A página descreve as métricas do OpenTelemetry disponíveis para monitorizar os seus recursos do Config Sync.
Como o Config Sync recolhe métricas
O Config Sync usa o OpenCensus para criar e registar métricas e o OpenTelemetry para exportar as respetivas métricas para o Prometheus e o Cloud Monitoring. Os seguintes guias explicam como exportar métricas:
- Cloud Monitoring
- Prometheus
- Sistema de monitorização personalizado (não recomendado)
Para configurar o OpenTelemetry Collector, por predefinição, o Config Sync cria um ConfigMap denominado otel-collector. A implementação é executada no espaço de nomes config-management-monitoring.otel-collector
A criação do otel-collector ConfigMap configura o prometheus
exportador, que expõe um ponto final de métricas para o Prometheus analisar.
Quando executa a sincronização de configuração no GKE ou noutro ambiente do Kubernetes configurado com credenciais Google Cloud , a sincronização de configuração cria um ConfigMap denominado otel-collector-google-cloud. O
otel-collector-google-cloud substitui a configuração no
otel-collector ConfigMap. O Config Sync reverte todas as alterações aos ConfigMaps otel-collector ou otel-collector-google-cloud.
A criação do otel-collector-google-cloud ConfigMap também adiciona o exportador cloudmonitoring, que exporta para o Cloud Monitoring, e o exportador kubernetes, que exporta para o serviço de métricas interno da Google. O exportador
kubernetes envia métricas selecionadas e anonimizadas para a Google para ajudar a melhorar o
Config Sync.
O Cloud Monitoring armazena as métricas que lhe envia no seuGoogle Cloud projeto. Os exportadores cloudmonitoring e kubernetes usam a mesma
Google Cloud conta de serviço, que precisa de autorização do IAM para escrever
no Cloud Monitoring. Para configurar estas autorizações, consulte o artigo
Conceda autorização de escrita de métricas para o Cloud Monitoring.
Métricas do OpenTelemetry
O Config Sync e o Resource Group Controller recolhem as seguintes métricas com o OpenCensus e disponibilizam-nas através do OpenTelemetry Collector . A coluna Etiquetas apresenta etiquetas específicas da sincronização de configuração que são aplicáveis a cada métrica. As métricas com etiquetas representam várias medições, uma para cada combinação de valores de etiquetas.
Métricas do Config Sync
| Nome | Tipo | Etiquetas | Descrição |
|---|---|---|---|
| api_duration_seconds | Distribuição | operação, estado | A distribuição da latência das chamadas do servidor da API. |
| apply_duration_seconds | Distribuição | estado | A distribuição da latência da aplicação de recursos declarados a partir da fonte prioritária a um cluster. |
| apply_operations_total | Contagem | funcionamento, estado, controlador | O número total de operações que foram realizadas para sincronizar recursos da fonte de informação fidedigna com um cluster. |
| declared_resources | Último valor | O número de recursos declarados analisados a partir do Git. | |
| internal_errors_total | Contagem | fonte | O número total de erros internos encontrados pelo Config Sync. A métrica pode não aparecer nos resultados da consulta se não tiver ocorrido nenhum erro interno. |
| last_sync_timestamp | Último valor | estado | A data/hora da sincronização mais recente do Git. |
| parser_duration_seconds | Distribuição | status, trigger, source | A distribuição da latência de diferentes fases envolvidas na sincronização da fonte de dados fidedignos com um cluster. |
| pipeline_error_observed | Último valor | name, reconciler, component | O estado dos recursos personalizados RootSync e RepoSync. Um valor de 1 indica uma falha. |
| reconcile_duration_seconds | Distribuição | estado | A distribuição da latência dos eventos de conciliação processados pelo gestor de conciliação. |
| reconciler_errors | Último valor | component, errorclass | O número de erros encontrados durante a sincronização de recursos da fonte de dados fidedignos para um cluster. |
| remediate_duration_seconds | Distribuição | estado | A distribuição da latência dos eventos de conciliação do remediador. |
| resource_conflicts_total | Contagem | O número total de conflitos de recursos resultantes de uma incompatibilidade entre os recursos em cache e os recursos do cluster. A métrica pode não aparecer nos resultados da consulta se não tiver ocorrido nenhum conflito de recursos. | |
| resource_fights_total | Contagem | O número total de recursos que estão a ser sincronizados com demasiada frequência. Qualquer resultado superior a zero indica um problema. Para mais informações, consulte o artigo KNV2005: ResourceFightWarning. A métrica pode não aparecer nos resultados da consulta se não tiver ocorrido qualquer lance de recurso. |
Métricas do controlador do grupo de recursos
O controlador do grupo de recursos é um componente no Config Sync que monitoriza os recursos geridos e verifica se cada recurso individual está pronto ou reconciliado. Estão disponíveis as seguintes métricas.
