Image search with natural language queries
Chansung Park
ML Google Developer Expert
Sayak Paul
ML Google Developer Expert
This post shows how to build an image search utility using natural language queries. Our aim is to use different GCP services to demonstrate this. At the core of our project is OpenAI's CLIP model. It makes use of two encoders - one for images and one for texts. Each encoder is trained to learn representations such that similar images and text embeddings are projected as close as possible.
We will first create a Flask-based REST API capable of handling natural language queries and matching them against relevant images. We will then demonstrate the use of the API through a Flutter-based web and mobile application. Figure 1 shows how our final application would look like:
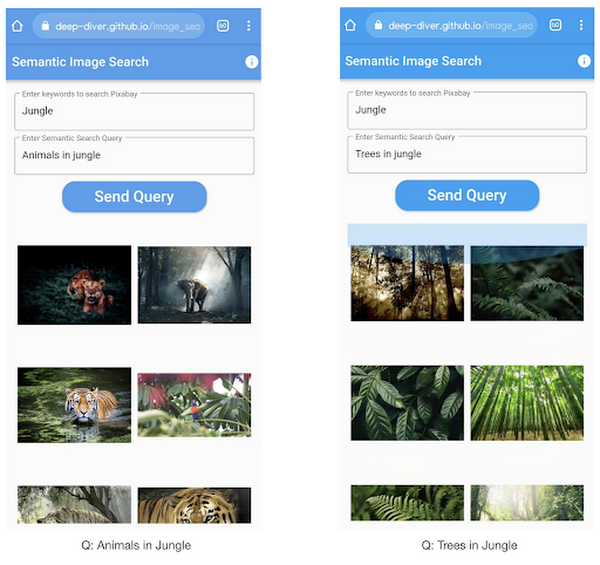
All the code shown in this post is available as a GitHub repository. Let’s dive in.
Application at a high-level
Our application will take two queries from the user:
- Tag or keyword query. This is needed in order to pull a set of images of interest from Pixabay. You can use any other image repositories for this purpose. But we found Pixabay’s API to be easier to work with. We will cache these images to optimize the user experience. Suppose we wanted to find images that are similar to this query: “horses amidst flowers”. For this, we’d first pull in a few “horse” images and then run another utility to find out the images that best match our query.
- Longer or semantic query that we will use to retrieve the images from the pool created in the step above. These images should be semantically similar to this query.
Note: Instead of two queries, we could have only taken a single long query and run named-entity extraction to determine the most likely important keywords to run the initial search with. For this post, we won’t be using this approach.
Figure 2 below depicts the architecture design of our application and the technical stack used for each of the components.
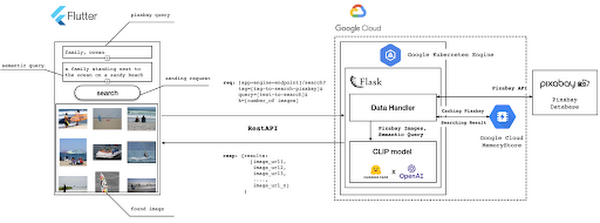
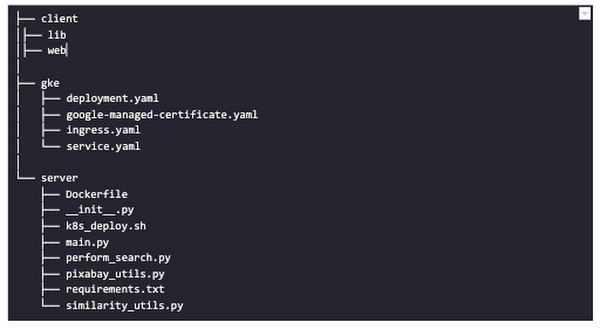
Figure 2 also presents the core logic of the API we will develop in bits and pieces in this post. We will deploy this API on a Kubernetes cluster using the Google Kubernetes Engine (GKE). The following presents a brief directory structure of our application code-base:
Next, we will walk through the code and other related components for building our image search API. For various machine learning-related utilities, we will be using PyTorch.
Building the backend API with Flask
First, we’d need to fetch a set of images with respect to user-provided tags/keywords before performing the natural language image search. The utility below from the pixabay_utils.py script can do this for us:
Note that all the API utilities are logging relevant information. But for brevity, we have omitted the lines of code responsible for that. Next, we will see how to invoke the CLIP model and select the images that would best match a given query semantically. For this, we’ll be using Hugging Face, an easy-to-use Python library offering state-of-the-art NLP capabilities. We’ll collate all the logic related to this search inside a SimilarityUtil class:
CLIP_MODEL uses a ViT-base model to encode the images for generating meaningful embeddings with respect to the provided query. The text-based query is also encoded using A Transformers-based model for generating the embeddings. These two embeddings are matched with one another during inference. To know more about the particular methods we are using for the CLIP model please refer to this documentation from Hugging Face.
