Die Ursache von Fehlern zu finden, die beim Trainieren des Modells oder Abrufen von Vorhersagen in der Cloud auftreten, kann eine Herausforderung darstellen. Auf dieser Seite wird beschrieben, wie Sie Probleme in AI Platform Prediction ermitteln und beheben. Wenn Probleme mit dem verwendeten Framework für maschinelles Lernen auftreten, lesen Sie stattdessen die Dokumentation zum Framework für maschinelles Lernen.
Befehlszeilentool
- FEHLER: (gcloud) Ungültige Auswahl: 'ai-plattform'.
Dieser Fehler bedeutet, dass Sie gcloud aktualisieren müssen. Führen Sie hierfür folgenden Befehl aus:
gcloud components update- FEHLER: (gcloud) Argumente nicht erkannt: --framework=SCIKIT_LEARN.
Dieser Fehler bedeutet, dass Sie gcloud aktualisieren müssen. Führen Sie hierfür folgenden Befehl aus:
gcloud components update- FEHLER: (gcloud) Argumente nicht erkannt: --framework=XGBOOST.
Dieser Fehler bedeutet, dass Sie gcloud aktualisieren müssen. Führen Sie hierfür folgenden Befehl aus:
gcloud components update- FEHLER: (gcloud) Fehler beim Laden des Modells: Das Modell konnte nicht geladen werden: /tmp/model/0001/model.pkl. '\x03'. (Fehlercode: 0)
Dieser Fehler bedeutet, dass zum Exportieren des Modells die falsche Bibliothek verwendet wurde. Sie beheben den Fehler, wenn Sie das Modell mit der richtigen Bibliothek noch einmal exportieren. Beispielsweise exportieren Sie Modelle im Format
model.pklmit der Bibliothekpickleund Modelle im Formatmodel.joblibmit der Bibliothekjoblib.- FEHLER: (gcloud.ai-platform.jobs.submit.prediction) Argument --data-format: Ungültige Auswahl: 'json'.
Dieser Fehler bedeutet, dass Sie beim Senden eines Batchvorhersagejobs
jsonals Wert für das Flag--data-formatangegeben haben. Sie müssentextals Wert für das Flag--data-formatangeben, um das DatenformatJSONzu verwenden.
Python-Versionen
- FEHLER: Ungeeignetes Modell mit folgendem Fehler erkannt: "Fehler beim Laden von Modell: Modell konnte nicht
- geladen werden: /tmp/model/0001/model.pkl. Pickle-Protokoll nicht unterstützt: 3. Das Modell muss
- mit Python 2 exportiert worden sein. Andernfalls müssen Sie beim
- Bereitstellen des Modells den richtigen Parameter für 'python_version' angeben. Derzeit
- werden für 'python_version' die Werte 2.7 und 3.5 akzeptiert. (Fehlercode: 0)"
- Dieser Fehler bedeutet, dass eine mit Python 3 exportierte Modelldatei in einer AI Platform Prediction-Modellversionsressource mit einer Python 2.7-Einstellung bereitgestellt wurde.
So beheben Sie dies:
- Erstellen Sie eine neue Modellversionsressource und setzen Sie 'python_version' auf 3.5.
- Diese Modelldatei stellen Sie für die neue Modellversionsressource bereit.
Befehl virtualenv wurde nicht gefunden
Wenn dieser Fehler beim Versuch auftritt, virtualenv zu aktivieren, können Sie das Verzeichnis, in dem virtualenv enthalten ist, in die Umgebungsvariable $PATH aufnehmen. Durch die Änderung dieser Variablen können Sie virtualenv-Befehle verwenden, ohne den vollen Dateipfad eingeben zu müssen.
Zuerst müssen Sie virtualenv mit dem folgenden Befehl installieren:
pip install --user --upgrade virtualenv
Vom Installationsprogramm bekommen Sie die Aufforderung, die Umgebungsvariable $PATH zu ändern, und es liefert Ihnen den Pfad zum virtualenv-Skript. Unter macOS sieht dieser etwa so aus: /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Dann öffnen Sie die Datei, aus der Ihre Shell Umgebungsvariablen lädt. In macOS ist dies ~/.bashrc oder ~/.bash_profile.
