Sentiment analysis with BigQuery ML
Thu Ya Kyaw
Senior Developer Advocate, Google Cloud
Xiaoqiu Huang
Software Engineer, Google Cloud
Performing sentiment analysis with BigQuery ML using sparse features
Introduction
We recently announced BigQuery support for sparse features which help users to store and process the sparse features efficiently while working with them. That functionality enables users to represent sparse tensors and train machine learning models directly in the BigQuery environment. Being able to represent sparse tensors is a useful feature because sparse tensors are used extensively in encoding schemes like TF-IDF as part of data pre-processing in NLP applications and for pre-processing images with a lot of dark pixels in computer vision applications.
There are numerous applications of sparse features such as text generation and sentiment analysis. In this blog, we’ll demonstrate how to perform sentiment analysis with the space features in BigQuery ML by training and inferencing machine learning models using a public dataset. This blog also highlights how easy it is to work with unstructured text data on BigQuery, an environment traditionally used for structured data.
Using sample IMDb dataset
Let’s say you want to conduct a sentiment analysis on movie reviews from the IMDb website. For the benefit of readers who want to follow along, we will be using the IMDb reviews dataset from BigQuery public datasets. Let's look at the top 2 rows of the dataset.
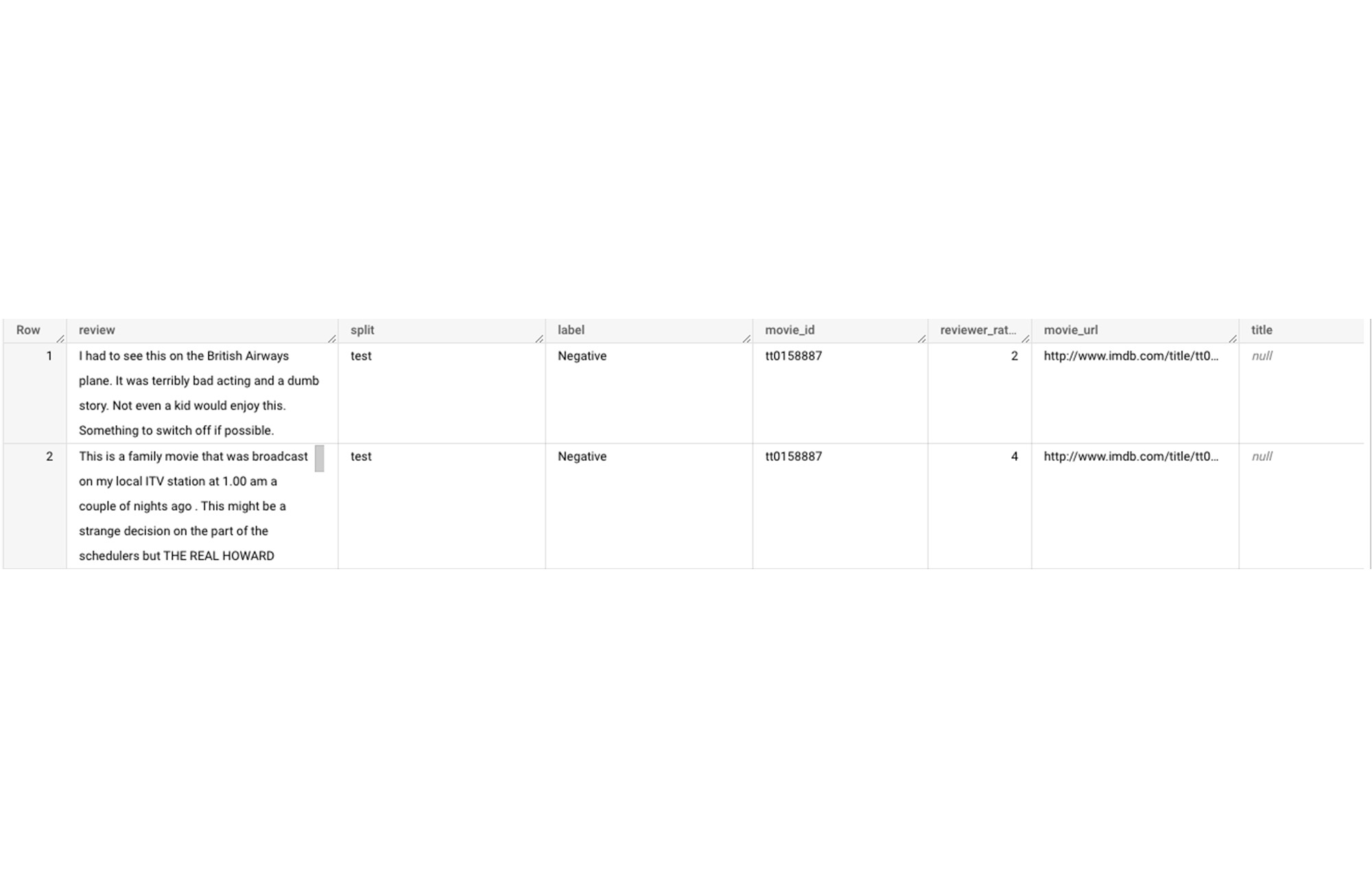
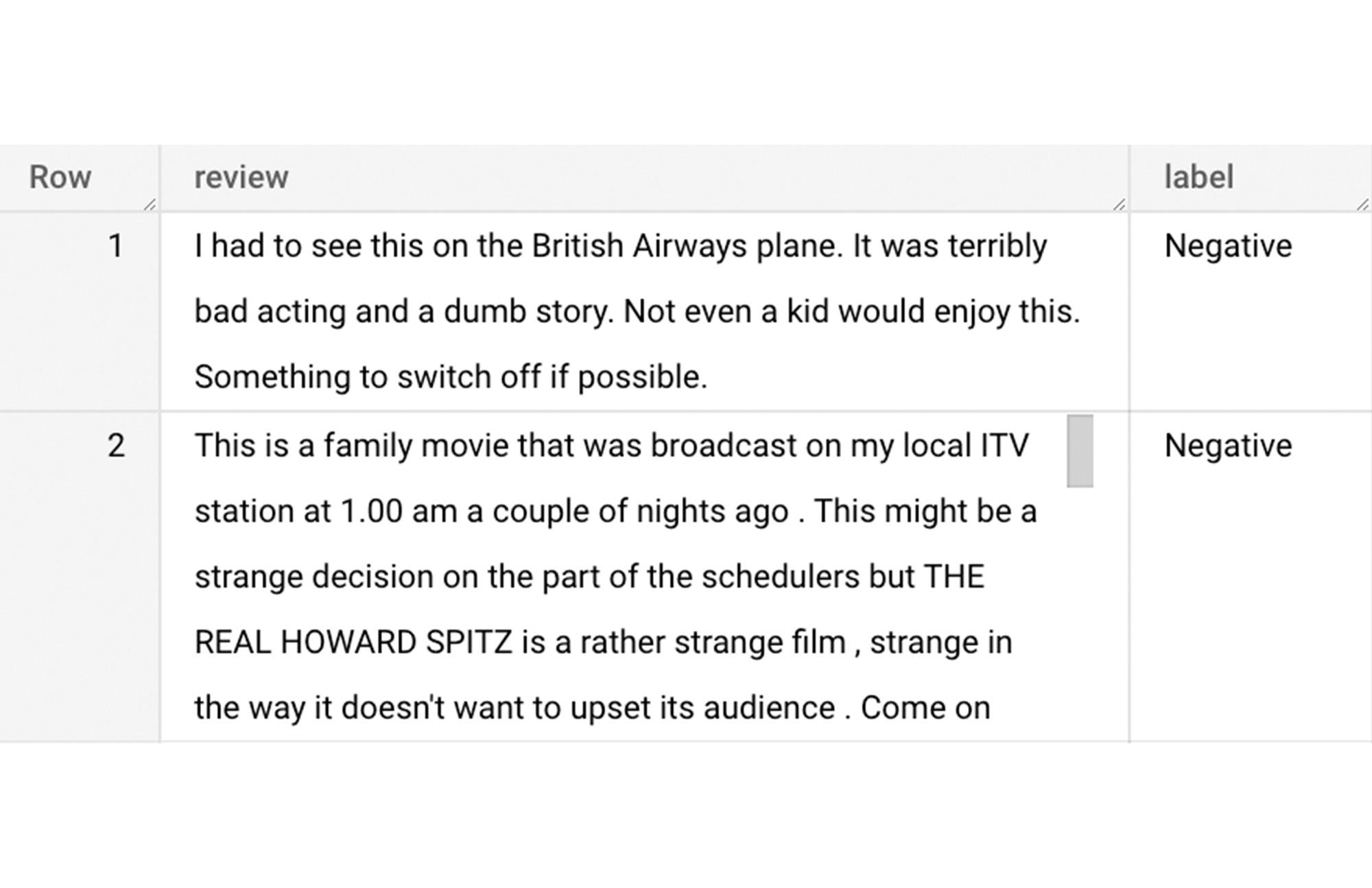
Although the reviews table has 7 columns, we only use reviews and label columns to perform sentiment analysis for this case. Also, we are only considering negative and positive values in the label columns. The following query can be used to select only the required information from the dataset.
The top 2 rows of the result is as follows:
Methodology
Based on the dataset that we have, the following steps will be carried out:
Build a vocabulary list using the review column
Convert the review column into sparse tensors
Train a classification model using the sparse tensors to predict the label ("positive" or "negative")