| Nome | Tipo | Etiquetas | Descrição |
|---|---|---|---|
| rg_reconcile_duration_seconds | Distribuição | stallreason | A distribuição do tempo necessário para conciliar um CR ResourceGroup |
| resource_group_total | Último valor | O número atual de CRs ResourceGroup | |
| resource_count | Último valor | resourcegroup | O número total de recursos monitorizados por um ResourceGroup |
| ready_resource_count | Último valor | resourcegroup | O número total de recursos prontos num ResourceGroup |
| resource_ns_count | Último valor | resourcegroup | O número de espaços de nomes usados por recursos num ResourceGroup |
| cluster_scoped_resource_count | Último valor | resourcegroup | O número de recursos com âmbito de cluster num ResourceGroup |
| crd_count | Último valor | resourcegroup | O número de CRDs num ResourceGroup |
| kcc_resource_count | Último valor | resourcegroup | O número total de recursos do KCC num ResourceGroup |
| pipeline_error_observed | Último valor | name, reconciler, component | O estado dos recursos personalizados RootSync e RepoSync. Um valor de 1 indica uma falha. |
Etiquetas de métricas do Config Sync
As etiquetas de métricas podem ser usadas para agregar dados de métricas no Cloud Monitoring e no Prometheus. São selecionáveis na lista pendente "Agrupar por" na consola de monitorização.
Para mais informações sobre a etiqueta do Cloud Monitoring e a etiqueta da métrica do Prometheus, consulte os componentes do modelo de métricas e o modelo de dados do Prometheus.
Etiquetas de métricas
As seguintes etiquetas são usadas pelas métricas do Config Sync e do Resource Group Controller, disponíveis quando monitorizadas com o Cloud Monitoring e o Prometheus.
| Nome | Valores | Descrição |
|---|---|---|
operation |
criar, patch, atualizar, eliminar | O tipo de operação realizada |
status |
success, error | O estado de execução de uma operação |
reconciler |
rootsync, reposync | O tipo de reconciliador |
source |
analisador, diferenciador, remediador | A origem do erro interno |
trigger |
retry, watchUpdate, managementConflict, resync, reimport | O acionador de um evento de conciliação |
name |
O nome do reconciliador | O nome do conciliador |
component |
Análise, origem, sincronização, renderização e disponibilidade | O nome do componente / fase atual da conciliação |
container |
reconciler, git-sync | O nome do contentor |
resource |
cpu, memória | O tipo de recurso |
controller |
applier, remediator | O nome do controlador num reconciliador de raiz ou espaço de nomes |
type |
Qualquer recurso do Kubernetes, por exemplo, ClusterRole, Namespace, NetworkPolicy, Role, etc. | O tipo de API Kubernetes |
commit |
---- | O hash da consolidação sincronizada mais recente |
Etiquetas de recursos
