Cloud against the storm: Clemson’s 2.1 million VCPU experiment

Kevin Kissell
Technical Director, Office of the CTO
While the phenomena of climate change are complex, it’s an empirical truth that the number of North Atlantic storms big enough to merit a name each year has increased dramatically in the past 20 years, and is projected to increase further, arguably the most obvious impact on the United States of a shifting global climate. When these storms come ashore, destruction follows, sometimes even death. Authorities face a series of dilemmas as they try to manage the risks to the populations of low-lying coastal areas. When is shelter-in-place the best option, and when must people evacuate? How can evacuations be managed safely and efficiently? When public safety officials get the answers to these questions wrong, tragedy can ensue.
A team at Clemson University has been exploring the use of Google Cloud to improve disaster planning and management in ways that are both scientifically interesting and instructive for users of Google Cloud computing services. And in doing so, they set a new record for the scale of computation on a single problem in a public cloud: 2.1 million cores. It was an adventure that I think is worth sharing.
The problem: Managing evacuation routes
Evacuations from threatened coastal areas are almost entirely done by private automobiles on public roads. The evacuation routes tend to be limited in number and capacity by the terrain and the weather: Bridges and causeways are bottlenecks, and alternate routes across low-lying areas may already be flooded. Optimizing vehicular “throughput” over the available channels is incredibly important—and quite difficult.
Brandon Posey of Clemson, under the supervision of Professor Amy Apon, has been working on building traffic flow models based on streaming data from existing street-level traffic cameras. Machine vision software capable of anonymously distinguishing vehicles and vehicular motion exists, but processing and correlating the feeds from multiple cameras at the necessary scale is a herculean computational task. A single evacuation zone can have thousands of these cameras, and the full cycle of an evacuation, cleanup, and return, can take days, even weeks.
The Clemson team assumed a 10-day cycle for the experiment, and chose an evacuation area with 8500 available camera feeds, which over 10 days generate 2 million hours of video—about 210TB. TrafficVision, a commercial company that participated in the experiment, provided the software for analysis of the video segments, so that vehicle, incident and anomaly detection on an individual video stream could be treated as a “solved problem” for the purposes of the experiment. The problem itself is “embarrassingly parallel,” in that the interpretations of individual video segments are completely independent of one another, and can be done in any order or all at once.
The challenge was in provisioning and operating the infrastructure to run the software at the necessary scale, with the scant advance notice one might have in a real climate emergency. It is simply not practical to have millions of cores “on deck” waiting for a hurricane. Public cloud providers, however, have fungible resources that can be procured at a range of service levels. Non-critical resources can be pre-empted and redeployed for emergency management services. The question becomes whether the computation can be provisioned and executed fast enough, at the necessary scale.
Architecting the solution
One common design pattern in high performance computing on Google Cloud is a “node-out” approach, where the first step is to understand and optimize application performance on a single virtual machine instance “node.” Every application has a “sweet spot” in the space of ratios of CPU cores to memory and other storage, GPUs, and other accelerators. When these can’t be computed from first principles, they are generally straightforward to determine experimentally. And once it has been determined, Google Cloud Platform provides the capability to generate an optimal custom node type that can be carved out of the Google infrastructure, as shown in the diagram below. The customer pays only for the resources actually deployed. The sweet spot for the TrafficVision application was 16 virtual CPUs and 16GB of memory per instance.
