Tempo estimado até à conclusão: 4 dias
Proprietário do componente operacional: HW
Perfil de competências: engenheiro de implementação
Conclua as seguintes tarefas para repor os dispositivos e os sistemas em execução no ambiente isolado do Google Distributed Cloud (GDC).
6.1. Índice
- Vista geral do procedimento de reposição
- HPE Server Reset
- Reposição do NetApp StorageGRID
- Reposição do NetApp ONTAP
- Reposição do HSM da Thales
- Reposição de firewalls da Palo Alto
- Reposição de comutadores Cisco
- Recursos adicionais
6.2. Pré-requisitos e segurança
6.2.1. Acesso necessário
- Acesso físico: acesso à sala de DC com equipamento de carrinho de emergência
- Acesso à rede: conetividade da interface de gestão ou acesso à consola
- Credenciais: acesso de administrador a todos os sistemas
- Cópias de segurança: cópia de segurança completa de todos os segredos e dados de configuração
6.2.2. Lista de verificação de segurança
- [ ] Acesso físico à infraestrutura
- [ ] Os segredos de acesso de emergência foram protegidos offline
- [ ] Cópia de segurança da infraestrutura (se necessário)
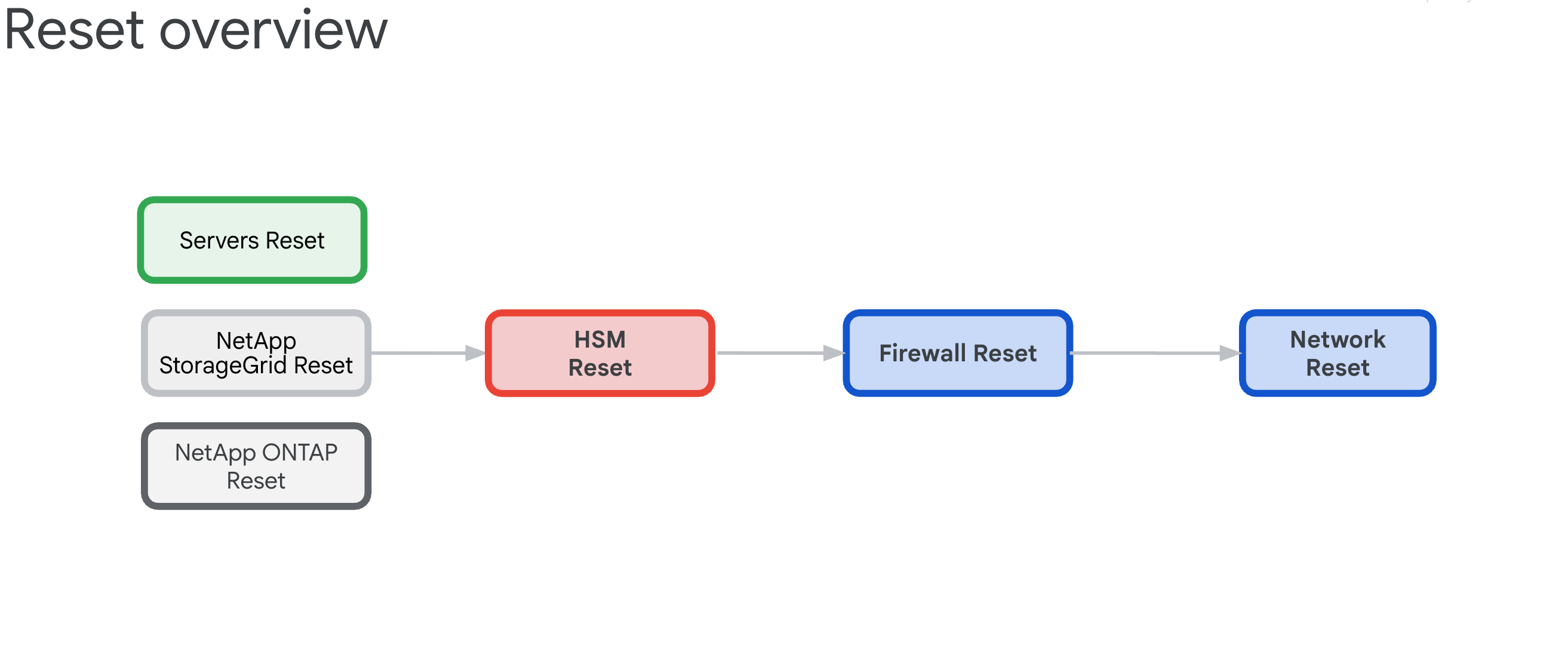
6.3. Vista geral do procedimento de reposição
O procedimento de reposição de uma zona de célula do GDC existente destina-se a libertar todos os dispositivos de hardware de qualquer dependência e, em seguida, revertê-los para o respetivo estado de fabrico.
