Sparse Features Support in BigQuery
Thu Ya Kyaw
Senior Developer Advocate, Google Cloud
Xiaoqiu Huang
Software Engineer, Google Cloud
Introduction
Most machine learning models require the input features to be in numerical format and if the features are in categorial format, pre-processing steps such as one-hot encoding are needed to convert them into numerical format. Converting a large number of categorical values may lead to creating sparse features, a set of features that contains mostly zero or empty values.
As zero values also occupy storage space and sparse features contain mostly zeros or empty values, the effective way of storing them becomes a necessity. We are happy to announce a new functionality that supports sparse features in BigQuery. This new feature efficiently stores and processes sparse features in BigQuery using Array[Struct<int, numerical>] data type.
What are sparse features?
If you have been working with machine learning systems for a while, you may come across the term, sparse features. As most machine learning algorithms require numerical features as input, if the features are in categorical format, pre-processing steps such as one-hot encoding are usually applied to convert them before using them as input features. Applying one-hot encoding to a categorical data column with a large number of categorical values creates a set of features that contains mostly zero or empty values, also known as sparse features.
Given two sentences: “Hello World” and “BigQuery supports sparse features now”. If we are to create a vector representation of those sentences using bag-of-words approach, we will get a result like this

Take a look at how “Hello World” is represented with [0 0 1 0 0 0 1]. There are only two instances of ones and the rest of the values in the vector are all zeros. As you can imagine, if we have a large corpus of text, suddenly we end up with a very large NxM dimension of mostly zeros! So due to its unpredictable nature, sparse features may span from a few columns to tens of thousands (or even more!) of columns.
Having tens of thousands of zero-valued columns isn't a particularly good idea, especially at scale. Not only are the zeros taking up the space, they are also adding additional computation for operations such as lookup. Hence, it is essential to store and process the sparse features efficiently when working with them.
