Rethinking commercial software delivery with Cloud Spanner and serverless

Ben Wilson
Senior Technical Director, Google Cloud Office of the CTO
Gregor Hohpe
Technical Director, Google Cloud Office of the CTO
Remember the olden days when television consisted of just a few major networks and everyone watched the same shows produced by a handful of studios? With the advent of cable TV, the number of channels exploded, promising programming for everyone as creatives wrote and produced more compelling content. Soon, though, we had hundreds of channels filled with infomercials.
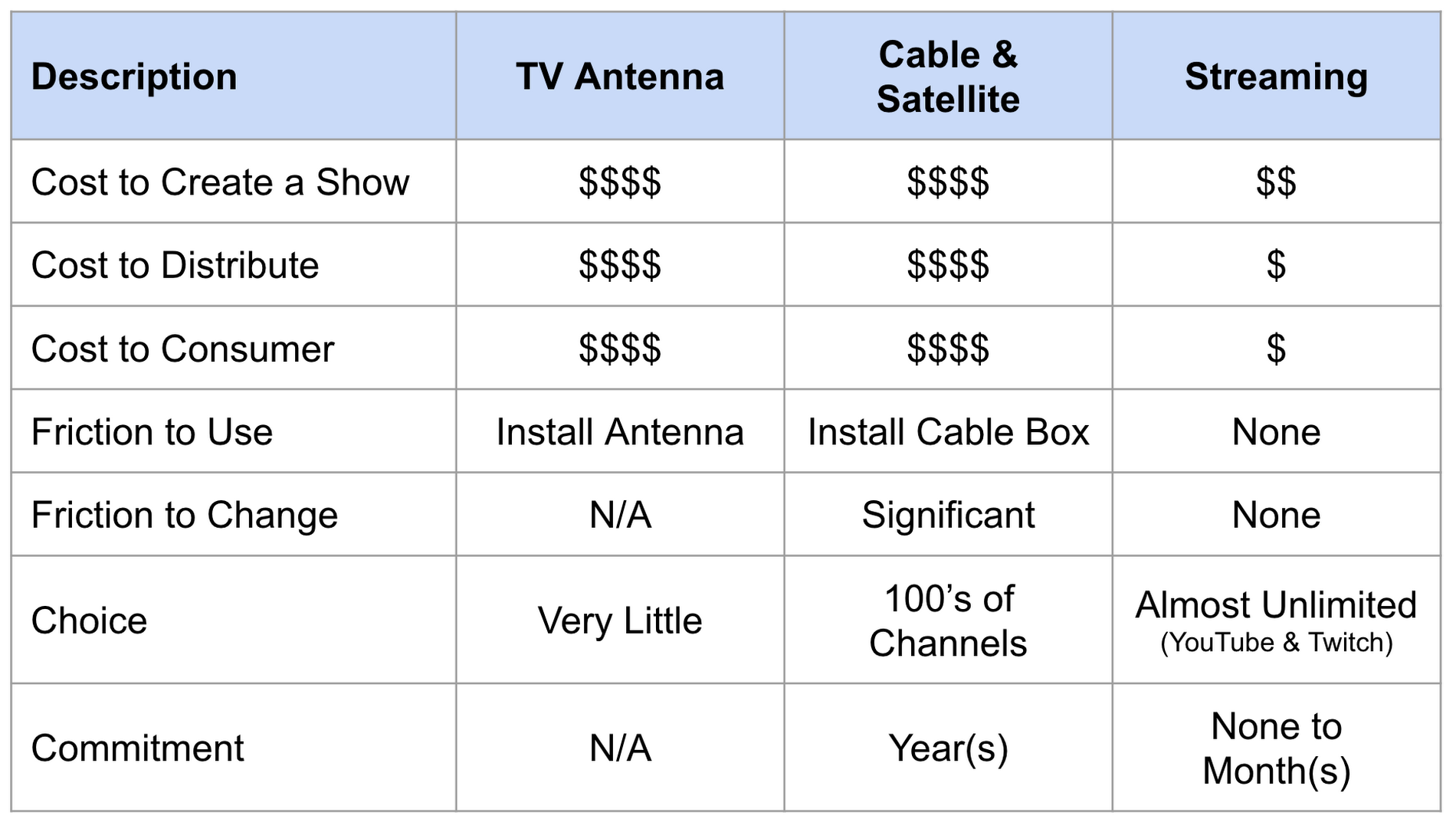
Thirty years later, internet streaming technologies have enabled niche programming for micro-audiences. Independent creatives now have their pick of production studios, and audiences can choose their preferred content and providers with a click of a mouse—not the installation of a new satellite dish or cable box. This is a whole new experience for both the creative and the consumer that has lowered or eliminated barriers to entry and fundamentally changed what media distribution means. It also leaves TV and cable broadcasters scrambling to define themselves in a streaming-first world.