6.3.1. Dependências de infraestrutura
Os componentes têm as seguintes interdependências que ditam a ordem de reposição:
- Os servidores, o NetApp ONTAP e o NetApp StorageGrid dependem dos dispositivos HSM da Thales, uma vez que estes fornecem as chaves de encriptação para ILOs, discos, inquilinos e contentores.
- Os dispositivos HSM da Thales baseiam-se na conetividade de firewalls de IDP/perímetro e comutadores Cisco.
- Os firewalls de perímetro/IDP baseiam-se na infraestrutura de rede dos comutadores Cisco.
- Os comutadores Cisco têm de ser repostos como último recurso, uma vez que a conetividade é interrompida após a reposição.
6.3.2. Reposição da ordem (importante)
Siga esta ordem exata para evitar bloqueios do sistema:
- Servidores HPE: remova primeiro as dependências do HSM
- NetApp StorageGRID: limpe a encriptação e reponha os nós
- NetApp ONTAP: desative o HSM e reponha o cluster
- HSM da Thales: reposição de fábrica e limpeza da raiz de fidedignidade
- Firewalls: reposição de fábrica para a configuração predefinida
- Comutadores Cisco: repor por último (interrompe a conetividade)
6.4. Apagamento seguro da Hewlett Packard Enterprise
Existem três tipos de operações de reposição disponíveis, cada uma servindo como um método alternativo para limpar a configuração do iLO Key Manager. O objetivo principal é remover a dependência do módulo de segurança de hardware (HSM).
Geralmente, a reposição de fábrica do ILO é suficiente para limpar a configuração do KMS. Em seguida, no próximo arranque, o processo de arranque do servidor inicializa os parâmetros da BIOS do servidor, apaga os discos e reinicializa o servidor.
Esta secção aborda como realizar três tipos de eliminações:
Estes scripts de eliminação usam um ficheiro CSV de exemplo denominado example.csv.
Antes de continuar, prepare o seguinte ficheiro CSV:
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. Reposição de fábrica do iLO
Conclua uma reposição de fábrica do iLO normal:
Crie um ficheiro denominado
serversreset.pye adicione o seguinte script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Execute o seguinte comando e substitua
example.csvpelo seu ficheiro CSV:python3 serversreset.py -csv example.csvUm resultado tem de ser semelhante ao seguinte:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. Passos manuais adicionais do iLO
Efetue uma reposição manual do iLO através da IU do iLO:
Selecione iLO > Administração > Gestor de chaves > Eliminar definições.
Na consola do BIOS, selecione System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default.
Defina as interfaces para arranque pela rede apenas para LOM1. Todos os nós da GPU NÃO têm cartões LOM1, mas sim cartões Intel.
Defina a rede iLO como DHCP.
6.4.3. Reposição do BIOS
Siga os passos abaixo para fazer uma reposição da BIOS:
Crie um ficheiro denominado
biosreset.pye adicione o seguinte script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Execute o seguinte comando e substitua
example.csvpelo seu ficheiro CSV:python3 biosreset.py -csv example.csvUm resultado tem de ser semelhante ao seguinte:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}Depois de executar o comando, os servidores estão no estado ligado. Tem de executar o seguinte script para desligar todos os servidores:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)Desligue manualmente os servidores:
python3 power-ilo.py -csv ~/servers.csv- (Opcional) Para verificar o estado, use o seguinte script:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: passExecute o seguinte comando:
python3 ilostatus.py -csv ~/servers.csvUm resultado tem de ser semelhante ao seguinte:
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. Apagamento seguro
Prima F10 no ecrã POST do servidor. Isto inicia o aprovisionamento inteligente.