In the code above, we are first invoking the CLIP model with images and the natural language query. This gives us a vector (logits_per_image) that contains the similarity scores between each of the images and the query. We then sort the vector in a descending manner. Note that we are initializing the CLIP model while instantiating the SimilarityUtil to save us the model loading time. This is the meat of our application and we have tackled it already. If you want to interact with this utility in a live manner you can check out this Colab Notebook.
Now, we need to collate our utilities for fetching images from Pixabay and for performing the natural language image search inside a single script - perform_search.py. Following is the main class of that script:
Here, we are just calling the utilities we had previously developed to return the URLs of the most similar images and their scores. What is even more important here is the caching capability. For that, we combined GCP’s MemoryStore and a Python library called direct-redis. More on setting up MemoryStore later.
MemoryStore provides a fully managed and low-cost platform for hosting Redis instances. Redis databases are in memory and light-weight making them an ideal candidate for caching. In the code above, we are caching the images fetched from Pixabay and their URLs. So, in the event of a cache hit, we won’t need to call the CLIP model and this will tremendously improve the response time of our API.
Other options for caching
We can cache other elements of our application. For example, the natural language query. When searching through the cached entries to determine if it’s a cache hit, we can compare two queries for semantic similarity and return results accordingly.
Consider that a user had entered the following natural language query: “mountains with dark skies”. After performing the search, we’d cache the embeddings of this query. Now, consider that another user entered another query: “mountains with gloomy ambiance”. We’d compute its embeddings and run a similarity search with the cached embeddings. We’d then compare the similarity scores with respect to a threshold and parse the most similar queries and their corresponding results. In case of a cache miss, we’d just call the image search utilities we developed above.
When working on real-time applications we often need to consider these different aspects and decide what enhances the user experience and maximizes business at the same time.
All that’s left now for the backend is our Flask application - main.py:
Here we are first parsing the query parameters from the request payload of our search API. We are then just calling the appropriate function from perform_search.py to handle the request. This Flask application is also capable of handling CORS. We do this via the flask_cors library:
And this is it! Our API is now ready for deployment.
Deployment with Compute Engine and GKE
The reason why we wanted to deploy our API on Kubernetes is because of the flexibility Kubernetes offers for managing deployments. When operating at scale, auto scalability and load balancing are very important. With the comes the requirement of security -- we’d not want to expose the utilities for interacting with any internal services such as databases. With Kubernetes, we can achieve all these easily and efficiently.
GKE provides secured and fully managed functionalities for operationalizing Kubernetes clusters. Here are the steps to deploy the API on GKE at a glance:
- We first build a Docker image for our API and then push it to the Google Container Registry (GCR).
- We then create a Kubernetes cluster on GKE and initialize a deployment.
- We then add scalability options.
- If any public exposure is needed for the API, we then tackle it.
These steps are well explained in this tutorial that you might want to refer to for more details. We can configure all the dependencies on our local machine and execute the shell script above. We can also use the GCP Console to execute it since a terminal on the GCP Console is pre-configured with the system-level dependencies we’d need. In reality, the Kubernetes cluster should only be created once and different deployment versions should be created under it.
After the above shell script is run successfully, we can run kubectl get service to know the external IP address of the service we just deployed:
We can now consume this API with the following base URI: http://203.0.113.0/. If we wanted to deal with only http-based API requests, then we are done here. But secured communication is often a requirement in order for applications to operate reliably. In the following section, we are to discuss how to configure the additional items to allow our Kubernetes cluster to allow https requests.
Configurations for handling https requests with GKE
A secure connection is almost often a must-have requirement in modern client/server applications. The front-end Flutter application would be hosted on GitHub Pages for this project, and it requires https-based connection as well. Even if configuring https connection particularly for a GKE-based cluster can be considered a chore, its setup might seem daunting at first.
There are six steps to configure https connection in the GKE environment:
- You need to have a domain name, and there are a lot of inexpensive options that you can buy. For instance, mlgde.com domain for this project is acquired via Gabia which is a Korean service provider.
- A reserved (static) external IP address has to be acquired via gcloud command or GCP console.
- You need to bind the domain name with the acquired external IP address. This is a platform-specific configuration that issued the domain name to you.
- There is a special ManagedCertificate resource which is specific to the GKE environment. ManagedCertificate resource specifies the domain that the SSL certificate will be created for, so you need this.