As métricas do Config Sync enviadas para o Prometheus e o Cloud Monitoring têm as seguintes etiquetas de métricas definidas para identificar o pod de origem:
| Nome | Descrição |
|---|---|
k8s.node.name |
O nome do nó que aloja um pod do Kubernetes |
k8s.pod.namespace |
O espaço de nomes do agrupamento |
k8s.pod.uid |
O UID do agrupamento |
k8s.pod.ip |
O IP do agrupamento |
k8s.deployment.name |
O nome da implementação proprietária do pod |
As métricas do Config Sync enviadas para o Prometheus e o Cloud Monitoring a partir dos reconcilerpods também têm as seguintes etiquetas de métricas definidas para identificar o RootSync ou o RepoSync usado para configurar o reconciliador:
| Nome | Descrição |
|---|---|
configsync.sync.kind |
O tipo de recurso que configura este reconciliador: RootSync ou RepoSync |
configsync.sync.name |
O nome do RootSync ou RepoSync que configura este reconciliador |
configsync.sync.namespace |
O espaço de nomes do RootSync ou RepoSync que configura este reconciliador |
Etiquetas de recursos do Cloud Monitoring
As etiquetas de recursos do Cloud Monitoring são usadas para indexar métricas no armazenamento, o que significa que têm um efeito insignificante na cardinalidade, ao contrário das etiquetas de métricas, em que a cardinalidade é uma preocupação de desempenho significativa. Consulte a secção Tipos de recursos monitorizados para mais informações.
O tipo de recurso k8s_container define as seguintes etiquetas de recursos para identificar o contentor de origem:
| Nome | Descrição |
|---|---|
container_name |
O nome do contentor |
pod_name |
O nome do agrupamento |
namespace_name |
O espaço de nomes do agrupamento |
location |
A região ou a zona do cluster que aloja o nó |
cluster_name |
O nome do cluster que aloja o nó |
project |
O ID do projeto que aloja o cluster |
Configure a filtragem de métricas personalizadas
Pode ajustar as métricas personalizadas que o Config Sync exporta para o Prometheus, o Cloud Monitoring e o serviço de monitorização interno da Google. Ajuste as métricas personalizadas para otimizar as métricas incluídas ou configurar diferentes backends.
Para modificar métricas personalizadas, crie e, em seguida, edite um ConfigMap denominado
otel-collector-custom. A utilização deste ConfigMap garante que o Config Sync não reverte nenhuma das modificações que fizer. Se modificar os ConfigMaps
otel-collector ou otel-collector-google-cloud, o Config Sync
reverte todas as alterações.
Para ver exemplos de como ajustar este ConfigMap, consulte a secção Filtragem de métricas personalizadas na documentação de código aberto do Config Sync.
Compreenda a métrica pipeline_error_observed
A métrica pipeline_error_observed é uma métrica que pode ajudar a identificar rapidamente CRs do RepoSync ou RootSync que não estão sincronizados ou contêm recursos que não estão reconciliados com o estado pretendido.