Depois de iniciar o aprovisionamento inteligente, clique na seta para baixo junto a Assistente de configuração inicial para ignorar o assistente.
Ignorar pedido do assistente, clique em Sim.
Clique em Realizar manutenção.
Clique em Eliminação segura com um botão.
Uma mensagem indica que não tem privilégios suficientes. Clique em Iniciar sessão e introduza as credenciais de administrador.
Clique em Concluído.
Clique em Enviar.
Confirme que quer realizar a eliminação segura e, em seguida, escreva ERASE.
Clique em ERASE.
Clique em Sim para confirmar.
Clique em Iniciar agora na secção Fila de tarefas.
Em cerca de 2 minutos ou menos, siga as instruções para clicar em OK.
A máquina é reiniciada. Não toque em nada durante cerca de 10 a 15 minutos.
Após a eliminação segura, volte a aceder ao BIOS clicando em F9 durante o POST Boot.
Navegue para Aplicações incorporadas > Registo de gestão integrada (IML) > Ver IML > OK. É apresentada a mensagem Apagamento seguro com um botão concluído:

Crie um ficheiro denominado
serversreset.pye adicione o seguinte script Python:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Execute o seguinte comando e substitua
example.csvpelo seu ficheiro CSV:python serversreset.py -csv example.csvDepois de executar o comando, os servidores estão desligados. Tem de ligar o servidor manualmente.
6.5. Reponha o dispositivo NetApp StorageGRID
6.5.1. Pré-requisitos
Antes de repor o dispositivo NetApp StorageGRID, certifique-se de que lê o seguinte: - Se o sistema tiver sido ativado com a encriptação de nós e/ou a encriptação de unidades, tem de realizar os passos descritos em Desative a encriptação do site do HSM. Caso contrário, avance para repôr o sistema StorageGRID.
6.5.2. Desative a encriptação do site do HSM do StorageGRID nos nós do controlador de armazenamento
Para obter os IPs dos nós do controlador de armazenamento (dois IPs para cada nó de armazenamento):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Se o sistema StorageGRID tiver sido ativado anteriormente com o HSM, a encriptação tem de ser removida antes de proceder à reposição de fábrica. Execute estes passos para cada nó de armazenamento antes de repor o dispositivo. Se não o fizer, pode bloquear os discos e o sistema.
Inicie sessão no site de armazenamento de objetos e navegue para a lista de nós que se encontra na barra lateral.
Clique no nome do nó de armazenamento.
Navegue para o separador SANtricity System Manager.
Navegue para Definições > Sistema > Gestão de chaves de segurança.

Selecione Desativar gestão de chaves externas e introduza a frase secreta para transferir a chave suplementar.
6.5.3. Reposição de fábrica do nó de administração do StorageGRID e do nó de computação de armazenamento
Para obter os IPs dos nós de administrador:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Para obter os IPs dos nós de computação de armazenamento:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Para fazer uma reposição de dados de fábrica do dispositivo StorageGRID, tem de concluir os seguintes passos para cada nó (nós de armazenamento e de administração) no site:
Obtenha os IPs de gestão de cada nó. Pode obtê-lo a partir do ficheiro cell.yaml, procurando
ObjectStorageStorageNodeeObjectStorageAdminNode. Também pode encontrá-los nos recursos de nós no cluster de administrador raiz.Obtenha a palavra-passe e ligue-se ao nó através de SSH:
Se o nó não tiver o StorageGRID instalado, use
admin/bycastouroot/netapp1!, respetivamente, como nome de utilizador e palavra-passe. Use a porta SSH 8022 se o SSH não funcionar.Se o nó tiver o StorageGRID instalado, mas não tiver configuração do site, use
admin/bycastouroot/bycast, respetivamente, como nome de utilizador e palavra-passe.Se o site estiver configurado e o nó fizer parte do site:
Obtenha a frase de acesso de aprovisionamento. Este valor é armazenado num segredo denominado
grid-secret, que pode ser encontrado no ficheiro cell.yaml. Opcionalmente, pode executar o seguinte comando. Certifique-se de que descodifica em Base64 a palavra-passe:echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)Na IU do site de armazenamento de objetos, navegue para Manutenção > Sistema > Pacote de recuperação para transferir o pacote de recuperação depois de introduzir a frase secreta de aprovisionamento.