As a former CTO for a number of independent software vendors (ISVs), I anticipate a similar shift for the software industry, thanks to two disruptive technologies: serverless computing and globally distributed databases like Spanner. When used together they can drive down operational costs while allowing for transaction-level billing, enabling hundreds or possibly thousands of niche vendors to enter the market. Cloud providers built a platform for streaming content to any screen in the world and it disrupted the entertainment industry. That same platform will be used to build and deploy next-generation enterprise applications that will be significantly less expensive to distribute and operate, disrupting the software industry.
Snowflake software stacks
But first, let’s talk about why enterprise software development is so hard and so expensive. Commercial software developers aim to create a single pristine code base, but often fork code when customers ask for specialized features or functions. This is sometimes disguised as “user config” but the end result is the same—a forked piece of code. Thus, the software development ideal stands against the commercial pressure to bend to customers’ individual needs. Many of us have sat in those meetings and agreed to customers’ individual development requests because they pay the bills.
Ultimately, customer pressure leads many software companies down a slippery slope towards a segmented deployment of an application that was intended to be deployed identically to all customers. Think about cable TV, how many “forked” channels are there? HGTV to DYI Networks or Lifetime Channel to Lifetime Movie Channel, they may have made some incremental revenue but did they really add value to the customer?
Because each new fork of the code causes additional inefficiencies, a vicious cycle sets in. For example, each customer’s deployment requires sizing of VMs, memory, disk, networking and many other infrastructure elements. Multiplied across many different instances, this results in overprovisioned resources and therefore low hardware utilization. It also leads to multiple sets of test scripts for similar features, inconsistent run books, troubleshooting guides, training of support staff, etc. All this results in higher costs, less effective support, and slower feature releases. These are similar reasons as to why so many cable channels merged in the 2010s—because the cost to maintain them all was too high.
What if this didn’t have to be the case? What if it were possible to drive down the cost to operate, enhance and maintain your products so significantly that a single standard solution worked for almost all customers, if only because the cost was so low? What if software companies could do this while maintaining margins, profitability and cash flow required by CEOs and boards alike? This sounds awesome right? But how?
Solving “The World’s Toughest Problems”
Cloud-native technologies have solved a number of problems that were long considered unsolvable. More than 10 years ago Google developed Spanner, a unique database that became commercially available last year as Cloud Spanner. Cloud Spanner is unique—a scalable, globally distributed, and synchronously replicated database that provides transactional consistency via a SQL-like interface—and it has a 99.999% SLA to boot.
Spanner’s innovation is that it was the first distributed database to provide both strong external consistency and horizontally distributed transactions. It achieves this using True Time based on atomic clocks. In practical terms, it’s no longer possible for two people on opposite sides of the world to grab the last seat at a concert at the same time—Spanner fixes this. With Cloud Spanner, delivering things like “Global Available to Promise” (promising inventory to a specific customer) transactions that were so hard with old-school sharded SQL databases is now a trivial exercise.
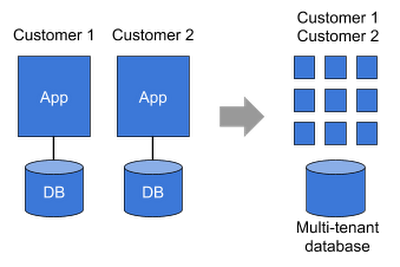
What’s the business benefit? Just as streaming video let broadcasters easily distribute content around the world, Cloud Spanner lets you use a single global, managed, multi-tenant database for all of your customers without needing to deploy and run multiple, separate instances. Having a single, fully managed, secured, production database for all of your customers vastly reduces operational cost and complexity.
