Improving the availability of your Cloud Storage: Automatic retries in client libraries
Sameena Shaffeeullah
Developer Relations Engineer
You can use client libraries to interact with Cloud Storage. Using client libraries provides several benefits, including abstracting away low level details when making requests (such as authentication), and providing automatic retries of transient operations.
Benefits of using client libraries for retries
Most Cloud Storage client libraries perform retries automatically. Retries are helpful in case of temporary server errors or connectivity issues, and using retries can help you reduce the number of intermittent failures. This is especially important when running a large volume of operations. Retries in the library make the service more reliable and fit to handle production-quality applications using Google Cloud Storage.
Client libraries automatically support all best practices for error handling:
Client libraries implement exponential backoff, a standard error handling strategy, with configurable options.
Client libraries determine if an error is safe to retry for a given operation, saving you the effort of distinguishing between idempotent, conditionally idempotent, and non idempotent operations as well as transient errors.
Client libraries resume complex uploads and downloads after interruption, making sure your data does not get lost or corrupted.
Client library retry code is validated which makes it safer from bugs than untested custom code.
Customize the behavior of retries
After a recent update, you can now customize your client library retry behavior across many parameters, including but not limited to: number of retries, maximum retry delay, total timeout, retry multiplier, idempotency strategy, and initial wait time. For a full list of parameters, defaults, and usage examples, see the retry documentation for your specific client library language.
Automatic, fully-configurable retries are supported for the following client libraries:
Go version 1.19.0 or greater
Java version 2.2.0 or greater
Python version 1.39.0 or greater
Node.js version 5.15.6 or greater
Any version of the C++ library
Robust, tested retries are still in development for C#, Ruby, and PHP.
How do client library retries work?
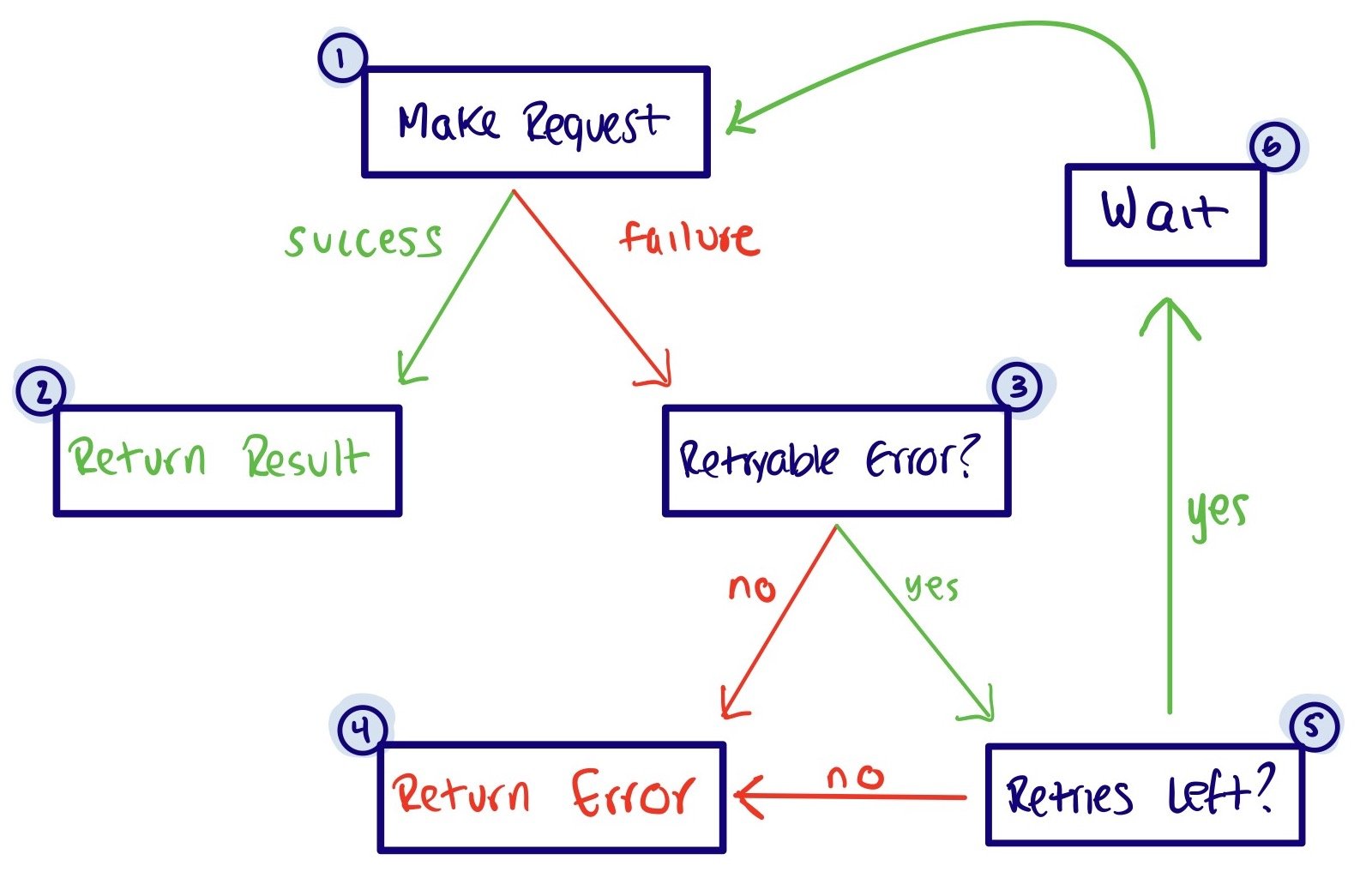
First, your code makes a request to the Cloud Storage server (box 1). This could be a call like Bucket.upload, File.download or File.getMetadata. If the request succeeds, you'll receive a success response (box 2).
If the request fails and the error is retryable (box 3), the client library will check to see if any retries are left (box 5) before returning the error back to you (box 4). An error is retryable if the following conditions are met:
The request is either idempotent, or conditionally idempotent and the correct preconditions are being met.
The error returned by the service is likely to be transient.
Retries are left if the request hasn't yet reached the maximum number of retries, and also hasn't yet reached the total timeout. If there are retries still waiting to be run, the library waits between sending each request again (box 6). The library uses exponential backoff to increase the wait time between retries, based on the maximum retry delay and retry multiplier parameters.
What's next
Get more detailed information about retry parameters, defaults, and usage samples by visiting the Cloud Storage retry documentation.
If you have questions or feedback, file an issue in one of the corresponding repos or click the “Send Feedback” button on the documentation page.