Depois de transferir, extraia o ficheiro TAR. Este vai conter outro ficheiro TAR:
GIDXXXXX_REV1_SAID.zip. Extraia o ficheiro tar.gz para encontrar o ficheiroPasswords.txt. Use oPasswordpara o acesso ssh e root e ignore oSSH Access Password.Ficheiro de exemplo:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
Abra uma consola de série para o nó ou ligue-se ao nó através de SSH:
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>Introduza as credenciais para iniciar sessão. Para obter privilégios de sudo, escreva
su -, e introduza a palavra-passe de raiz obtida no segundo passo.Introduza o comando
sgareinstalle primaypara continuar a repor o dispositivo.Se a encriptação tiver sido ativada no dispositivo, após a conclusão da reposição, siga estes passos para eliminar os conjuntos de discos e a cache SSD.
6.5.4. Elimine grupos de discos e a cache SSD nos nós do controlador de armazenamento
Para obter os IPs dos nós do controlador de armazenamento (dois IPs para cada nó de armazenamento):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Se a encriptação tiver sido ativada no dispositivo e os nós tiverem sido repostos após seguir a última secção, os conjuntos de discos têm de ser eliminados juntamente com o apagamento das unidades. Isto tem de ser feito antes de reiniciar o site para que possa criar novos conjuntos de discos. Siga estes passos para cada nó de armazenamento (controlador de armazenamento e2860) no site (também conhecido como controllerAManagementIP):
Abra um navegador de Internet para visitar
https://<storage-node-controller-ip>:8443e introduza as credenciais. Se não tiver acesso às credenciais do SANtricity, siga estes passos.Navegue para Armazenamento > Pools e grupos de volumes.
Elimine a cache de SSD:
Selecione a cache SSD para a realçar.
Selecione o menu pendente Tarefas invulgares e clique em Eliminar.

Elimine o grupo de discos:
Selecione o conjunto de discos para o realçar.
Selecione o menu pendente Tarefas invulgares e clique em Eliminar.

Experimente criar um novo conjunto de discos. É apresentada uma caixa de diálogo que bloqueia a criação e pede para apagar as unidades.

Uma vez que não é possível usar unidades seguras ativadas não atribuídas para a criação de um conjunto, tem de as eliminar primeiro. Clique no botão de opção Sim, quero selecionar as unidades que pretendo apagar para a operação e, em seguida, selecione todas as unidades que quer apagar. Confirme a operação de eliminação e clique em OK. Não avance para a criação de um novo conjunto.
Siga os passos descritos na secção de remoção da encriptação de nós.
6.5.5. Remova a encriptação de nós nos nós de administração e nos nós de computação de armazenamento do StorageGRID
Para obter os IPs dos nós de administrador:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
Para obter os IPs dos nós de computação de armazenamento:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Se a encriptação tiver sido ativada no dispositivo e os nós tiverem sido repostos depois de seguir estes passos e os conjuntos de discos e a cache SSD tiverem sido eliminados com estes passos, siga os passos seguintes em cada nó para remover a encriptação do nó:
Navegue para a IU do instalador do dispositivo StorageGRID.
Aceda a Configurar hardware > Encriptação de nós.
Clique em Limpar chave do KMS e eliminar dados.

Assim que a limpeza for acionada, o comando é reiniciado, o que pode demorar cerca de 15 minutos.
6.5.6. Reinstale o StorageGRID
Reiniciar manualmente cada nó.
Abra uma consola série para o nó, aceda ao menu do carregador de arranque GRUB e selecione StorageGRID Appliance: Force StorageGRID reinstall.

6.5.7. Obtenha credenciais do SANtricity
Abra uma consola série para qualquer um dos controladores SANtricity.
