Get fast, reliable messaging with IBM MQ on Compute Engine

Ron Pantofaro
Solutions Architect, Google Cloud Platform
Robert Parker
IBM MQ development, IBM
Moving data is one essential task for enterprises today, especially if you’re using lots of different systems across many locations. One product for this is IBM MQ, which helps you move data dependably with secure messaging. Deploying a highly available IBM MQ cluster in the cloud is not a straightforward task, and IBM provides many clustering configurations you can use and combine in various ways to achieve your high availability goals. It’s challenging to deploy a cluster like this in a way that takes advantage of cloud’s benefits, like multiple zone availability, load balancers and vertical scaling. But once you’ve got it set up, you can safely move, integrate and process data from within applications across your organization quickly and securely, with multiple petabytes of data processed.
We’ve heard that you want to know how to use a tool like IBM MQ as part of your Google Cloud Platform (GCP) deployment, specifically Compute Engine. We’re pleased to introduce this guide to how to deploy a highly available IBM MQ Queue Manager Cluster on Compute Engine with GlusterFS. GlusterFS is an open-source, scale-out storage system that works well for this purpose because it is designed for high-throughput storage shared between instances and requires little effort to set up.
Using queue managers to build the IBM MQ cluster
In this solution, we recommend combining queue manager clusters with multi-instance queue managers (instances of the same queue manager configured on different servers) to create a highly available, scalable IBM MQ deployment. Multi-instance queue managers run in an active/standby configuration, using a shared volume for configuration and state data. Clustered queue managers share configuration information using a network channel and can perform load balancing on incoming messages. However, the message state is not shared between the two queue managers.
By using both IBM MQ cluster deployment models at once, you can achieve redundancy at the queue manager level and then scale by distributing the load of the IBM MQ cluster across one or more queue managers.You can see the architecture of the deployment in this diagram:
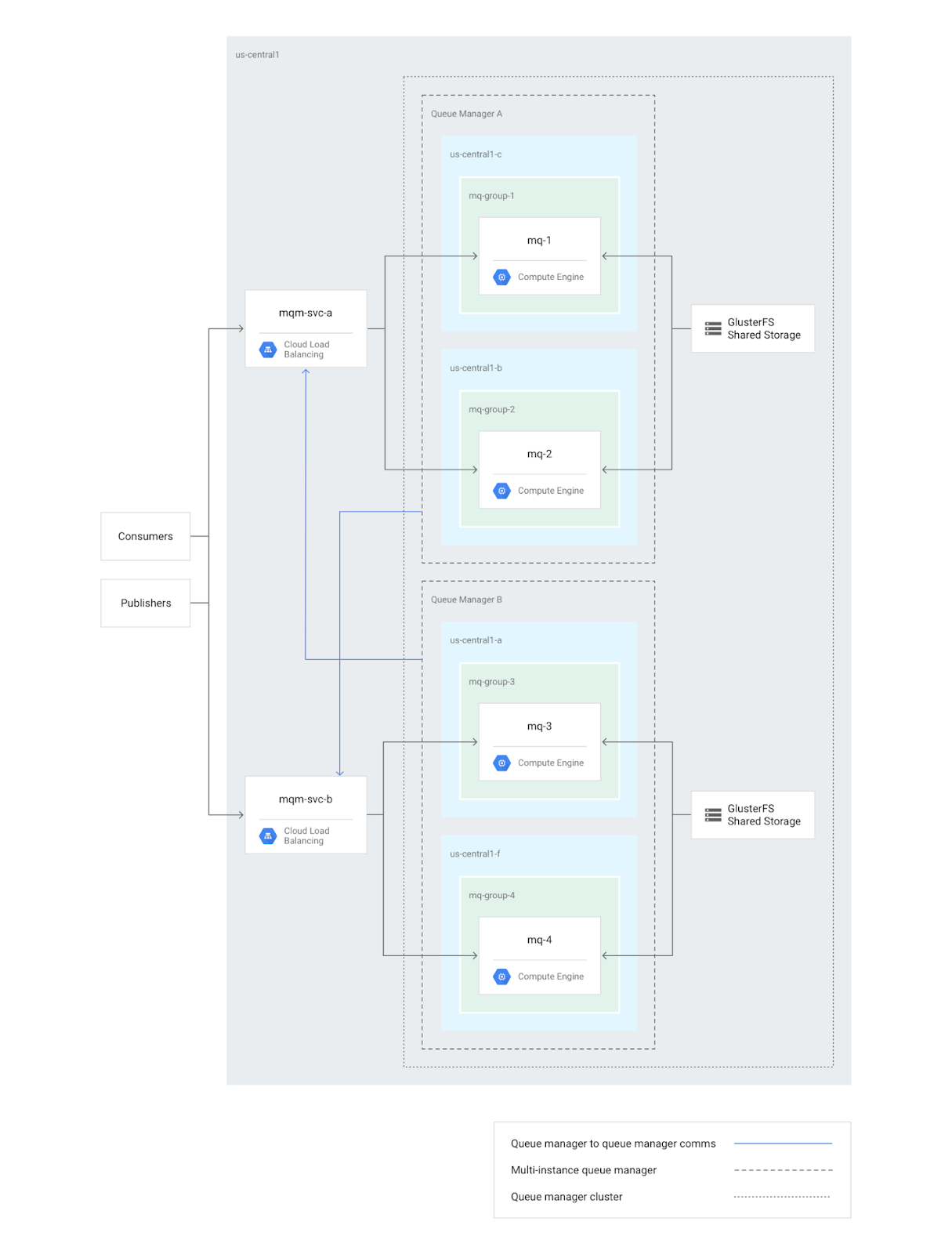
There are two queue managers shown here, referred to in the diagram as A and B. For each queue manager, there is a primary node and standby node (mq-1 and mq-2 for queue manager A, and mq-3 and mq-4 for queue manager B). To route traffic to the primary instances, the solution leverages internal load balancers, one for each queue manager. Consumers and publishers end up at the load balancer addresses as if those were the direct queue managers’ addresses. The queue managers communicate with each other through the internal load balancers as well.
IBM MQ multi-instance queue managers require shared storage. In this tutorial, we use GlusterFS, a distributed, scalable file system, as a shared file system between the nodes of each multi-instance queue manager. You may choose to use other shared storage systems, such as IBM Spectrum Scale File System (GPFS), NFS on Cloud Filestore, NFS with Elastifile, and more. For more details and to get started building a cluster for better messaging, visit the IBM MQ-Compute Engine solution page to take the tutorial.
Thanks to additional contributions from Ben Good, Solutions Architect, Google Cloud Platform.


