Cette page constitue un point de départ pour vous aider à planifier et à concevoir des pipelines CI/CD GitOps pour Kubernetes. GitOps, ainsi que des outils tels que Config Sync, offre des avantages tels qu'une meilleure stabilité, une meilleure lisibilité et une automatisation du code.
GitOps est une approche en plein essor pour gérer la configuration Kubernetes à grande échelle. En fonction de vos exigences pour votre pipeline CI/CD, il existe de nombreuses options pour concevoir et organiser votre application et votre code de configuration. En apprenant quelques bonnes pratiques GitOps, vous pouvez créer une architecture stable, bien organisée et sécurisée.
Cette page s'adresse aux administrateurs, aux architectes et aux opérateurs qui souhaitent implémenter GitOps dans leur environnement. Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenu Google Cloud, consultez la section Rôles utilisateur et tâches courantes de GKE Enterprise.
Organiser vos dépôts
Lorsque vous configurez votre architecture GitOps, séparez vos dépôts en fonction des types de fichiers de configuration stockés dans chacun d'eux. De manière générale, vous aurez probablement besoin d'au moins quatre types de dépôts :
- Un dépôt de packages pour des groupes de configurations associées.
- Un dépôt de plate-forme pour la configuration à l'échelle du parc pour les clusters et les espaces de noms.
- Un dépôt de configuration d'application.
- Un dépôt de code de l'application.
Le schéma suivant illustre la disposition de ces dépôts :
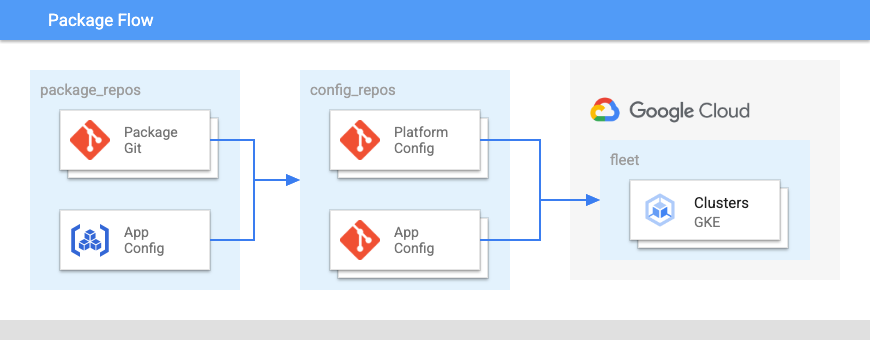
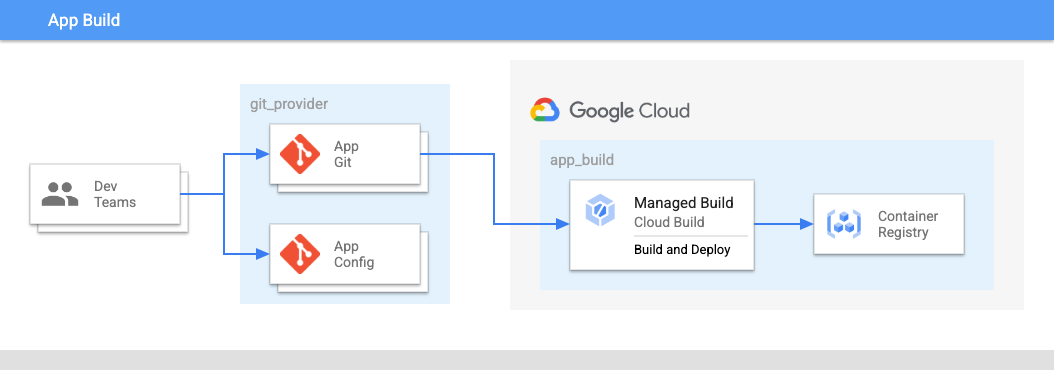
Dans la figure 2 :
- Les équipes de développement transfèrent le code des applications et des configurations d'applications dans un dépôt.
