Year in Review for BigQuery User Friendly SQL

Jagan R. Athreya
Product Manager, Google Cloud
Early in the year, we shared the new capabilities that made BigQuery SQL more user-friendly than ever in our Valentine’s Day update. In this year-end edition, we are pleased to walk you through new SQL capabilities that we launched in the categories of Enterprise Class, Data Quality and Schema Operations.
Enterprise Class
For our enterprise data analysts, we are pleased to share new capabilities in BigQuery SQL that allow them to manage their workloads using the same familiarity that they may have used in legacy databases and data warehouses.
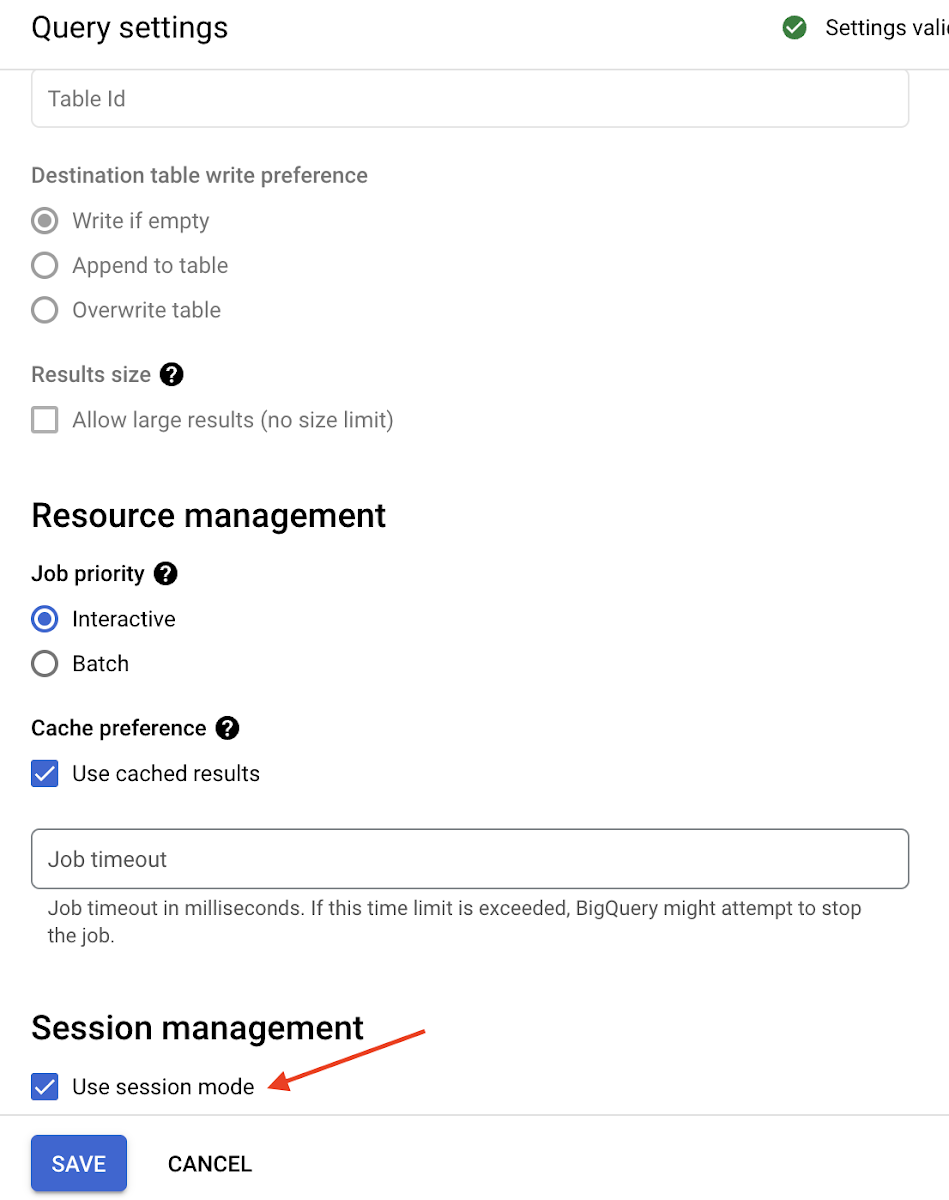
Sessions (GA)
A database session (or session) represents a connection between a user or a program and a database or data warehouse that stores and queries data. A data analyst through a tool or a program may execute multiple commands which are tracked under this session. BigQuery at its heart is a stateless query engine which means it doesn’t maintain a persistent network connection, as traditional database connections do. This allows BigQuery to scale compute and storage independently without limits.
For those enterprise data administrators looking to manage BigQuery activity through sessions, they can optionally enable session support in BigQuery using the UI, API and CLI or can by setting the EnableSession parameter in the JDBC or ODBC driver. This allows enterprises to accrue all the benefits of sessions without the overhead of a persistent connection.
For data analysts, sessions provides the benefits of:
Session variables: which allows the creation of a session-specific variable that is persisted for all commands that get executed in the session.