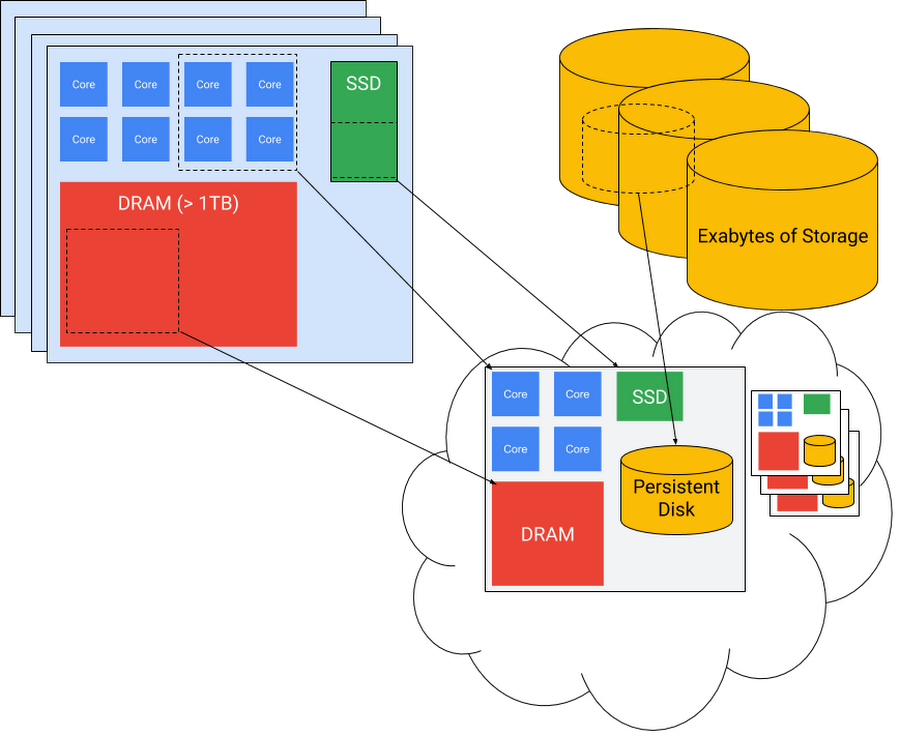
Once the virtual node has been defined, it’s easy to make virtual clusters of them within Google Cloud. These can be persistent or ephemeral, spun up by a job orchestration or batch management system long enough to run the specific work for which they are adapted, at the level of parallel scaling that provides the most cost-effective results, as shown in the following diagram.
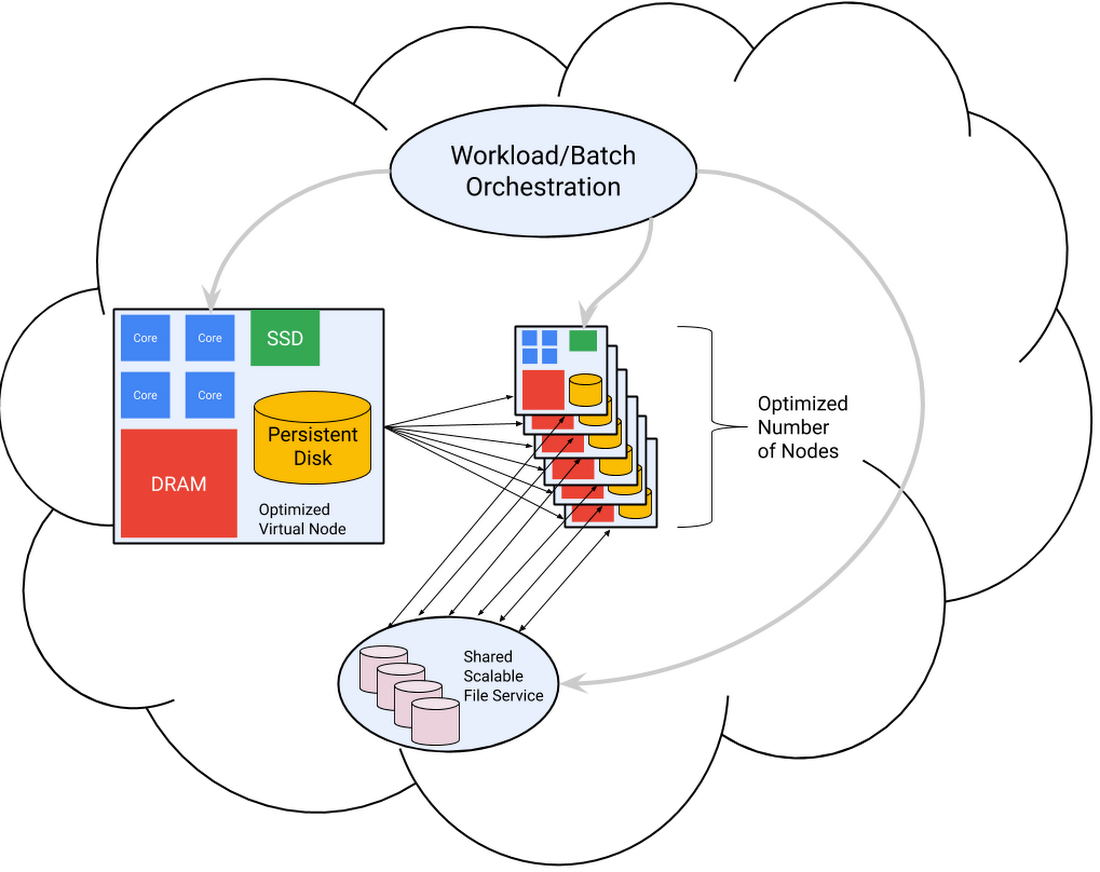
The Clemson team started with this node-out approach. The processing of individual video segments by the TrafficVision software runs most cost-effectively on small virtual nodes, each with 16 VCPU “cores” and 16GB of memory. This memory/CPU ratio is significantly lower than the default for compute VM instances. “Custom-16-16384” became the custom instance type for the worker nodes.
The fact that the processing of the video segments can be done in any order suggested that the team could also take advantage of Google Cloud’s preemptible VMs. These are offered with a discount of up to 80% in return for reduced service levels of availability—the instance can be shut down at any moment, and cannot run for more than 24 hours. Neither of those constraints were problematic for the experiment, since processing time on an individual video is on the order of an hour, not a day, and the small number of jobs that fail because their resources were preempted can simply be restarted.
A tale of scale
But while the nodes of the virtual supercomputer are small, and potentially ephemeral, they are very numerous—up to 2 million of them (now, that’s a tale of scale). To meet this challenge, the Clemson team used their Provisioning And Workflow management tool, PAW (Go Tigers!). PAW is provider- and workflow-agnostic, allowing the team to use GCP infrastructure with CloudyCluster workflow tooling, which had already been demonstrated to work at a million-core scale.
