Automated fraud detection with Fivetran and BigQuery
Ankit Virmani
Senior Cloud Data Architect, Google
Kelly Kohlleffel
Senior Global Director-Partner Sales Engineering, Fivetran
In today’s dynamic landscape, businesses need faster data analysis and predictive insights to identify and address fraudulent transactions. Typically, tackling fraud through the lens of data engineering and machine learning boils down to these key steps:
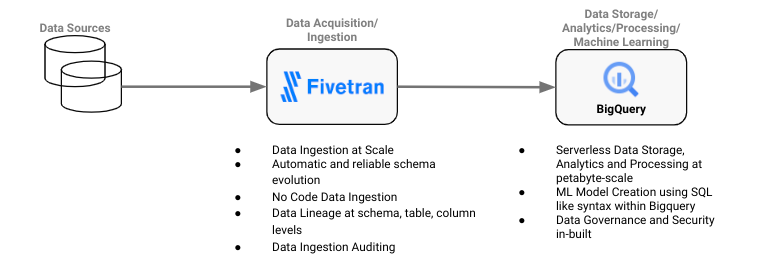
- Data acquisition and ingestion: Establishing pipelines across various disparate sources (file systems, databases, third-party APIs) to ingest and store the training data. This data is rich with meaningful information, fueling the development of fraud-prediction machine learning algorithms.
- Data storage and analysis: Utilizing a scalable, reliable and high-performance enterprise cloud data platform to store and analyze the ingested data.
- Machine-learning model development: Building training sets out of and running machine learning models on the stored data to build predictive models capable of differentiating fraudulent transactions from legitimate ones.
Common challenges in building data engineering pipelines for fraud detection include:
- Scale and complexity: Data ingestion can be a complex endeavor, especially when organizations utilize data from diverse sources. Developing in-house ingestion pipelines can consume substantial data engineering resources (weeks or months), diverting valuable time from core data analysis activities.
- Administrative effort and maintenance: Manual data storage and administration, including backup and disaster recovery, data governance and cluster sizing, can significantly impede business agility and delay the generation of valuable data insights.
- Steep learning curve/skill requirements: Building a data science team to both create data pipelines and machine learning models can significantly extend the time required to implement and leverage fraud detection solutions.
Addressing these challenges requires a strategic approach focusing on three central themes: time to value, simplicity of design and the ability to scale. These can be addressed by leveraging Fivetran for data acquisition, ingestion and movement, and BigQuery for advanced data analytics and machine learning capabilities.
Streamlining data integration with Fivetran
It’s easy to underestimate the challenge of reliably persisting incremental source system changes to a cloud data platform unless you happen to be living it and dealing with it on a daily basis. In my previous role, I worked with an enterprise financial services firm that was stuck on legacy technology described as “slow and kludgy” by the lead architect. The addition of a new column to their DB2 source triggered a cumbersome process, and it took six months for the change to be reflected in their analytics platform.
This delay significantly hampered the firm’s ability to provide downstream data products with the freshest and most accurate data. Consequently, every alteration in the source’s data structure resulted in time-consuming and disruptive downtime for the analytics process. The data scientists at the firm were stuck wrangling incomplete and outdated information.
In order to build effective fraud detection models, they needed all of their data to be:
- Curated, contextual: The data should be personalized and specific to their use case, while being high quality, believable, transparent, and trustworthy.
- Accessible and timely: Data needs to always be available, high performance, and offering frictionless access with familiar downstream data consumption tools.
The firm chose Fivetran notably for its automatic and reliable handling of schema evolution and schema drift from multiple sources to their new cloud data platform. With over 450 source connectors, Fivetran allows the creation of datasets from various sources, including databases, applications, files and events.
The choice was game-changing. With Fivetran ensuring a constant flow of high-quality data, the firm’s data scientists could devote their time to rapidly testing and refining their models, closing the gap between insights and action and moving them closer to prevention.
Most importantly for this business, Fivetran automatically and reliably normalized the data and managed changes that were required from any of their on-premises or cloud-based sources as they moved to the new cloud destination. These included:
- Schema changes (including schema additions)
- Table changes within a schema (table adds, table deletes, etc.)
- Column changes within a table (column adds, column deletes, soft deletes, etc.)
- Data type transformation and mapping (here’s an example for SQL Server as a source)
The firm’s selection of a dataset for a new connector was a straightforward process of informing Fivetran how they wanted source system changes to be handled — without requiring any coding, configuration, or customization. Fivetran set up and automated this process, enabling the client to determine the frequency of changes moving to their cloud data platform based on specific use case requirements.
Fivetran demonstrated its ability to handle a wide variety of data sources beyond DB2, including other databases and a range of SaaS applications. For large data sources, especially relational databases, Fivetran accommodated significant incremental change volumes. The automation provided by Fivetran allowed the existing data engineering team to scale without the need for additional headcount. The simplicity and ease of use of Fivetran allowed business lines to initiate connector setup with proper governance and security measures in place.
In the context of financial services firms, governance and complete data provenance are critical. The recently released Fivetran Platform Connector addresses these concerns, providing simple, easy and near-instant access to rich metadata associated with each Fivetran connector, destination or even the entire account. The Platform Connector, which incurs zero Fivetran consumption costs, offers end-to-end visibility into metadata (26 tables are automatically created in your cloud data platform - see the ERD here) for the data pipelines, including:
- Lineage for both source and destination: schema, table, column
- Usage and volumes
- Connector types
- Logs
- Accounts, teams, roles
This enhanced visibility allows financial service firms to better understand their data, fostering trust in their data programs. It serves as a valuable tool for providing governance and data provenance — crucial elements in the context of financial services and their data applications.
BigQuery’s scalable and efficient data warehouse for fraud detection
BigQuery is a serverless and cost-effective data warehouse designed for scalability and efficiency, making it good fit for enterprise fraud detection. Its serverless architecture minimizes the need for infrastructure setup and ongoing maintenance, allowing data teams to focus on data analysis and fraud mitigation strategies.
Key benefits of BigQuery include:
- Faster insights generation: BigQuery's ability to run ad-hoc queries and experiments without capacity constraints allows for rapid data exploration and quicker identification of fraudulent patterns.
- Scalability on demand: BigQuery’s serverless architecture automatically scales up or down based on demand, ensuring that resources are available when needed and avoiding over-provisioning. This removes the need for data teams to manually scale their infrastructure, which can be time-consuming and error-prone. A key part here to understand is that BigQuery can scale while the queries are running/in-flight — a clear differentiator with other modern cloud data warehouses.
- Data analysis: BigQuery datasets can scale to petabytes, helping to store and analyze financial transactions data at near-limitless scale. This empowers you to uncover hidden patterns and trends within your data, for effective fraud detection.
- Machine learning: BigQuery ML offers a range of off-the-shelf fraud detection models, from anomaly detection to classification, all implemented through simple SQL queries. This democratizes machine learning and enables rapid model development for your specific needs. Different types of models that BigQuery ML supports are listed here.
- Model deployment for inference at scale: While BigQuery supports batch inference, Google Cloud’s Vertex AI can be leveraged for real-time predictions on streaming financial data. Deploy your BigQuery ML models on Vertex AI to gain immediate insights and actionable alerts, safeguarding your business in real-time.
The combination of Fivetran and BigQuery provides a simple design to a complex problem — an effective fraud detection solution capable of real-time, actionable alerts. In the next series of this blog, we’ll focus on the hands-on implementation of the Fivetran-BigQuery integration using an actual dataset and create ML models in BigQuery that can accurately predict fraudulent transactions.


