Scaling Microservices Applications: From Open Source to Redis Enterprise on Google Cloud
Cody Hill
Staff Solutions Consultant, Google Cloud
Gilbert Lau
Cloud Partner Solution Architect, Redis
Redis excels as a fast caching solution or in-memory database, and is commonly utilized by startups as a self-managed open source technology. But what happens when you eventually outgrow open source limitations and the in-house expertise required to manage OSS deployments? How do you scale without business disruption or data loss? Read on to discover how Google Cloud and Redis make it easy to transition from open source to enterprise-ready as your business grows.
Let’s explore this common scenario for digital-native companies and illustrate it using a hypothetical retailer we will call “Online Boutique”. Online Boutique is a popular online shop that recently launched a digital storefront to connect consumers with its products. This storefront utilizes a microservices architecture running on Google Kubernetes Engine (GKE) in addition to caching with Redis open source.
Online Boutique’s DevOps team is responsible for deploying and scaling this home-grown microservices application in production. Its engineers selected GKE as their Kubernetes engine because it allows their infrastructure to scale to support application and business growth, while guaranteeing a 99.95% uptime SLA.
In order to scale performance and prevent downtime should failure occur, the engineering team set up the microservices to scale out by simply increasing the number of replicas for each instance. The DevOps team decided to implement GKE’s Cluster Autoscaler and Horizontal Pod Autoscaling to allow the cluster and microservices to grow dynamically without human intervention. Online Boutique’s configuration and management approach to Redis open source made it the only service that couldn’t scale automatically once multiple replicas were created. Because Redis stores persistent data, there was a need to ensure that data was consistent between replicas. This required a higher level of orchestration internally and added management complexity.
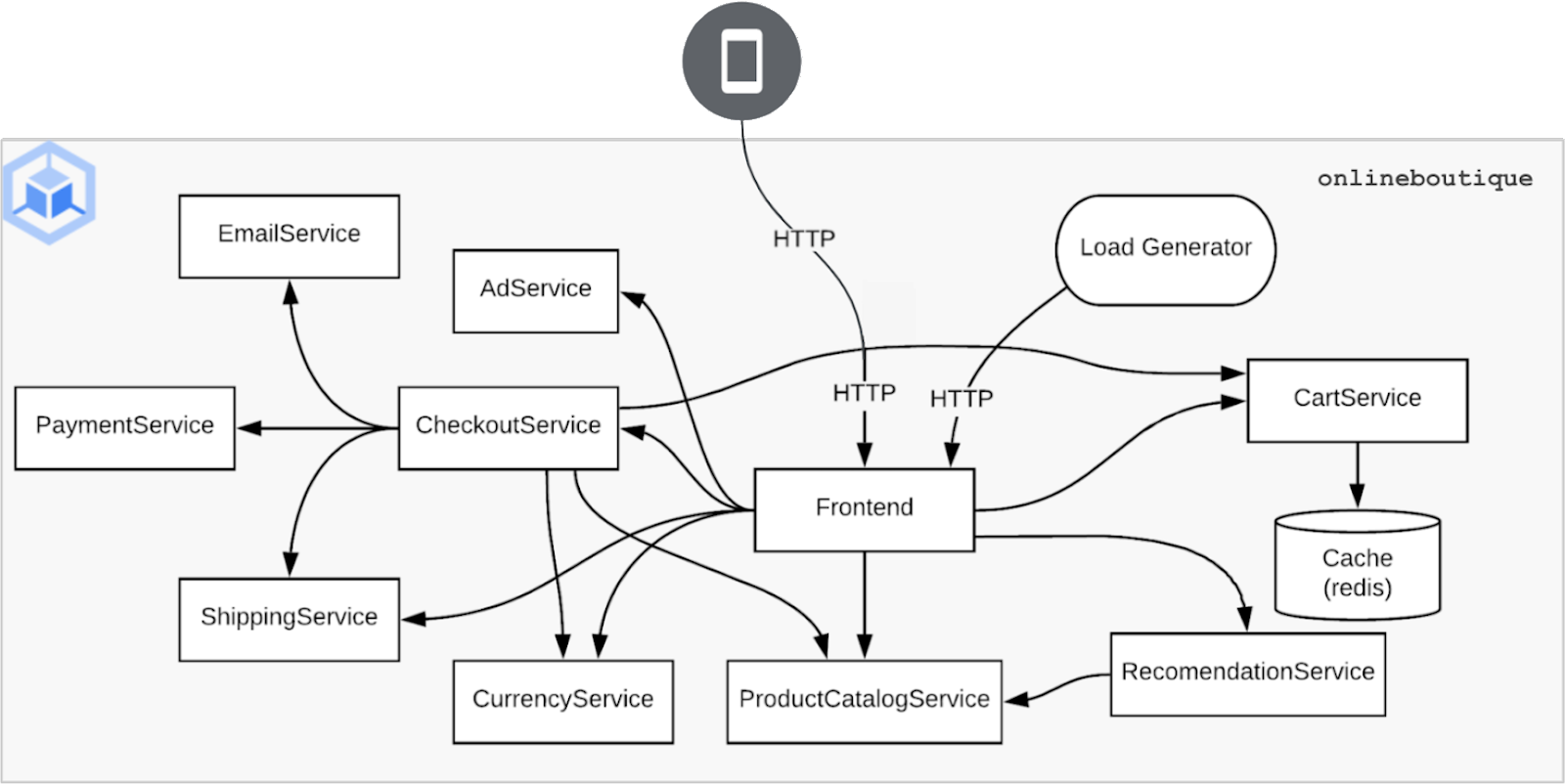
