确保高可用性 Patroni 设置的可靠性和质量对于维持数据库的连续操作并最大限度地缩短停机时间至关重要。本页面提供了有关测试 Patroni 集群的全面指南,涵盖各种故障场景、复制一致性和故障切换机制。
测试 Patroni 设置
连接到您的任意 patroni 实例(
alloydb-patroni1、alloydb-patroni2或alloydb-patroni3),然后前往 AlloyDB Omni patroni 文件夹。cd /alloydb/
检查 Patroni 日志。
docker compose logs alloydbomni-patroni
最后的条目应反映 Patroni 节点的相关信息。您应该会看到如下内容。
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock连接到与主 Patroni 实例
alloydb-patroni1具有网络连接的任何运行 Linux 的实例,并获取该实例的相关信息。您可能需要通过运行sudo apt-get install jq -y来安装jq工具。curl -s http://alloydb-patroni1:8008/patroni | jq .
您应该会看到类似以下内容的显示。
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
在 Patroni 节点上调用 Patroni HTTP API 端点会显示有关 Patroni 管理的特定 PostgreSQL 实例的状态和配置的各种详细信息,包括集群状态信息、时间轴、WAL 信息以及用于指示节点和集群是否正常运行的健康检查。
测试您的 HAProxy 设置
在具有浏览器且与 HAProxy 节点建立了网络连接的机器上,前往以下地址:
http://haproxy:7000。或者,您也可以使用 HAProxy 实例的外部 IP 地址,而不是其主机名。您应该会看到类似以下屏幕截图的内容。
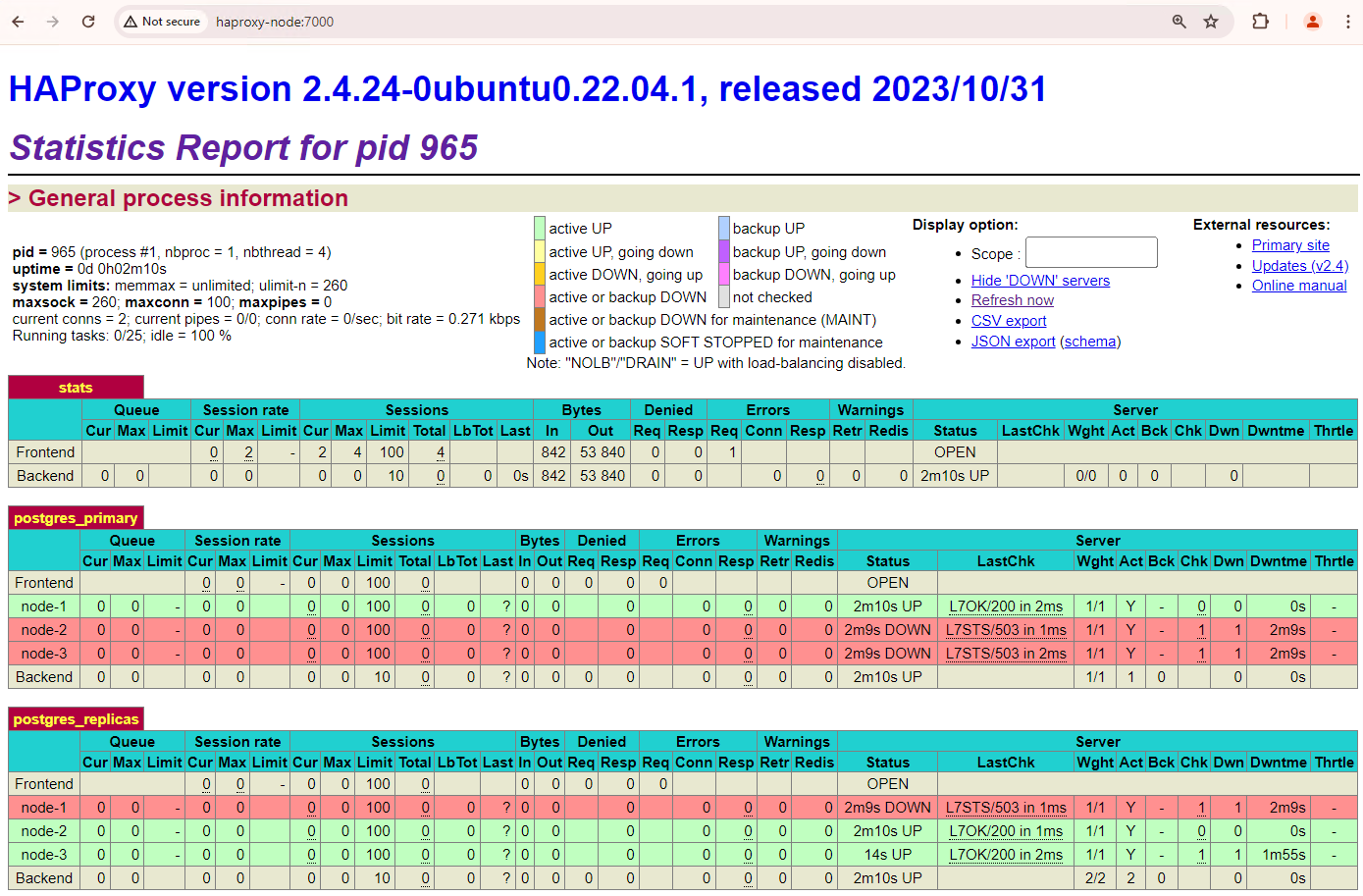
图 1. HAProxy 状态页面,显示 Patroni 节点的运行状况和延迟时间。
在 HAProxy 信息中心内,您可以查看主 Patroni 节点
patroni1以及两个副本patroni2和patroni3的运行状况和延迟时间。您可以执行查询来检查集群中的复制统计信息。通过 HAProxy 从 pgAdmin 等客户端连接到主数据库服务器,然后运行以下查询。