Use as seguintes credenciais para iniciar sessão:
- nome de utilizador:
spri - palavra-passe:
SPRIentry
- nome de utilizador:
Depois de iniciar sessão, é apresentado um menu como este:
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulInicie sessão nos controladores SANtricity e a reposição da palavra-passe vai ficar disponível.
6.6. Reponha o dispositivo NetApp ONTAP
6.6.1. Pré-requisitos
Antes de repor o dispositivo NetApp ONTAP, certifique-se de que lê as seguintes informações:
Se o sistema tiver sido ativado anteriormente com um módulo de segurança de hardware (HSM), tem de realizar os passos descritos em Desative o módulo de segurança de hardware antes de repor os sistemas ONTAP.
Esta é uma operação destrutiva que apaga todos os dados do CipherTrust Manager, incluindo, entre outros, chaves, cópias de segurança, chaves de cópias de segurança e registos do sistema.
Certifique-se de que tem uma cópia de segurança válida do CipherTrust Manager de todos os dados e chaves de cópia de segurança.
Se estiver disponível um HSM incorporado, este não é reposto como parte desta operação.
Opcional: recomenda-se vivamente a reinicialização de um HSM incorporado após esta operação para o configurar como a raiz de confiança.
Se tiver sido usado um dispositivo de introdução de PIN (PED) remoto, este tem de ser novamente ligado após a conclusão.
Esta operação pode demorar até 15 minutos. Certifique-se de que tem uma cópia de segurança de energia no local.
6.6.2. Desative o módulo de segurança de hardware
Se o sistema foi ativado anteriormente com um HSM, execute estes passos antes de repôr os sistemas ONTAP. Se não o fizer, pode bloquear os discos e o sistema. Execute os seguintes comandos no cluster ONTAP:
Defina o nível de privilégio como avançado:
set -privilege advancedIndique a chave de dados do disco e as chaves de autenticação dos Federal Information Processing Standards (FIPS) que está a usar:
storage encryption disk showPara cada disco no sistema, defina o ID da chave de autenticação de dados e FIPS para o nó novamente como o MSID predefinido 0x0:
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0Confirme se a operação foi bem-sucedida com o seguinte:
storage encryption disk show-statusRepita o comando
show-statusaté receberDisks Begun == Disks Done. Esta saída significa que a operação está concluída.cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.Remova a configuração do gestor de chaves externo:
Se a ligação HSM estiver ativa, avance diretamente para o passo f. Se a ligação HSM estiver inativa, avance para o passo b.
cluster1::> security key-manager external show-statusAceda ao modo
diagexecutando o comandoset -priv diag.Execute o seguinte comando para mostrar todas as chaves de encriptação de volume.
debug smdb table kmip_external_key_cache_mdb_v2 show.Recolha a propriedade
vserver-id.Execute o seguinte comando para todos os servidores de chaves para eliminar as chaves:
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>.Elimine todos os volumes através da interface do utilizador (IU) do ONTAP ou elimine manualmente os volumes da consola.
Se eliminar a partir da consola, tem de ignorar os volumes raiz dos nós. Normalmente, têm o nome
vol0e um dos nós comovserver. Geralmente, não é permitido eliminar volumes com um nó comovservere não devem ser eliminados.Se não for possível eliminar outros volumes que não
vol0, do passo anterior, da IU, experimente usar a CLI:cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idPara iniciar sessão num cluster de armazenamento a partir da IU, obtenha o nome de utilizador e a palavra-passe do segredo com os seguintes comandos, substituindo CELL_ID pelo ID exclusivo da célula que está a instalar:
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decodeEm seguida, aceda a Volumes, selecione tudo e clique em Eliminar. Tem de repetir várias vezes para cada página. Nota: pode ignorar em segurança um erro que indique que não foi possível eliminar um volume. Consulte a base de conhecimentos da NetApp para ver detalhes.