Dabei fügen Sie die folgende Zeile hinzu und ersetzen [VALUES-IN-BRACKETS] durch die entsprechenden Werte:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Abschließend führen Sie den folgenden Befehl aus, um die aktualisierte Datei .bashrc oder .bash_profile zu laden:
source ~/.bashrc
Joblogs
Ein guter Ausgangspunkt für die Fehlerbehebung sind die von Cloud Logging erfassten Joblogs.
Logging für verschiedene Arten von Vorgängen
Welche Art von Logging stattfindet, hängt vom jeweiligen Vorgang ab, wie in den folgenden Abschnitten beschrieben.
Batchvorhersagelogs
Alle Batchvorhersagejobs werden protokolliert.
Onlinevorhersage-Logs
Für Onlinevorhersageanfragen werden standardmäßig keine Logs generiert. Sie können Cloud Logging aktivieren, wenn Sie Ihre Modellressource erstellen:
gcloud
Wenn Sie gcloud ai-platform models create ausführen, verwenden Sie das Flag --enable-logging.
Python
In der Ressource Model, die Sie für den Aufruf von projects.models.create verwenden, setzen Sie onlinePredictionLogging auf True.
Logs suchen
Die Job-Logs enthalten alle Ereignisse im jeweiligen Vorgang, einschließlich Ereignisse aus allen Prozessen im Cluster, sofern das Training verteilt ist. Wenn Sie einen Job für verteiltes Training ausführen, werden die Job-Logs für den Master-Worker-Prozess ausgegeben. Der erste Schritt zur Fehlerbehebung besteht normalerweise in der Durchsicht der Logs für den jeweiligen Prozess, wobei protokollierte Ereignisse für andere Prozesse im Cluster herauszufiltern sind. Die Beispiele in diesem Abschnitt veranschaulichen diese Filterung.
Sie können die Logs über die Befehlszeile oder im Cloud Logging-Bereich der Google Cloud Console filtern. Verwenden Sie in beiden Fällen je nach Bedarf folgende Metadatenwerte in Ihrem Filter:
| Metadatenelement | Filter zur Anzeige von Elementen, für die Folgendes gilt: |
|---|---|
| resource.type | Ist gleich "cloud_ml_job" (Cloud ML-Job). |
| resource.labels.job_id | Entspricht Ihrem Jobnamen. |
| resource.labels.task_name | Ist gleich "master-replica-0", um nur die Log-Einträge für den Master-Worker anzuzeigen. |
| severity | Ist größer als oder gleich ERROR (FEHLER), um nur die Log-Einträge anzuzeigen, die Fehlerbedingungen entsprechen. |
Befehlszeile
Erstellen Sie mit gcloud beta logging read eine Abfrage, die Ihren Anforderungen entspricht. Hier einige Beispiele:
In jedem Beispiel werden folgende Umgebungsvariablen verwendet:
PROJECT="my-project-name"
JOB="my_job_name"
Sie können stattdessen das Stringliteral eingeben, wenn Sie dies bevorzugen.
So geben Sie die Joblogs auf dem Bildschirm aus:
gcloud ai-platform jobs stream-logs $JOB
Hier finden Sie alle Optionen für gcloud ai-platform jobs stream-logs.
So geben Sie das Log für den Master-Worker auf dem Bildschirm aus:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
So geben Sie nur die für den Master-Worker protokollierten Fehler auf dem Bildschirm aus:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Die obigen Beispiele stellen die gängigsten Filtervorgänge für Logs aus dem AI Platform Prediction-Trainingsjob dar. Cloud Logging bietet viele leistungsstarke Filteroptionen, die Sie zur Verfeinerung Ihrer Suche verwenden können. In der Dokumentation zur erweiterten Filterung werden diese Optionen im Detail beschrieben.
Console
Öffnen Sie in der Google Cloud Console die Seite Jobs für AI Platform Prediction.
Wählen Sie den Job mit dem Fehler in der Liste auf der Seite Jobs aus, um die zugehörigen Details anzuzeigen.

- Klicken Sie auf Logs ansehen, um Cloud Logging zu öffnen.