Bin packing for (server)less
The second part of the software revolution comes to you courtesy of serverless, which is admittedly a bit of a misnomer because actual servers are still running the code. What’s different about serverless is that developers don’t need to worry about infrastructure like servers. Instead, they can focus on building the code to run a function or transaction that provides value to a customer.
Google was one of the first vendors to popularize serverless computing with App Engine back in 2008. Then, in 2014, AWS introduced Lambda, which takes an event-driven approach to serverless computing, and several others have followed, including Oracle with Fn, Microsoft with Azure Functions and Google with Cloud Functions. Serverless has taken root among our customers, and now, CTOs like the New York Times’ Nick Rockwell are leapfrogging containerization to embrace serverless.
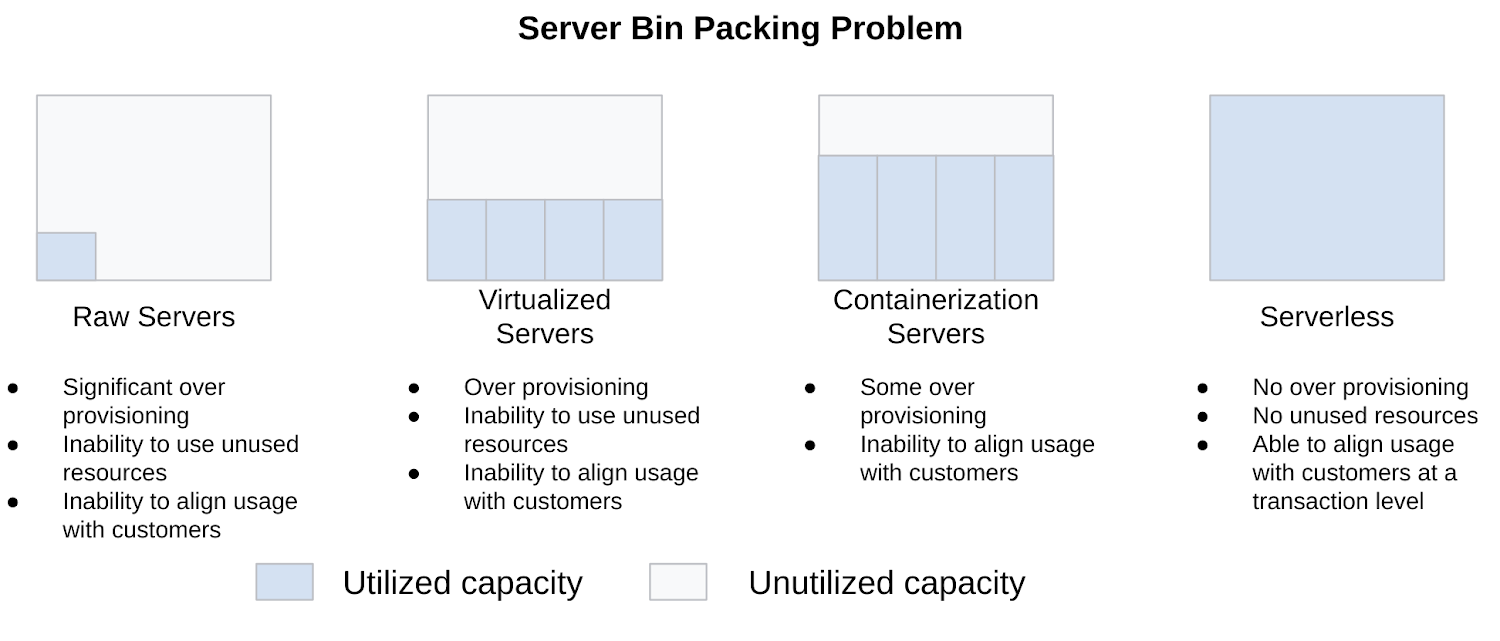
From a CTO perspective, the interesting property of serverless is how gracefully it solves the “server bin packing” problem, helping to better utilize compute assets, especially in light of variable workloads. Virtualization provided the first step to squeezing more out of physical servers, followed by containerization. Now serverless is taking it to the next level by managing smaller units of deployment that can be packed more tightly. Think of it this way: filling a bucket with rocks leaves a lot of empty space; pebbles are better; sand fills the bucket very efficiently.
