如果在云端训练模型或获取预测结果时发生错误,找出错误的原因很不容易。本页介绍如何查找和调试在 AI Platform Prediction 中遇到的问题。如果您在使用机器学习框架时遇到问题,请参阅机器学习框架的文档。
命令行工具
- 错误:(gcloud) 无效的选项:“ai-platform”。
此错误意味着您需要更新 gcloud。要更新 gcloud,请运行以下命令:
gcloud components update- 错误:(gcloud) 无法识别的参数:--framework=SCIKIT_LEARN.
此错误意味着您需要更新 gcloud。要更新 gcloud,请运行以下命令:
gcloud components update- 错误:(gcloud) 无法识别的参数:--framework=XGBOOST。
此错误意味着您需要更新 gcloud。要更新 gcloud,请运行以下命令:
gcloud components update- 错误:(gcloud) 加载模型失败:无法加载模型:/tmp/model/0001/model.pkl。'\x03'。(错误代码:0)
此错误意味着使用了错误的库来导出模型。如需更正此问题,请使用正确的库重新导出模型。例如,使用
pickle库导出model.pkl格式的模型,而使用joblib库导出model.joblib格式的模型。- 错误:(gcloud.ai-platform.jobs.submit.prediction) 参数 --data-format:无效的选项:“json”。
此错误表示您在提交批量预测作业时,将
json指定为--data-format标志的值。如需使用JSON数据格式,您必须提供text作为--data-format标志的值。
Python 版本
- 错误:检测到不正确的模型并出现错误消息:“加载模型失败:无法加载
- 模型:/tmp/model/0001/model.pkl。不受支持的 pickle 协议:3。请确保
- 该模型系使用 python 2 导出。否则,请在部署模型时指定
- 正确的‘python_version’参数。目前,
- ‘python_version’接受 2.7 和 3.5。(错误代码:0)”
- 此错误意味着使用 Python 3 导出的模型文件已部署到使用 Python 2.7 设置的 AI Platform Prediction 模型版本资源中。
如需解决此问题,请执行以下操作:
- 创建一个新的模型版本资源,并将“python_version”设置为 3.5。
- 将相同的模型文件部署到新的模型版本资源中。
找不到 virtualenv 命令
如果您在尝试激活 virtualenv 时遇到此错误,一种可行的解决方案是将包含 virtualenv 的目录添加到 $PATH 环境变量中。修改此变量可让您在使用 virtualenv 命令时无需键入其完整文件路径。
首先,通过运行以下命令来安装 virtualenv:
pip install --user --upgrade virtualenv
安装程序会提示您修改 $PATH 环境变量,并提供 virtualenv 脚本的路径。在 macOS 上,这类似于 /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin。
打开 shell 加载环境变量的文件。通常,在 macOS 中,相应的文件为 ~/.bashrc 或 ~/.bash_profile。
添加以下行,并将 [VALUES-IN-BRACKETS] 替换为适当的值:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
最后,运行以下命令加载更新的 .bashrc(或 .bash_profile)文件:
source ~/.bashrc
使用作业日志
如需进行问题排查,最好先查看 Cloud Logging 收集的作业日志。
不同类型操作的日志
您的日志记录因操作类型而异,如以下部分所示。
批量预测日志
系统会记录所有批量预测作业。
在线预测日志
默认情况下,您的在线预测请求不会生成日志。您可以在创建模型资源时启用 Cloud Logging:
gcloud
在运行 gcloud ai-platform models create 时添加 --enable-logging 标志。
Python
