Boosting Google Cloud HPC performance with optimized Intel MPI
Mansoor Alicherry
HPC Software Engineer, Cloud ML Compute Services, Google Cloud
Todd Rimmer
Director of Software Architecture, Intel NEX Cloud Connectivity Group
High performance computing (HPC) is central to fueling innovation across industries. Through simulation, HPC accelerates product design cycles, increases product safety, delivers timely weather predictions, enables training of AI foundation models, and unlocks scientific discoveries across disciplines to name but a few examples. HPC tackles these computationally demanding problems by employing large numbers of computing elements, servers, or virtual machines, in tight orchestration with one another and communicating via the Message Passing Interface (MPI). In this blog, we show how we boosted HPC performance on Google Cloud using Intel® MPI Library.
Google Cloud offers a wide range of VM families that cater to demanding workloads, including H3 compute optimized VMs, which are ideal for HPC workloads. These VMs feature Google’s Titanium technology, for advanced network offloads and other functions, and are optimized by Intel software tools to bring together the latest innovations in computing, networking, and storage into one platform. In third-generation VMs such as H3, C3, C3D or A3, the Intel Infrastructure Processing Unit (IPU) E2000 offloads the networking from the CPU onto a dedicated device, securely enabling low latency 200G Ethernet. Further, integrated support for Titanium in the Intel MPI library, brings the benefits of network offload to HPC workloads such as molecular dynamics, computational geoscience, weather forecasting, front-end and back-end Electronic Design Automation (EDA), Computer Aided Engineering (CAE), and Computational Fluid Dynamics (CFD). The latest version of the Intel MPI Library is included in the Google Cloud HPC VM Image.
MPI Library optimized for 3rd gen VMs and Titanium
Intel MPI Library is a multi-fabric message-passing library that implements the MPI API standard. It’s a commercial-grade MPI implementation based on the open-source MPICH project, and it uses the OpenFabrics Interface (OFI, aka libfabric) to handle fabric-specific communication details. Various libfabric providers are available, each optimized for a different set of fabrics and protocols.
Version 2021.11 of the Intel MPI Library specifically improves the PSM3 provider and provides tunings for the PSM3 and OFI/TCP providers for the Google Cloud environment, including the Intel IPU E2000. The Intel MPI Library 2021.11 also takes advantage of the high core counts and advanced features available on 4th Generation Intel Xeon Scalable Processors and supports newer Linux OS distributions and newer versions of applications and libraries. Taken together, these improvements unlock additional performance and application features on 3rd generation VMs with Titanium.
Boosting HPC application performance
Applications like Siemens SimcenterTM STAR-CCM+TM software shorten the time-to-solution through parallel computing. For example, if doubling the computational resources solves the same problem in half the time, the parallel scaling is 100% efficient, and the speedup is 2x compared to the run with half the resources. In practice, a speedup of 2x per doubling may not be achieved for a variety of reasons, such as not exposing enough parallelism, or overhead from inter-node communication. An improved communication library directly improves the latter problem.
To demonstrate the performance improvements of the new Intel MPI Library, Google and Intel tested Simcenter STAR-CCM+ with several standard benchmarks on H3 instances. The figure shows five standard benchmarks up to 32 VMs (2,816 cores). As you can see, good speedups are achieved throughout the tested scenarios; only the smallest benchmark (LeMans_Poly_17M) stops scaling beyond 16 nodes due to its small problem size (which is not addressed by communication library performance). In some benchmarks (LeMans_100M_Coupled and AeroSuvSteadyCoupled106M), superlinear scaling can even be observed for some VM counts, likely due to the increased available cache.