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;您应该会看到类似下图的内容,显示
patroni2和patroni3正在从patroni1流式传输。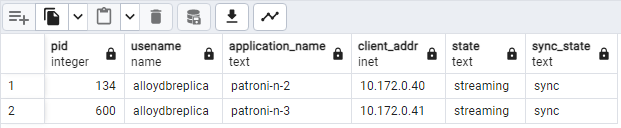
图 2。pg_stat_replication 输出,显示 Patroni 节点的复制状态。
测试自动故障切换
在本部分中,我们将在您的三个节点集群中,通过停止已附加的正在运行的 Patroni 容器来模拟主节点发生故障。您可以停止主服务器上的 Patroni 服务来模拟服务中断,也可以强制执行一些防火墙规则来停止与该节点的通信。
在主 Patroni 实例上,前往 AlloyDB Omni Patroni 文件夹。
cd /alloydb/
停止容器。
docker compose down
您应该会看到类似以下输出的内容。这应该可以验证容器和网络是否已停止。
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default Removed刷新 HAProxy 信息中心,查看故障切换的发生方式。
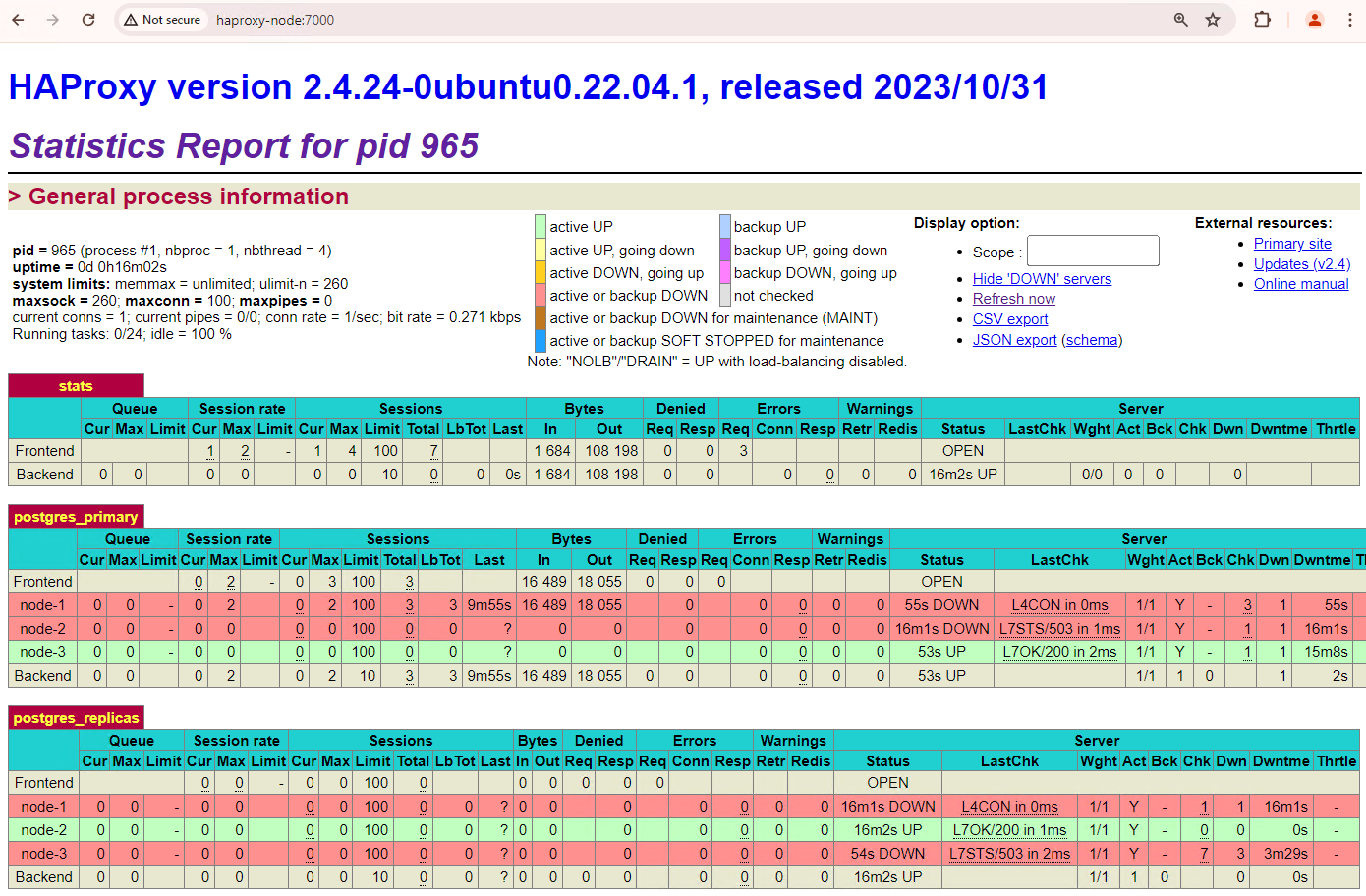
图 3.HAProxy 信息中心,显示从主节点到备用节点的故障切换。
