle diverse fasi coinvolte nella sincronizzazione dall'origine attendibile a un cluster. |
| pipeline_error_observed | Ultimo valore | name, reconciler, component | Lo stato delle risorse personalizzate RootSync e RepoSync. Un valore pari a 1 indica un errore. |
| reconcile_duration_seconds | Distribuzione | stato | La distribuzione della latenza degli eventi di riconciliazione gestiti dal gestore della riconciliazione. |
| reconciler_errors | Ultimo valore | componente, errorclass | Il numero di errori riscontrati durante la sincronizzazione delle risorse dall'origine attendibile a un cluster. |
| remediate_duration_seconds | Distribuzione | stato | La distribuzione della latenza degli eventi di riconciliazione del correttore. |
| resource_conflicts_total | Conteggio | Il numero totale di conflitti di risorse derivanti da una mancata corrispondenza tra le risorse memorizzate nella cache e le risorse del cluster. La metrica potrebbe non essere visualizzata nei risultati della query se non si è verificato alcun conflitto di risorse. | |
| resource_fights_total | Conteggio | Il numero totale di risorse che vengono sincronizzate troppo spesso. Qualsiasi risultato superiore a zero indica un problema. Per ulteriori informazioni, consulta KNV2005: ResourceFightWarning. La metrica potrebbe non essere visualizzata nei risultati della query se non si è verificata alcuna contesa di risorse. |
Metriche del controller del gruppo di risorse
Resource Group Controller è un componente di Config Sync che tiene traccia delle risorse gestite e controlla se ogni singola risorsa è pronta o riconciliata. Sono disponibili le seguenti metriche.
| Nome | Tipo | Tag | Descrizione |
|---|---|---|---|
| rg_reconcile_duration_seconds | Distribuzione | stallreason | La distribuzione del tempo impiegato per riconciliare una CR ResourceGroup |
| resource_group_total | Ultimo valore | Il numero attuale di CR ResourceGroup | |
| resource_count | Ultimo valore | resourcegroup | Il numero totale di risorse monitorate da un ResourceGroup |
| ready_resource_count | Ultimo valore | resourcegroup | Il numero totale di risorse pronte in un ResourceGroup |
| resource_ns_count | Ultimo valore | resourcegroup | Il numero di spazi dei nomi utilizzati dalle risorse in un ResourceGroup |
| cluster_scoped_resource_count | Ultimo valore | resourcegroup | Il numero di risorse con ambito cluster in un ResourceGroup |
| crd_count | Ultimo valore | resourcegroup | Il numero di CRD in un ResourceGroup |
| kcc_resource_count | Ultimo valore | resourcegroup | Il numero totale di risorse KCC in un ResourceGroup |
| pipeline_error_observed | Ultimo valore | name, reconciler, component | Lo stato delle risorse personalizzate RootSync e RepoSync. Un valore pari a 1 indica un errore. |
Etichette delle metriche di Config Sync
Le etichette delle metriche possono essere utilizzate per aggregare i dati delle metriche in Cloud Monitoring e Prometheus. Sono selezionabili dall'elenco a discesa "Raggruppa per" nella console Monitoring.
Per saperne di più sull'etichetta Cloud Monitoring e sull'etichetta della metrica Prometheus, consulta Componenti del modello di metrica e Modello di dati Prometheus.
Etichette metriche
Le seguenti etichette vengono utilizzate dalle metriche di Config Sync e Resource Group Controller, disponibili durante il monitoraggio con Cloud Monitoring e Prometheus.