Make predictions on new test data to classify reviews as positive or negative.
Feature engineering
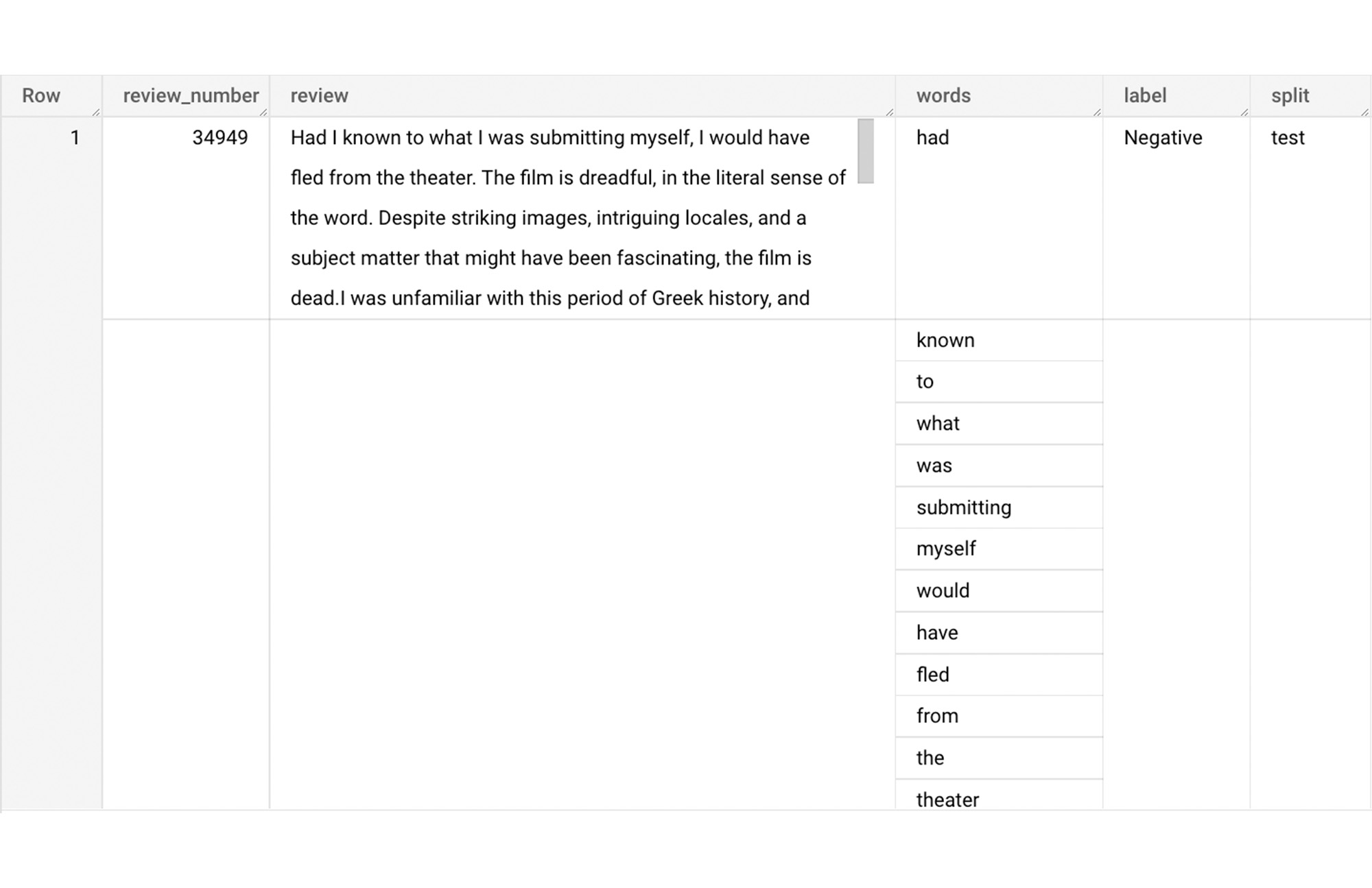
In this section, we will convert the text from the reviews column to numerical features so that we can feed them into a machine learning model. One of the ways is the bag-of-words approach where we build a vocabulary using the words from the reviews and select the most common words to build numerical features for model training. But first, we must extract the words from each review. The following code creates a dataset and a table with row numbers and extracted words from reviews.
The output table from the query above should look like this:
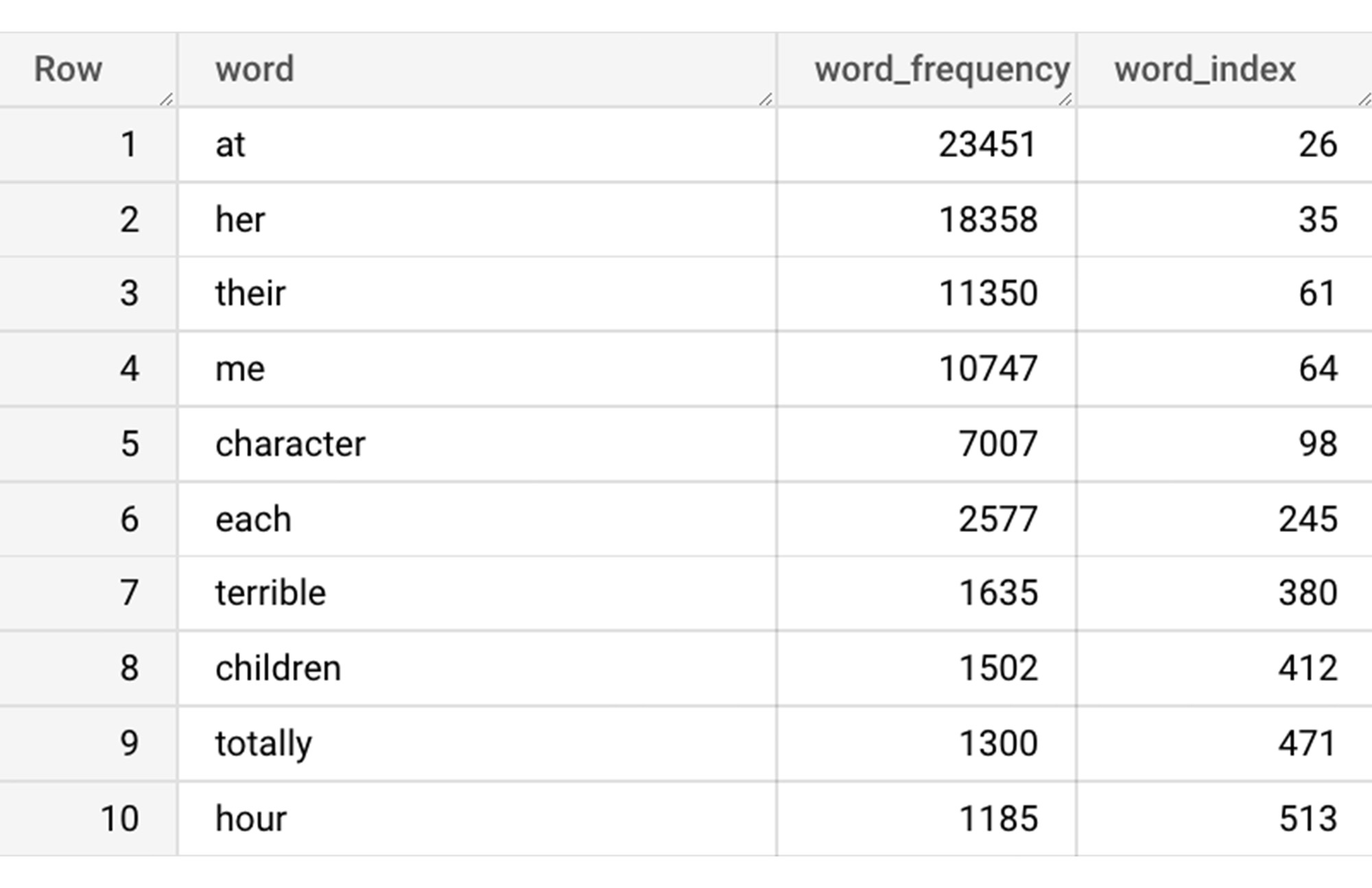