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
Depois de eliminar todos os volumes, execute o seguinte comando para limpar a fila de recuperação:
recovery-queue purge-all -vserver <vserver>.Execute o seguinte comando para eliminar o gestor de chaves externo:
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>. Após este passo, pode receber o seguinte erro:Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.Este erro indica que existem chaves restantes. Para eliminar as chaves restantes, siga estes passos:
Para apresentar uma lista das chaves restantes, execute o seguinte comando:
security key-manager key queryO resultado é semelhante ao seguinte exemplo:
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Tome nota do valor do ID da chave da saída anterior. Use o comando
security key-manager key delete -key-id+ o valor Key ID para eliminar as chaves restantes:security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Repita os passos i e j para eliminar as chaves restantes. Quando terminar, o resultado é semelhante ao seguinte exemplo:
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. Reponha nós do ONTAP
Para repor nós do ONTAP:
Reinicie o nó para aceder ao menu de arranque através do comando
system node rebootno comando do sistema. Nota: pode ignorar com segurança os avisos de reinício do sistema.Exemplos:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.Se estiver no menu
LOADER, introduzaboot_ontappara continuar com o reinício. Durante o processo de reinício, primaCtrl-Cpara apresentar o menu de arranque quando lhe for pedido. O nó apresenta as seguintes opções para o menu de arranque:(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?Selecione a opção
(9) Configure Advanced Drive Partitioning. O nó apresenta as seguintes opções:* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.Selecione a opção
9ae introduzanoquando lhe for pedido o encerramento. O nó apresenta novamente a seguinte opção após9a:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```Execute a operação
9apara todos os nós de armazenamento existentes no cluster antes de continuar.Para cada nó, execute a opção
9be introduzayespara confirmar.(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.Se existir um par de HA, é apresentada a seguinte mensagem. Certifique-se de que todos os nós no cluster concluíram o passo 9a antes de executar o passo 9b.
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
Quando a mensagem
Welcome to the cluster setup wizardfor apresentada, a reposição está concluída.
6.7. Reponha o Thales k570
Para repor o Thales k570, comece por fazer uma reposição de fábrica do Ciphertrust Manager e, de seguida, reponha o próprio HSM Luna.
6.7.1. Reposição de fábrica do sistema
Crie um diretório de trabalho temporário para as credenciais do HSM:
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIREstabeleça uma ligação SSH ao HSM:
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPSe isto não for possível, estabeleça ligação através de um cabo série do computador à porta da consola. Execute o seguinte comando num separador diferente para obter a palavra-passe
ksadmin.export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeDepois de iniciar sessão na porta série, é apresentada uma mensagem de início de sessão. Introduza o nome de utilizador como
ksadmine cole a palavra-passe do comando anterior.Antes de executar o comando
factory-reset:Evite reiniciar o sistema durante este período, uma vez que a nova associação envolve um reinício múltiplo do sistema e não pode ser anulada.
Certifique-se de que tem uma cópia de segurança de energia.
Execute o seguinte comando para fazer uma reposição de fábrica:
sudo /opt/keysecure/ks_reset_to_factory.shO processo de reposição demora cerca de 10 minutos a ser concluído.
6.7.2. Reposição do HSM Luna
A reposição de fábrica do sistema não limpa a raiz de confiança dos HSMs. Execute os seguintes comandos para repor o HSM Luna:
No anfitrião do CipherTrust Manager, através de SSH ou da consola em série, execute o seguinte comando:
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetElimine o diretório de trabalho temporário do instalador:
rm $TMPPWDDIR
6.8. Reponha firewalls
Para obter instruções sobre como repor as definições de fábrica das firewalls, consulte o artigo Reposição de fábrica da firewall.
6.9. Reponha os comutadores Cisco
Siga os passos seguintes para repor os comutadores Cisco. Tenha em atenção que estas instruções também se aplicam a comutadores de armazenamento, como stgesw.
- Inicie sessão nos comutadores.
Escreva, apague e volte a carregar os interruptores:
write erase reloadSe os switches foram configurados anteriormente e tiver um diretório
cellcfgdisponível, pode seguir a Limpeza prévia.Verifique se os comutadores estão na administração de contas automática (POAP).
Se o comutador for reposto corretamente, deve aparecer a seguinte mensagem quando estabelecer ligação ao mesmo através do servidor da consola:
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. Recursos adicionais sobre o processo de reposição
Para mais informações sobre o processo de reposição, consulte os seguintes recursos:
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html