- Le code des applications et des configurations est stocké au même endroit, et les équipes d'applications contrôlent ces dépôts.
- Les équipes d'application transfèrent le code dans un build.
Utiliser un dépôt de packages privé et centralisé
Utilisez un dépôt central pour les packages publics ou internes, tels que les graphiques Helm, afin d'aider les équipes à trouver des packages. Par exemple, si le dépôt est structuré de manière logique ou contient un readme, l'utilisation de dépôts de packages privés et centralisés peut aider les équipes à trouver rapidement des informations. Vous pouvez utiliser des services tels que Artifact Registry ou des dépôts Git pour organiser votre dépôt central.
Par exemple, l'équipe de plate-forme de votre organisation peut mettre en œuvre des règles qui permettent aux équipes d'applications d'utiliser des packages uniquement à partir du dépôt central.
Vous pouvez limiter les autorisations d'écriture sur le dépôt à un petit nombre d'ingénieurs. Le reste de l'organisation peut disposer d'un accès en lecture. Nous vous recommandons de mettre en œuvre un processus de promotion des packages dans le dépôt central et de diffusion des mises à jour.
Bien que la gestion d'un dépôt central puisse entraîner des frais supplémentaires, car quelqu'un doit le gérer et qu'il ajoute un processus supplémentaire pour les équipes d'applications, cette approche présente de nombreux avantages :
- Une équipe centrale peut choisir d'ajouter des packages publics à une cadence définie, ce qui permet d'éviter les problèmes de connectivité ou de perte d'utilisateurs en amont.
- Des examinateurs humains et automatisés peuvent vérifier les packages pour détecter les problèmes avant de les rendre largement disponibles.
- Le dépôt central permet aux équipes de découvrir ce qui est utilisé et ce qui est compatible. Par exemple, les équipes peuvent trouver le déploiement Redis standard stocké dans le dépôt central.
- Vous pouvez automatiser les modifications apportées aux packages en amont pour vous assurer qu'ils respectent les normes internes telles que les valeurs par défaut, l'ajout de libellés et les dépôts d'images de conteneurs.
Créer des dépôts WET
WET signifie "Write Everything Twice" (Écrire tout deux fois). Elle s'oppose à la règle DRY, qui signifie "Don't Repeat Yourself" (Ne pas se répéter). Ces approches représentent deux types de fichiers de configuration différents :
- Les configurations DRY, où un seul fichier de configuration subit une action de transformation pour renseigner les champs avec des valeurs différentes pour différents environnements. Par exemple, vous pouvez avoir une configuration de cluster partagée qui contient une région ou des paramètres de sécurité diffférents pour différents environnements.
- Les configurations WET (également appelées configurations "entièrement hydratées"), où chaque fichier de configuration est représentatif de l'état final.
Bien que les dépôts WET puissent entraîner la répétition de certains fichiers de configuration, ils présentent les avantages suivants pour un workflow GitOps :
- Les membres de l'équipe peuvent ainsi examiner plus facilement les modifications.
- Aucun traitement n'est nécessaire pour afficher l'état souhaité d'un fichier de configuration.
Tester plus tôt lors de la validation des configurations
Attendre que Config Sync commence la synchronisation pour vérifier les problèmes peut créer des commits Git inutiles et une longue boucle de rétroaction. De nombreux problèmes peuvent être détectés avant qu'une configuration ne soit appliquée à un cluster à l'aide des fonctions de validation kpt.
Bien qu'il soit nécessaire d'ajouter des outils et une logique supplémentaires à votre processus de validation, effectuer des tests avant l'application des configurations présente les avantages suivants :
- L'affichage des modifications de configuration dans une demande de modification peut vous aider à éviter l'inscription d'erreurs dans un dépôt.
- Cela permet de réduire l'impact des problèmes dans les configurations partagées.