System variables: Pre-build variables for timezone, dataset identifiers, projects, session identifiers, which if specified, allow the data analysts to override the organization or project level default values with session-specific settings.
Session-duration temporary tables and temporary functions: When temporary tables are used in a session to stage results or a session-specific temporary function is used to make query operations efficient, they are persisted for the entire duration of the session and are accessible to all jobs in that session.
For data administrators, the benefits are:
Session labels: By assigning labels for job tracking, data administrators can find all activities associated with that session using that label in the audit log.
Session management: data administrators can manually terminate sessions by calling the BQ.ABORT_SESSION system procedure with the session ID as input.
BigQuery sessions also support multi-statement queries and transactions. Documentation
Case-insensitive dataset and table names (Preview)
BigQuery tables names and dataset names are case sensitive, by default, reflecting its origins in big data analysis where dataset file names have maintained case sensitivity. To become more user-friendly to the tools and programs brought over by data analysts from their legacy data warehouses, BigQuery now supports case-insensitive table names and schema (dataset) names so that a dataset.Table ≡ DaTaSeT.TABLE ≡ Dataset.table ≡ DATASET.tAbLe in BigQuery. You can configure this in the definition (DDL) for dataset or table using the is_case_insensitive option. Documentation
Data Quality
As data analytics platforms, such as BigQuery, bring data from different sources to help with decision making, data engineers need to maintain the quality of critical data elements. Data sources may be imperfect and have incomplete information. Therefore, data engineers need to configure intelligent defaulting logic when column data is missing to ensure that the right data gets populated. Similarly, data pipelines need to provide flexible logic for numeric data to reduce bias and ensure accurate outcomes. Data analysts need to match text information independent of case to ensure accurate reporting.
Default column value (Preview)
When new rows are inserted into a table, some columns may not have any data. Default value expression allows the specification of a default value using a literal value or a function that computes the default value when the associated column data is missing. The default value specification can be set when creating a new table or by altering the column properties of an existing table. In addition, DML statements such as INSERT or CREATE TABLE AS SELECT or MERGE allow the specification of the defaulting logic in place of an actual inserted value which uses the defaulting specification of the column being inserted into. Documentation
Case-insensitive string collation (Preview)
A collation specification when associated with a column operation, e.g. join, comparison or ORDER BY or GROUP BY clause, determines the logic used to compare or order string values. For example, the default collation specific in BigQuery is ‘binary’ which uses the code point order to specify the ordering sequence in Unicode by which all uppercase letters [A-Z] precede lower case letters [a-z]. We are pleased to offer case insensitive collation, specified using ‘und:ci’ by which [A,a] will be treated as equivalent characters and will precede [B. b] for string value operations. This allows data analysts to find matching string values independent of the case by treating Maclean and MacLean as equivalent. Documentation
Banker’s rounding (GA)
BigQuery has been natively rounding all values that overflow maximum precision using the most common rounding logic: “round half away from zero”. Using “Round half away from zero” exclusively however, can introduce a rounding bias in the data by causing the aggregate operation e.g. sum or average to drift away from the actual value. Other rounding techniques, such as Gaussian rounding, commonly known as banker’s rounding, provide an alternate rounding scheme which does not suffer from negative or positive bias as much as the round half away from zero method over aggregations over most reasonable distributions. With this, BigQuery is pleased to introduce support for multiple rounding modes for columns in table definitions and in the explicit ROUND function: the existing mode of rounding, called “round_half_away_from_zero”, and a new mode, Bankers Rounding, otherwise known as “round_half_even”. The “round_half_even” mode rounds towards the nearest “neighbor” unless both neighbors are equidistant, in which case, round towards the even neighbor, e.g., 3.1 & 3.2 will round to 3 and 3.5 & 4.5 will round to 4. Documentation
Schema operations
Continuing the expansion of SQL syntax for schema operations, BigQuery is pleased to introduce two new SQL capabilities: LOAD DATA to load data into tables and RENAME column to allow existing table columns to be renamed
LOAD DATA (Preview)
This statement provides data engineers and analysts with a SQL interface to load one or more files into tables. It provides the ability to load into a named table, create a new table , or truncate an existing table as a part of the load from all the file types supported by BigQuery including CSV, AVRO, Parquet, JSON, etc. In addition to specifying table options, such as table metadata or table expiration, the LOAD DATA command also allows users to specify partition and clustering schemes as a part of the table specification or from a hive partitioning specification for external files.
LOAD DATA uses the same resource pool as the BigQuery load api to load data. If flat slots customers have configured a PIPELINE reservation, then the LOAD DATA will use the dedicated compute slots from the PIPELINE reservation assignment. Documentation
RENAME column (Preview)
RENAME COLUMN allows users to change a column name in an existing table; this is a metadata only change. Previously, renaming columns required a workaround which required column data to be rewritten. Now, when a column has to be renamed because the current naming is obsolete or was named incorrectly in error, data owners can run a zero cost metadata only command, RENAME column, to fix and correct the column name. Documentation
As we close out this year, we are excited about bringing new capabilities in the new year to you, our BigQuery data aficionados, to make BigQuery SQL more user-friendly than ever.