Public cloud services like Google Cloud manage very large pools of resources for large pools of clients. Resource management must necessarily be parallel and distributed to operate at scale. This distribution and parallelism is normally transparent to users, but at the scale of this experiment, it was necessary to understand and adapt to the underlying design.
Fairness is an important property of a multi-user operating system, and Google Cloud enforces it in various ways. One of those is limiting the rate at which one user can make resource requests of the shared infrastructure. With no limit, a malicious (or more likely simply erroneous) script could saturate the resource management system, acting as a de facto denial-of-service (DOS) attack. Google Cloud solves this problem by putting quotas on the number of GCP REST API requests that can be made per 100 seconds. The default is 2000. At a minimum, an API request is made to create each VM instance, and another is required to delete it when it is no longer needed.
2000 API calls per 100 seconds, 20 per second, is more than enough for most applications, but at the scale of Clemson’s experiment, 93,750 virtual machine instances, it would take more than an hour just to provision or free all the worker nodes. The system supports a tripling of the quota to 6000 per 100 seconds, but even at this level, spinning down after a run would take 26 minutes, during most of which tens of thousands of instances are sitting idle—but nevertheless billable.
The key to solving this problem lies in the fact that these quotas are defined per GCP project, not per customer. By using CloudyCluster to federate multiple GCP projects, each associated with a specific Google Cloud region (which generally corresponds to a data center), the quotas can be combined. Not only can the provisioning of projects happen in parallel, but the per-region provisioning, having higher locality, is generally faster. Within each regional project, CloudyCluster instantiated a SLURM batch scheduler per zone in a further level of parallel distribution and federation.