To achieve that goal, we can store only the index of non-zero elements in a vector since the rest of the values will be zeros anyway. Once we have the indices of all the non-zero elements, we can reconstruct the sparse vector by knowing the highest index. With this approach, we can represent “Hello World” with just [(2, 1), (6,1)] instead of [0 0 1 0 0 0 1] like before. If you are familiar with SparseTensor from TensorFlow, this new feature in BigQuery is similar to that.
Working with sparse features in BigQuery
This newly released feature enables efficient storage and processing of sparse features in BigQuery. In this blog post, we will demonstrate how to create sparse features with an example.
First things first – let’s create a dataset with the two sentences: “Hello World” and “BigQuery ML supports sparse features now”. We will also split the sentences into words using the REGEXP_EXTRACT_ALL function.
The result table sentences should look like this
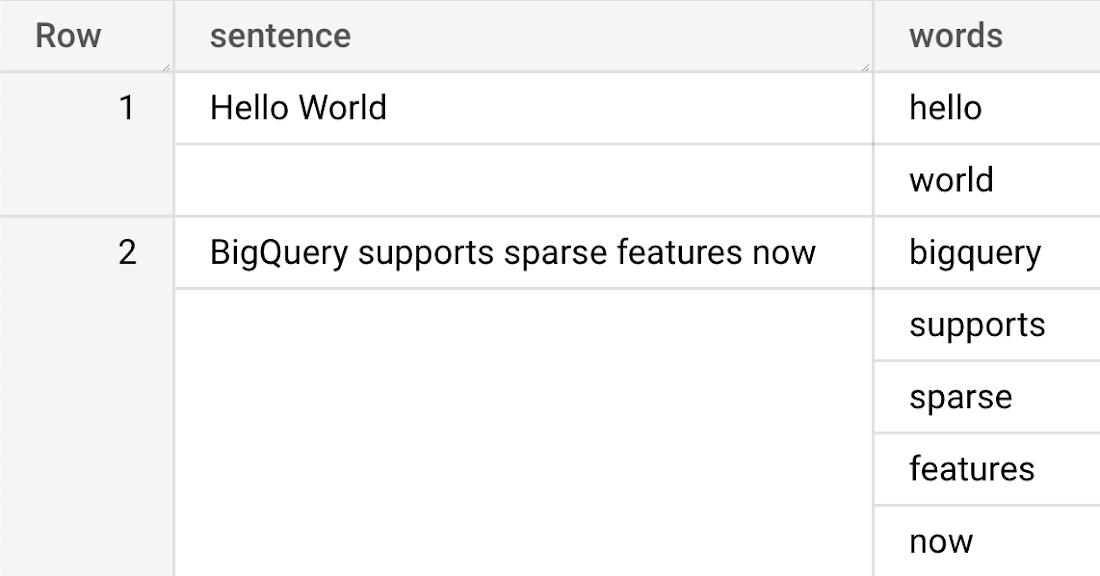
To be able to represent the sentence in vector format, we will create a table to store the vocabulary using all the words from the sentences. It can be done by executing following commands
The vocabulary table will be populated with these information
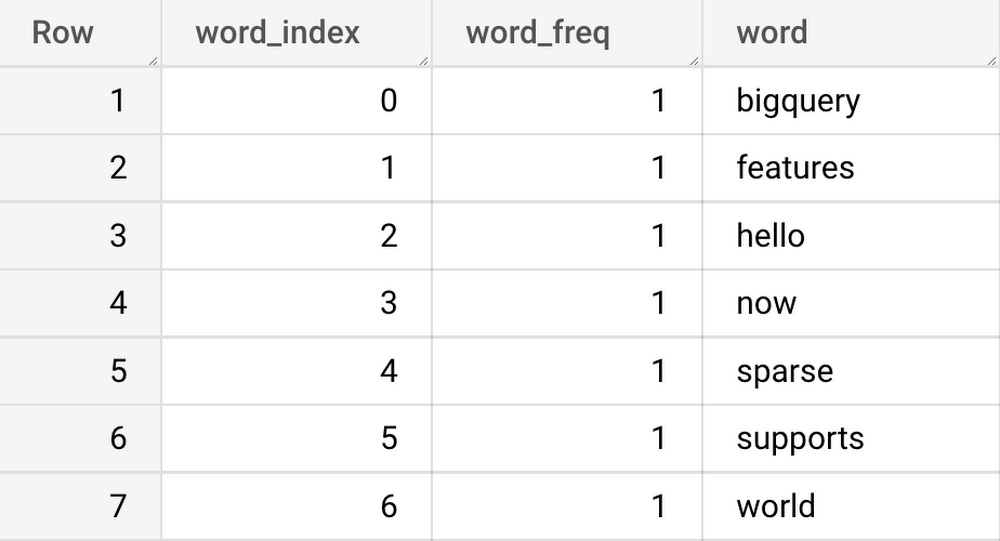
Once we have the vocabulary table, we can create a sparse feature using the new functionality. To create a sparse feature in BigQuery, we just need to define a column with Array[Struct<int, numerical>] type as follows
You should see this result:
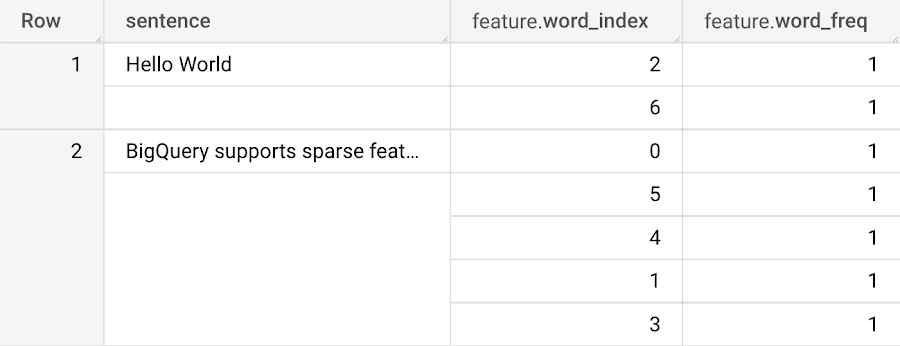
And that's it! We just created a sparse feature using BigQuery. You can then use this feature to train models with BigQuery ML, which would not have been possible without the use of sparse feature functionality.
If you would like to see a complete end-of-end example with spare features on BigQuery, check out this blog post. It starts by using a corpus of movie reviews, generating sparse features using bag-of-words approach, and then training a sentiment classifier on the sparse features using BigQuery ML.



