En esta página se ofrece un punto de partida para ayudarte a planificar y diseñar las canalizaciones de CI/CD GitOps para Kubernetes. GitOps, junto con herramientas como Config Sync, ofrece ventajas como una mayor estabilidad del código, una mejor legibilidad y automatización.
GitOps es un enfoque que está creciendo rápidamente para gestionar la configuración de Kubernetes a gran escala. En función de los requisitos de tu flujo de procesamiento de CI/CD, hay muchas opciones para diseñar y organizar el código de tu aplicación y configuración. Si aprendes algunas prácticas recomendadas de GitOps, puedes crear una arquitectura estable, bien organizada y segura.
Esta página está dirigida a administradores, arquitectos y operadores que quieran implementar GitOps en su entorno. Para obtener más información sobre los roles habituales y las tareas de ejemplo a las que hacemos referencia en el contenido, consulta Roles y tareas habituales de los usuarios de GKE. Google Cloud
Organizar los repositorios
Al configurar tu arquitectura de GitOps, separa tus repositorios en función de los tipos de archivos de configuración almacenados en cada uno. En términos generales, puede considerar al menos cuatro tipos de repositorios:
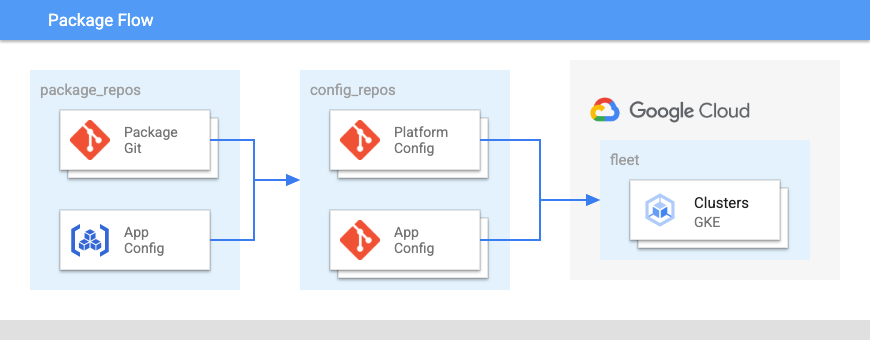
- Un repositorio de paquetes para grupos de configuraciones relacionadas.
- Un repositorio de plataforma para la configuración de toda la flota de clústeres y espacios de nombres.
- Un repositorio de configuración de aplicaciones.
- Un repositorio de código de aplicación.
En el siguiente diagrama se muestra la estructura de estos repositorios:
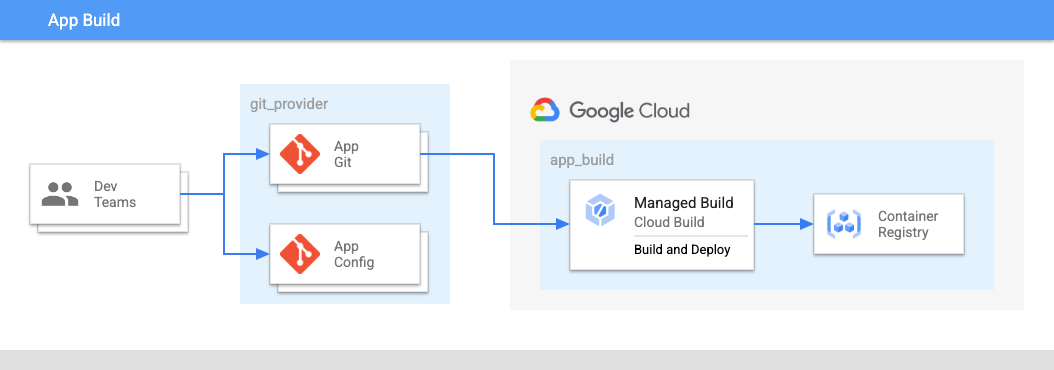
En la imagen 2:
- Los equipos de desarrollo envían el código de las aplicaciones y las configuraciones de las aplicaciones a un repositorio.
- El código de las aplicaciones y las configuraciones se almacena en el mismo lugar y los equipos de aplicaciones tienen control sobre estos repositorios.
- Los equipos de aplicaciones envían código a una compilación.
Usar un repositorio de paquetes privado y centralizado
Usa un repositorio central para paquetes públicos o internos, como gráficos de Helm,para ayudar a los equipos a encontrar paquetes. Por ejemplo, si el repositorio está estructurado de forma lógica o contiene un readme, usar repositorios de paquetes privados y centralizados puede ayudar a los equipos a encontrar información rápidamente. Puedes usar servicios como Artifact Registry o repositorios de Git para organizar tu repositorio central.
Por ejemplo, el equipo de la plataforma de tu organización puede implementar políticas en las que los equipos de aplicaciones solo puedan usar paquetes del repositorio central.
Puedes limitar los permisos de escritura del repositorio a un pequeño número de ingenieros. El resto de la organización puede tener acceso de lectura. Te recomendamos que implementes un proceso para promocionar paquetes en el repositorio central y difundir actualizaciones.