The next step is to build a vocabulary using the extracted words. The following code creates a vocabulary including word frequency and word index from reviews. For this case, we are going to select only the top 20,000 words to reduce the computation time.
The following shows the top 10 words based on frequency and their respective index from the resulting table of the query above.
Creating a sparse feature
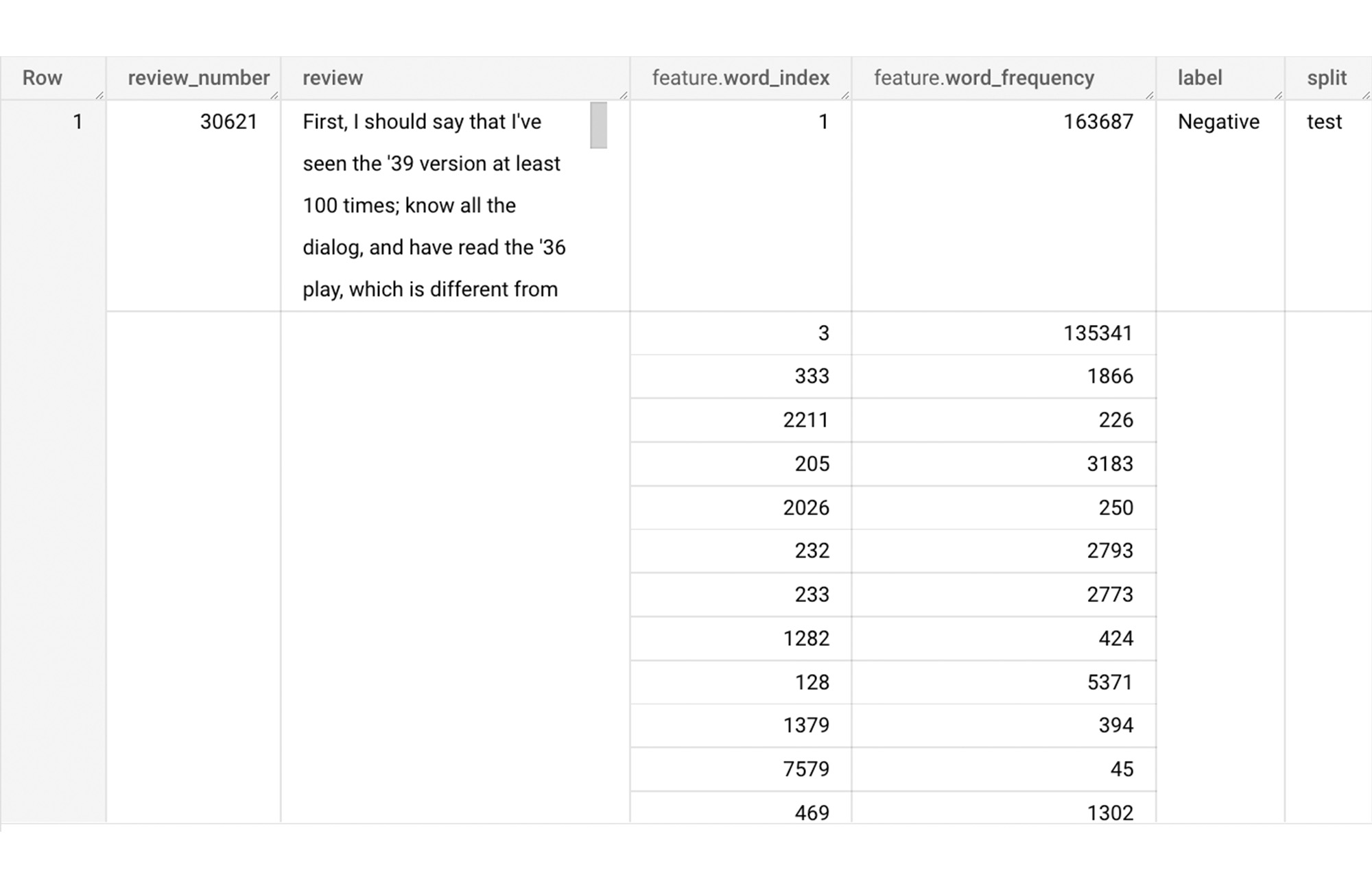
Now we will use the newly added feature to create a sparse feature in BigQuery. For this case, we aggregate `word_index` and `word_frequency` in each review, which generates a column as ARRAY[STRUCT<int, numerical>] type. Now, each review is represented as ARRAY[(word_index, word_frequency)].
Once the query is executed, a sparse feature named `feature` will be created. That `feature` column is an `ARRAY of STRUCT` column which is made of `word_index` and `word_frequency` columns. The picture below displays the resulting table at a glance.
Training a BigQuery ML model
We just created a dataset with a sparse feature in BigQuery. Let's see how we can use that dataset to train with a machine learning model with BigQuery ML. In the following query, we will train a logistic regression model using the review_number, review, and feature to predict the label:
Now that we have trained a BigQuery ML Model using a sparse feature, we evaluate the model and tune it as needed.

The score looks like a decent starting point, so let's go ahead and test the model with the test dataset.