在用于调用 projects.models.create 的 Model 资源中,将 onlinePredictionLogging 设置为 True。
查找日志
您的作业日志包含您的操作引发的所有事件,包括使用分布式训练时集群中所有进程的事件。如果您正在运行分布式训练作业,则会报告主工作器进程的作业级日志。因此,如果发生错误,则对其进行问题排查的第一步通常是检查该进程的日志,以此来过滤掉集群中其他进程的已记录事件。本节中的示例显示了具体的过滤流程。
您可以通过命令行或 Google Cloud Console 的“Cloud Logging”部分过滤日志。无论采用何种方式,请根据需要在过滤条件中使用以下元数据值:
| 元数据项 | 过滤以显示符合以下条件的内容… |
|---|---|
| resource.type | 等于“cloud_ml_job”。 |
| resource.labels.job_id | 等于作业名称。 |
| resource.labels.task_name | 等于“master-replica-0”,以便仅读取主工作器的日志条目。 |
| 严重程度 | 大于或等于 ERROR(错误),以便仅读取与错误情况对应的日志条目。 |
命令行
使用 gcloud beta logging read 构建满足需求的查询。以下是一些示例:
每个示例都依赖于以下环境变量:
PROJECT="my-project-name"
JOB="my_job_name"
如果您愿意,也可以在需要的地方直接输入字符串字面量。
如需将作业日志输出到屏幕,请运行以下命令:
gcloud ai-platform jobs stream-logs $JOB
查看 gcloud ai-platform jobs stream-logs 的所有选项。
如需将主工作器的日志输出到屏幕,请运行以下命令:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
如需仅将主工作器的错误日志输出到屏幕,请运行以下命令:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
上述示例代表了对 AI Platform Prediction 训练作业的日志进行过滤的最常见情况。Cloud Logging 提供了许多强大的过滤选项,供您在需要优化搜索时使用。高级过滤文档详细描述了这些选项。
控制台
打开 Google Cloud 控制台中的 AI Platform Prediction 作业页面。
从作业页面的列表中选择失败的作业,以查看其详情。

- 点击查看日志打开 Cloud Logging。
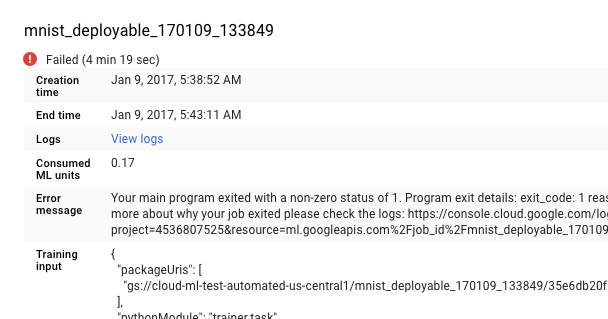
您也可以直接进入 Cloud Logging,但是这样您还要执行以下操作才能查找自己的作业:
- 展开资源选择器。
- 在资源列表中展开 AI Platform Prediction 作业。
- 在 job_id 列表中找到作业名称(您可以在搜索框中输入作业名称的前几个字母以减少显示的作业数)。
- 展开作业条目,然后从任务列表中选择
master-replica-0。

从日志中获取信息
找到作业的正确日志并将其过滤到 master-replica-0 后,您可以检查记录的事件以找到问题的根源。这涉及标准的 Python 调试过程,请谨记以下事项:
- 事件具有多个严重性级别。您可以过滤事件,以仅查看特定级别的事件,例如错误,或错误和警告。
- 导致训练程序退出且显示不可恢复的错误情况(返回代码 > 0)的问题会记录一次异常(显示在堆栈轨迹的前面):
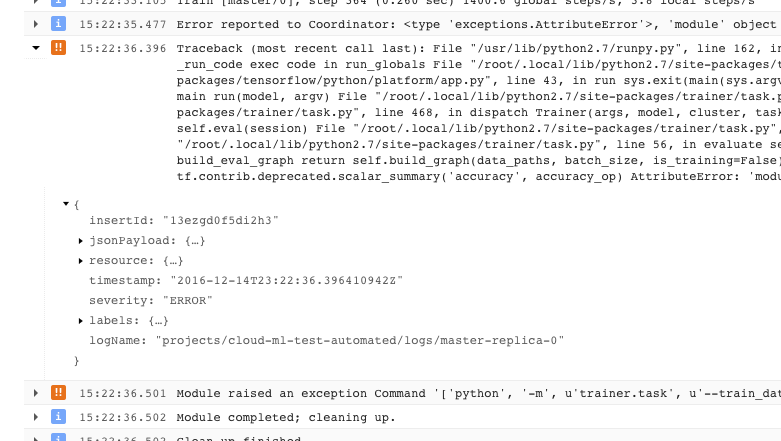
- 如需获取更多信息,您可以展开已记录的 JSON 消息中的对象(由右向箭头和列为 {...} 的内容表示)。例如,您可以展开 jsonPayload 以查看堆栈轨迹,与查看主要错误说明的方式相比,这种方式更加直观:
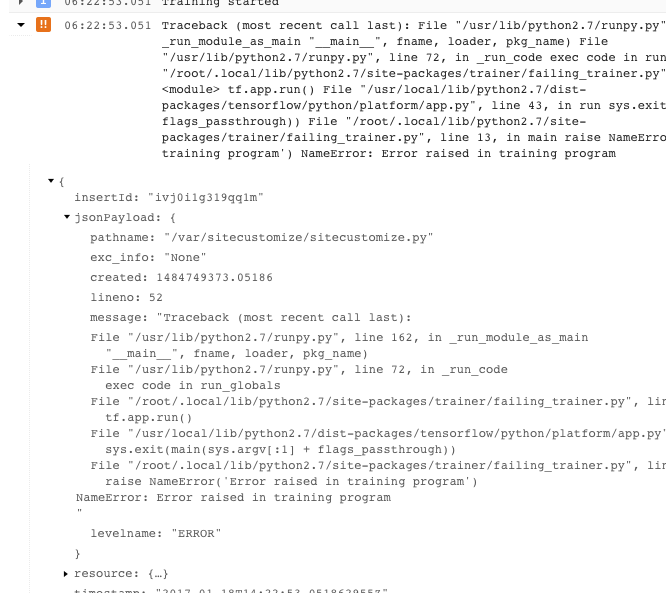
- 某些错误显示了可重试错误的实例。这些实例通常不包含堆栈轨迹,并且可能更难诊断。
充分利用日志记录
AI Platform Prediction 训练服务自动记录以下事件:
- 服务内部的状态信息。
- 您的训练程序应用发送给
stderr的消息。 - 您的训练程序应用发送给
stdout的输出文本。
遵循良好的编程做法,您可以更轻松地对训练程序应用中的错误进行问题排查:
- 将有意义的消息发送到 stderr(例如,使用日志记录)。
- 当出现问题时,找出最合乎逻辑的描述性异常。
- 向异常对象添加描述性字符串。
如需了解异常的更多信息,请参阅 Python 文档。
排查预测问题
本部分收集了获取预测结果时遇到的一些常见问题。
处理在线预测的特定条件
本部分提供指导,帮助您了解一些已知会影响某些用户的在线预测错误情况。
完成预测所需的时间太长(30-180 秒)
在线预测太慢最常见的原因是从零开始调节处理节点数。如果您的模型会定期收到预测请求,则系统会准备好一个或多个节点以处理预测。如果您的模型长时间未处理任何预测,则该服务会将就绪节点数“下调”到零。此下调操作之后的下一个预测请求将比平时花费更多的时间来返回,因为服务必须预配节点才能处理请求。
HTTP 状态代码
如果在线预测请求发生错误,您通常会收到服务返回的 HTTP 状态代码。以下列出了一些常见的代码及其在在线预测上下文中的含义:
- 429 - 内存不足
运行模型时,处理节点内存不足。此时无法增加分配给预测节点的内存。但您可以尝试以下操作来运行模型:
- 通过以下方式缩小模型大小:
- 使用降低精确率的变量。
- 量化连续数据。
- 缩小其他输入特征的大小(例如,减少使用的词汇量)。
- 使用较小批量的实例,再次发送请求。
- 通过以下方式缩小模型大小:
- 429 - 待处理的请求太多
您的模型收到的请求数量超出其处理能力。如果您使用自动扩缩,则表明收到请求的速度快于系统扩缩的速度。此外,如果最小节点值为 0,则此配置可能会导致“冷启动”场景,即在第一个节点可用之前,观察到 100% 错误率。
对于自动扩缩,您可以尝试使用指数退避算法来重新发送请求。使用指数退避算法重新发送请求可以给系统更多时间进行调整。
默认情况下,自动扩缩由 CPU 利用率超过 60% 触发,并且可以配置。
- 429 - 配额
您的 Google Cloud Platform 项目每 100 秒只能处理 10000 个请求(大约每秒 100 个)。如果您在短暂峰值中收到此错误,则通常可以使用指数退避算法进行重试,及时处理所有请求。如果您一直收到此代码,则可以请求增加配额。如需了解详情,请参阅配额页面。
- 503 - 我们的系统检测到您的计算机网络发出异常的流量
您的模型从单个 IP 收到请求的频率非常高,以致于系统怀疑遇到了拒绝服务攻击。停止发送请求一分钟,然后继续以较低的频率发送请求。
- 500 - 无法加载模型
系统无法加载您的模型。请尝试按照以下步骤操作:
- 确保训练程序正在导出正确的模型。
- 使用
gcloud ai-platform local predict命令尝试测试预测。 - 再次导出模型并重试。
预测请求中的格式化错误
以下消息都与您的预测输入有关。
- “请求正文中出现空白或格式错误/无效的 JSON”
- 该服务无法解析请求中的 JSON,或者您的请求为空。请检查您的消息,确认是否有使 JSON 无效的错误或遗漏。
- “请求正文中缺少‘实例’字段”
- 您的请求正文未遵循正确的格式。正常情况下,正文应该是一个包含名为
"instances"的单键的 JSON 对象,而此键包含所有输入实例的列表。 - 创建请求时出现 JSON 编码错误
您的请求中包含 base64 编码数据,但数据的 JSON 格式不正确。正常情况下,每个 base64 编码的字符串必须由一个包含名为
"b64"的单键的对象表示。例如:{"b64": "an_encoded_string"}当您有非 base64 编码的二进制数据时,会发生另一个 base64 错误。此时,请对数据进行编码并将其格式化如下:
{"b64": base64.b64encode(binary_data)}如需了解详细信息,请参阅格式化和编码二进制数据。
云端预测比桌面预测花费更长时间
在线预测设计为可扩缩服务,可以快速处理高速传入的预测请求。该服务针对处理所有服务请求的整合性能进行了优化。对可扩缩性的强调,导致其与在本地机器上生成少量预测有不同的性能特征。
后续步骤
- 获取支持。
- 详细了解 Google API 错误模型,尤其是
google.rpc.Code中定义的规范错误代码和 google/rpc/error_details.proto 中定义的标准错误详细信息。 - 了解如何监控您的训练作业。
- 参阅 Cloud TPU 问题排查和常见问题解答,以便在使用 Cloud TPU 运行 AI Platform Prediction 时诊断和解决问题。