Para uma sincronização bem-sucedida por um RootSync ou um RepoSync, as métricas com todos os componentes (
rendering,source,sync,readiness) são observadas com o valor 0.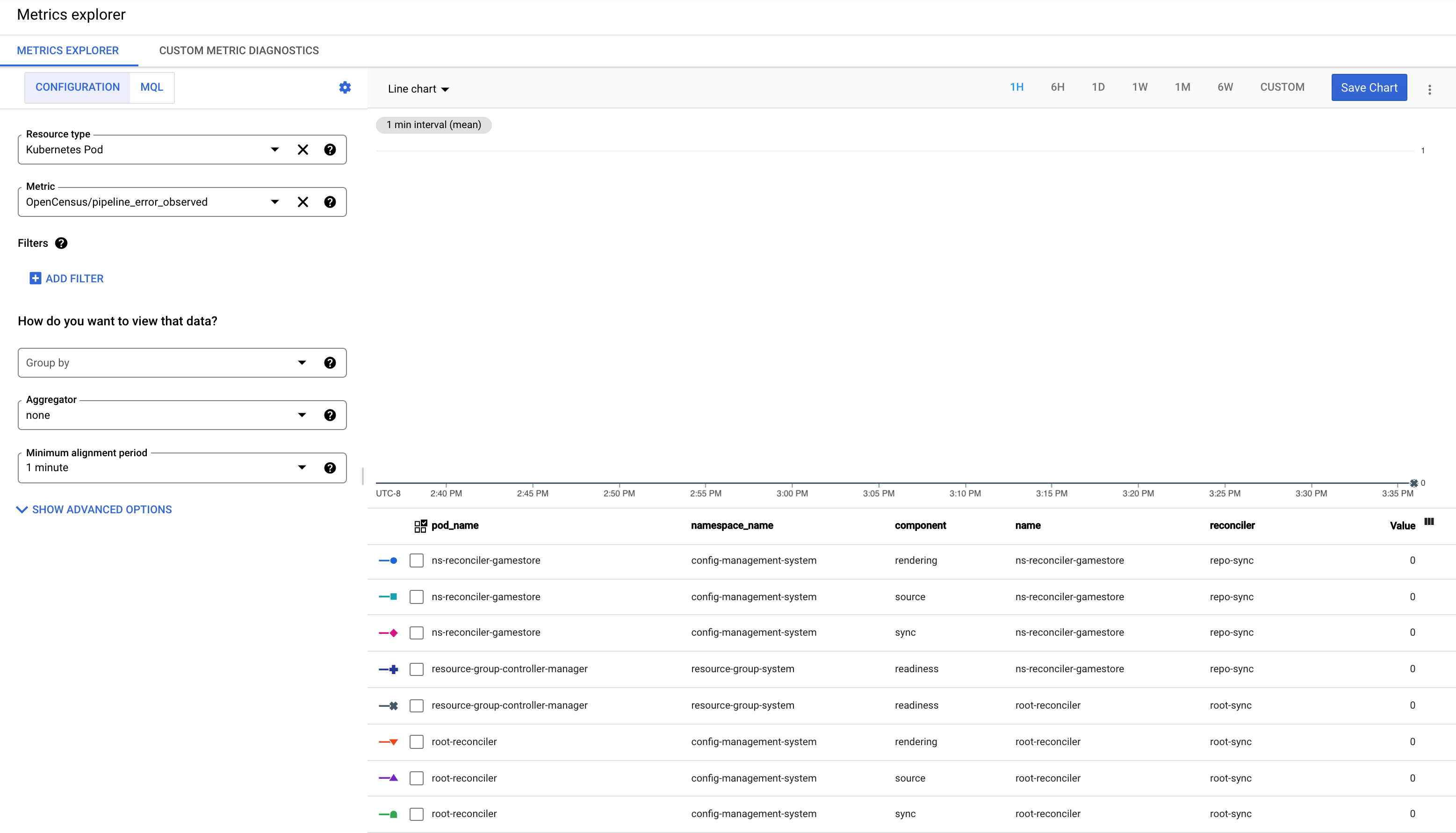
Quando a confirmação mais recente falha na renderização automática, a métrica com o componente
renderingé observada com o valor 1.Quando a obtenção da confirmação mais recente encontra um erro ou a confirmação mais recente contém uma configuração inválida, a métrica com o componente
sourceé observada com o valor 1.Quando não é possível aplicar um recurso ao cluster, a métrica com o componente
syncé observada com o valor 1.Quando um recurso é aplicado, mas não atinge o estado pretendido, a métrica com o componente
readinessé observada com o valor 1. Por exemplo, uma implementação é aplicada ao cluster, mas os pods correspondentes não são criados com êxito.
O que se segue?
- Saiba como monitorizar objetos RootSync e RepoSync.
- Saiba como usar os SLIs do Config Sync.