Aunque gestionar un repositorio central puede suponer un esfuerzo adicional, ya que alguien debe mantenerlo y se añade un proceso adicional para los equipos de aplicaciones, este enfoque tiene muchas ventajas:
- Un equipo central puede añadir paquetes públicos a un ritmo definido, lo que ayuda a evitar que se rompan por problemas de conectividad o cambios en el upstream.
- Una combinación de revisores humanos y automatizados puede comprobar si hay problemas en los paquetes antes de que estén disponibles para todos los usuarios.
- El repositorio central ofrece a los equipos una forma de descubrir qué se está usando y qué se admite. Por ejemplo, los equipos pueden encontrar la implementación estándar de Redis almacenada en el repositorio central.
- Puedes automatizar los cambios en los paquetes upstream para asegurarte de que cumplen los estándares internos, como los valores predeterminados, la adición de etiquetas y los repositorios de imágenes de contenedor.
Crear repositorios WET
WET significa "Write Everything Twice" (escribe todo dos veces). Se diferencia de DRY, que significa "No te repitas". Estos enfoques representan dos tipos diferentes de archivos de configuración:
- Configuraciones DRY, en las que un único archivo de configuración se somete a una acción de transformación para rellenar los campos con valores diferentes en distintos entornos. Por ejemplo, puedes tener una configuración de clúster compartida que se rellene con una región o una configuración de seguridad diferentes para distintos entornos.
- Configuraciones WET (o "totalmente hidratadas"), en las que cada archivo de configuración representa el estado final.
Aunque los repositorios WET pueden dar lugar a algunos archivos de configuración repetidos, tienen las siguientes ventajas para un flujo de trabajo de GitOps:
- Los miembros del equipo pueden revisar los cambios más fácilmente.
- No es necesario ningún procesamiento para ver el estado previsto de un archivo de configuración.
Hacer pruebas antes al validar configuraciones
Si esperas a que Config Sync empiece a sincronizar para comprobar si hay problemas, se pueden crear confirmaciones de Git innecesarias y un bucle de comentarios largo. Se pueden detectar muchos problemas antes de aplicar una configuración a un clúster mediante las kptfunciones de validador.
Aunque debes añadir herramientas y lógica adicionales a tu proceso de confirmación, probar antes de aplicar las configuraciones tiene las siguientes ventajas:
- Mostrar los cambios de configuración en una solicitud de cambio puede ayudar a evitar que se produzcan errores en un repositorio.
- Reduce el impacto de los problemas en las configuraciones compartidas.
Usar carpetas en lugar de ramas
Usa carpetas para las variantes de los archivos de configuración en lugar de ramas. Con las carpetas, puedes usar el comando tree para ver las variantes. Con las ramas, no puedes saber si la diferencia entre una rama de producción y una de desarrollo es un cambio de configuración que se va a producir o una diferencia permanente entre los entornos prod y dev.
El principal inconveniente de este método es que no permite promocionar los cambios de configuración mediante una solicitud de cambio en los mismos archivos. Sin embargo, usar carpetas en lugar de ramas tiene las siguientes ventajas:
- Es más fácil descubrir carpetas que ramas.
- Se pueden comparar carpetas con muchas herramientas de CLI y GUI, mientras que la comparación de ramas es menos habitual fuera de los proveedores de Git.
- Con las carpetas, es más fácil distinguir entre las diferencias permanentes y las que no se han promocionado.
- Puedes implementar cambios en varios clústeres y espacios de nombres en una sola solicitud de cambio, mientras que las ramas requieren varias solicitudes de cambio en diferentes ramas.
Minimizar el uso de ClusterSelectors
ClusterSelectors te permite aplicar determinadas partes de una configuración a un subconjunto de clústeres. En lugar de configurar un objeto RootSync o RepoSync,
puedes modificar el recurso que se está aplicando o añadir etiquetas
a los clústeres. Aunque es una forma sencilla de añadir traits a un clúster, a medida que aumenta el número de ClusterSelectors, puede resultar complicado entender el estado final del clúster.
Como Config Sync te permite sincronizar varios objetos RootSync y RepoSync a la vez, puedes añadir la configuración pertinente a un repositorio independiente y, a continuación, sincronizarla con los clústeres que quieras. De esta forma, es más fácil entender el estado final del clúster y puedes reunir las configuraciones del clúster en una carpeta en lugar de aplicar esas decisiones de configuración directamente en el clúster.
Evitar gestionar trabajos con Config Sync
En la mayoría de los casos, los trabajos y otras tareas situacionales deben gestionarse mediante un servicio que se encargue de su gestión del ciclo de vida. Después, puedes gestionar ese servicio con Config Sync en lugar de con los trabajos.
Aunque Config Sync puede aplicar trabajos por ti, estos no son adecuados para las implementaciones de GitOps por los siguientes motivos:
Campos inmutables: muchos campos de Job son inmutables. Para cambiar un campo inmutable, el objeto debe eliminarse y volver a crearse. Sin embargo, Config Sync no elimina el objeto a menos que lo quites del origen.