The team had a conversation about the fact that their approach to Redis OSS potentially introduced a single point of failure, and about their need to deploy Redis as a cluster to improve scalability and reliability. With the deadline to launch their online store looming, leadership decided that a single Redis open source database instance would be an acceptable risk for initial launch. When running Kubernetes on the Google Compute Engine (GCE) a service level agreement (SLA) of 99.5% uptime can be achieved, which means that if the Redis instance went down, another node would be recreated and mapped to the persistent volume. The decision to deploy Redis open source as a single instance was made with the promise that this vulnerability would be resolved shortly after launch.
Let’s say a few months go by and it finally happened, it’s 3am and a phone buzzes off the nightstand. There are dozens of notifications that Online Boutique’s online store is down. As a support engineer starts digging into the logs, metrics, and traces using observability tools, they realize that the Redis instance has been restarted 13 times and won’t stay in a “ready” state. After further investigation, it is determined that the sheer number of transactions to this single Redis instance is well over a million per second, which is beyond the upper limit a single Redis open source instance can handle.
Once the engineer had diagnosed the issue, a site event incident (SEV) was triggered to get all hands on deck and bring the site back online. The entire DevOps team was now on a call along with the head of engineering and a few senior software engineers. It was determined that the amount of traffic to the website had overwhelmed their self-managed Redis open source instance, and without the traffic on the website being reduced, the only way to bring things back online was to scale Redis. The team broke into three groups, the first group put up a static landing page for the storefront to let users know the store was temporarily offline. The second group dug into whether the traffic was legitimate or the result of a malicious attack. The third group rehashed conversations from months back on their approach to scaling Redis.
The team discussed a number of different paths they could take, laying out each approach and its pros and cons.