Big changes, big benefits
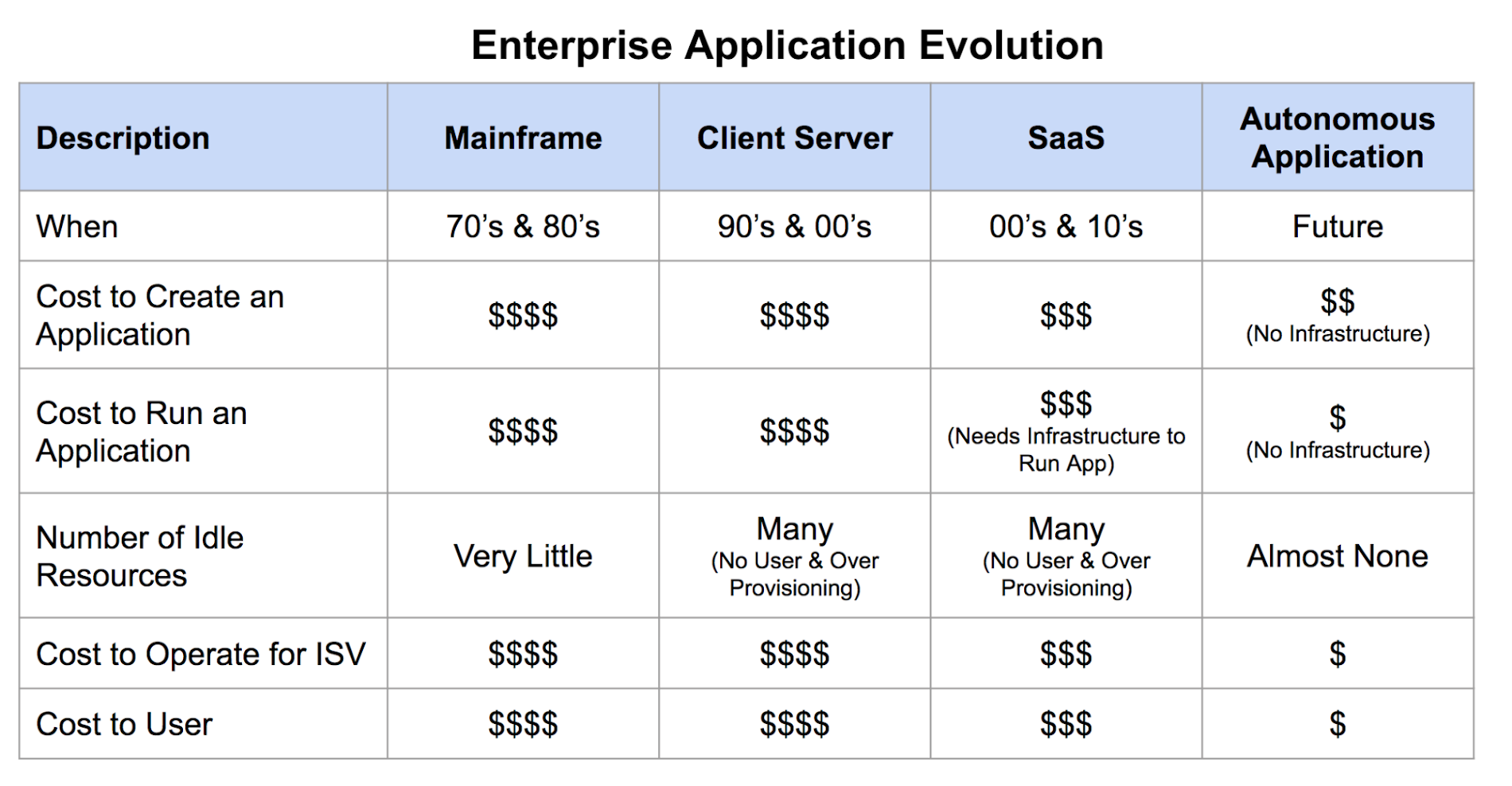
So now that you have a globally consistent and fully managed multi-tenant database in the form of Cloud Spanner, and a globally scalable serverless platform with Cloud Functions, you can build what I call “autonomous applications.” These applications replace a monolithic three-tier application with finer-grained services, each of which can perform a specific business function or transaction. Instead of replicating the deployment for each customer, all customer instances can operate on a single platform in a multi-tenant model, sharing common resources and scaling according to individual and current customer demand.