Utiliser des dossiers au lieu de branches
Utilisez des dossiers pour les variantes de fichiers de configuration au lieu de branches. Avec les dossiers, vous pouvez utiliser la commande tree pour afficher les variantes. Avec les branches, vous ne pouvez pas savoir si le delta entre une branche de production et une branche de développement correspond à une modification de configuration à venir ou à une différence permanente entre les environnements prod et dev.
Le principal inconvénient de cette approche est que l'utilisation de dossiers ne vous permet pas de promouvoir les modifications de configuration à l'aide d'une demande de modification de ces mêmes fichiers. Toutefois, l'utilisation de dossiers au lieu de branches présente les avantages suivants :
- La découverte des dossiers est plus facile que celle des branches.
- Il est possible d'effectuer une comparaison de dossiers avec de nombreux outils de ligne de commande et d'interface graphique, tandis que la comparaison de branches est moins courante en dehors des fournisseurs Git.
- Il est plus facile d'effectuer une comparaison des différences permanentes et des différences non promues avec les dossiers.
- Vous pouvez déployer des modifications sur plusieurs clusters et espaces de noms dans une seule demande de modification, tandis que les branches nécessitent plusieurs demandes de modification sur différentes branches.
Minimiser l'utilisation de ClusterSelectors
ClusterSelectors vous permet d'appliquer certaines parties d'une configuration à un sous-ensemble de clusters. Au lieu de configurer un objet RootSync ou RepoSync, vous pouvez modifier la ressource appliquée ou ajouter des libellés aux clusters. Bien que ce soit un moyen simple d'ajouter des traits à un cluster, le nombre de ClusterSelectors augmentant au fil du temps, il peut devenir difficile de comprendre l'état final du cluster.
Étant donné que Config Sync vous permet de synchroniser plusieurs objets RootSync et RepoSync à la fois, vous pouvez ajouter la configuration appropriée à un dépôt distinct, puis la synchroniser avec les clusters de votre choix. Cela permet de mieux comprendre l'état final du cluster. Vous pouvez assembler les configurations du cluster dans un dossier au lieu d'appliquer ces décisions de configuration directement sur le cluster.
Éviter de gérer des jobs avec Config Sync
Dans la plupart des cas, les jobs et les autres tâches ponctuelles doivent être gérées par un service qui gère leur cycle de vie. Vous pouvez ensuite gérer ce service avec Config Sync, au lieu de gérer les jobs eux-mêmes.
Bien que Config Sync puisse appliquer des jobs à votre place, ceux-ci ne sont pas adaptés aux déploiements GitOps pour les raisons suivantes :
Champs immuables : de nombreux champs de type "Job" sont immuables. Pour modifier un champ immuable, l'objet doit être supprimé et recréé. Toutefois, Config Sync ne supprime pas votre objet, sauf si vous le supprimez de la source.
Exécution involontaire de tâches : si vous synchronisez une tâche à l'aide de Config Sync et que cette tâche est ensuite supprimée du cluster, Config Sync prend en compte cette dérive par rapport à l'état choisi et recrée le Job. Si vous spécifiez une durée de vie (TTL) de job, Config Sync supprime automatiquement le job, puis le recrée et le redémarre automatiquement, jusqu'à ce que vous le supprimiez de la source de référence.
Problèmes de rapprochement : Config Sync attend normalement que les objets soient rapprochés après avoir été appliqués. Toutefois, les tâches sont considérées comme rapprochées lorsqu'elles ont commencé à s'exécuter. Cela signifie que Config Sync n'attend pas que la tâche soit terminée avant de continuer à appliquer d'autres objets. Toutefois, si la tâche échoue ultérieurement, cela est considéré comme un échec du rapprochement. Dans certains cas, cela peut empêcher la synchronisation d'autres ressources et provoquer des erreurs jusqu'à ce que vous les corrigiez. Dans d'autres cas, la synchronisation peut réussir et seul le rapprochement échoue.
Pour ces raisons, nous vous déconseillons de synchroniser des jobs avec Config Sync.
Utiliser des dépôts non structurés
Config Sync prend en charge deux structures pour l'organisation d'un dépôt : non structurée et hiérarchique.