But while some management processes, like provisioning, would take too long at this scale if one followed the usual cloud playbook, another was so unexpectedly fast on Google Cloud Platform as to create a problem! Getting past 20 instance creations per second was critical to ramping rapidly enough to the required scale, but each instance needs to create an SSH network connection to a CloudyCluster master node. At the full scale of the experiment, with provisioning running open-loop in parallel in multiple zones, the incoming connection rate exceeded the capacity of that node to accept incoming SSH connections, causing some to fail. What was needed was a means to pace instance creation so as not to overwhelm SSH connection services, without increasing the deployment time. Fortunately, Google Cloud provides such a mechanism.
To regulate the flow of creation requests, the Clemson team used batching of GCP API requests. Instead of instance creation running open-loop at the aggregate maximum rate, instances were created in bursts of no more than 5000, with randomized pauses between batches. This allowed administrative connection setup to make enough forward progress to avoid timeouts.
Clemson’s final operational model was something like the diagram below. They spread the work across six Google Cloud geographical regions (and the administrative zones within the regions), to parallelize the provisioning process and get beyond the API rate limitations. This also allowed them to cast a wide net when looking for available preemptible cores.
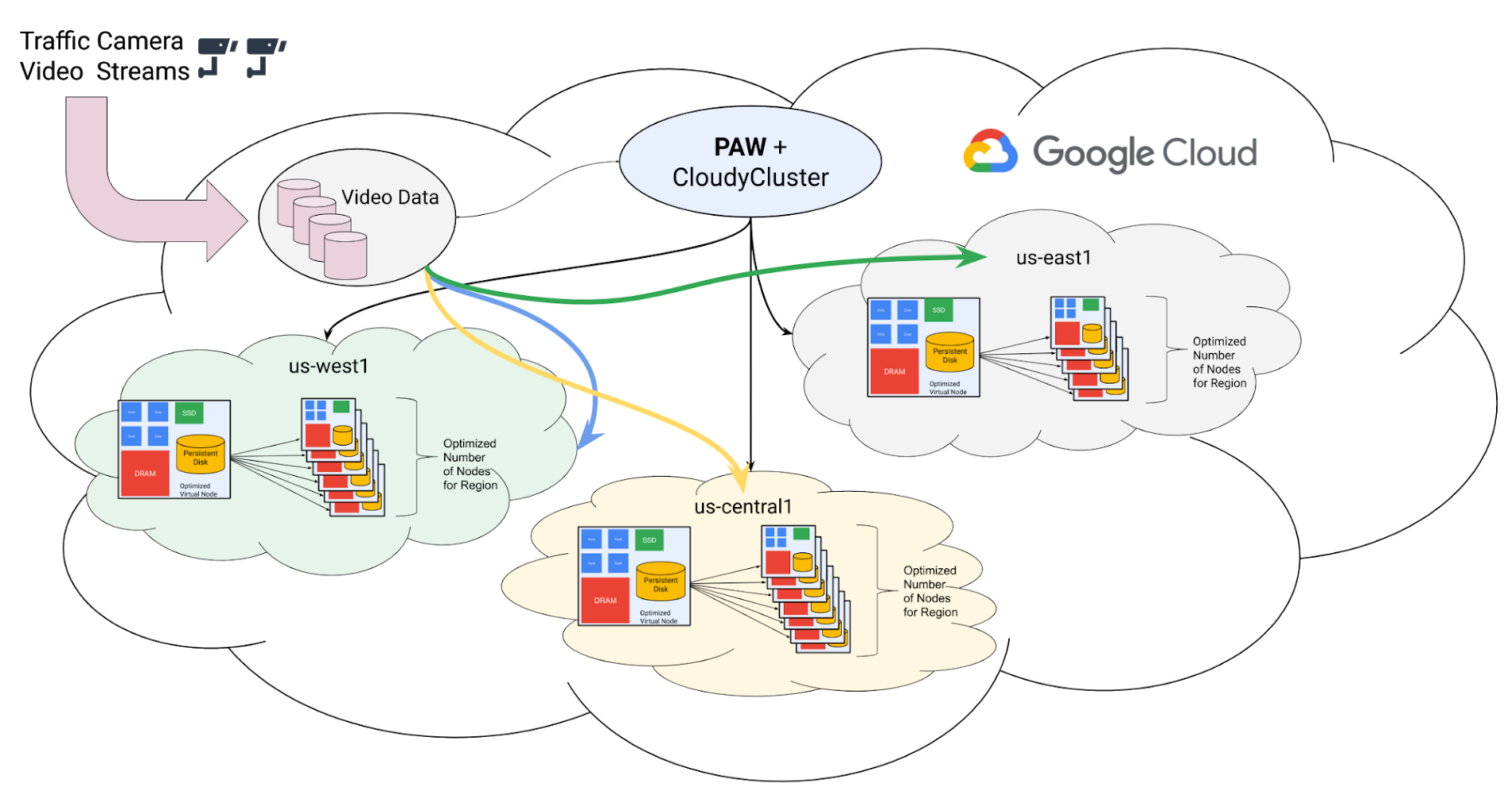
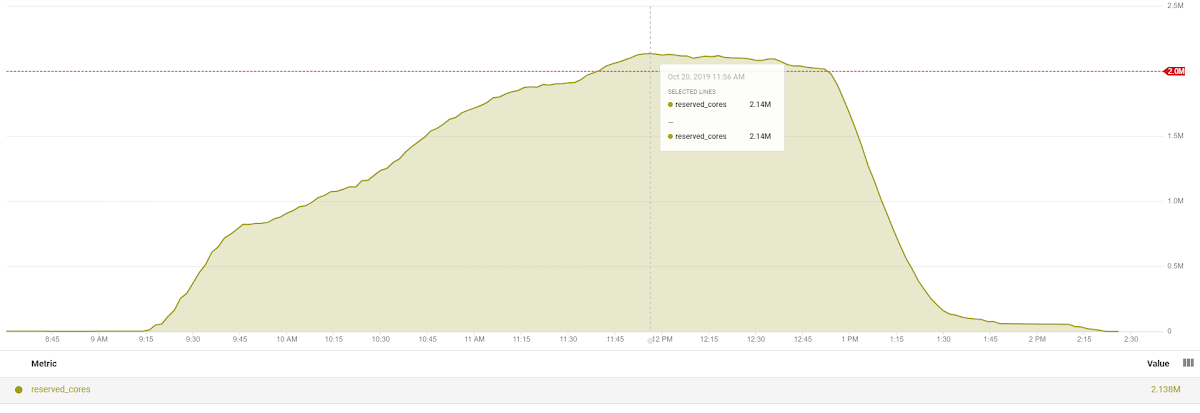
This tuned, hierarchical scheme allowed the Clemson team to successfully scale up to 2.14 million virtual CPUs executing in parallel to analyze traffic video. The chart below shows the ramp-up and ramp-down of active VCPUs running in the experiment. 967,000 were running at the end of the first hour, 1.5 million in 1.5 hours, and 2.13 after 3 hours, with a peak of 133,573 concurrent VM instances. The peak Google Cloud Storage IO throughput was 128 GB/s.
While some ingenuity was required, the experiment was a success. Using Google Cloud, Posey and the Clemson team showed it is possible to draw on worldwide spare capacity to deploy very large scale emergency computations in the interest of public safety. Most hurricane evacuations won’t require the full 2-million-plus virtual CPUs used here to process evacuation data in real time, but it’s reassuring to know that it’s possible. And a source of some pride to me that it’s possible on Google Cloud. Kudos to Brandon Posey and Amy Apon of Clemson University, Boyd Wilson and Neeraj Kanhere of TrafficVision, Dan Speck of the Burwood Group, and my Google colleagues Vanessa July, Wyatt Gorman, and Adam Deer.