| Nome | Valori | Descrizione |
|---|---|---|
operation |
create, patch, update, delete | Il tipo di operazione eseguita |
status |
success, error | Lo stato di esecuzione di un'operazione |
reconciler |
rootsync, reposync | Il tipo di riconciliatore |
source |
parser, differ, remediator | L'origine dell'errore interno |
trigger |
retry, watchUpdate, managementConflict, resync, reimport | Il trigger di un evento di riconciliazione |
name |
Il nome del riconciliatore | Il nome del riconciliatore |
component |
parsing, source, sync, rendering, readiness | Il nome del componente / della fase attuale della riconciliazione |
container |
reconciler, git-sync | Il nome del contenitore |
resource |
cpu, memory | Il tipo di risorsa |
controller |
applier, remediator | Il nome del controller in un riconciliatore root o spazio dei nomi |
type |
Qualsiasi risorsa Kubernetes, ad esempio ClusterRole, Namespace, NetworkPolicy, Role e così via. | Il tipo di API Kubernetes |
commit |
---- | L'hash dell'ultimo commit sincronizzato |
Etichette risorse
Le metriche di Config Sync inviate a Prometheus e Cloud Monitoring hanno le seguenti etichette delle metriche impostate per identificare il pod di origine:
| Nome | Descrizione |
|---|---|
k8s.node.name |
Il nome del nodo che ospita un pod Kubernetes |
k8s.pod.namespace |
Lo spazio dei nomi del pod |
k8s.pod.uid |
L'UID del pod |
k8s.pod.ip |
L'IP del pod |
k8s.deployment.name |
Il nome del deployment proprietario del pod |
Le metriche di Config Sync inviate a Prometheus e Cloud Monitoring dai pod reconciler hanno anche le seguenti etichette delle metriche impostate per identificare RootSync o RepoSync utilizzati per configurare il riconciliatore:
| Nome | Descrizione |
|---|---|
configsync.sync.kind |
Il tipo di risorsa che configura questo riconciliatore: RootSync o RepoSync |
configsync.sync.name |
Il nome di RootSync o RepoSync che configura questo riconciliatore |
configsync.sync.namespace |
Lo spazio dei nomi di RootSync o RepoSync che configura questo riconciliatore |
Etichette delle risorse Cloud Monitoring
Le etichette delle risorse di Cloud Monitoring vengono utilizzate per indicizzare le metriche nello spazio di archiviazione, il che significa che hanno un effetto trascurabile sulla cardinalità, a differenza delle etichette delle metriche, in cui la cardinalità è un problema di prestazioni significativo. Per saperne di più, consulta la sezione Tipi di risorse monitorate.
Il tipo di risorsa k8s_container imposta le seguenti etichette risorse per identificare il contenitore di origine:
| Nome | Descrizione |
|---|---|
container_name |
Il nome del container |
pod_name |
Il nome del pod |
namespace_name |
Lo spazio dei nomi del pod |
location |
La regione o la zona del cluster che ospita il nodo |
cluster_name |
Il nome del cluster che ospita il nodo |
project |
L'ID del progetto che ospita il cluster |
Configurare il filtro delle metrica personalizzata
Puoi modificare le metriche personalizzate che Config Sync esporta in Prometheus, Cloud Monitoring e nel servizio di monitoraggio interno di Google. Modifica le metriche personalizzate per perfezionare le metriche incluse o configurare backend diversi.
Per modificare le metriche personalizzate, crea e poi modifica un ConfigMap denominato
otel-collector-custom. L'utilizzo di questo ConfigMap garantisce che Config Sync
non annulli le modifiche apportate. Se modifichi i ConfigMap
otel-collector o otel-collector-google-cloud, Config Sync
ripristina le modifiche.
Per esempi su come modificare questo ConfigMap, consulta Custom Metric Filtering nella documentazione open source di Config Sync.
Informazioni sulla metrica pipeline_error_observed
La metrica pipeline_error_observed è una metrica che può aiutarti a identificare rapidamente
le CR RepoSync o RootSync che non sono sincronizzate o contengono risorse che non sono
riconciliate con lo stato desiderato.