L'approche non structurée est recommandée, car elle vous permet d'organiser un dépôt de la manière qui vous convient le mieux.
En revanche, les dépôts hiérarchiques appliquent une structure spécifique, comme les définitions de ressources personnalisées (CRD) dans un répertoire cluster.
Cela peut entraîner des problèmes lorsque vous devez partager des configurations. Par exemple, si une équipe publie un package contenant un CRD, une autre équipe qui doit utiliser ce package doit déplacer le CRD dans un répertoire cluster, ce qui alourdit le processus.
L'utilisation d'un dépôt non structuré facilite grandement le partage et la réutilisation des packages de configuration. Toutefois, sans processus ou consignes définis pour organiser les dépôts, les structures de dépôt peuvent varier d'une équipe à l'autre, ce qui peut rendre l'implémentation d'outils à l'échelle du parc plus difficile.
Pour savoir comment convertir un dépôt hiérarchique, consultez la section Convertir un dépôt hiérarchique en dépôt non structuré.
Séparer les dépôts de code et de configuration
Lors du scaling à la hausse d'un dépôt "mono", il nécessite une compilation spécifique à chaque dossier. Les autorisations et les préoccupations des personnes qui travaillent sur le code et sur la configuration du cluster sont généralement différentes.
La séparation des dépôts de code et de configuration présente les avantages suivants :
- Évite les commits en boucle. Par exemple, un commit dans un dépôt de code peut déclencher une requête CI, qui peut produire une image, qui nécessite ensuite un commit de code.
- Le nombre de commits requis peut devenir un fardeau pour les membres de l'équipe qui contribuent.
- Vous pouvez utiliser différentes autorisations pour les personnes travaillant sur le code de l'application et la configuration du cluster.
La séparation des dépôts de code et de configuration présente les inconvénients suivants :
- Réduit la découverte de la configuration de l'application, car elle ne se trouve pas dans le même dépôt que le code de l'application.
- La gestion de nombreux dépôts peut être chronophage.
Utiliser des dépôts distincts pour isoler les modifications
Lors du scaling à la hausse d'un dépôt "mono", différentes autorisations sont requises sur différents dossiers. Par conséquent, la séparation des dépôts permet de définir des limites de sécurité entre les configurations de la sécurité, de la plate-forme et de l'application. Il est également judicieux de séparer les dépôts de production et les dépôts hors production.
Bien que la gestion de nombreux dépôts puisse être une tâche importante en soi, l'isolation de différents types de configuration dans différents dépôts présente les avantages suivants :
- Dans une organisation qui dispose d'équipes de plate-forme, de sécurité et d'application, la cadence des modifications et les autorisations sont différentes.
- Les autorisations restent au niveau du dépôt. Les fichiers
CODEOWNERSpermettent aux organisations de limiter l'autorisation d'écriture tout en autorisant l'autorisation de lecture. - Config Sync accepte plusieurs synchronisations par espace de noms, ce qui peut avoir un effet similaire au fait d'obtenir des fichiers à partir de plusieurs dépôts.
Épingler des versions de package
Que vous utilisiez Helm ou Git, vous devez épingler la version du package de configuration sur une version qui n'a pas été accidentellement déplacée sans déploiement explicite.
Bien que cela ajoute des vérifications supplémentaires à vos déploiements lorsqu'une configuration partagée est mise à jour, cela réduit le risque que les mises à jour partagées aient un impact plus important que prévu.
Utiliser Workload Identity Federation for GKE
Vous pouvez activer Workload Identity Federation for GKE sur les clusters GKE. Cela permet aux charges de travail Kubernetes d'accéder aux services Google de manière sécurisée et gérable.
Bien que certains services non Google Cloud, tels que GitHub et GitLab, ne soient pas compatibles avec Workload Identity Federation for GKE, vous devez essayer de l'utiliser dans la mesure du possible, car il offre une sécurité accrue et réduit la complexité de la gestion des secrets et des mots de passe.