Shifting to this model brings two major transformations to the existing software development and delivery model:
Reduced operational cost and complexity
Software providers only have to manage the operations of a single instance of their application as opposed to one instance per customer or sets of customers. This reduces operational overhead tremendously and drives down the operational cost per customer.
With a globally scalable multi-tenant database, you can deploy serverless applications globally with very little effort. This architecture minimizes the effort to provision individual application instances, allowing for a single unified CI/CD process. Further, with a single global instance for your application, you get instant feedback on product changes and how to drive more user engagement.
Transparent, transaction-level economics
Existing, monolithic applications and coarse-grained infrastructure make software economics horribly opaque. Not only is it unclear which functionality provides the most value to the customer, you also can’t see which functionality incurs the highest operational cost. Being able to consume infrastructure resources in a consumption model, combined with a transaction-level granularity, brings transparency into software economics through:
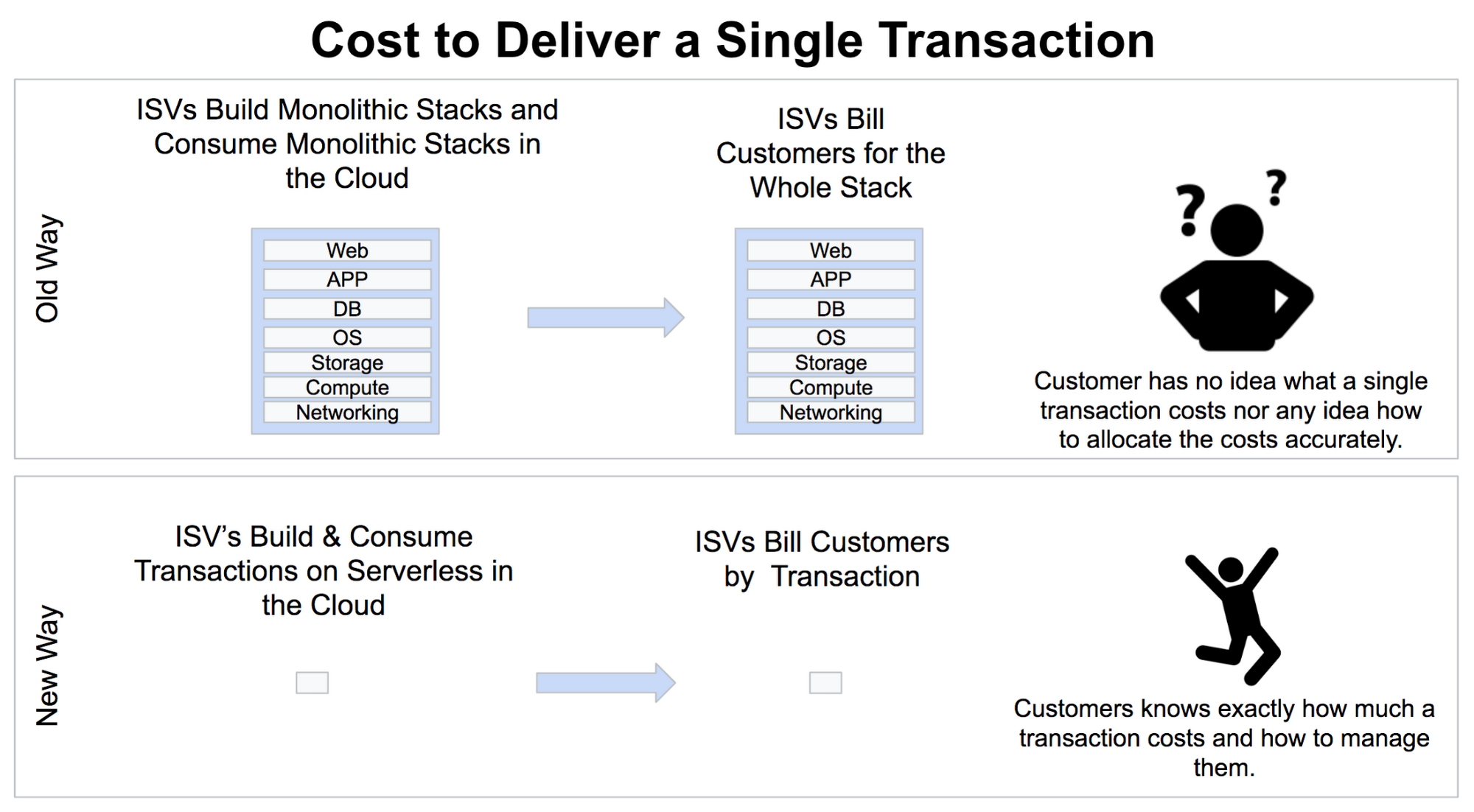
- Cost analysis. Autonomous applications enable transaction-level billing from the cloud provider, providing operational cost allocation to a specific function or transaction instead of a single, monolithic application. This level of transparency allows you to optimize cost, e.g., by deprecating or optimizing expensive functions.