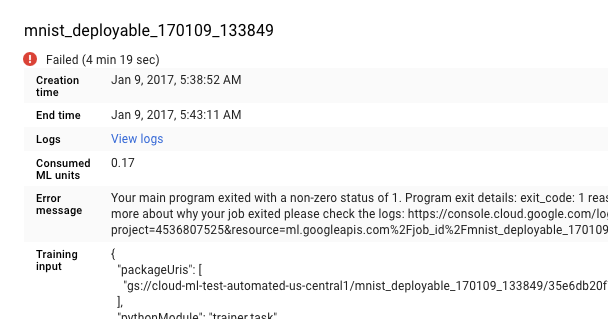
Sie können auch direkt zu Cloud Logging wechseln, müssen aber dort als zusätzlichen Schritt Ihren Job ermitteln:
- Maximieren Sie die Ressourcenauswahl.
- Maximieren Sie den AI Platform Prediction-Job in der Ressourcenliste.
- Suchen Sie in der Liste der Job-IDs nach Ihrem Jobnamen. Sie können die ersten Buchstaben des Jobnamens im Suchfeld eingeben, um die angezeigten Jobs einzugrenzen.
- Maximieren Sie den Jobeintrag und wählen Sie
master-replica-0aus der Aufgabenliste aus.

Informationen aus den Logs ermitteln
Nachdem Sie das richtige Log für Ihren Job gefunden und auf master-replica-0 beschränkt haben, können Sie die protokollierten Ereignisse durchsehen, um die Ursache des Problems zu finden. Dazu gehen Sie wie bei einer normalen Python-Fehlerbehebung vor. Denken Sie dabei vor allem an Folgendes:
- Ereignisse haben verschiedene Wichtigkeitsstufen. Mithilfe des Filters können Sie sich ausschließlich Ereignisse einer bestimmten Stufe anzeigen lassen, beispielsweise Fehler oder aber Fehler und Warnungen.
- Ein Problem, das zur Beendigung des Trainers aufgrund eines nicht behebbaren Fehlers geführt hat (Rückgabecode > 0), wird als Ausnahme mit vorangegangenem Stacktrace protokolliert:
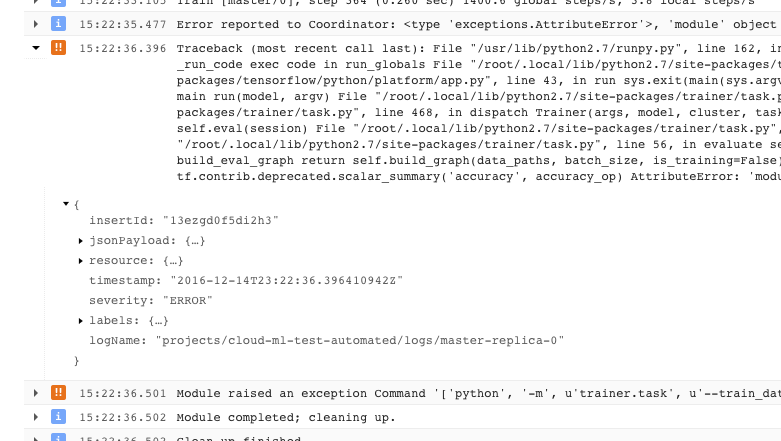
- Sie können weitere Informationen abrufen, wenn Sie die Objekte in der protokollierten JSON-Nachricht maximieren. Diese erkennen Sie an einem nach rechts gerichteten Pfeil und geschweiften Klammern ({...}). Sie können beispielsweise jsonPayload maximieren, um den Stacktrace in einer besser lesbaren Form als in der Hauptfehlerbeschreibung abzurufen:
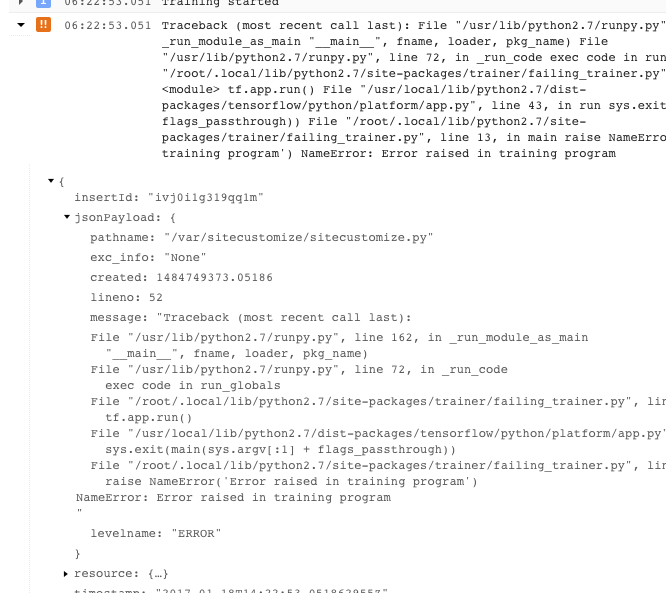
- Manche Fehler liegen in Form von wiederholbaren Fehlern vor. Diese beinhalten normalerweise keinen Stacktrace und sind unter Umständen schwieriger zu diagnostizieren.
