Search engines made simple: A low-code approach with GKE and Vertex AI Agent Builder
Krishna Chytanya Ayyagari
Generative AI Field Solutions Architect
Samuel Andersen
Senior Customer Engineer
Building a search engine for your website used to be a formidable task that required substantial resources and specialized technical prowess. Not any more. By harnessing the potential of low-code tools and Google Cloud serverless infrastructure, you can build a search engine that’s both smart and simple, with minimal effort on your part.
In this blog, we’ll explore a "low-code search" architecture built on Google Cloud that’s designed to fetch, process, and enable search functionality for content from RSS feeds. Here's a breakdown of its components and workflow:
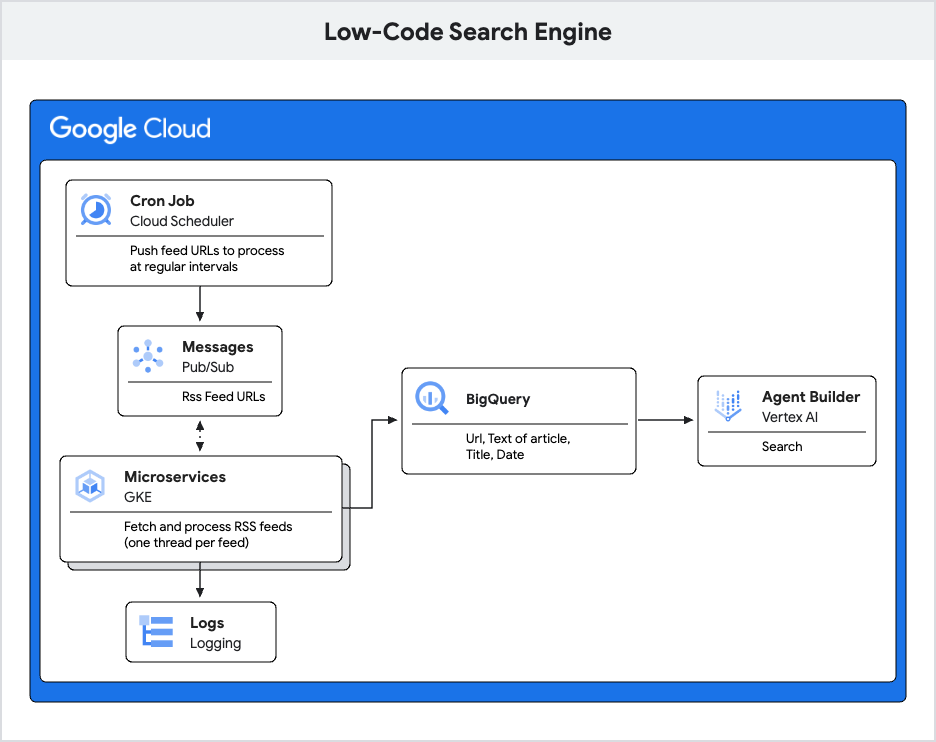
Let’s take a look at the process flow:
-
A cron job, running on a scheduled basis, starts the workflow by transmitting the list of URLs that need to be retrieved to a Pub/Sub service. This service acts as a message broker, distributing the URLs to various microservices.
-
Upon receiving a message from the Pub/Bub service, each microservice fetches and processes the corresponding RSS feed from its assigned URL. This involves extracting relevant information, such as article titles, descriptions, and publication dates.
-
The extracted data is then formatted and loaded into BigQuery, a scalable data warehouse that can handle large volumes of structured data.
-
Next, Vertex AI Search, a powerful search engine platform, comes into play. It leverages the stored data in BigQuery to construct a comprehensive search index. This index allows for efficient and relevant retrieval of information when users perform searches.
-
Users can interact with a search interface, inputting their queries and receiving results based on the indexed content. The search engine retrieves matching documents from the index and presents them to the user.
-
Throughout this entire workflow, logs are diligently recorded. These logs capture information about the execution of the cron job, the message passing within the pub/sub service, the RSS feed fetching and processing activities of the microservices, the data storage in BigQuery, the search index creation by Vertex AI Search, and the user interactions with the search interface. These logs are invaluable for monitoring the system's health, identifying potential issues, and conducting analysis to optimize performance.