- An Ingress resource should be created by listing the static external IP address, ManagedCertificate resource, and the service name and port which the incoming traffic will be routed to. The Service resource could remain the same as in the above section with only changes from LoadBalancer to ClusterIP.
- Last but not least, you need to modify the existing Flask application and Deployment resource to support liveness and readiness probes which are used to check the health status of the Deployment. The Flask application side can be simply modified with the flask-healthz Python package, and you only need to add
livenessProbeandreadinessProbesections in the Deployment resource. In the code example below, thelivenessProbeandreadinessProbeare checked via/aliveand/readyendpoints respectively.
One thing to be careful of is the initialDelaySeconds attribute of the probes. It is uncommon to configure this attribute with a big number, but it could be bigger than 90 - 120 seconds depending on the size of the model to be used. For this project, it is configured in 90 seconds in order to wait until the CLIP model is fully loaded into memory (full YAML script here).
Again, these steps may seem daunting at first, but it will become clear when you have done it once. Here is the official document for Using Google-managed SSL certificates You can find all the GKE-related resources used in this project here.
Once every step is completed you should be able to see your server application running on the GKE environment. Please make sure to run kubectl apply command whenever you create Kubernetes resources such as Deployment, Service, Ingress, and ManagedCertificate, and it is important to wait for more than 10 minutes until the ManagedCertifcate provisioning is done.
You can run gcloud compute addresses list command to find out the static external IP address that you have configured.
Then, the IP address has to be mapped to the domain. Figure 3 is a screenshot of a dashboard from where we got the mlgde.com domain. It clearly shows mlgde.com is mapped to the static external IP address configured in GCP.

Figure 3: API endpoints mapped to our custom domain.
In case you’re wondering why we didn’t deploy this application on App Engine, well that is because of the compute needed to execute the CLIP model. App Engine instance won’t fit in that regime. We could have also incorporated compute-heavy capabilities via a VPC Connector. That is a design choice that you and your team would need to consider. In our experiments, we found the GKE deployment to be easier and suitable for our needs.
Infrastructure for the CLIP model
As mentioned earlier, at the core of our application is the CLIP model. It is computationally a bit more expensive than the regular deep learning models. This is why it makes sense to have the hardware infrastructure set up accordingly to execute it. We ran a small benchmark in order to see how a GPU-based environment could be beneficial here.
We ran the CLIP on a Tesla P100-based machine and also on a standard CPU-only machine 1000 times. The code snippet below is the meat of what we executed:
As somewhat expected, with the GPU, the code took 13 minutes to complete execution. With no GPU, it took about 157 minutes.
It is uncommon to leverage GPUs for model prediction because of cost restrictions, but sometimes we have to access GPUs for deploying a big model like CLIP. We configured a GPU-based cluster on GKE and compared the performance differences with and without it. It took about 1 second to handle a request with GPU and MemoryStore cache while it took more than 4 seconds with MemoryStore only (without the GPUs).
For the purposes of this post, we used a CPU-based cluster on Kubernetes. But It is easy to configure GPU usage in a GKE cluster. This document shows you how to do so. For a short summary, there are two steps. First, a node should be configured with GPUs when creating a GKE cluster. Second, GPU drivers should be installed in GKE nodes. You don’t need to visit and manually install GPU drivers for each node by yourself. Rather you can simply apply the DaemonSet resource to GKE as described here.
Setting up MemoryStore
In this project, we first query the general concept of images to Pixabay, then we filter the images with a semantic query using CLIP. It means we can cache the initially retrieved images from Pixabay for the next specific semantic query. For instance, you may want to search with “gentleman wearing tie” at first, then you may want to retry searching for “gentleman wearing glass”. In this case, the base images remain all the same, so they could be stored in a cache server like Redis.
MemoryStore is a GCP service wrapping the Redis which is an in-memory data store, so you can simply use a standard Redis Python package for accessing it. The only thing to be careful about when provisioning a MemoryStore Redis instance is to make sure it is in the same region where your GKE cluster or Compute Engine instance is.
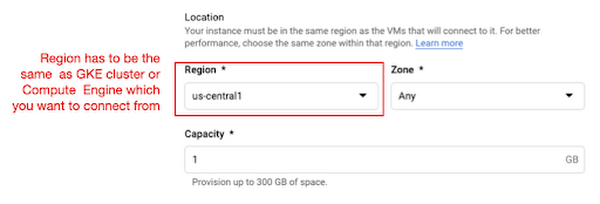
The code snippet below shows how to make a connection to the Redis instance in Python. Nothing specific to GCP, but you only need to be aware of the usage of the standard redis-py package.