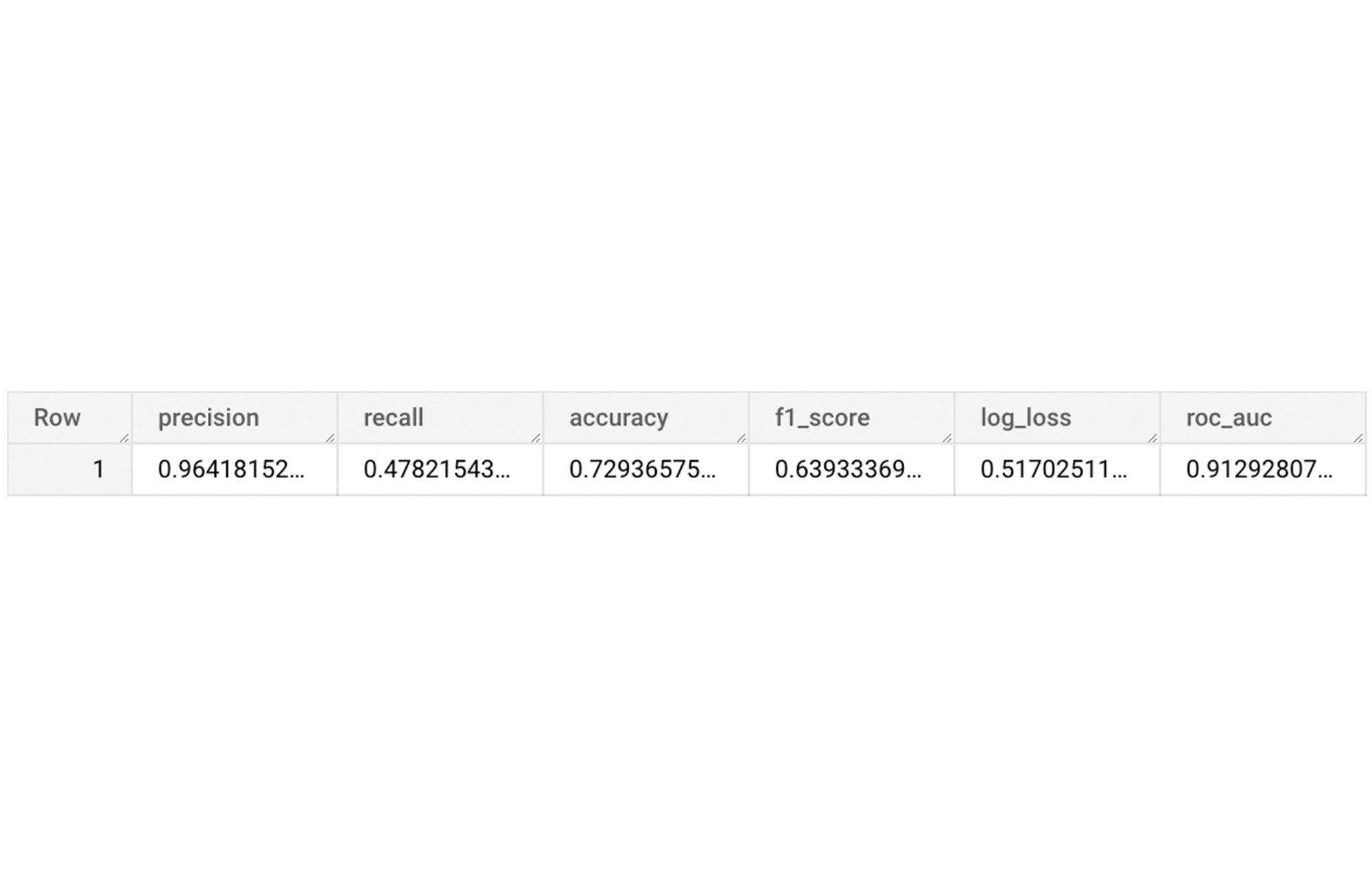
The model performance for the test dataset looks satisfactory and it can now be used for inference. One thing to note here is that since the model is trained on the numerical features, the model will only accept numeral features as input. Hence, the new reviews have to go through the same transformation steps before they can be used for inference. The next step shows how the transformation can be applied to a user-defined dataset.
Sentiment predictions from the BigQuery ML model
All we have left to do now is to create a user-defined dataset, apply the same transformations to the reviews, and use the user-defined sparse features to perform model inference. It can be achieved using a WITH statement as shown below.