Automating search
The schedule for updating search content can be automated using a combination of a cron job and Cloud Scheduler. The cron job, managed by Cloud Scheduler, triggers the workflow at predetermined intervals, such as hourly or daily. This helps ensure regular updates to the search content. Cloud Scheduler also provides message attributes that can be utilized to pass feed URLs to Pub/Sub, facilitating the efficient delivery of updates to the search engine.
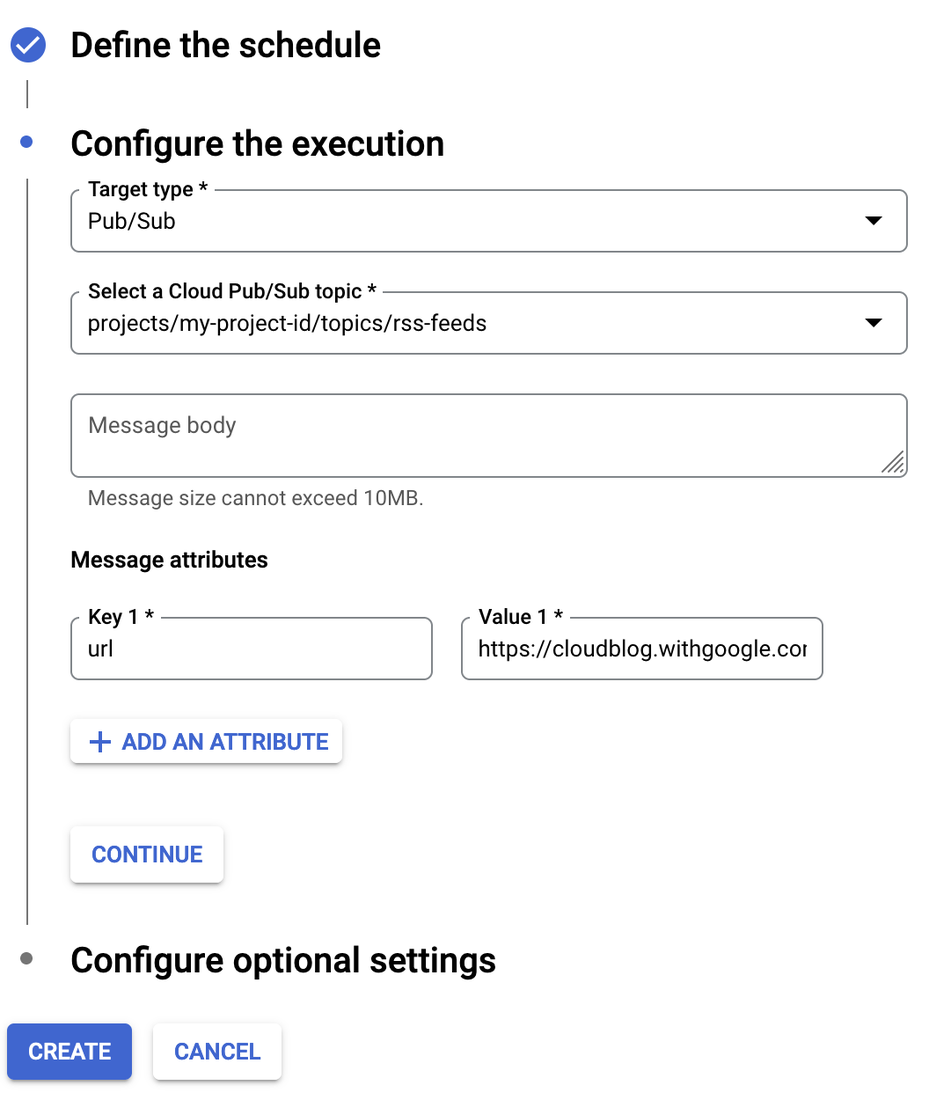
The cron job initiates the process by sending messages to a Pub/Sub topic, which contain RSS feed URLs. These messages act as triggers for the next steps. Microservices running on Google Kubernetes Engine (GKE) receive these messages, fetch RSS feeds, and process their content. The "one thread per feed" approach ensures that each microservice is dedicated to handling a specific RSS feed, enhancing parallelism and efficiency. Once the content is processed, the Pub/Sub streaming client waits for messages from Cloud Scheduler. Upon receiving a message, the client executes the task as per its configuration.