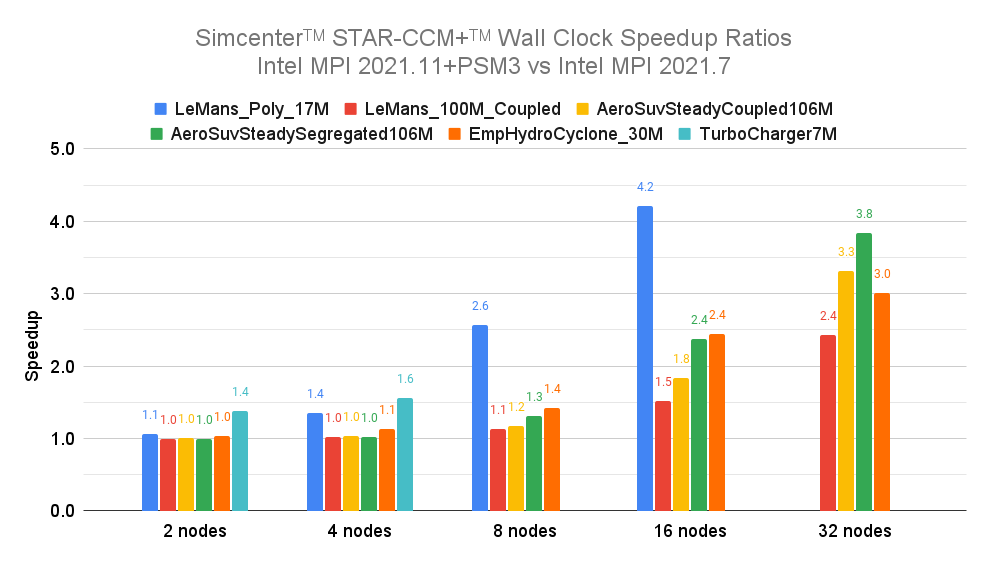
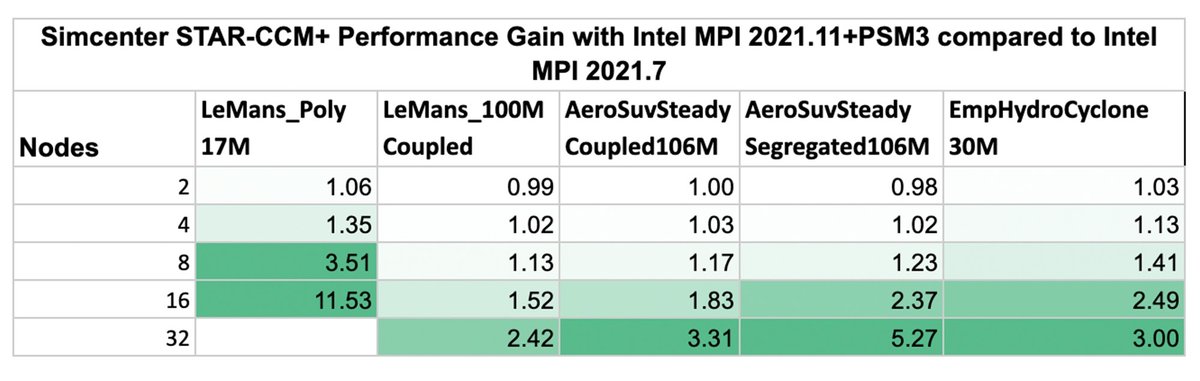
To show the improvements of Intel MPI 2021.11 over Intel MPI 2021.7, we used the ratio of runtimes between the two for each run. This speedup ratio is computed by dividing the parallel runtime of the older version by the parallel runtime of the newer version; we show those speedup ratios in the table below.
The table shows that for nearly all benchmarks and node counts, the optimized Intel MPI 2021.11 version delivers higher parallel scalability and absolute performance. This gain in efficiency — and thus shorter time-to-solution and lower cost — is already present at just two VMs (up to 1.06x improvement) and grows dramatically at larger VM counts (between 2.42x and 5.27x at 32 VMs). For the smallest benchmark (LeMans_Poly_17M) at 16 VMs, there’s an impressive improvement of 11.53x, which indicates that, unlike the older version, the newer MPI version allows good scaling up to 16 VMs.
These results demonstrate that the optimized Intel MPI Library increases the scalability of Simcenter STAR-CCM+ on Google Cloud, allowing for faster time-to-solution for end users and more efficient use of their cloud resources.
Benchmarks were run using Intel MPI 2021.7 and its TCP provider and Intel MPI 2021.11 and the PSM3 libfabric provider. Simcenter STAR-CCM+ version 2306 (18.06.006) was tested on Google Cloud’s H3 instances, with 88 MPI processes per node and 200 Gbps networking, running CentOS Linux release 7.9.2009.
What customers and partners are saying
“Intel is proud to collaborate with Google to deliver leadership software and hardware for the Google Cloud Platform and H3 VMs. Together, our work gives customers new levels of performance and efficiency for computational fluid dynamics and HPC workloads.” -Sanjiv Shah, Vice President, Intel, Software and Advanced Technology Group, General Manager, Developer Software Engineering
Trademarks
A list of relevant Siemens trademarks can be found here. Other trademarks belong to their respective owners.