Per una sincronizzazione riuscita da parte di RootSync o RepoSync, le metriche con tutti i componenti (
rendering,source,sync,readiness) vengono osservate con valore 0.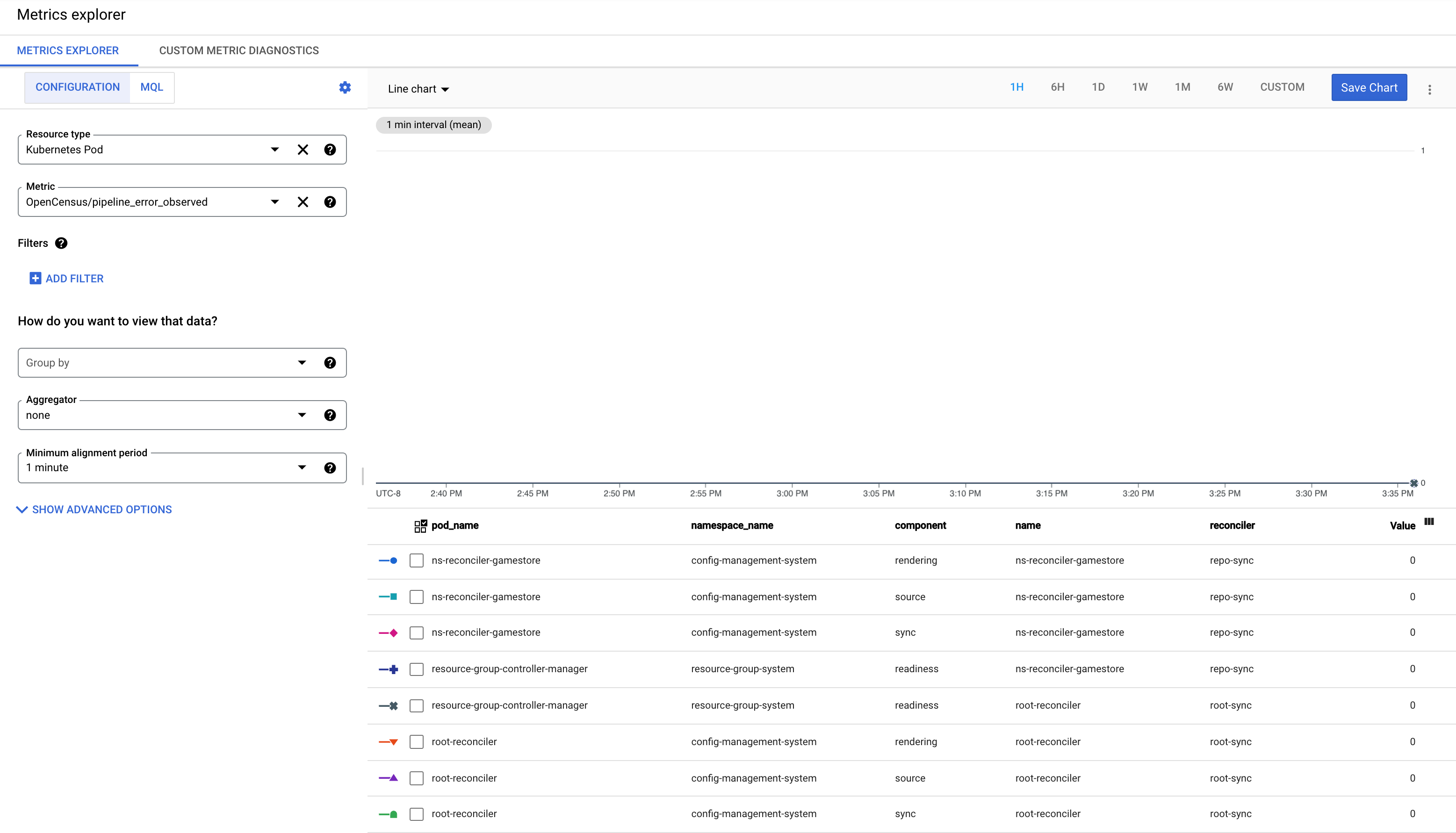
Quando l'ultimo commit non supera il rendering automatico, la metrica con il componente
renderingviene osservata con valore 1.Quando il check-out dell'ultimo commit rileva un errore o l'ultimo commit contiene una configurazione non valida, la metrica con il componente
sourceviene osservata con il valore 1.Quando una risorsa non viene applicata al cluster, la metrica con il componente
syncviene osservata con il valore 1.Quando una risorsa viene applicata, ma non raggiunge lo stato desiderato, la metrica con il componente
readinessviene osservata con il valore 1. Ad esempio, un deployment viene applicato al cluster, ma i pod corrispondenti non vengono creati correttamente.
Passaggi successivi
- Scopri di più su come monitorare gli oggetti RootSync e RepoSync.
- Scopri come utilizzare gli indicatori di livello del servizio (SLI) di Config Sync.