The process of RSS feed ingestion starts with extracting the message URL. Next, the RSS feed is fetched, and each article is iterated through to verify that it has not already been indexed. For new articles, the URL in the RSS feed is followed, and the text of the article is retrieved. Relevant information, such as the author, source, and publish date, is extracted. The new articles are then pushed into the datastore (BigQuery). Using GKE Autopilot Spot Pods helps to optimize costs, as they provide the lowest cost per pod. Since unprocessed messages aren’t acknowledged, killing pods doesn’t disrupt the RSS refresh process.
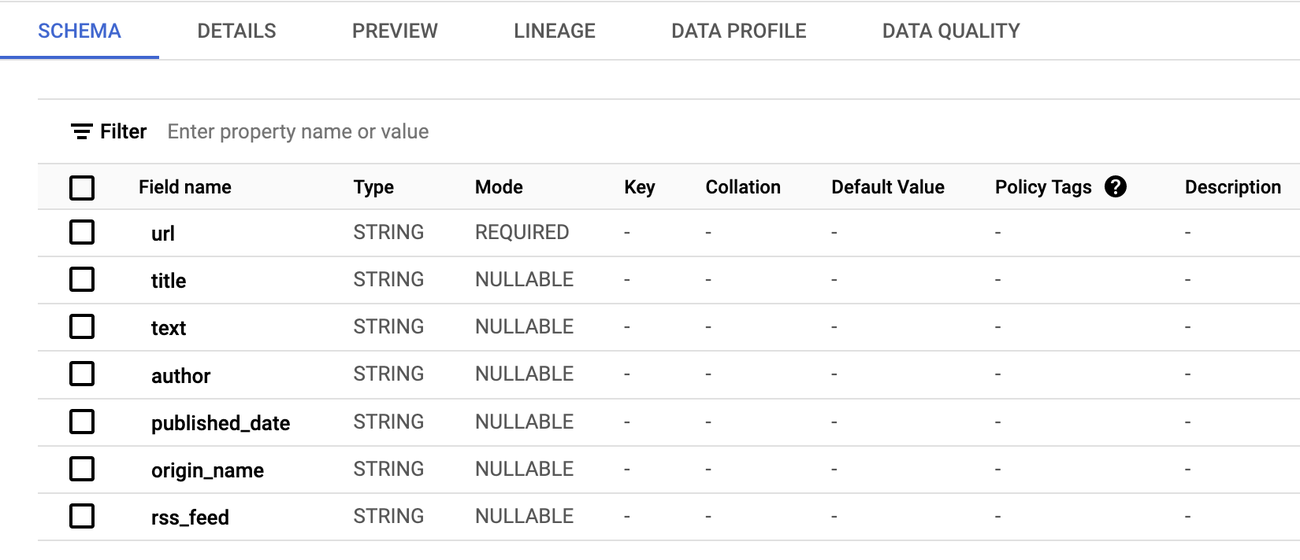
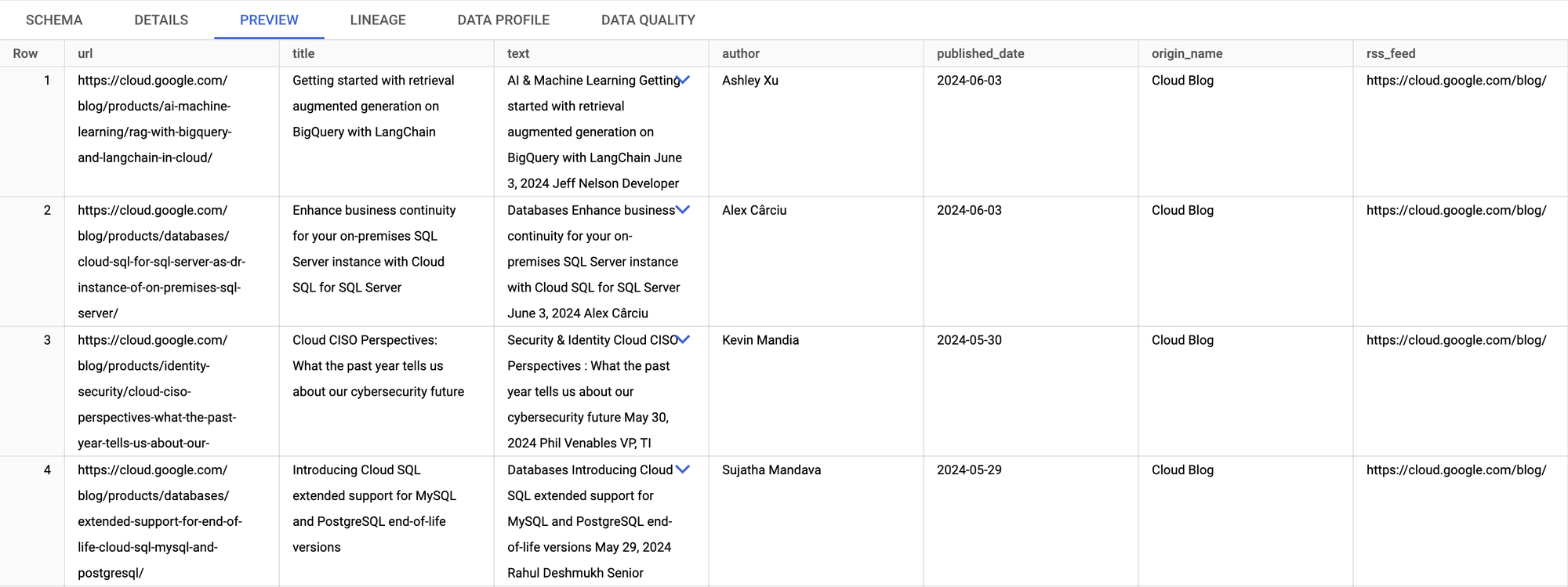
Extracted information from the RSS feeds, such as the URL, article text, title, and date, is stored in BigQuery, which helps ensure efficient storage and easy querying of the extracted metadata, enabling further analysis and insights. In the screenshots below, you can find a sample BigQuery schema and populated data.
Vertex AI Agent Builder and Vertex AI Search are two powerful tools that allow developers to easily create and deploy AI agents and applications. Agent Builder simplifies the process of integrating AI agents or apps with enterprise data, offering a range of options for seamless integration. Vertex AI Search, a part of Agent Builder, helps developers build Google-quality search experiences for websites, structured and unstructured data. It also provides an out-of-the-box grounding system and DIY grounding APIs for building generative AI agents and apps. By indexing data from various sources, including BigQuery, Vertex AI Search enables users to quickly find relevant information through natural language queries. Data stored in BigQuery can be used to create a search index using Vertex AI Search, and Agent Builder can be utilized to customize the search experience or integrate it with other Vertex AI features. Follow this documentation to create a generic "Search" experience with BigQuery as the data store.