After creating a connection, you can store and retrieve data from MemoryStore. There are more advanced use cases of Redis, but we only used exists, get, and set methods for the demonstration purpose. These methods should be very familiar if you know maps, dictionaries, or other similar data structures. For the code portion that uses Redis-related utilities, please refer to the Searcher Python class we discussed in an earlier section.
In the URLs below, you can find side-by-side comparisons of using MemoryStore:
- Without MemoryStore: https://youtu.be/7B88Eyrd-4s
- With MemoryStore (1st try): https://youtu.be/LE6xeEIRuMM
- With MemoryStore (2nd try): https://youtu.be/rRfK17sdk84
Putting everything together
All that’s left now is to collate the different components we developed in the sections above and deploy our application with a frontend. All the frontend-related code is present here.
The front-end application is written in the Flutter development kit. The main screen contains two text fields for queries to Pixabay and CLIP model respectively. When you click the “Send Query” button, it will send out a RestAPI request to the server. After receiving the result back from the server, the retrieved images from the semantic query will be displayed at the bottom section of the screen.
Please note that a Flutter application can be deployed to various environments including desktop, web, iOS, and Android. In order to keep as simple as possible, we chose to deploy the application to the GitHub Pages. Whenever there is any change to a client-side source directory, the GitHub Action will be triggered to build a web page and deploy the latest version to the GitHub Pages.
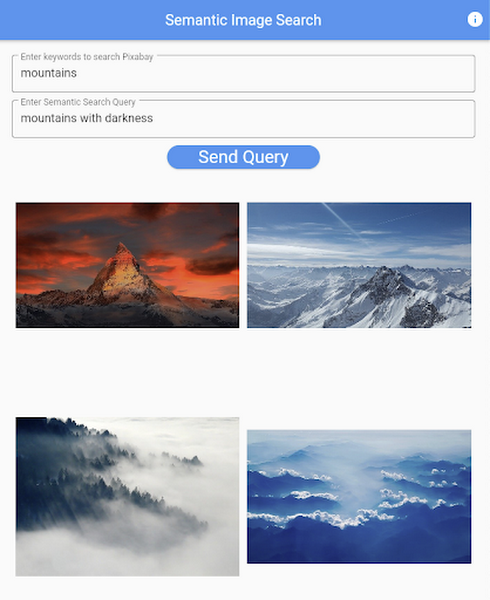
Figure 5: Live application screen.
Note that due to constraints, the above-mentioned URL will only be live for one or two months.
It is also possible to redeploy the back-end application with a GitHub Action.
The very first step is to craft a Dockerfile like below. Since Python is a scripting language, and there are lots of heavy packages that the application is dependent on, it is important to cache the steps. For instance, installing the dependencies should be separated from other commands.
With the Dockerfile defined, we can use a GitHub Action like this for automatic deployment.
Edge cases
Since the CLIP model is pre-trained on a large corpus of image and text pairs it’s likely that it may not generalize well to every natural language query we throw at it. Also, because we are limiting the number of images on which the CLIP model can operate, this somehow restricts the expressivity of the model.
We may be able to improve the performance for the second situation by increasing the number of images to be pre-fetched and by indexing them into a low-cost and high-performance database like Datastore.
Costs
In this section, we wanted to provide the readers a breakdown of the costs they might incur in order to consume the various services used throughout the application.
Frontend hosting
The front-end application is hosted on GitHub Pages, so there is no expenditure for this.
Compute Engine
With an e2-standard-2 instance type without GPUs, the cost is around $48.92 per month. In case you want to add a GPU (NVIDIA K80), the cost goes up to $229.95 per month.
MemoryStore
The cost for MemoryStore depends on the size. With 1GB of space, the cost is around $35.77 per month, and whenever you add more GBs the cost will be doubled.
Google Kubernetes Engine
The monthly cost for a 3 node GKE cluster with n2-standard-2 (vCPUs: 2, RAM: 8GB without GPUs) is about $170.19. If you add one GPU (NVIDIA K80) to the cluster, the cost goes up to $835.48.
While you may think that is a lot cost-wise, it is good to know that Google gives away free $300 credits when you create a new GCP account. It is still not enough for leveraging GPUs, but it is enough to learn and experiment with GKE and MemoryStore usage.
Conclusion
In this post, we walked through the components needed to build a basic image search utility for natural language queries. We discussed how these different components are connected to each other. Our image search API is able to utilize caching and was deployed on a Kubernetes cluster using GKE. These elements are essential when building a similar service to cater to a much bigger workload. We hope this post will serve as a good starting point for that purpose. Below are some references on similar areas of work that you can explore:
Acknowledgments: We are grateful to the Google Developers Experts program for supporting us with GCP credits. Thanks to Karl Weinmeister and Soonson Kwon of Google for reviewing the initial draft of this post.