Redis Operator from Artifact Hub
Pros:
Free
Easy procurement process
Can run in existing GKE cluster
Cloud agnostic
Cons:
No support
Requires high level of expertise to deploy, scale, and upgrade
Requires time to design, test, & deploy
Multi-cluster deployments are not supported with this operator, making multi-region availability impossible
No guarantee of scalability
Redis Enterprise on Kubernetes
Pros:
24/7x365 Support
Can run in existing GKE cluster
Cloud agnostic
Free trial available
Easy-to-follow documentation to: deploy, scale, and upgrade
Supports Multi-Cluster deployments to ensure multi-region availability
200+ Million queries per second (QPS)
Cons:
Costs money (after free trial)
Requires some expertise to: deploy, scale, and upgrade
Requires time to: design, test, and deploy
Google Cloud Memorystore
Pros:
24/7x365 Support
99.9% SLA
Fully managed service
Simplified billing through our Google Cloud Account
Minimal expertise needed to: Deploy, Scale, & Upgrade
Instantly deployable
Single pane of glass to manage infrastructure
Cons:
Costs money
Maximum of 1 million queries per second (QPS)
No multi-region availability
Maximum dataset size: 300GB
Not cloud agnostic
Cannot scale writes (read replicas only)
Redis Enterprise Cloud
Pros:
24/7x365 Support
99.999% SLA
Fully managed service
Instantly deployable
Simplified billing through Google Cloud account when using Google Cloud Marketplace
24TB+ dataset size
Requires Flash Storage for 24TB+
Maximum in RAM is 12TB+
Multi-region & multi-cloud availability
Cloud agnostic
Cons:
Costs money (after free trial)
Two panes of glass to manage infrastructure
Due to time pressure to get the application back online, options one and two were eliminated. There was not enough time for the team to design, test, and deploy an open source-based solution that would prevent an event like this from happening again. This left the team considering both SaaS solutions, Google Cloud Memorystore & Redis Enterprise Cloud. After performing an analysis of the two, the only real point of contention was the price. However, after pricing out similarly-sized clusters as accurately as possible on both Google Cloud Memorystore and Redis Enterprise Cloud, the prices were comparable.
Plus, Redis Enterprise Cloud is highly available and persistent with 99.999% SLA to minimize future downtime and data loss. With sub-millisecond latency, support for significantly larger datasets, and the ability to seamlessly scale clusters vertically and horizontally Redis Enterprise on Google Cloud was the clear choice to future proof their application for optimal performance at any scale.