The search index allows users to search through the extracted article content using keywords or phrases. Vertex AI Search provides advanced search capabilities, such as natural language processing, ranking, and relevance scoring. Throughout the entire process, logs are generated to capture information about events, errors, or performance. This is crucial for monitoring, debugging, and optimizing the system's operation.
Additional considerations and next steps
This blog post presents a detailed guide on constructing a low-code search engine by leveraging the combined capabilities of GKE, Cloud Scheduler, BigQuery and vector search:
-
Designed for scalability, the architecture handles multiple RSS feeds and large volumes of data.
-
Google Cloud managed services simplify infrastructure management and maintenance.
-
The use of microservices promotes modularity and flexibility for future enhancements or changes.
-
Vertex AI Search provides a powerful foundation for implementing sophisticated search features.
This resulting search engine efficiently searches through RSS feeds and delivers relevant results, making it a valuable tool for users seeking specific information from various sources. For example, you could use it to construct internal knowledge bases, monitor evolving news and trends, or create customized search engines that meet specific requirements such as newsletters.
In this post, we offer a comprehensive guide to building a custom low-code search engine on Google Cloud, using BigQuery, Vertex AI Agent Builder, and Vertex AI Search. Take the chance to create a search engine that fits your needs precisely using our Google Cloud Generative AI github repository.