Here is what you would get for executing the query above:
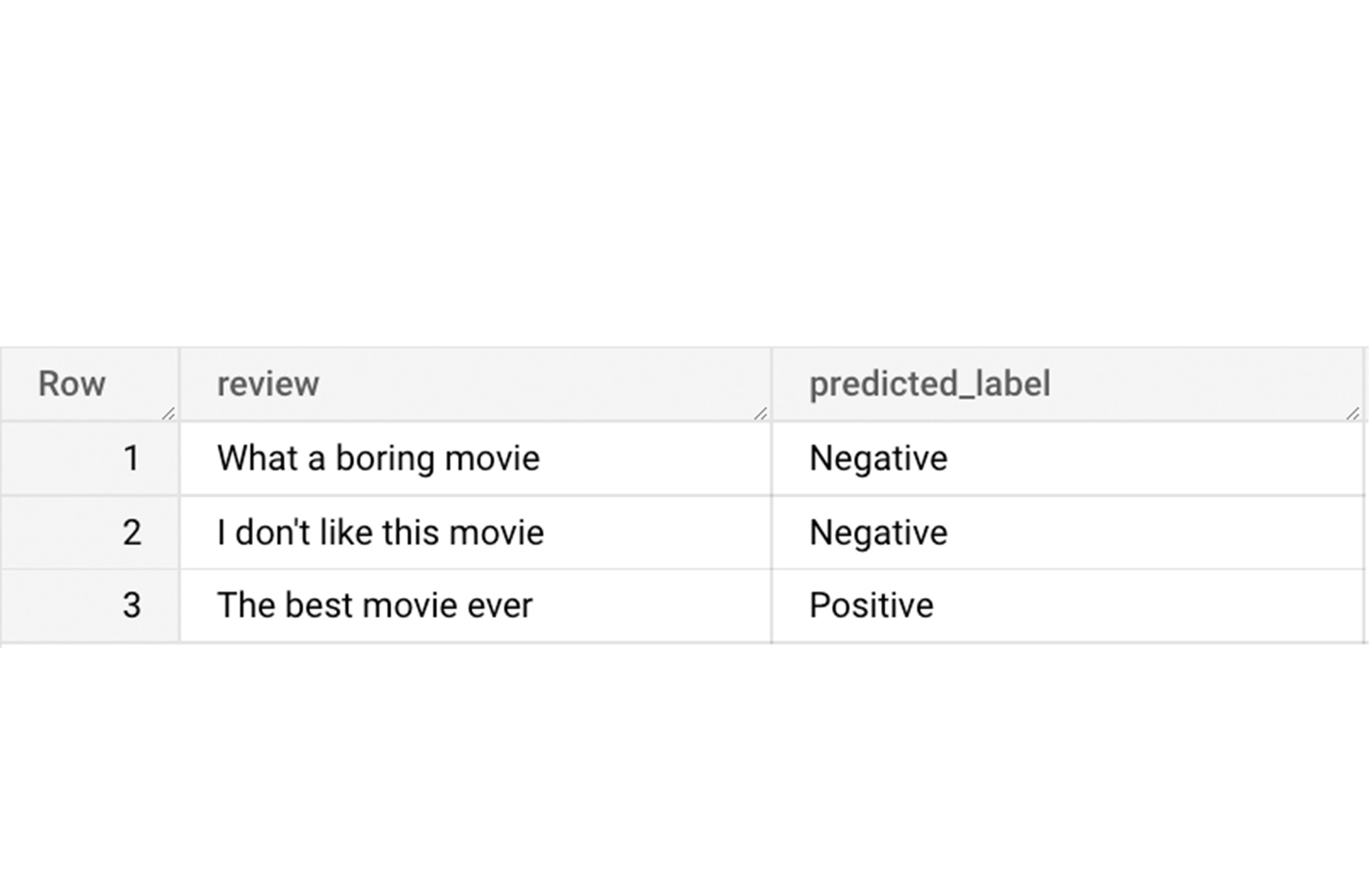
And that's it! We just performed a sentiment analysis on the IMDb dataset from a BigQuery Public Dataset using only SQL statements and BigQuery ML. Now that we have demonstrated how sparse features can be used with BigQuery ML models, we can’t wait to see all the amazing projects that you would create by harnessing this functionality.
If you're just getting started with BigQuery, check out our interactive tutorial to begin exploring.



