Saat Anda membuat grafik throughput dari waktu ke waktu saat variabel lain diubah, biasanya Anda akan melihat peningkatan throughput hingga throughput mencapai titik kelelahan resource.
Gambar berikut menunjukkan grafik penskalaan throughput yang umum. Seiring bertambahnya jumlah klien, workload dan throughput akan meningkat hingga semua resource habis.
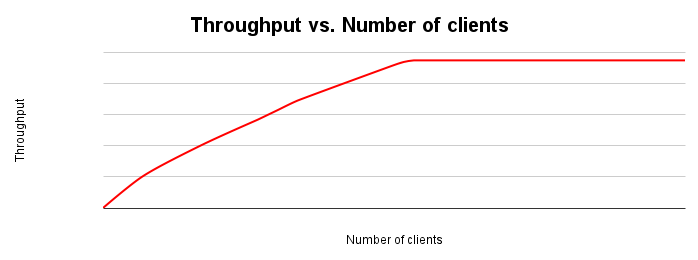
Idealnya, saat Anda menggandakan beban pada sistem, throughput juga harus berlipat ganda. Dalam praktiknya, akan ada persaingan pada resource yang menyebabkan peningkatan throughput yang lebih kecil. Pada titik tertentu, kelelahan atau persaingan resource akan menyebabkan throughput menjadi datar atau bahkan menurun. Jika Anda mengoptimalkan throughput, ini adalah poin penting untuk diidentifikasi karena mendorong upaya Anda ke tempat untuk menyesuaikan aplikasi atau sistem database guna meningkatkan throughput.
Alasan umum mengapa throughput menjadi stabil atau menurun meliputi:
- Kehabisan resource CPU di server database
- Penggunaan sumber daya CPU yang berlebihan di klien sehingga server database tidak dikirimi lebih banyak pekerjaan
- Pertentangan kunci database
- Waktu tunggu I/O saat data melebihi ukuran kumpulan buffer Postgres
- Waktu tunggu I/O karena pemanfaatan mesin penyimpanan
- Bottleneck bandwidth jaringan yang menampilkan data ke klien
Latensi dan throughput berbanding terbalik. Saat latensi meningkat, throughput menurun. Secara intuitif, hal ini masuk akal. Saat hambatan mulai muncul, operasi akan memakan waktu lebih lama dan sistem melakukan lebih sedikit operasi per detik.
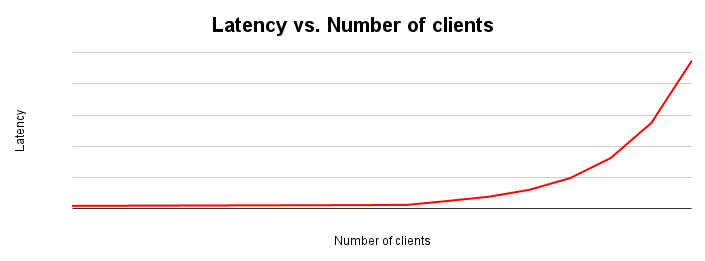
Grafik penskalaan latensi menunjukkan perubahan latensi saat beban yang ditempatkan pada sistem meningkat. Latensi tetap relatif konstan hingga terjadi gesekan karena pertentangan sumber daya. Titik infleksi kurva ini umumnya sesuai dengan perataan kurva throughput dalam grafik penskalaan throughput.
Cara lain yang berguna untuk mengevaluasi latensi adalah sebagai histogram. Dalam representasi ini, kita mengelompokkan latensi ke dalam bucket dan menghitung jumlah permintaan yang termasuk dalam setiap bucket.
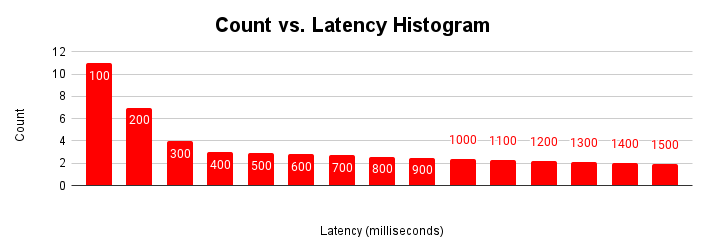
Histogram latensi ini menunjukkan sebagian besar permintaan berada di bawah 100 milidetik, dan latensi yang lebih lama dari 100 milidetik. Memahami penyebab permintaan dengan ekor latensi yang lebih panjang dapat membantu menjelaskan variasi performa aplikasi yang terlihat. Penyebab ekor panjang peningkatan latensi sesuai dengan peningkatan latensi yang terlihat dalam grafik penskalaan latensi umum dan perataan grafik throughput.
Histogram latensi paling berguna saat ada beberapa modalitas dalam aplikasi. Modalitas adalah serangkaian kondisi operasi normal. Misalnya, sebagian besar waktu aplikasi mengakses halaman yang ada di cache buffer. Sebagian besar waktu, aplikasi memperbarui baris yang ada, tetapi mungkin ada beberapa mode. Terkadang, aplikasi mengambil halaman dari penyimpanan, menyisipkan baris baru, atau mengalami persaingan kunci.
Saat aplikasi mengalami berbagai mode operasi ini dari waktu ke waktu, histogram latensi akan menampilkan beberapa modalitas ini.
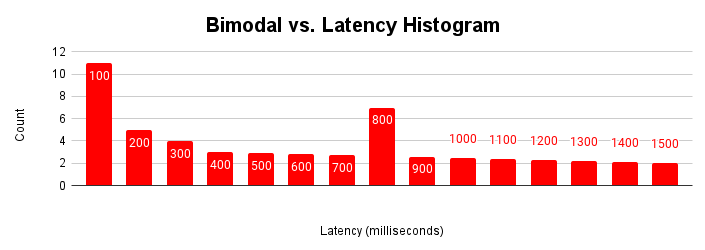
Gambar ini menunjukkan histogram bimodal umum yang sebagian besar permintaannya diproses dalam waktu kurang dari 100 milidetik, tetapi ada cluster permintaan lain yang memerlukan waktu 401-500 milidetik. Memahami penyebab modalitas kedua ini dapat membantu meningkatkan performa aplikasi Anda. Bisa juga ada lebih dari dua modalitas.
Modalitas kedua mungkin disebabkan oleh operasi database normal, infrastruktur dan topologi heterogen, atau perilaku aplikasi. Berikut beberapa contoh yang perlu dipertimbangkan:
- Sebagian besar akses data berasal dari buffer pool PostgreSQL, tetapi beberapa berasal dari penyimpanan
- Perbedaan latensi jaringan untuk beberapa klien ke server database
- Logika aplikasi yang melakukan operasi berbeda bergantung pada input atau waktu
- Pertentangan kunci sporadis
- Lonjakan aktivitas klien