- Feature prioritization. Much like how Netflix can see exactly how much of which shows are watched and how often, every application can provide detailed analytics to help you understand its true usage and the value of a transaction for the customer. Analytics can also give you insight into whether to continue to invest in new features, de-feature transactions that are not well used, or charge more for them to justify continuing to support them.
- Bill per business transaction. Cloud computing has changed how you buy IT infrastructure from an asset-based to a consumption-based model, providing enormous benefits to consumers of IT infrastructure. Cloud Spanner and serverless have the opportunity to elevate this consumption-based model further, to the transaction level. With a single database hosting all your customers, and all compute triggered by atomic functions that can be traced back to a specific customer action, it becomes feasible for the software provider to calculate (and bill for) not just how many resources that customer consumed, but how many actions (transactions) they undertook. Imagine, for example, a Manufacturing Execution System (MES) billing by the product produced, thus aligning specific MES transactions to cost of goods sold (COGS)? Now an ISV’s customers pay for what they actually use and have the ability to align it to COGS, using the same billing model and method regardless of scale.
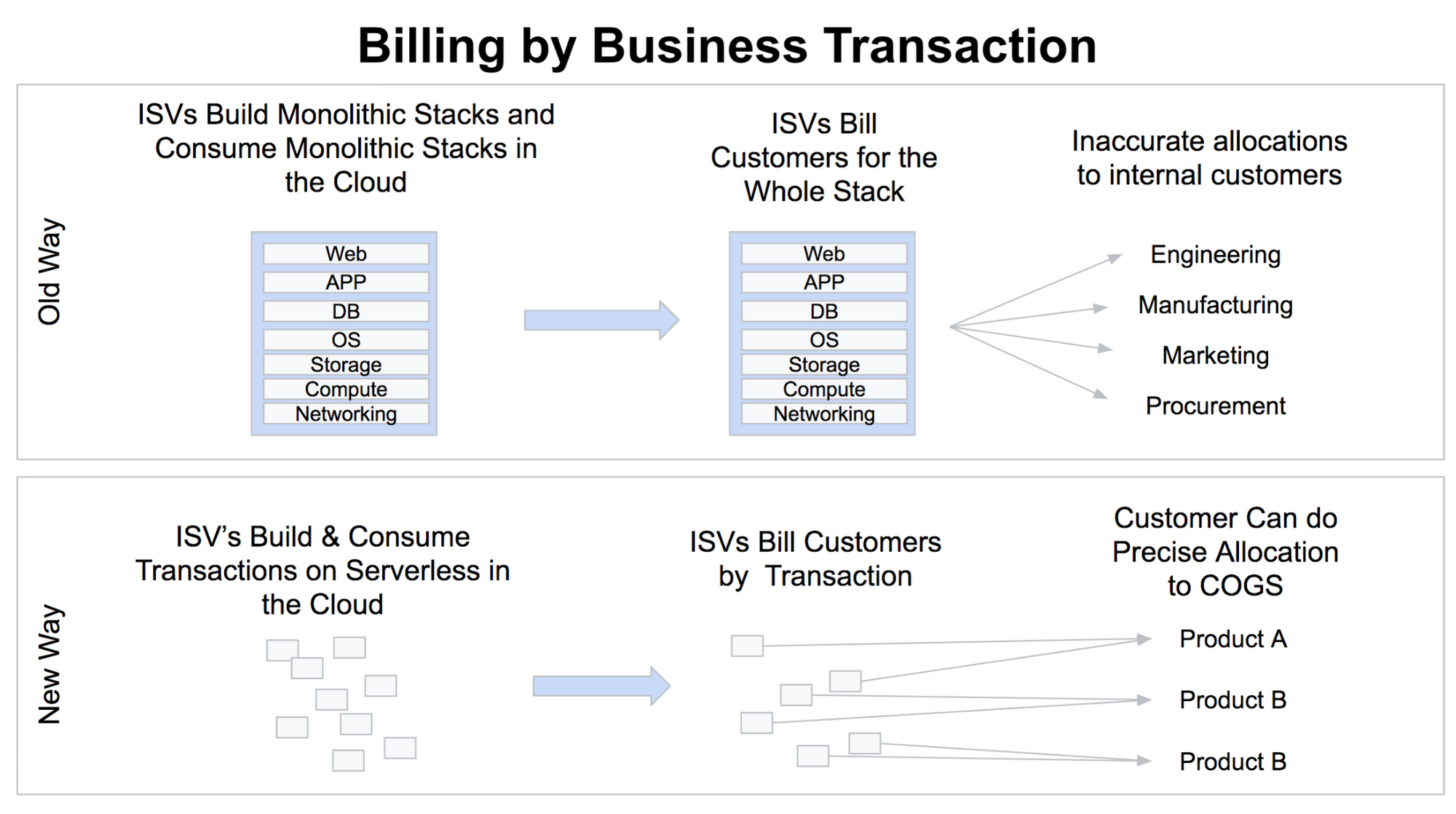
Melting the snowflake
Ultimately, reduced software cost also means that the economic pressure to perform one-off customization is dramatically reduced. A large, monolithic application that carries an up-front investment in the double-digit millions is much more likely to come with a long list of desired customizations than software that’s billed by business transaction with a low or zero upfront investment. Incentives for both the software provider and the consumer are aligned towards driving consumption, not to bill for professional services to build customizations.
Looking ahead
As a CTO, I see this model as a huge opportunity to align feature innovation and delivery directly to customer value, charging for that value on a micro-transaction basis. Now your design decisions and feature prioritization can be based on data, such as transaction volume and cost per transaction. It will also drive down your operational costs, making it easier to enter markets that were previously closed because of the high technical overhead.
We will see software companies that understand this seismic shift in the industry drive down the cost of enterprise applications and grab market share away from traditional players. These companies will likely be more valued because:
- Reduced friction - Lower prices and billing on the basis of transactions rather than users translates to reduced friction that drives revenue faster.
- Cost / revenue alignment - Increases or decreases in market share align almost perfectly to infrastructure costs rather than resulting in underutilized resources.
- Transparency - You can see the revenue generated via application transaction volume daily or even hourly, rather than the annualised method used today that is prone to year-end cancellation surprises.
Increasingly, CTOs have the tools they need to delight customers and investors while increasing revenue accretion and widening gross margins. It may sound too good to be true, but just like binge-watching Netflix was once inconceivable, technologies like Cloud Spanner and serverless computing are enabling scenarios that would have seemed like science fiction just a few years ago.