patroni3实例成为新的主实例,patroni2是唯一剩余的副本。之前的主副本patroni1已关闭,并且其健康检查失败。Patroni 通过监控、共识和自动化编排相结合的方式执行和管理故障切换。一旦主节点在指定的超时时间内未能续订其租约,或者报告失败,集群中的其他节点就会通过共识系统识别此情况。其余节点会协调选择最合适的副本,以将其提升为新的主副本。选择候选副本后,Patroni 会应用必要的更改(例如更新 PostgreSQL 配置和重放所有未处理的 WAL 记录),将此节点提升为主节点。然后,新的主节点会使用其状态更新共识系统,其他副本会自行重新配置以跟随新的主节点,包括切换其复制源并可能跟上所有新事务。HAProxy 会检测新的主服务器并相应地重定向客户端连接,从而最大限度地减少中断。
通过 HAProxy 从 pgAdmin 等客户端连接到数据库服务器,然后检查集群中的故障切换后复制统计信息。
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;您应该会看到类似于以下示意图的内容,其中显示目前只有
patroni2正在流式传输。
图 4。pg_stat_replication 输出,显示故障切换后 Patroni 节点的复制状态。
您的三个节点集群还能再承受一次宕机。如果您停止当前的主节点
patroni3,系统会进行另一次故障转移。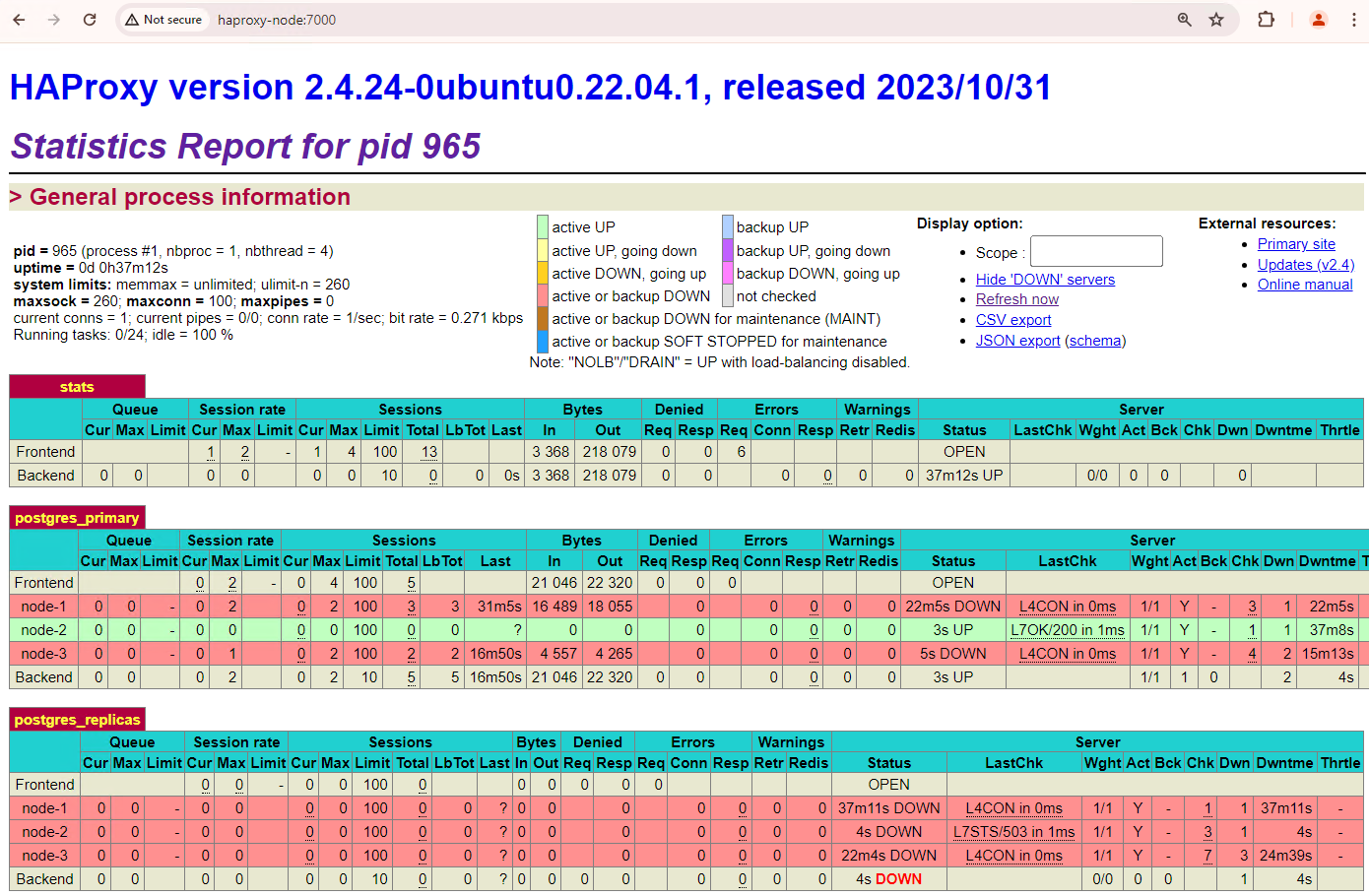
图 5. HAProxy 信息中心,显示了从主节点
patroni3到备用节点patroni2的故障切换。
回退注意事项
回退是指发生故障切换后恢复之前的源节点的过程。通常不建议在高可用性数据库集群中使用自动回退,因为存在一些严重问题,例如恢复不完整、出现分脑场景的风险和复制延迟。
在 Patroni 集群中,如果您启动模拟服务中断的两个节点,它们将作为备用副本重新加入集群。
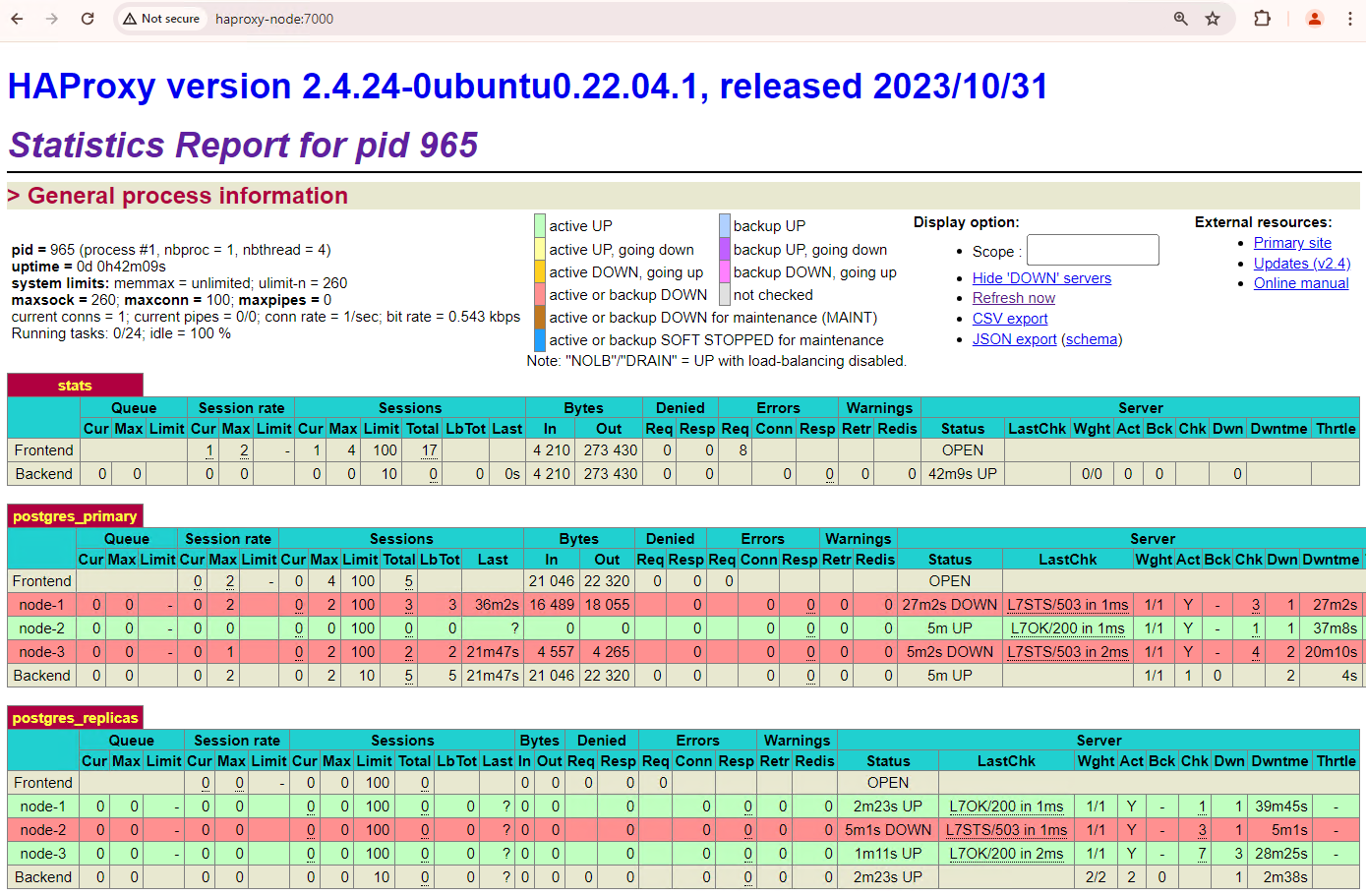
Figure 6. HAProxy 信息中心,显示 patroni1 和 patroni3 已恢复为备用节点。
现在,patroni1 和 patroni3 正在从当前主实例 patroni2 复制数据。

图 7。pg_stat_replication 输出,显示了回退后 Patroni 节点的复制状态。
如果您想手动回退到初始主副本,可以使用 patronictl 命令行界面执行此操作。通过选择手动回退,您可以确保恢复过程更加可靠、一致且经过彻底验证,从而维护数据库系统的完整性和可用性。