Ejecución no intencionada de Jobs: si sincronizas un Job con Config Sync y, a continuación, se elimina del clúster, Config Sync considera que se ha producido una desviación del estado elegido y vuelve a crear el Job. Si especificas un tiempo de vida (TTL) del trabajo, Config Sync elimina automáticamente el trabajo y lo vuelve a crear y reiniciar automáticamente hasta que lo elimines de la fuente de información veraz.
Problemas de conciliación: Config Sync suele esperar a que los objetos se concilien después de aplicarse. Sin embargo, los trabajos se consideran conciliados cuando han empezado a ejecutarse. Esto significa que Config Sync no espera a que se complete el trabajo antes de seguir aplicando otros objetos. Sin embargo, si el trabajo falla más adelante, se considera que no se ha podido conciliar. En algunos casos, esto puede impedir que se sincronicen otros recursos y provocar errores hasta que lo solucione. En otros casos, la sincronización puede completarse correctamente, pero solo falla la conciliación.
Por estos motivos, no recomendamos sincronizar los trabajos con Config Sync.
Usar repositorios sin estructurar
Config Sync admite dos estructuras para organizar un repositorio: sin estructurar y jerárquica.
Es el enfoque recomendado porque te permite organizar un repositorio de la forma que más te convenga.
En cambio, los repositorios jerárquicos aplican una estructura específica, como las definiciones de recursos personalizadas (CRDs) en un directorio cluster.
Esto puede causar problemas cuando necesites compartir configuraciones. Por ejemplo, si un equipo publica un paquete que contiene un CRD, otro equipo que necesite usar ese paquete tendría que mover el CRD a un directorio cluster, lo que añadiría más sobrecarga al proceso.
Si usas un repositorio sin estructurar, será mucho más fácil compartir y reutilizar paquetes de configuración. Sin embargo, si no se definen procesos ni directrices para organizar los repositorios, las estructuras de los repositorios pueden variar entre los equipos, lo que puede dificultar la implementación de herramientas en toda la flota.
Para saber cómo convertir un repositorio jerárquico, consulta Convertir un repositorio jerárquico en un repositorio no estructurado.
Repositorios de código y configuración independientes
Al ampliar un monorepositorio, se necesita una compilación específica para cada carpeta. Los permisos y las preocupaciones de las personas que trabajan en el código y en la configuración del clúster suelen ser diferentes.
Separar los repositorios de código y de configuración tiene las siguientes ventajas:
- Evita las confirmaciones en bucle. Por ejemplo, si se confirma un repositorio de código, se puede activar una solicitud de integración continua, que puede generar una imagen, que a su vez requiere una confirmación de código.
- El número de confirmaciones necesarias puede convertirse en una carga para los miembros del equipo que contribuyen.
- Puedes usar diferentes permisos para las personas que trabajan en el código de la aplicación y en la configuración del clúster.
Separar los repositorios de código y de configuración tiene los siguientes inconvenientes:
- Reduce la detección de la configuración de la aplicación, ya que no se encuentra en el mismo repositorio que el código de la aplicación.
- Gestionar muchos repositorios puede llevar mucho tiempo.
Usa repositorios independientes para aislar los cambios
Al ampliar un monorepositorio, se necesitan permisos diferentes en carpetas diferentes. Por este motivo, separar los repositorios permite establecer límites de seguridad entre la configuración de seguridad, la plataforma y la aplicación. También es recomendable separar los repositorios de producción y los que no son de producción.
Aunque gestionar muchos repositorios puede ser una tarea compleja, aislar diferentes tipos de configuración en distintos repositorios tiene las siguientes ventajas:
- En una organización con equipos de plataforma, seguridad y aplicaciones, la cadencia de los cambios y los permisos es diferente.
- Los permisos se mantienen a nivel de repositorio.
CODEOWNERSarchivos Permiten que las organizaciones limiten el permiso de escritura y, al mismo tiempo, mantengan el permiso de lectura. - Config Sync admite varias sincronizaciones por espacio de nombres, lo que puede conseguir un efecto similar al de obtener archivos de varios repositorios.
Fijar versiones de paquetes
Tanto si usas Helm como Git, debes fijar la versión del paquete de configuración en algo que no se actualice por error sin una implementación explícita.
Aunque esto añade comprobaciones adicionales a tus lanzamientos cuando se actualiza una configuración compartida, se reduce el riesgo de que las actualizaciones compartidas tengan un impacto mayor de lo previsto.
Usar Workload Identity Federation para GKE
Puedes habilitar Workload Identity Federation for GKE en clústeres de GKE, lo que permite que las cargas de trabajo de Kubernetes accedan a los servicios de Google de forma segura y gestionable.
Aunque algunos servicios que no son deGoogle Cloud , como GitHub y GitLab, no admiten Workload Identity Federation para GKE, debes intentar usar Workload Identity Federation para GKE siempre que sea posible debido al aumento de la seguridad y a la reducción de la complejidad de la gestión de secretos y contraseñas.