Logging optimal nutzen
Der AI Platform Prediction-Trainingsdienst protokolliert automatisch folgende Ereignisse:
- Dienstinterne Statusinformationen
- Nachrichten, die Ihre Traineranwendung an
stderrsendet - Ausgabetext, den Ihre Traineranwendung an
stdoutsendet
Sie können die Fehlerbehebung in Ihrer Traineranwendung vereinfachen, indem Sie einen guten Programmierstil pflegen:
- Senden Sie aussagekräftige Nachrichten an stderr, zum Beispiel mit "logging".
- Lösen Sie die logischste und anschaulichste Ausnahme aus, wenn ein Vorgang fehlschlägt.
- Fügen Sie den Ausnahmeobjekten beschreibende Strings hinzu.
In der Python-Dokumentation finden Sie weitere Informationen zu Ausnahmen.
Fehlerbehebung bei Vorhersagen
In diesem Abschnitt werden einige gängige Probleme zusammengefasst, die in Zusammenhang mit Vorhersagen auftreten können.
Bestimmte Bedingungen bei Onlinevorhersagen behandeln
Dieser Abschnitt enthält Anleitungen zur Behandlung bestimmter Fehlerbedingungen bei Onlinevorhersagen, die bereits bei einigen Nutzern aufgetreten sind.
Zu lange Ausführungszeit von Vorhersagen (30 bis 180 Sekunden)
Die häufigste Ursache für langsame Onlinevorhersagen ist die Hochskalierung von Verarbeitungsknoten von null aufwärts. Wenn regelmäßig Vorhersageanfragen an Ihr Modell gehen, hält das System einen oder mehrere Knoten bereit, um Vorhersagen durchzuführen. Sollte Ihr Modell lange Zeit keine Vorhersagen geliefert haben, skaliert der Dienst die in Bereitschaft stehenden Knoten auf null herunter. Die nächste Vorhersageanfrage nach einer solchen Abwärtsskalierung dauert wesentlich länger als normalerweise, da der Dienst Knoten zur Verarbeitung abstellen muss.
HTTP-Statuscodes
Wenn bei einer Onlinevorhersageanfrage ein Fehler auftritt, gibt der Dienst normalerweise einen HTTP-Statuscode zurück. Im Folgenden sind einige gängige Codes und deren Bedeutung in Zusammenhang mit Onlinevorhersagen aufgeführt:
- 429 – Nicht genügend Arbeitsspeicher
Dem Verarbeitungsknoten stand beim Ausführen des Modells nicht genügend Speicher zur Verfügung. Es gibt keine Möglichkeit, den für Vorhersageknoten zugeteilten Speicher zu diesem Zeitpunkt zu erhöhen. Sie können aber Folgendes probieren, um das Modell doch noch auszuführen:
- Sie verringern die Modellgröße, wenn Sie:
- weniger genaue Variablen verwenden,
- die kontinuierlichen Daten quantisieren und
- die Größe von anderen Eingabemerkmalen reduzieren (beispielsweise die Vokabulargröße).
- Senden Sie die Anfrage noch einmal mit einem kleineren Batch von Instanzen.
- Sie verringern die Modellgröße, wenn Sie:
- 429 – Zu viele ausstehende Anfragen
Ihr Modell erhält mehr Anfragen, als es verarbeiten kann. Wenn Sie Autoscaling verwenden, gehen Anfragen schneller ein, als das System Ressourcen hochskalieren kann. Wenn der minimale Knotenwert 0 ist, kann diese Konfiguration außerdem zu einem „Kaltstart”-Szenario führen, bei dem eine Fehlerrate von 100 % beobachtet wird, bis der erste Knoten praktikabel ist.