Now, the team had to deploy it and migrate their previous Redis deployment from their self-managed open source instance to Redis Enterprise Cloud with minimal downtime and without losing any data. Deploying proved quite simple through Google Cloud Marketplace which the team was already familiar with. With just a few clicks (there is a Terraform provider too) the team was able to provision a highly available Redis Enterprise database in a matter of minutes. Once the database was created, the team was able to provide a GCP Project and Network name for the GKE cluster and Redis Enterprise Cloud provided a gcloud command to peer the GKE VPC with the Redis VPC. After the peering was complete the GKE cluster could connect to the Redis Enterprise database through the database’s private endpoint.
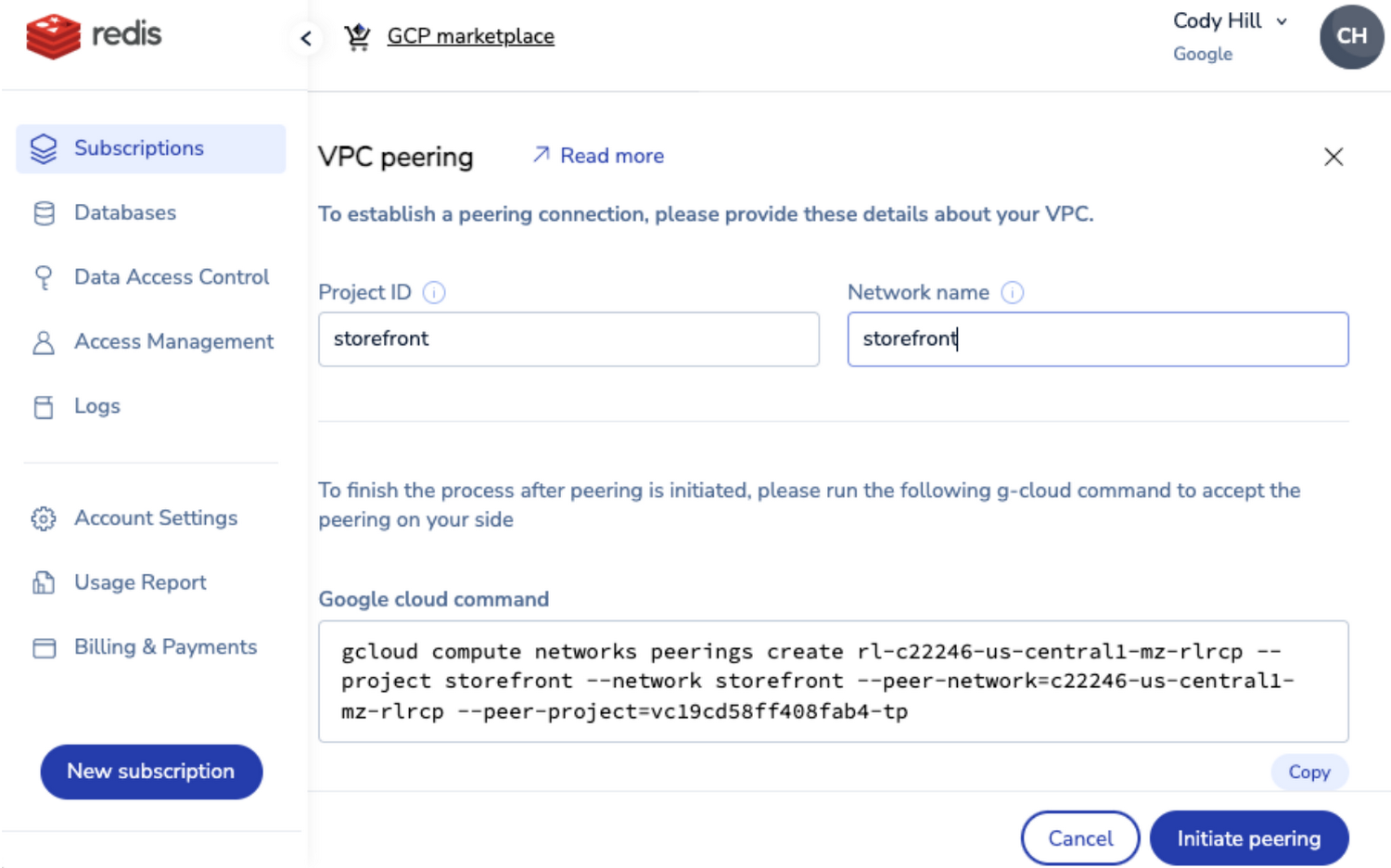
At this point the team needed to get all of the data from the existing Redis database instance into the Redis Enterprise Cloud database. This was done by creating a Kubernetes secret with the connection information for both the local Redis instance and the cloud instance that looked a little something like this:
The team then kicked off a Kubernetes job to migrate the data from the local instance to the cloud instance (which was back online since the static webpage that was put in place took the load off of the failed Redis OSS database). The job looks like this:
Once the job was complete the team was able to update the deployment to point to the new location of Redis using a Kubernetes patch command:
The team ran checks to verify that everything was working properly, and was pleasantly surprised to find that everything “just worked”. The team removed the static webpage, allowing traffic back to the storefront, and got their application back up and migrated without an issue.
The team reconvened and held a retrospective on what happened, lessons learned and how to prevent the same failure from happening again. One question that hadn’t been answered yet was: “How did we get such a surge in traffic?!” Apparently, a social media influencer mentioned how they loved a pair of shoes that were sold on the site, and their entire following decided to browse and shop at the store at the same time. They discovered this through complaints on their own social media account, with shoppers stating they wanted to buy the same shoes, but couldn’t. The social media influencer shoutout would have been a nice problem to have if they could have handled the surge in traffic. Moving forward, this will no longer be an issue and they will be able to scale to meet the needs of their business at any time.
Thanks for following along as we illustrated how to scale a microservices application from open source to Redis Enterprise on Google Cloud to achieve the scalability and high availability your real-time applications need. Visit Google Marketplace to learn more and take advantage of the latest offers like free marketplace credits to help you get started. And don’t take our word for it, deploy this microservices application and test out how easy it is to migrate from Redis open source to Redis Enterprise on Google Cloud for yourself. All of the code and the instructions are located on GitHub!