Bei Verwendung der automatischen Skalierung können Sie versuchen, Anfragen mit exponentiellem Backoff noch einmal zu senden. Wenn Sie Anfragen mit exponentiellem Backoff noch einmal senden, kann sich das System anpassen.
Standardmäßig wird die automatische Skalierung durch eine CPU-Auslastung von mehr als 60 % ausgelöst und ist konfigurierbar.
- 429 – Kontingent
Ihr Google Cloud Platform-Projekt ist auf 10.000 Anfragen pro 100 Sekunden (etwa 100 pro Sekunde) beschränkt. Wenn Sie diesen Fehler bei temporären Spitzen erhalten, können Sie oft mit einem exponentiellen Backoff die rechtzeitige Verarbeitung aller Anfragen erreichen. Wenn Sie diesen Code immer wieder erhalten, können Sie eine Kontingenterhöhung anfordern. Weitere Informationen finden Sie auf der Seite zu den Kontingenten.
- 503 – Unsere Systeme haben ungewöhnlichen Traffic aus Ihrem Computernetzwerk festgestellt.
Die Anzahl der Anfragen, die Ihr Modell von einer einzigen IP-Adresse erhalten hat, ist so hoch, dass das System einen Denial-of-Service-Angriff vermutet. Senden Sie eine Minute lang keine Anfragen mehr und nehmen Sie das Senden dann mit einem geringeren Tempo wieder auf.
- 500 – Modell konnte nicht geladen werden.
Das System hat mit dem Laden Ihres Modells Probleme. Versuchen Sie Folgendes:
- Sorgen Sie dafür, dass der Trainer das richtige Modell exportiert.
- Führen Sie mit dem Befehl
gcloud ai-platform local predicteine Testvorhersage aus. - Exportieren Sie Ihr Modell noch einmal und starten Sie einen neuen Versuch.
Formatierungsfehler bei Vorhersageanfragen
Alle der folgenden Nachrichten stehen in Zusammenhang mit der Eingabe für die Vorhersage.
- "Leerer oder fehlerhafter/ungültiger JSON-Anfragetext"
- Der Dienst konnte das JSON-Objekt in Ihrer Anfrage nicht parsen oder die Anfrage ist leer. Prüfen Sie Ihre Nachricht auf Fehler oder Auslassungen, die das JSON-Objekt ungültig machen.
- "Feld "instances" fehlt im Anfragetext"
- Ihr Anfragetext ist falsch formatiert. Es sollte ein JSON-Objekt mit einem einzigen Schlüssel namens
"instances"sein, der eine Liste aller Eingabeinstanzen enthält. - JSON-Codierungsfehler beim Erstellen einer Anfrage
Ihre Anfrage enthält base64-codierte Daten, jedoch im falschen JSON-Format. Jeder base64-codierte String muss durch ein Objekt mit einem einzigen Schlüssel namens
"b64"dargestellt werden. Beispiel:{"b64": "an_encoded_string"}Ein weiterer base64-Fehler tritt auf, wenn Binärdaten vorliegen, die nicht base64-codiert sind. So kodieren und formatieren Sie Ihre Daten:
{"b64": base64.b64encode(binary_data)}Weitere Informationen finden Sie unter Binärdaten formatieren und kodieren.
Längere Ausführungszeit der Vorhersage in der Cloud als auf dem Desktop
Die Onlinevorhersage ist ein skalierbarer Dienst, der eine große Menge an Vorhersageanfragen schnell verarbeiten soll. Der Dienst ist darauf ausgelegt, eine optimale Gesamtleistung für alle laufenden Anfragen zu bieten. Da die Betonung auf Skalierbarkeit liegt, sind die Leistungsmerkmale andere als beim Generieren einer kleinen Anzahl von Vorhersagen auf lokalen Rechnern.
Weitere Informationen
- Support anfordern
- Weitere Informationen über das Fehlermodell von Google APIs, insbesondere über die in
google.rpc.Codedefinierten kanonischen Fehlercodes und die in google/rpc/error_details.proto definierten Standardfehlerdetails - Trainingsjobs überwachen
- Mithilfe der Fehlerbehebung und FAQ für Cloud TPU Fehler beim Ausführen von AI Platform Prediction mit Cloud TPU diagnostizieren und lösen.